[爬虫实战]利用python快速爬取NCBI中参考基因组assembly的相关信息 |
您所在的位置:网站首页 › ncbi下载文章 › [爬虫实战]利用python快速爬取NCBI中参考基因组assembly的相关信息 |
[爬虫实战]利用python快速爬取NCBI中参考基因组assembly的相关信息
|
1.问题导向
最近在做某个课题的时候,按老师的要求需要从NCBI中批量下载不同物种的参考基因组,同时收集相应参考基因组的一些组装信息,基因组非常多,导致工作量巨大,一个一个手动收集的话,既费时又费力,这时就想到了用python爬虫来完成这项任务。 2.爬虫思路 2.1找到所需爬取的网页并观察网址urls的异同点以猪、马、牛、羊参考基因组为例: # Sus scrofa (pig) https://www.ncbi.nlm.nih.gov/assembly/GCA_000003025.6 # Equus caballus (horse) https://www.ncbi.nlm.nih.gov/assembly/GCF_002863925.1 # Bos taurus (cattle) https://www.ncbi.nlm.nih.gov/assembly/GCF_002263795.1 # Ovis aries (sheep) https://www.ncbi.nlm.nih.gov/assembly/GCF_016772045.1 ...... #汇总: urls = "https://www.ncbi.nlm.nih.gov/assembly/{assembly_ID}"NCBI中的参考基因组大部分是按照GenBank assembly accession号来存放位置的,因此我们只需要得到所需要收集物种的登录号,即可找到对应参考基因组的组装信息的页面。 2.2确认所需爬取的信息并确认是否需要二次爬取
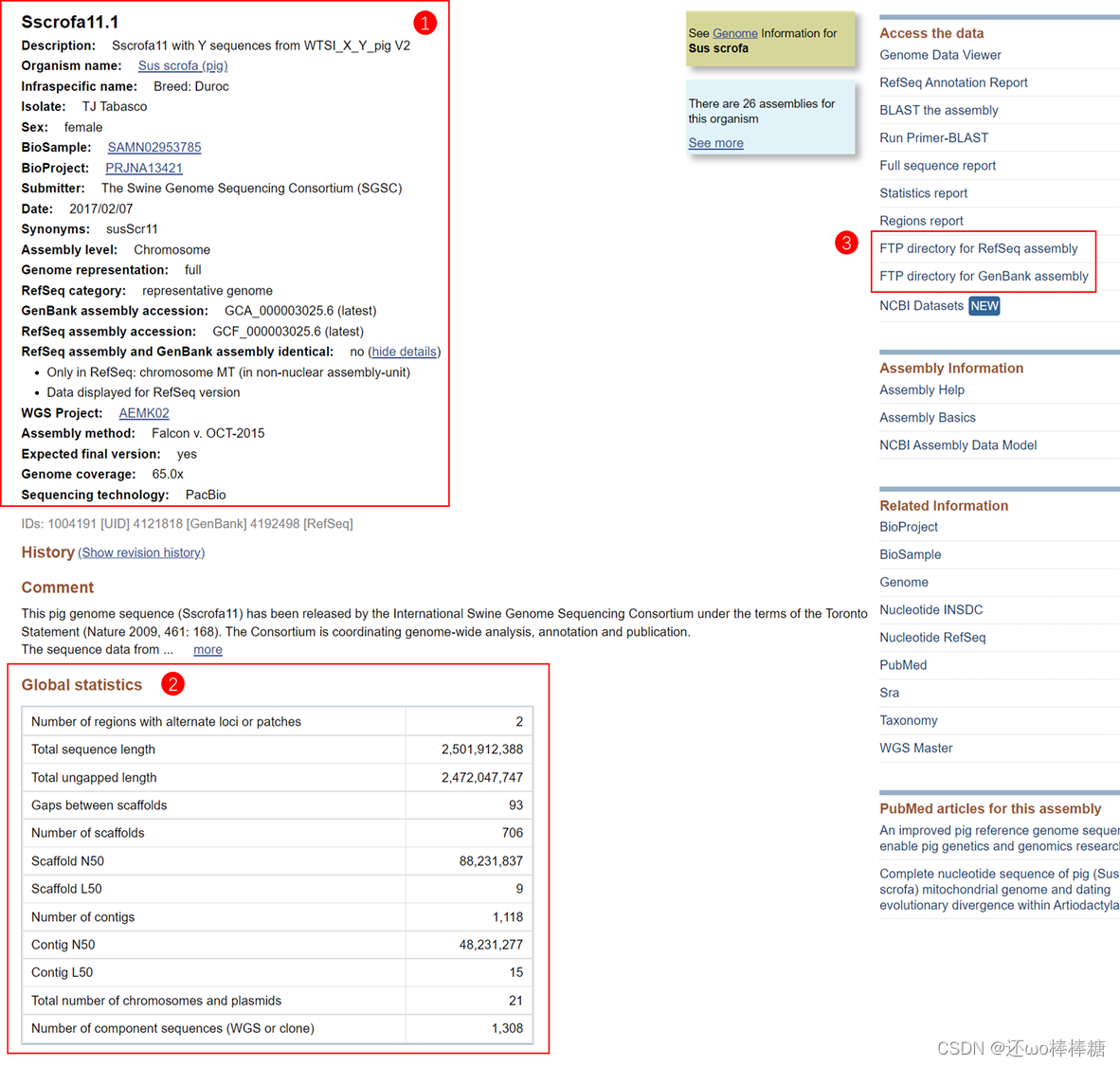
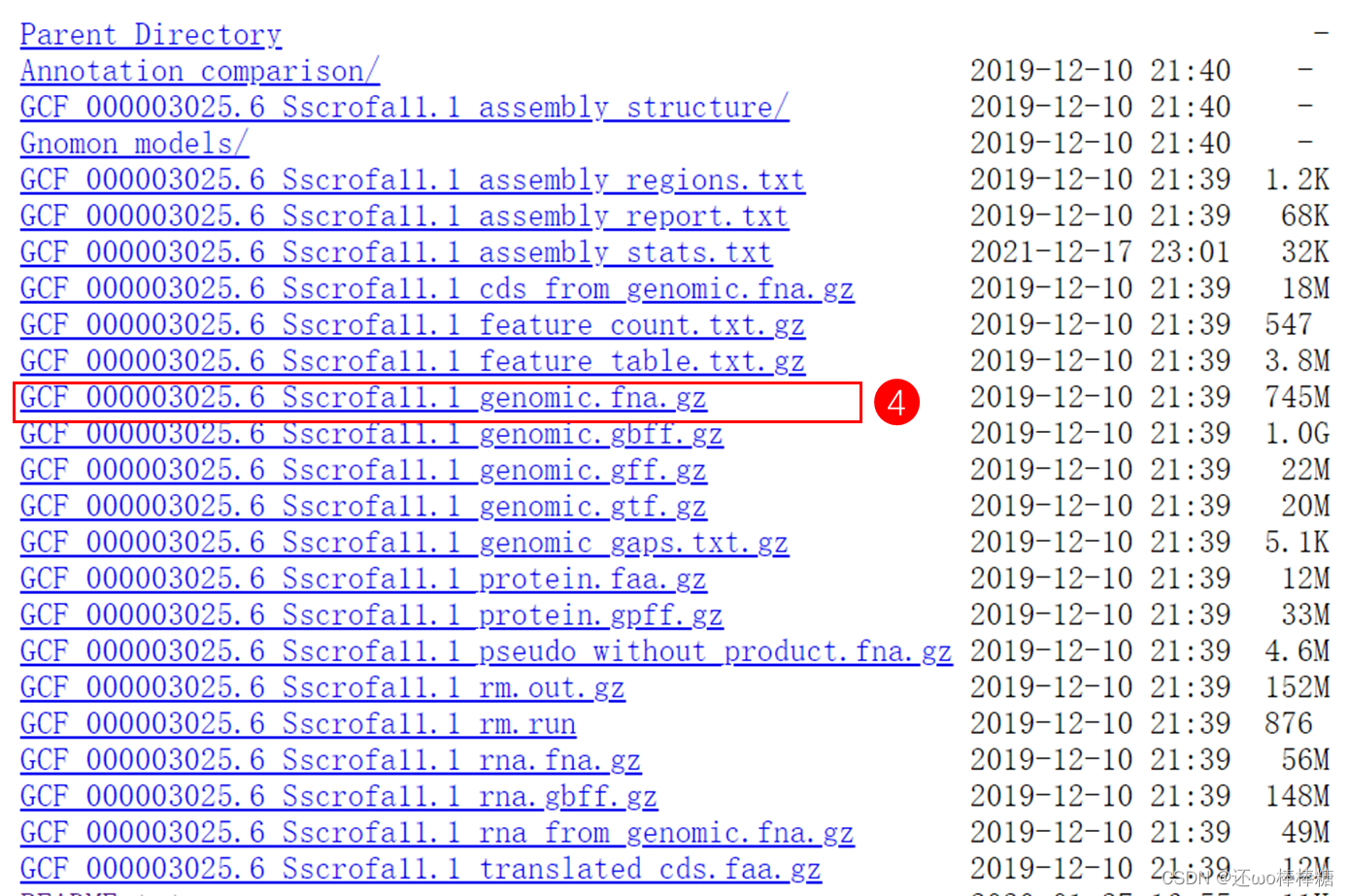
此处,需要爬取的信息共分为三部分,分别为上图红框中部分: 第一部分为每个assembly的基本信息,按照自己的需要选择内容,如assembly name、Organism name、Genome coverage等。 第二部分为每个assembly的组装信息,主要反映assembly的组装质量,建议全都收集。 第三部分为常规下载的FTP地址,用来存放供下载的参考基因组、CDS序列、或注释文件GFF、GTF等文件,因为其拥有独立的网址url,需要二次爬取。新页面如下图所示: 如下图。本文主要下载参考基因组,即.fna文件,可按需要下载蛋白.faa、注释文件.gff或.gtf文件等。
通过鼠标右键或快捷键"CTRL+U"来调出网页源代码,并利用"CTRL+F"来快速定位自己所需要爬取的内容的位置,如下: 第一部分:assembly基本信息 Sscrofa11.1Description: Sscrofa11 with Y sequences from WTSI_X_Y_pig V2Organism name: Sus scrofa (pig)Infraspecific name: Breed: DurocIsolate: TJ TabascoSex: femaleBioSample: SAMN02953785BioProject: PRJNA13421Submitter: The Swine Genome Sequencing Consortium (SGSC)Date: 2017/02/07Synonyms: susScr11Assembly level: ChromosomeGenome representation: fullRefSeq category: representative genomeGenBank assembly accession: GCA_000003025.6 (latest)RefSeq assembly accession: GCF_000003025.6 (latest)RefSeq assembly and GenBank assembly identical: no (hide details)Only in RefSeq: chromosome MT (in non-nuclear assembly-unit)Data displayed for RefSeq versionWGS Project: AEMK02Assembly method: Falcon v. OCT-2015Expected final version: yesGenome coverage: 65.0xSequencing technology: PacBioIDs: 1004191 [UID] 4121818 [GenBank] 4192498 [RefSeq] See Genome Information for |
【本文地址】
今日新闻 |
推荐新闻 |