【实用算法教学】 |
您所在的位置:网站首页 › nba赛事分析aman01。in › 【实用算法教学】 |
【实用算法教学】
|
本章主要内容有:
用
pandas
库加载、处理数据
决策树
随机森林
对真实数据集进行数据挖掘
创建新特征,用强有力的框架对其进行测试
一 加载数据集
如果你看过NBA,可能知道比赛中两支球队比分咬得 很紧,难分胜负,有时最后一分钟才能定输赢,因此预测赢家很难。很多体育赛事都有类似的特 点,预期的大赢家也许当天被另一支队伍给打败了。 以往很多对体育赛事预测的研究表明,正确率因体育赛事而异,其上限在 70%~80% 之间。 体育赛事预测多采用数据挖掘或统计学方法。 二 采集数据 我们将使用 NBA 2013 — 2014 赛季的比赛数据。 http://Basketball-Reference.com 网站提供了 NBA 及其他赛事的大量资料和统计数据。请按以下方法下载数据。 (1) 在浏览器中打开 http://www.basketball-reference.com/leagues/NBA_2014_games.html 。 (2) 点击标题 Regular Season 旁边的 Export 按钮。 (3) 将文件下载到 Data 文件夹,记录文件的路径。 数据文件格式为 CSV ,包含了 NBA 常规赛季的 1230 场比赛。 CSV 为简单的文本格式文件,每行为一条用逗号分隔的数据(文件格式的名字就是这么来 的)。在记事本里输入内容,保存时使用 .csv 扩展名,也能生成 CSV 文件。只要能阅读文本文件的 编辑器,就能打开 CSV 文件,也可以用 Excel 把它作为电子表格打开。 我们用 pandas ( Python Data Analysis 的简写,意为 Python 数据分析)库加载这些数据, pandas 在数据处理方面特别有用。 Python 内置了读写 CSV 文件的 csv 库。但是,考虑到后面创建新特征 时还要用到 pandas 更强大的一些函数,所以我们干脆用 pandas 加载数据文件。 三 用pandas加载数据集 pandas 库是用来加载、管理和处理数据的。它在后台处理数据结构,支持诸计算均值等分析 方法。 如果做过大量数据挖掘实验,就会发现自己翻来覆去地编写文件读取、特征抽取等函数。而 这些函数每重新实现一次,都可能引入新错误。使用 pandas 等封装了很多功能的库,能有效减少 反复实现上述函数所带来的工作量,并能保证代码的正确性。用read_csv函数就能加载数据集: import pandas as pd dataset = pd.read_csv(data_filename) 上述代码会加载数据集,将其保存到 数据框 ( dataframe )中。数据框提供了一些非常好用的 方法,后面会用到。我们来看看数据集是否有问题。输入以下代码,输出数据集的前 5 行: dataset.ix[:5] 输出结果如下: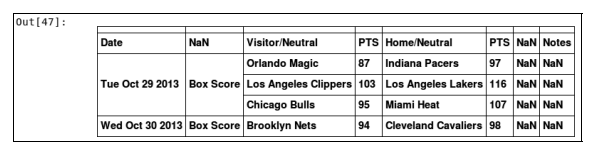
从输出结果来看,这个数据集可以用,但存在几个小问题。下面我们就来修复这些问题。 四 数据集清洗 从上面的输出结果中,我们发现了以下几个问题。 日期是字符串格式,而不是日期对象。 第一行没有数据。 从视觉上检查结果,发现表头不完整或者不正确。 这些问题来自数据,我们可以改动数据本身,但是这样做的话,容易忘记之前做过哪些操作, 落下步骤或是弄错哪一步,因而无法重现之前的结果。 我们用 pandas 对原始数据进行预处理。 pandas.read_csv 函数提供了可用来修复数据的参数,导入文件时指定这几个参数就好。 导入后,我们还可以修改文件的头部,如下所示: dataset = pd.read_csv(data_filename, parse_dates=["Date"], skiprows=[0,]) dataset.columns = ["Date", "Score Type", "Visitor Team", "VisitorPts", "Home Team", "HomePts", "OT?", "Notes"]经过这些处理之后,结果会有很大改善,我们再来输出前5行看看: dataset.ix[:5] 结果如下: 即使原始数据很规整,比如刚使用的这个,我们仍需要对其做些调整。其中一个原因是,文
件可能来自不同的系统,由于存在兼容性问题,文件也许会发生变化。
<
即使原始数据很规整,比如刚使用的这个,我们仍需要对其做些调整。其中一个原因是,文
件可能来自不同的系统,由于存在兼容性问题,文件也许会发生变化。
<
|
【本文地址】
今日新闻 |
推荐新闻 |