pytorch综合多个弱分类器,投票机制,进行手写数字分类(boosting) |
您所在的位置:网站首页 › nbamvp投票机制 › pytorch综合多个弱分类器,投票机制,进行手写数字分类(boosting) |
pytorch综合多个弱分类器,投票机制,进行手写数字分类(boosting)
|
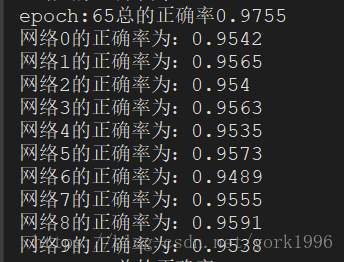
首先,这个文章的出发点就是让一个网络一个图片进行预测,在直观上不如多个网络对一个图片进行预测之后再少数服从多数效果好。 也就是对于任何一个分类任务,训练n个弱分类器,也就是分类准确度只比随机猜好一点,那么当n足够大的时候,通过投票机制,也能提升很大的准确度:毕竟每个网络都分错同一个数据的可能性会降低。 接下来就是代码实现。 import torch import torchvision import torch.nn as nn from torch.utils.data import DataLoader from collections import Counter import numpy as np class MLP(nn.Module): def __init__(self): super(MLP, self).__init__() self.input_layer=nn.Sequential( nn.Linear(28*28,30), nn.Tanh(), ) self.output_layer=nn.Sequential( nn.Linear(30,10), #nn.Sigmoid() ) def forward(self, x): x=x.view(x.size(0),-1) x=self.input_layer(x) x=self.output_layer(x) return x trans=torchvision.transforms.Compose( [ torchvision.transforms.ToTensor(), torchvision.transforms.Normalize([.5],[.5]), ] ) BATCHSIZE=100 DOWNLOAD_MNIST=False EPOCHES=200 LR=0.001 train_data=torchvision.datasets.MNIST( root="./mnist",train=True,transform=trans,download=DOWNLOAD_MNIST, ) test_data=torchvision.datasets.MNIST( root="./mnist",train=False,transform=trans,download=DOWNLOAD_MNIST, ) train_loader=DataLoader(train_data,batch_size=BATCHSIZE,shuffle=True) test_loader =DataLoader(test_data,batch_size=BATCHSIZE,shuffle=False) mlps=[MLP().cuda() for i in range(10)] optimizer=torch.optim.Adam([{"params":mlp.parameters()} for mlp in mlps],lr=LR) loss_function=nn.CrossEntropyLoss() for ep in range(EPOCHES): for img,label in train_loader: img,label=img.cuda(),label.cuda() optimizer.zero_grad()#10个网络清除梯度 for mlp in mlps: out=mlp(img) loss=loss_function(out,label) loss.backward()#网络们获得梯度 optimizer.step() pre=[] vote_correct=0 mlps_correct=[0 for i in range(len(mlps))] for img,label in test_loader: img,label=img.cuda(),label.cuda() for i, mlp in enumerate( mlps): out=mlp(img) _,prediction=torch.max(out,1) #按行取最大值 pre_num=prediction.cpu().numpy() mlps_correct[i]+=(pre_num==label.cpu().numpy()).sum() pre.append(pre_num) arr=np.array(pre) pre.clear() result=[Counter(arr[:,i]).most_common(1)[0][0] for i in range(BATCHSIZE)] vote_correct+=(result == label.cpu().numpy()).sum() print("epoch:" + str(ep)+"总的正确率"+str(vote_correct/len(test_data))) for idx, coreect in enumerate( mlps_correct): print("网络"+str(idx)+"的正确率为:"+str(coreect/len(test_data)))可以看到虽然网络模型很简单,但是通过多个弱分类模型的投票,得到的结果也是比其中任何一个网络的效果都要好不少的。应该关注相对提升,不应该关注绝对提升。 这些网络模型的架构一致,只是初始化不一样。如果模型之间架构差别比较大,比如有简单的cnn,dnn,rnn,svm等等,效果可能更好。 |
【本文地址】
今日新闻 |
推荐新闻 |