navicat使用及SQL查询语法 |
您所在的位置:网站首页 › navicat怎么给数据库改名 › navicat使用及SQL查询语法 |
navicat使用及SQL查询语法
navicat使用及SQL查询语法目录复制
数据库工具连接使用1.1新建mysql数据库1.2工具如果使用1.3用工具执行查询语句SQL语法2.1简介2.2 SQL 查询数据 (SELECT 语句)查询并显示表中所有数据
2.3 SQL WHERE 子句WHERE子句中允许的运算符
2.4 SQL AND & OR 运算符OR运算符
2.5 SQL IN & BETWEEN 运算符IN运算符BETWEEN 运算符==定义日期范围==
2.6 SQL ORDER BY 子句对结果集排序单列排序多列排序
2.7 SQL LIMIT 子句SQL LIMIT 子句
2.8 SQL DISTINCT 子句2.9 SQL 联表查询(Join)2.9.1 INNER JOIN 语句
2.9.2 LEFT JOIN 语句2.9.3 RIGHT JOIN 语句2.10 LIKE 运算符2.11 表、列别名2.11.1定义表别名
2.11.2定义表列的别名2.12 GROUP BY 子句2.13 HAVING 子句
数据库工具连接使用
打开Navicat Premium工具,选择要连接的数据库类型,这里选择Mysql数据库,如图所示。 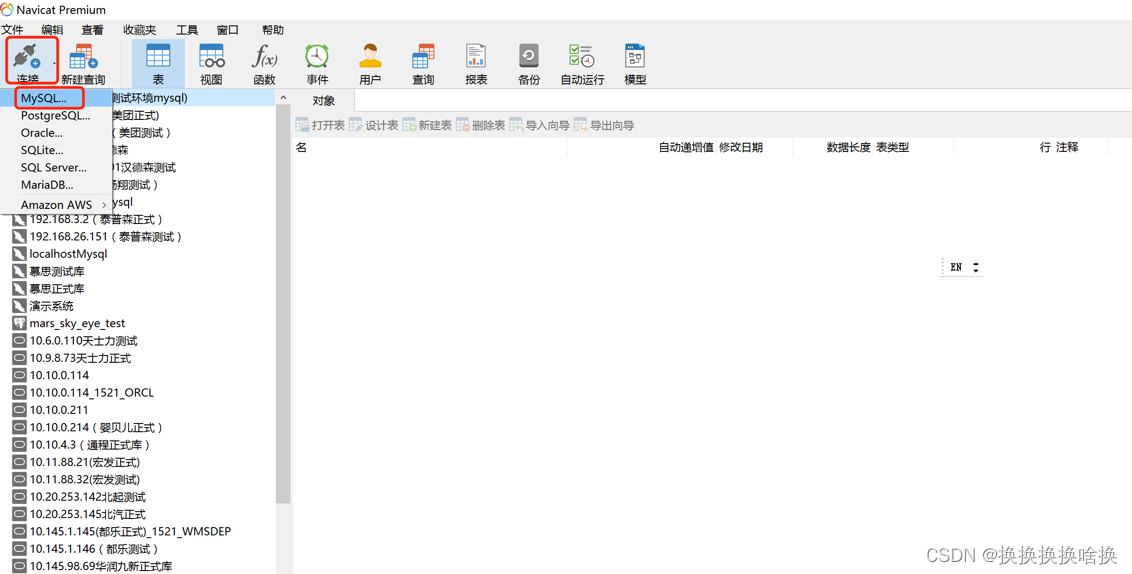 然后设置连接名及其他信息,输入IP地址,服务名称及用户名及密码信息,如下图所示。 然后设置连接名及其他信息,输入IP地址,服务名称及用户名及密码信息,如下图所示。 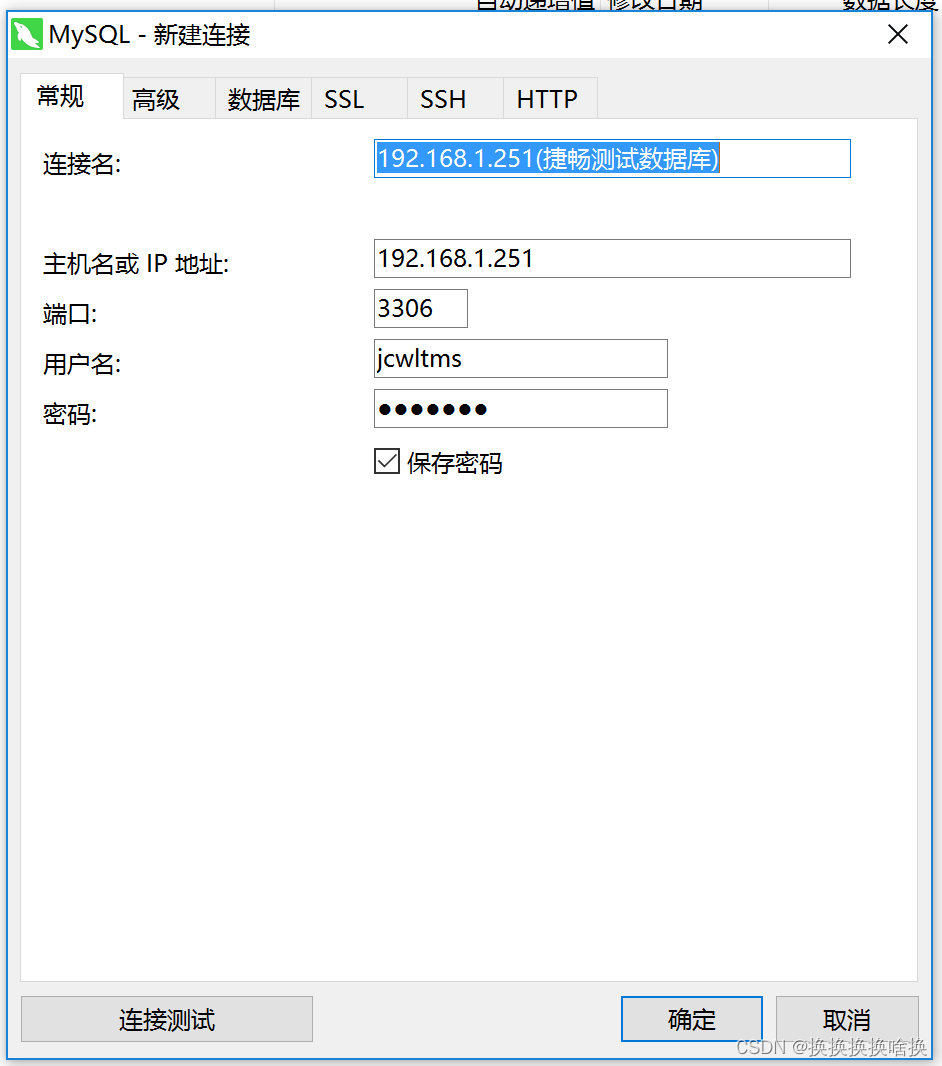 如果项目的数据库需要通过ssh通道连接,则需要配置SSH信息,点击SSH,输入主机、用户名、密码,不用则不需要这一步。 如果项目的数据库需要通过ssh通道连接,则需要配置SSH信息,点击SSH,输入主机、用户名、密码,不用则不需要这一步。 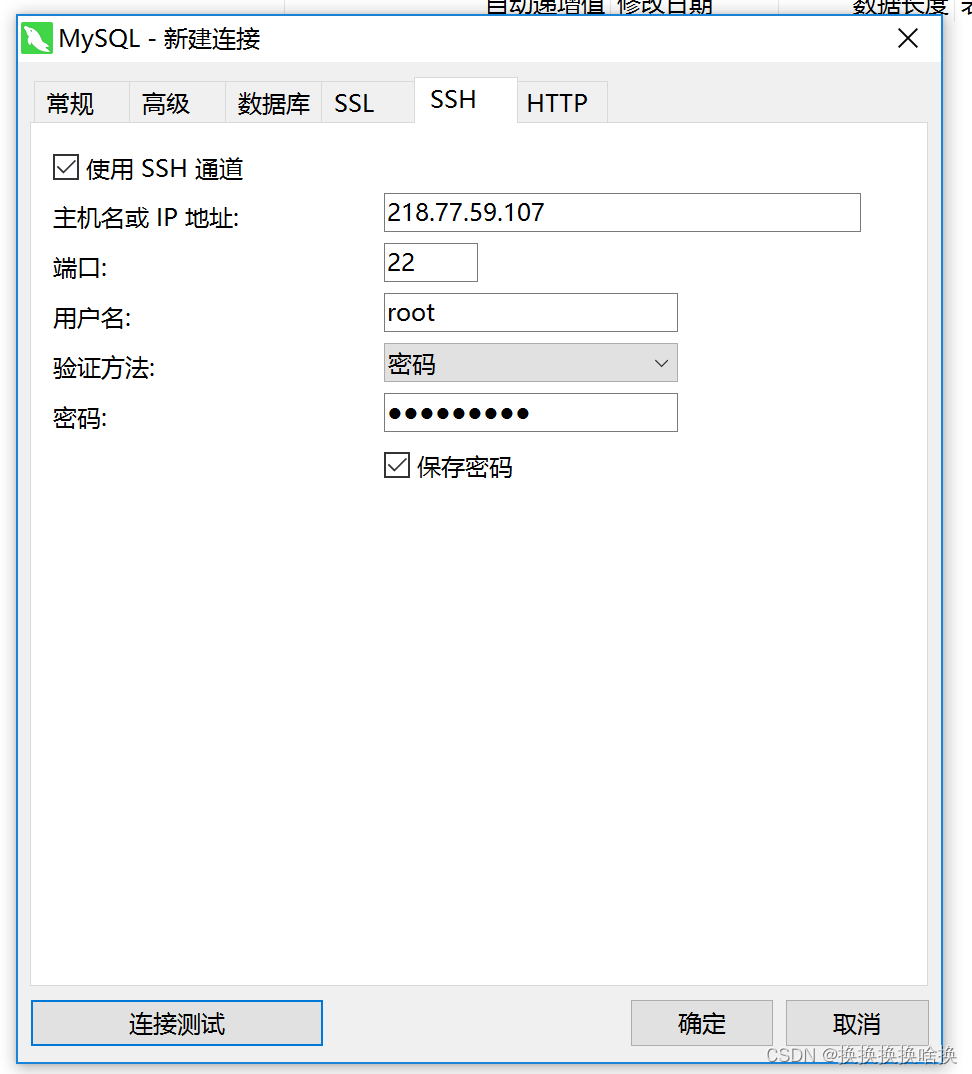 信息输入完毕后,可以点击连接测试的按钮,测试一下输入的信息是否正确,如果弹出连接成功的按钮,证明配置正确。点击保存 信息输入完毕后,可以点击连接测试的按钮,测试一下输入的信息是否正确,如果弹出连接成功的按钮,证明配置正确。点击保存 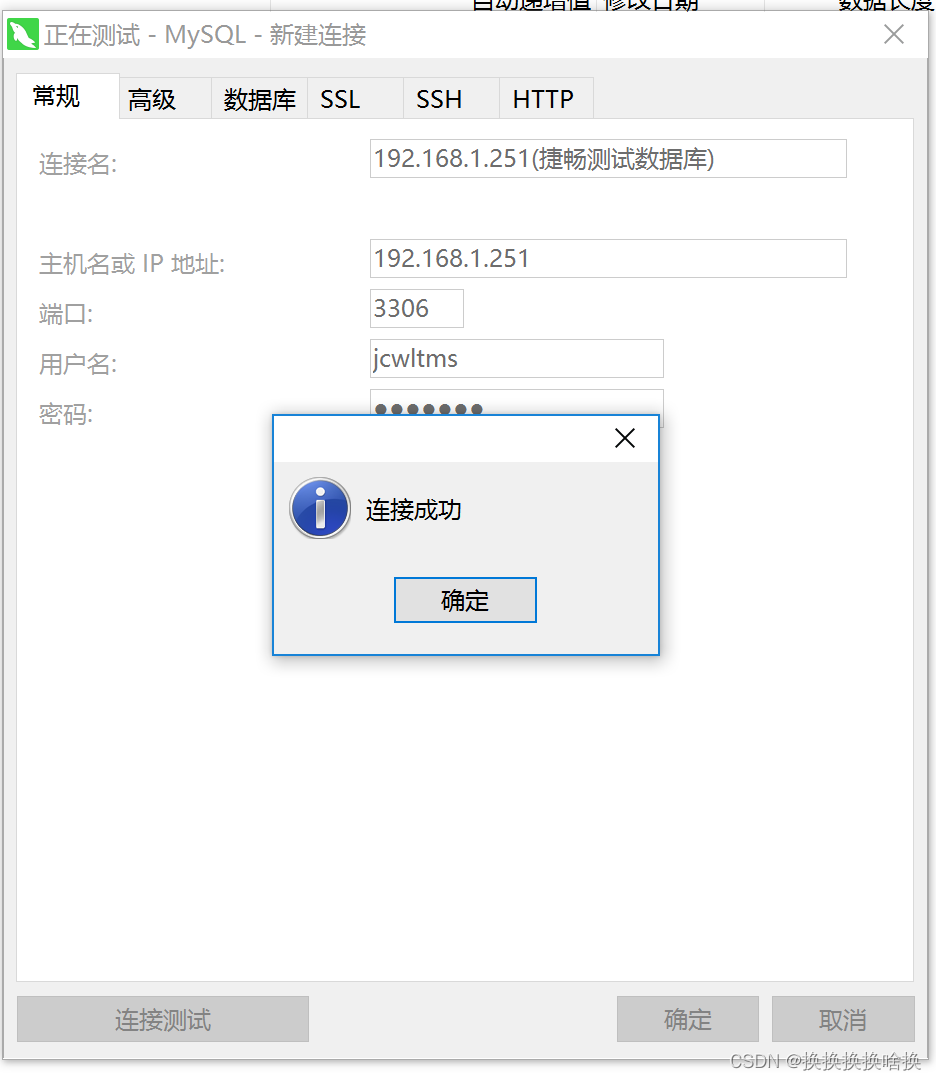 1.1新建mysql数据库
下载培训数据库脚本 脚本地址:链接: https://pan.baidu.com/s/14oupc2dn-RYjXcvSAwhXeg 提取码: xqei选择连接右键 新建数据库
1.1新建mysql数据库
下载培训数据库脚本 脚本地址:链接: https://pan.baidu.com/s/14oupc2dn-RYjXcvSAwhXeg 提取码: xqei选择连接右键 新建数据库 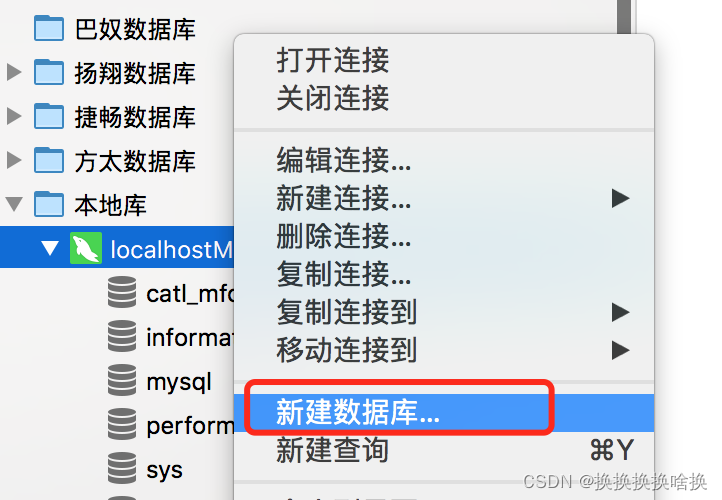 新建 填写数据库名称 train_demo 、字符集选utf8、排序规则:utf8_general_ci ,点击确定 新建 填写数据库名称 train_demo 、字符集选utf8、排序规则:utf8_general_ci ,点击确定 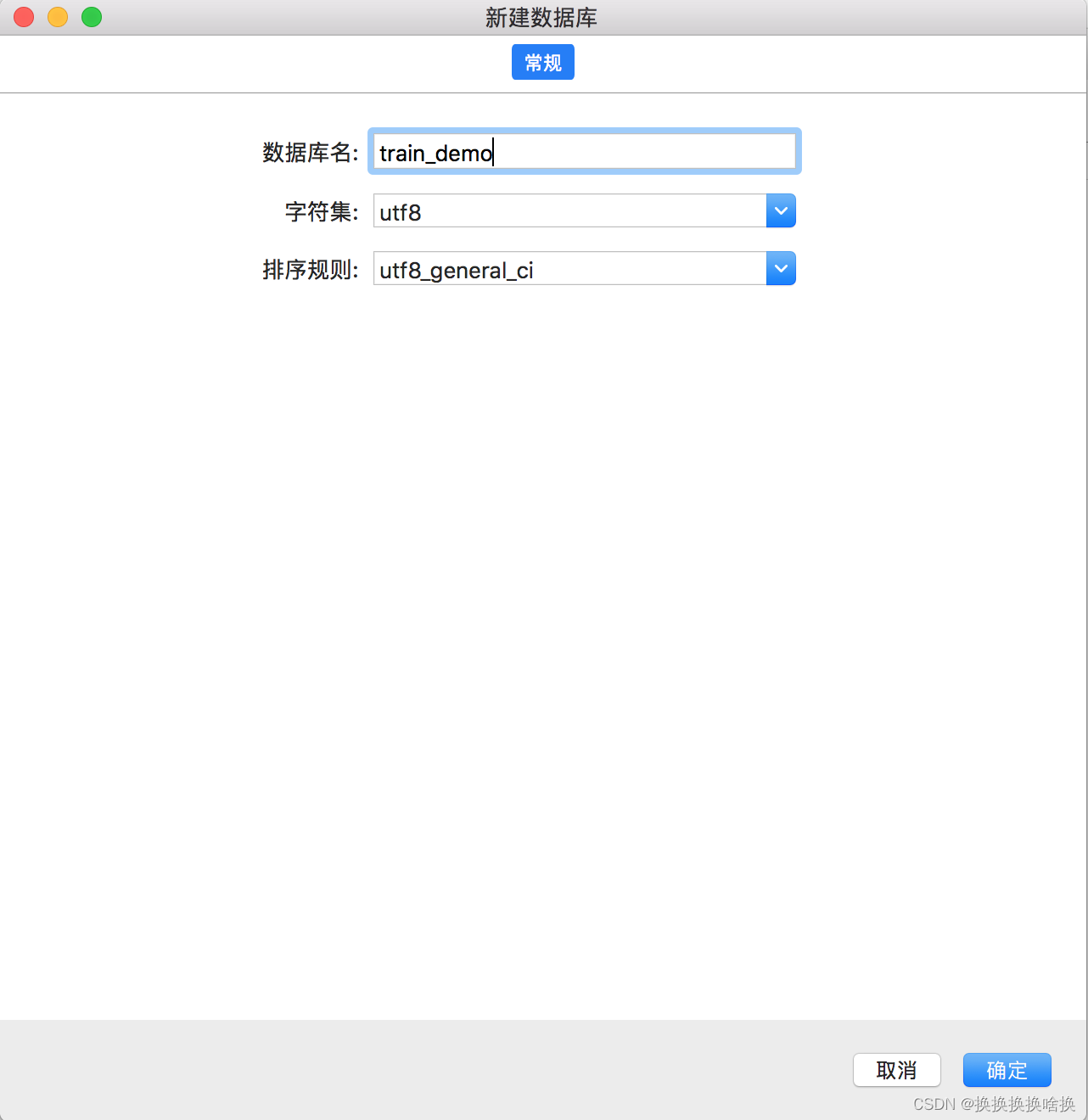 双击新建数据库,点击右键运行SQL文件 双击新建数据库,点击右键运行SQL文件 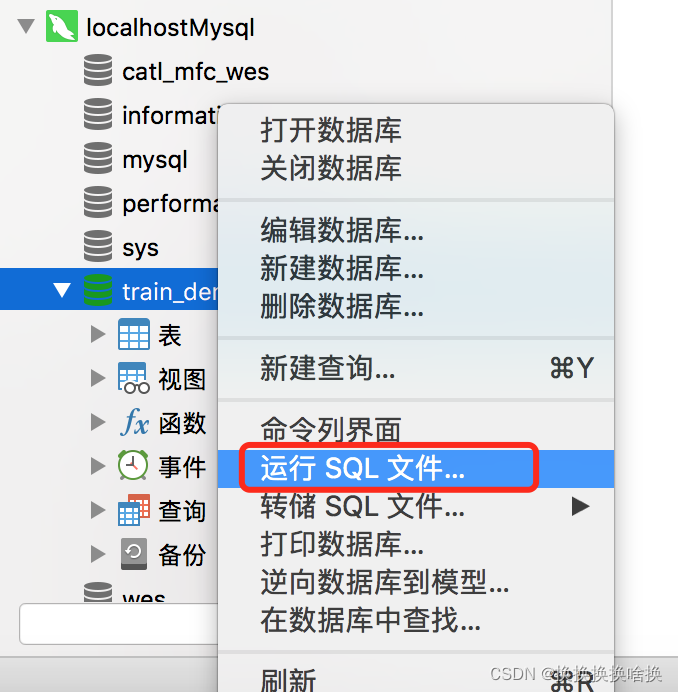 选择已下载的培训数据库脚本,点击开始 选择已下载的培训数据库脚本,点击开始 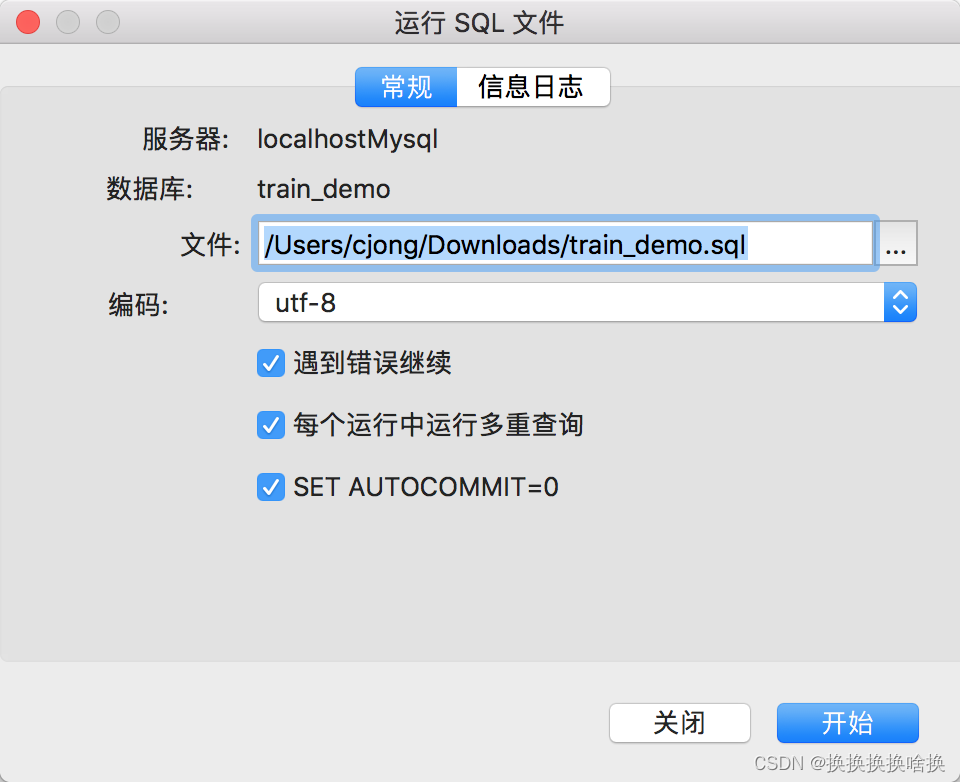 显示成功后,点击关闭。 显示成功后,点击关闭。 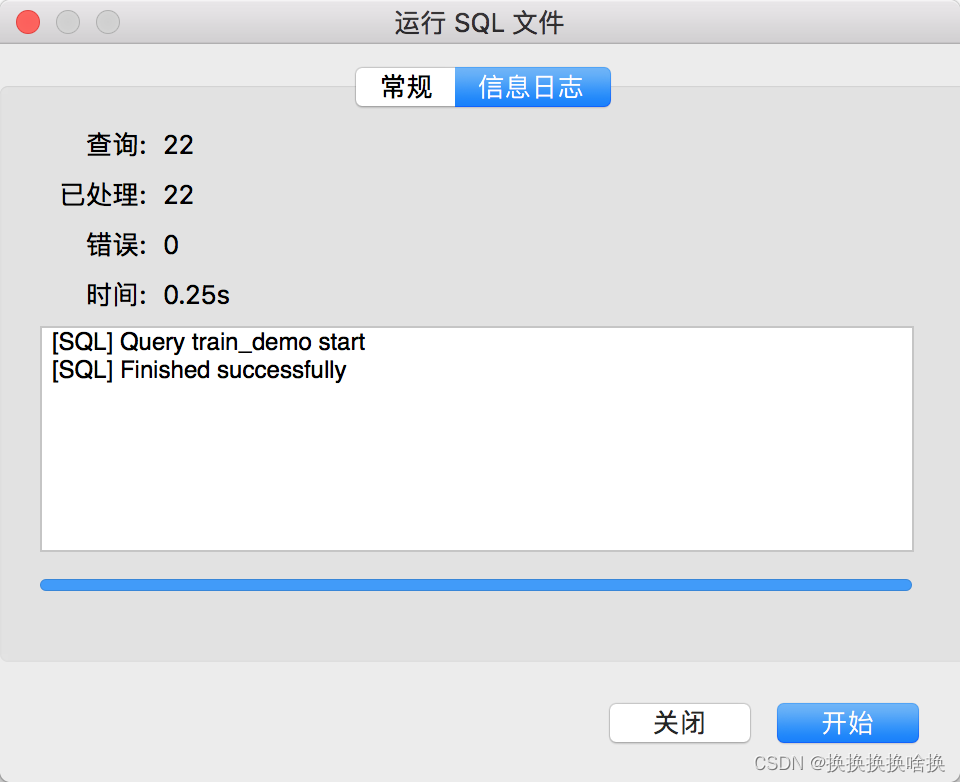 此时可以看到培训数据库表已生成。 此时可以看到培训数据库表已生成。 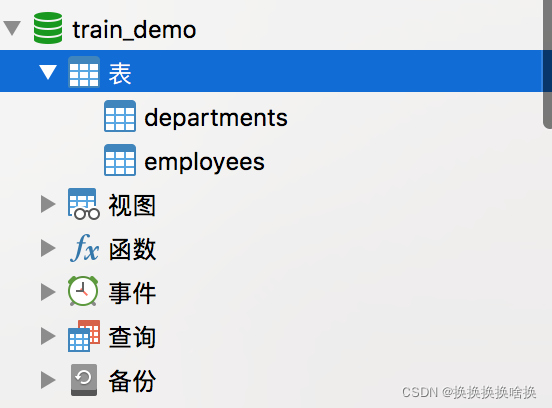 sql语法使用手册会使用当前培训数据库。
1.2工具如果使用
我们双击左侧的连接,选择使用的数据库,本文例子培训数据库train_demo,然后选择表看到右侧出来所有的表信息。 sql语法使用手册会使用当前培训数据库。
1.2工具如果使用
我们双击左侧的连接,选择使用的数据库,本文例子培训数据库train_demo,然后选择表看到右侧出来所有的表信息。 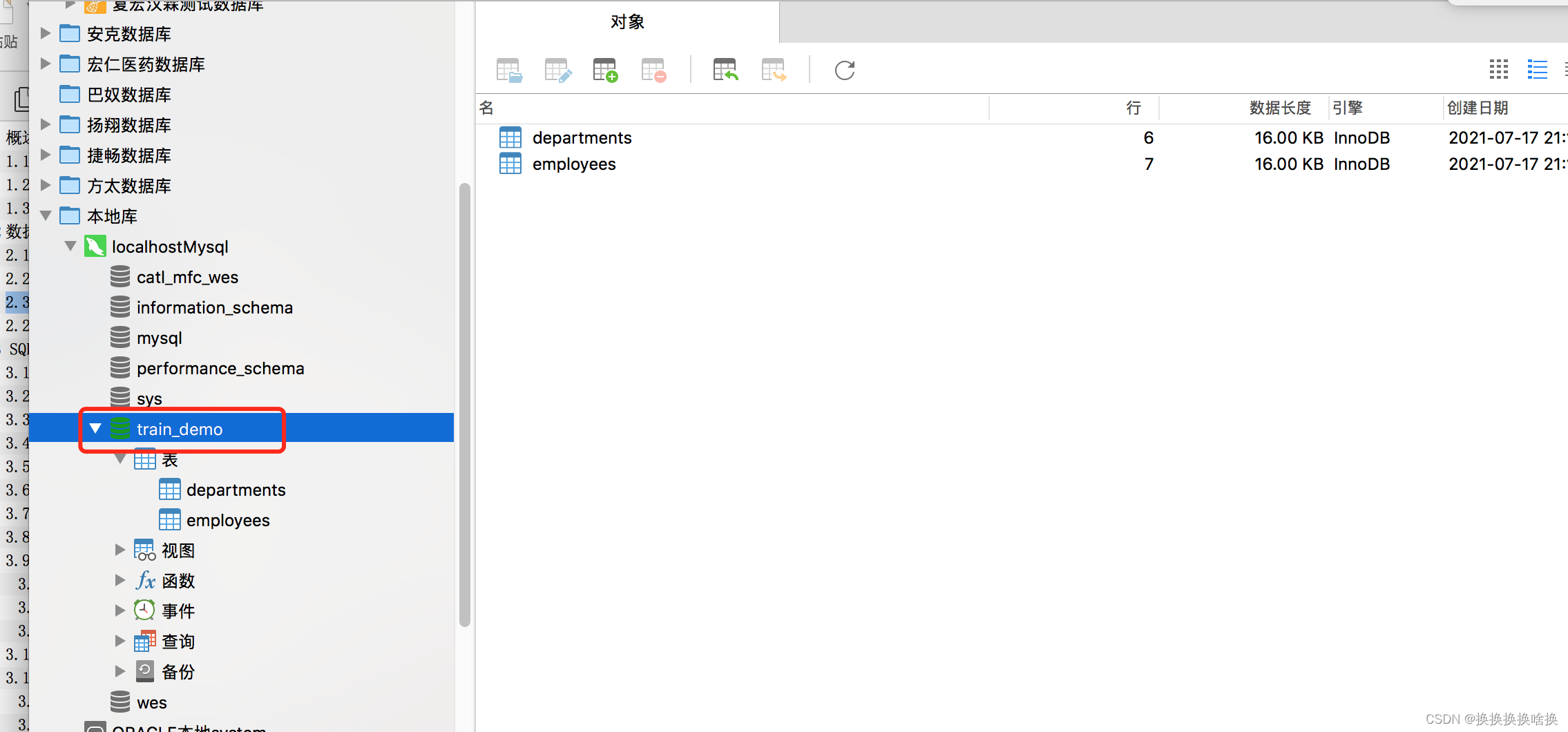 如果我们想看表的数据信息,可以双击表名信息,也可以选择右键,打开表。如下图所示 如果我们想看表的数据信息,可以双击表名信息,也可以选择右键,打开表。如下图所示 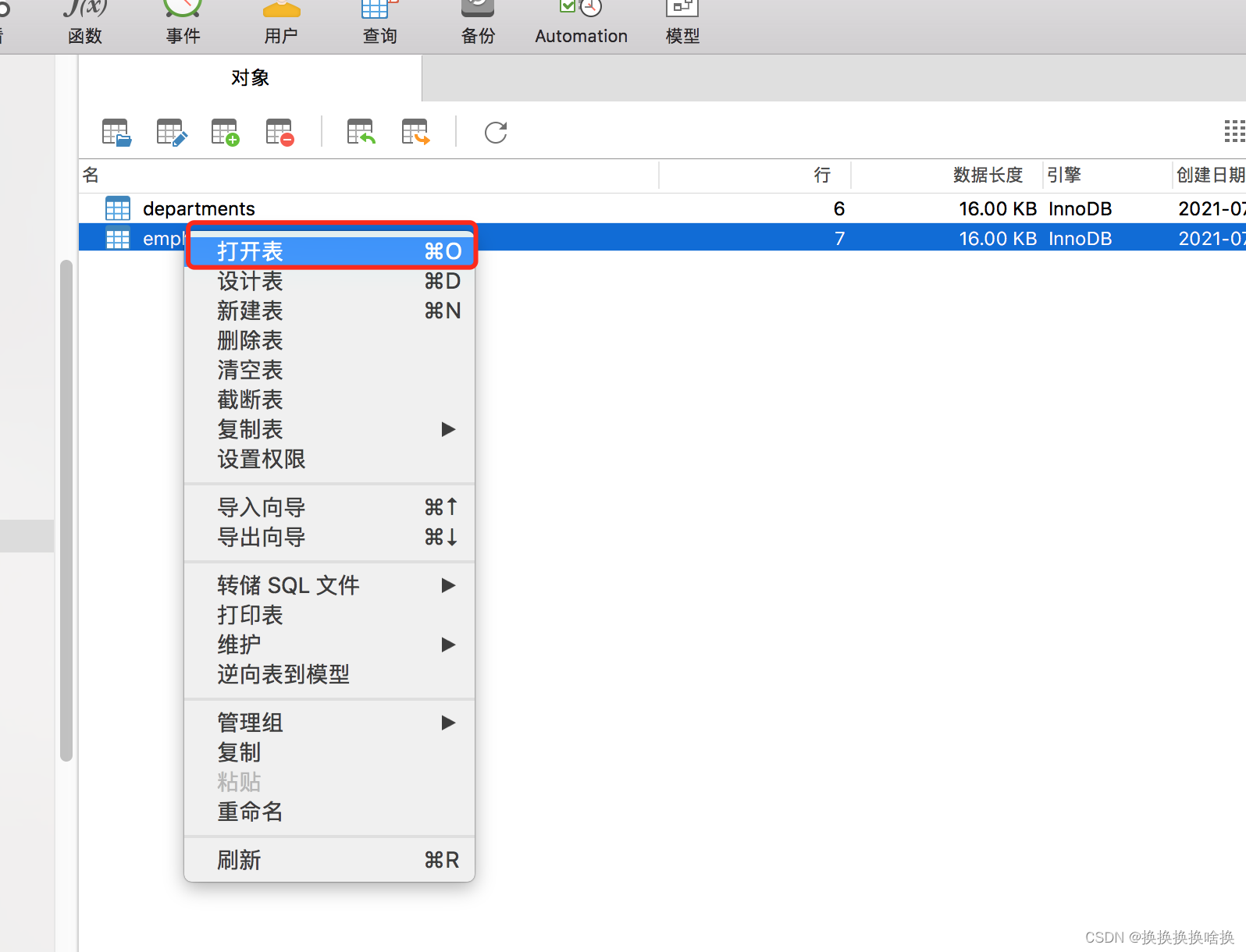 当打开表的数据信息,可以增加数据、修改数据、修改数据,如果想修改数据直接修改后点击保存即可。 当打开表的数据信息,可以增加数据、修改数据、修改数据,如果想修改数据直接修改后点击保存即可。 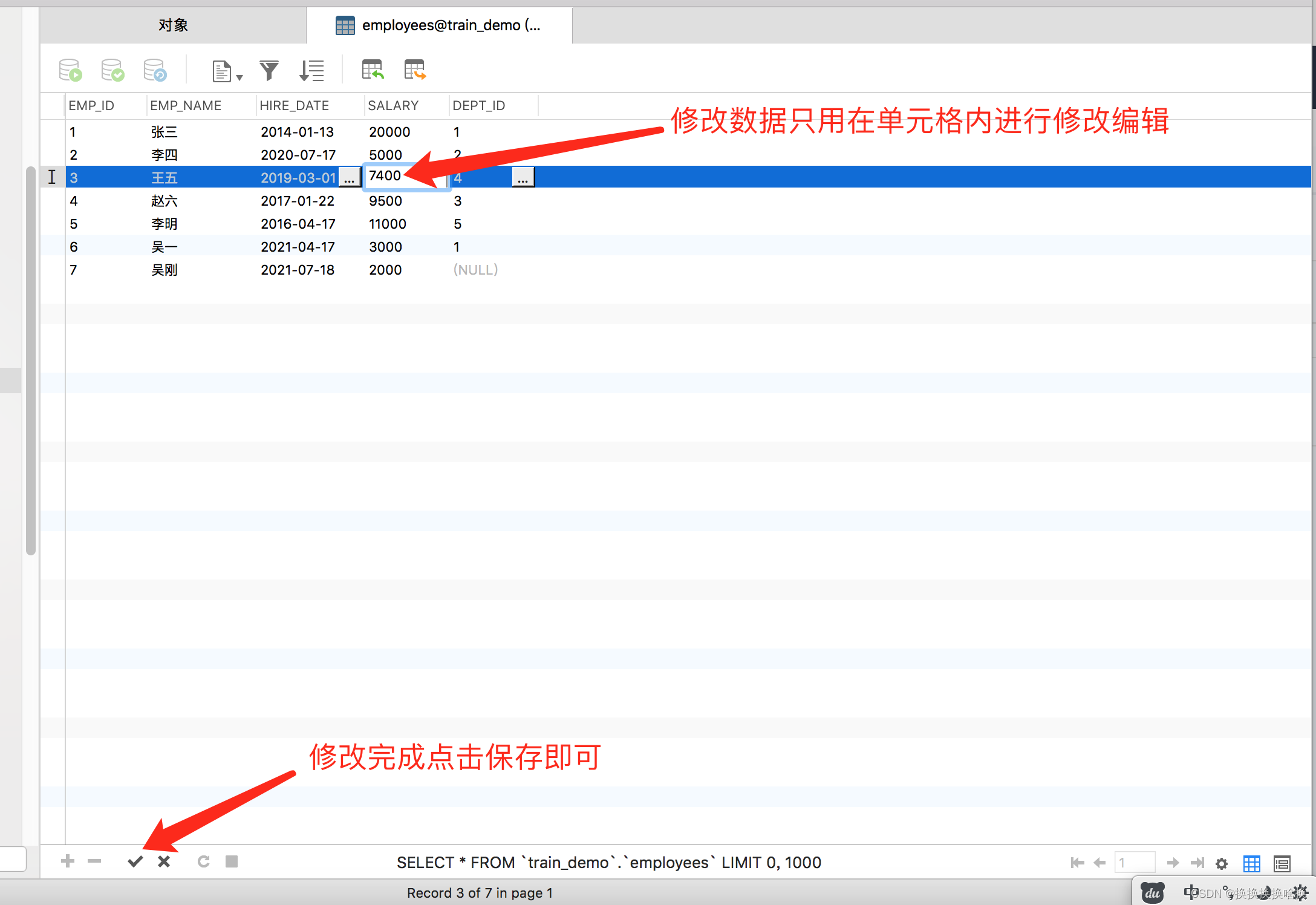 按钮说明 按钮说明  打开表之后如何进行数据塞选,查找自己想要的数据。 例如选择base_order表打开点击筛选点击添加,一般情况下直接根据ID也就是页面的序号进行筛选,在问号处填入序号ID后点击确定,比如1 打开表之后如何进行数据塞选,查找自己想要的数据。 例如选择base_order表打开点击筛选点击添加,一般情况下直接根据ID也就是页面的序号进行筛选,在问号处填入序号ID后点击确定,比如1 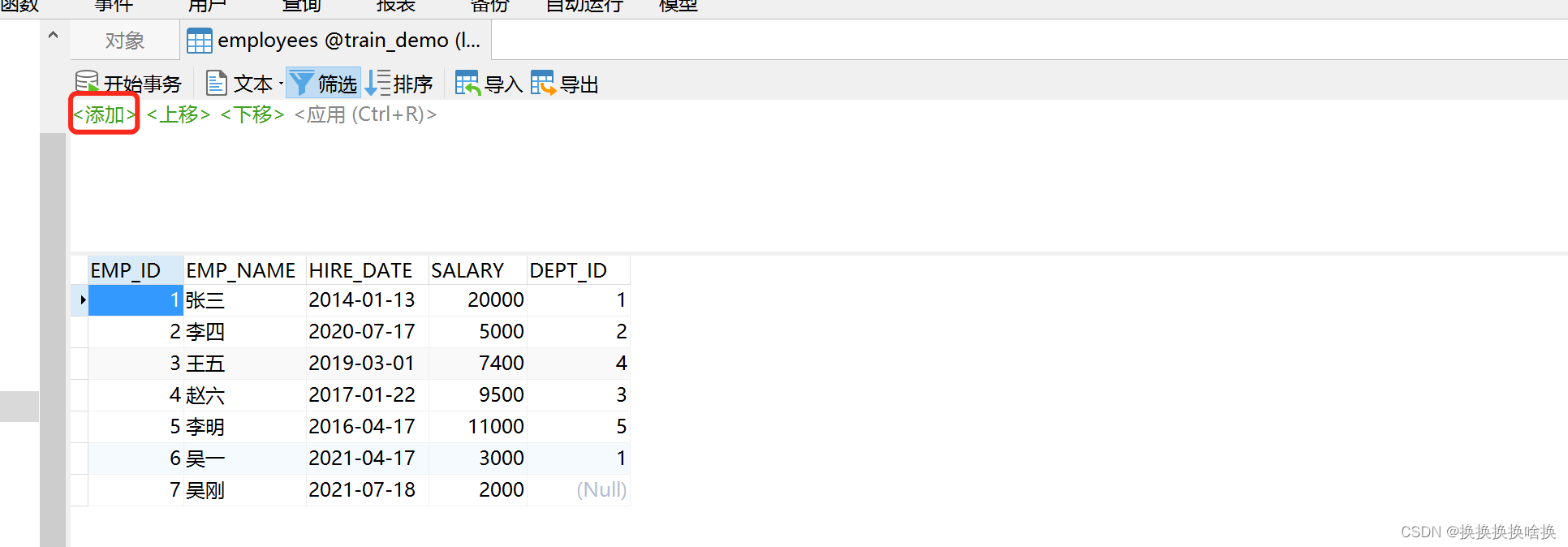 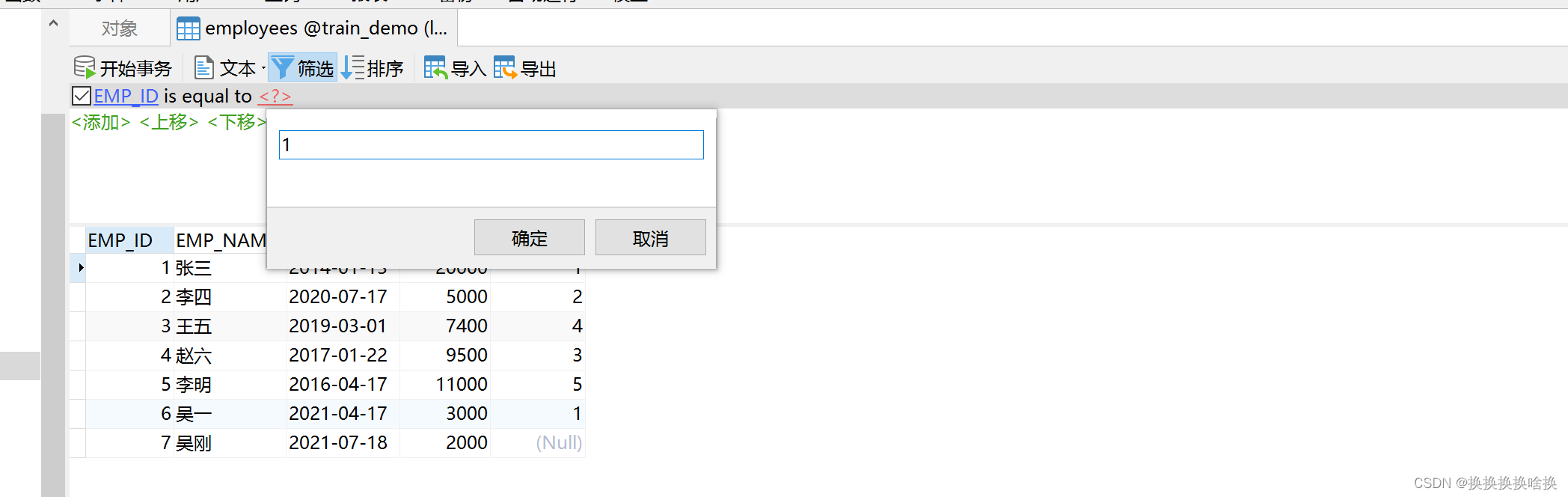 然后点击应用 然后点击应用 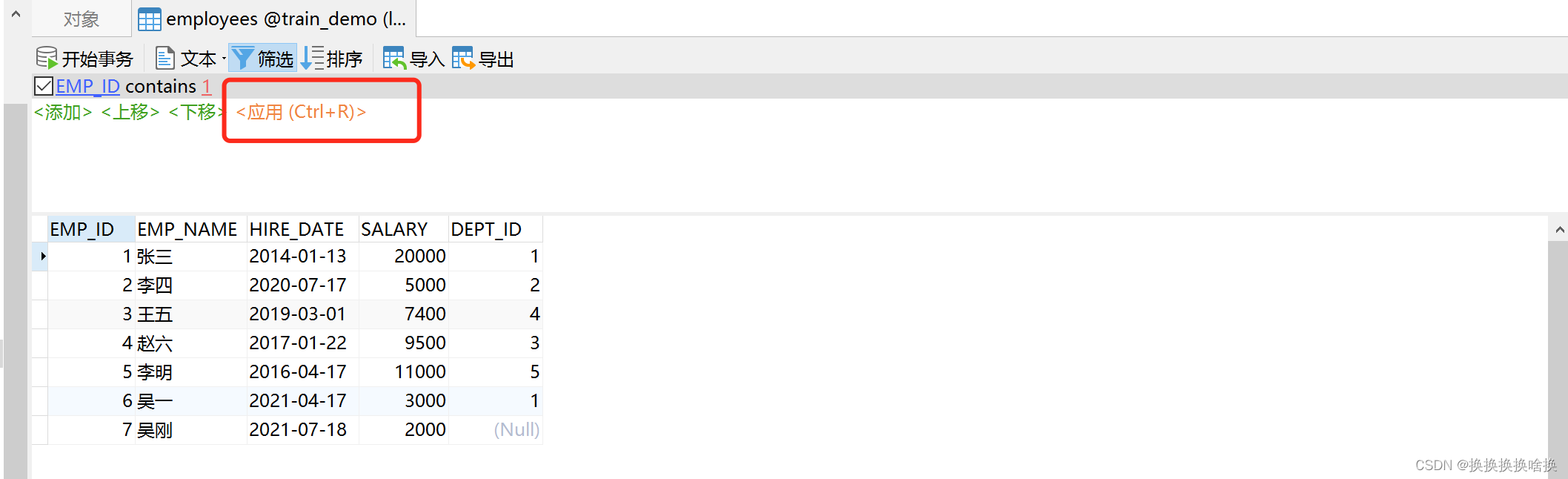 查询后结果如下图 查询后结果如下图 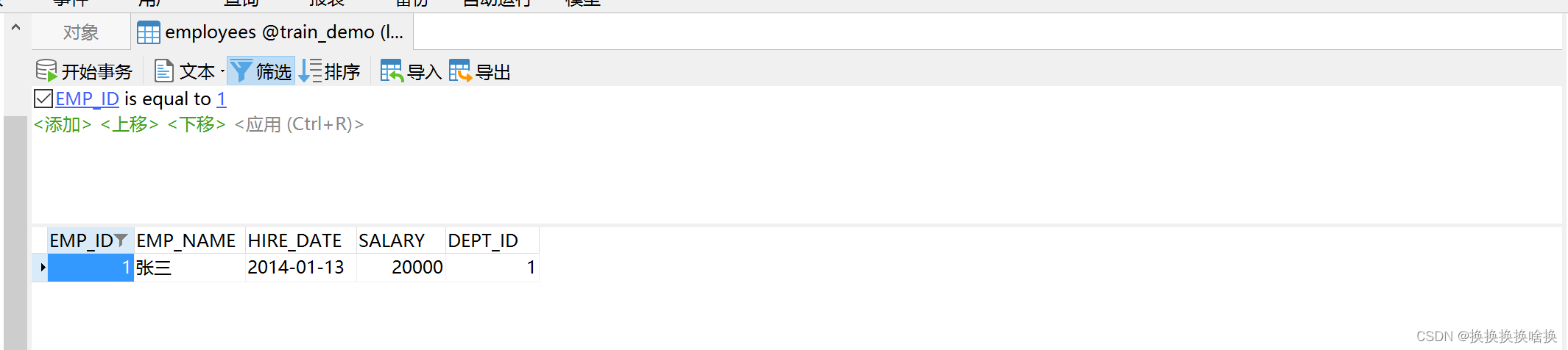 然后如果需要修改或者删除数据通过之前的操作步骤即可。 如果需要更换查询条件点击ID后选择相应查询字段比如状态emp_name查询。 然后如果需要修改或者删除数据通过之前的操作步骤即可。 如果需要更换查询条件点击ID后选择相应查询字段比如状态emp_name查询。 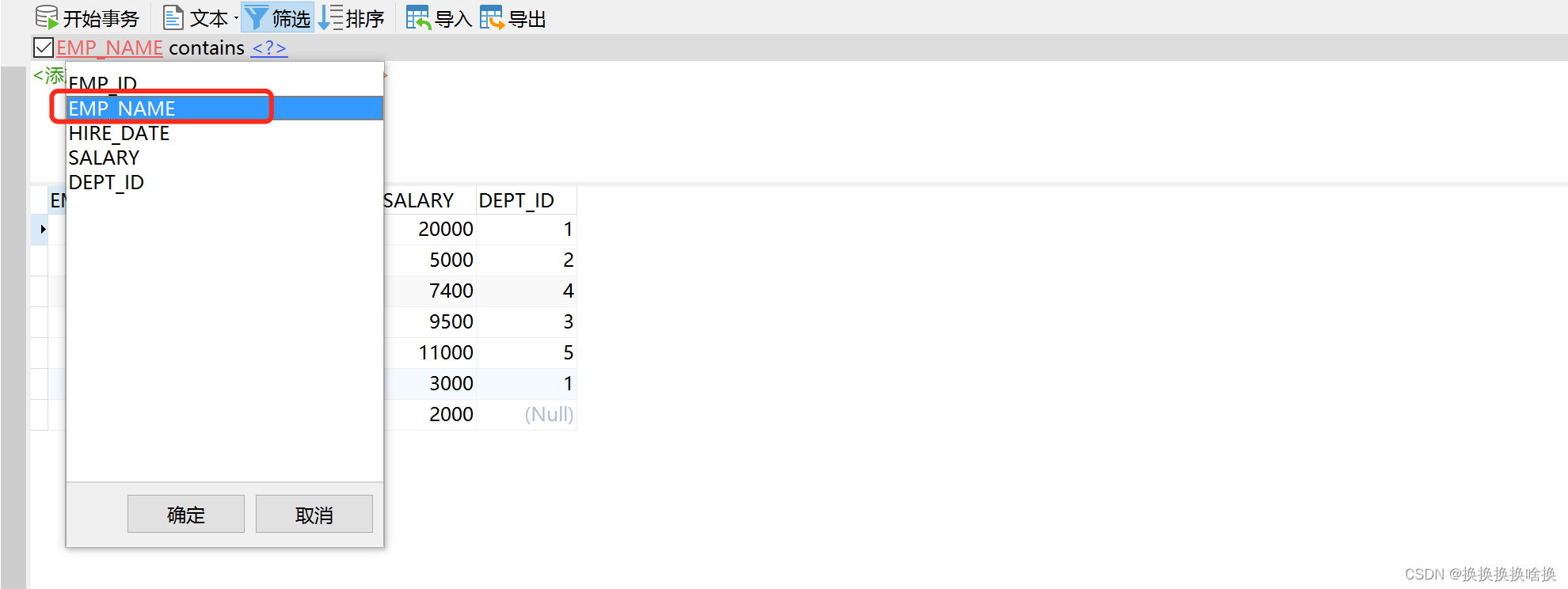 多个条件筛选继续点击添加即可。比如根据员工名称和部门ID查询 多个条件筛选继续点击添加即可。比如根据员工名称和部门ID查询  以下为常用的条件 以下为常用的条件   以上为通过工具进行条件查询单个表中数据。并可以修改或删除相关数据。(调整数据请核对清楚再操作,一定要核对页面的序号和数据库工具的表的id是否一致)
1.3用工具执行查询语句
用工具进行语句查询,选择数据库 ctrl+Q(快捷键)或者-右键 新建 查询 以上为通过工具进行条件查询单个表中数据。并可以修改或删除相关数据。(调整数据请核对清楚再操作,一定要核对页面的序号和数据库工具的表的id是否一致)
1.3用工具执行查询语句
用工具进行语句查询,选择数据库 ctrl+Q(快捷键)或者-右键 新建 查询  弹出便捷查询对话框 弹出便捷查询对话框  例如根据姓名查询员工 select * from employees where EMP_NAME=‘张三’; 例如根据姓名查询员工 select * from employees where EMP_NAME=‘张三’;  选中查询语句点击查询按钮 选中查询语句点击查询按钮  弹出查询结果 弹出查询结果 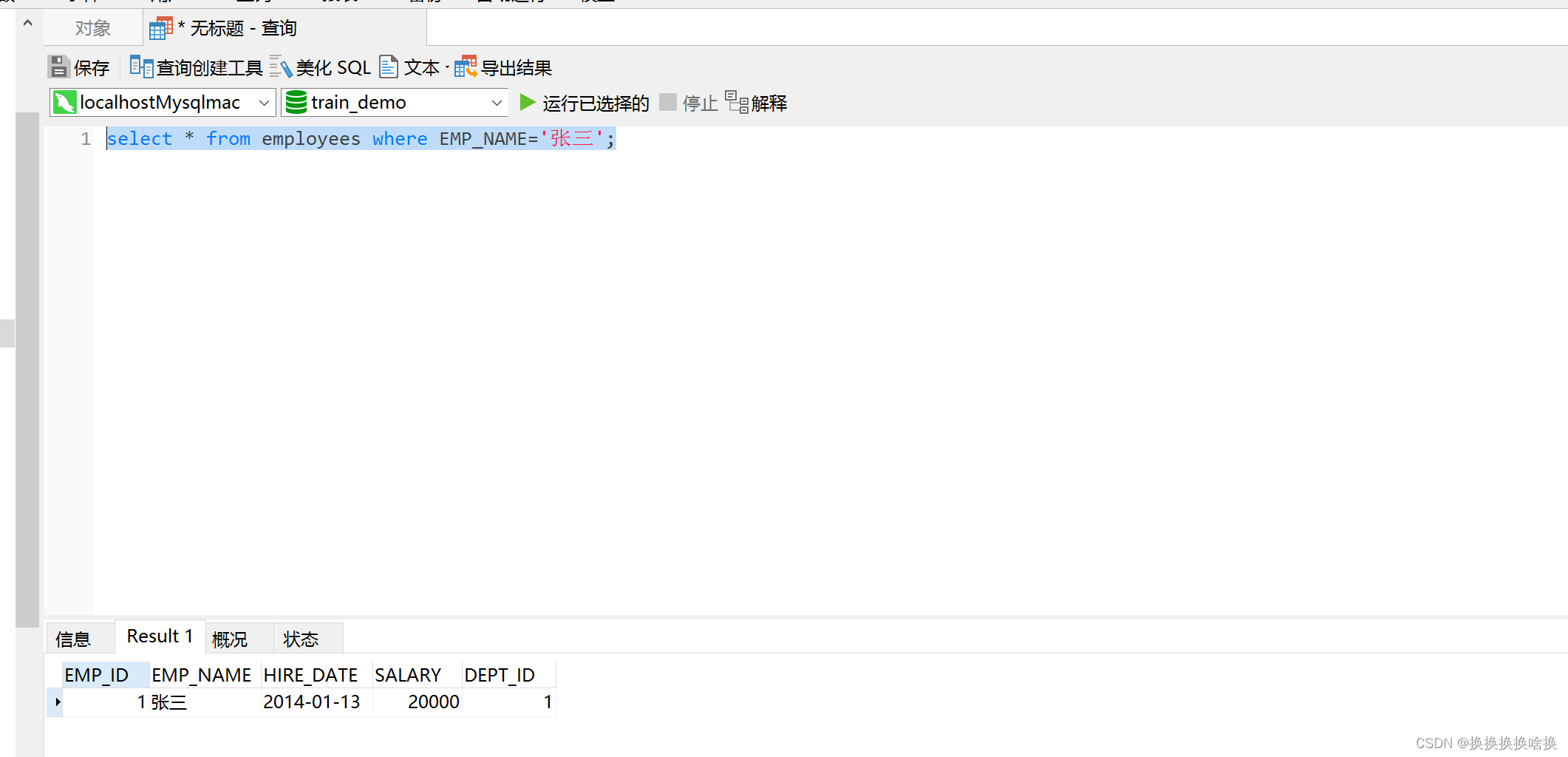 SQL语法
2.1简介
SQL语法
2.1简介
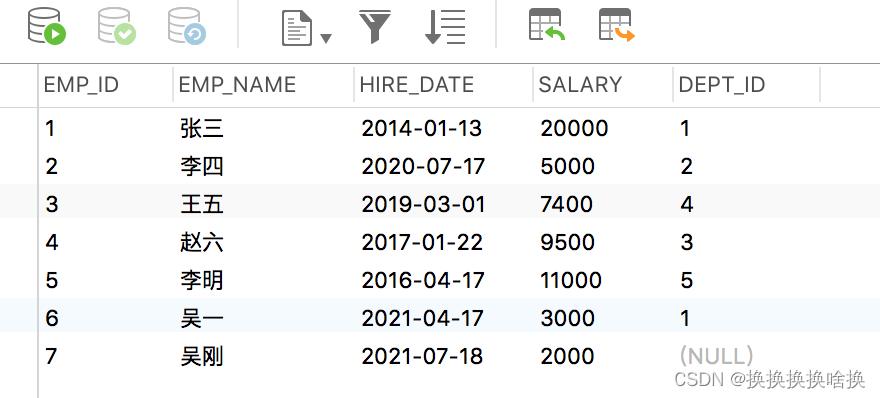
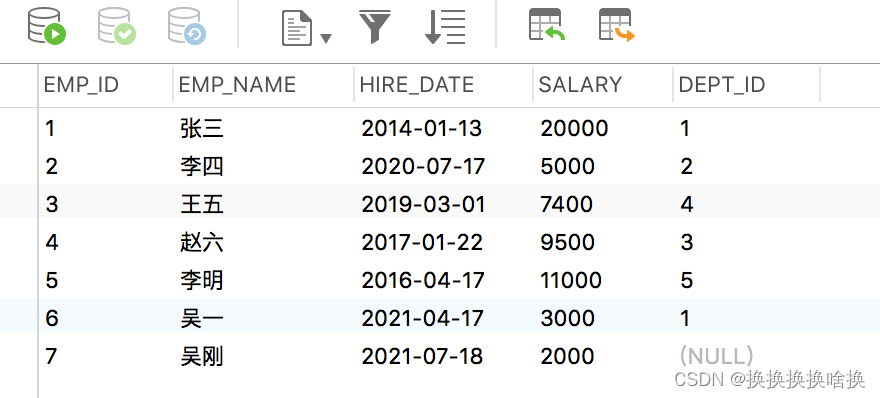
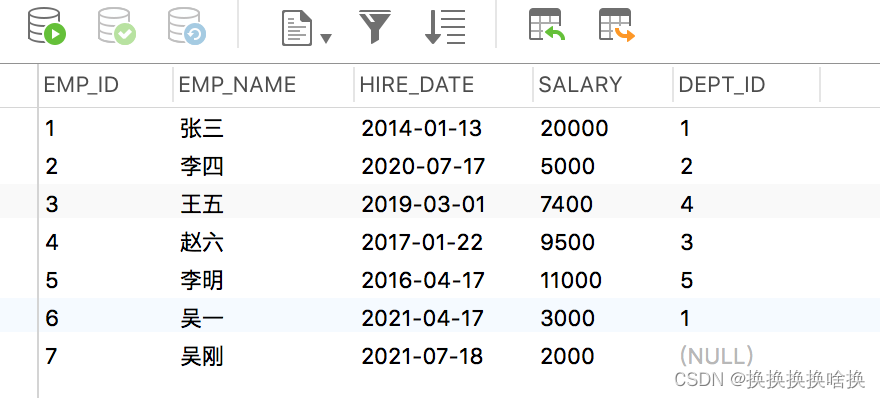
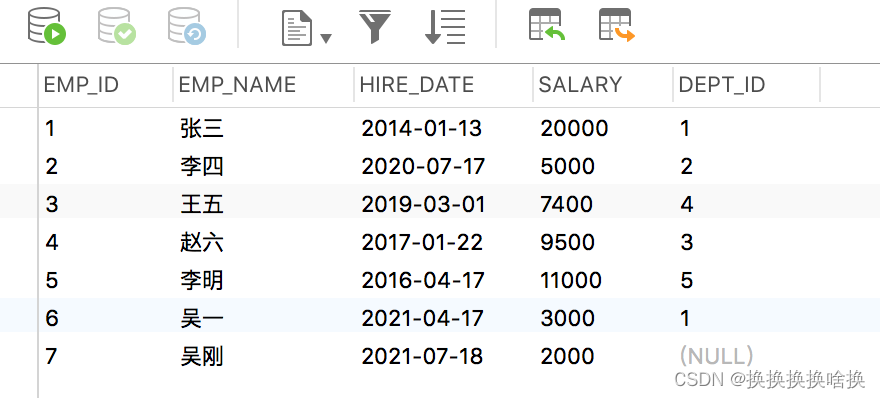
SQL是设计用于在关系数据库管理系统中管理数据的标准语言。 SQL表示结构化查询语言。SQL是一种标准编程语言,专门设计用于在关系数据库管理系统(RDBMS)内存储,检索,管理或处理数据。SQL于1987年成为ISO标准。 SQL是使用最广泛的数据库语言,并受到流行的关系数据库系统(例如MySQL,SQL Server和Oracle)的支持。但是,SQL标准的某些功能在不同的数据库系统中以不同的方式实现。 SQL最初是在1970年代初期在IBM开发的。最初,它被称为SEQUEL(结构化英语查询语言),后来被更改为SQL(发音为SQL)。 2.2 SQL 查询数据 (SELECT 语句)先通过第3章navicat使用手册学习新建培训数据库。 从表中选择数据的基本语法可以通过以下方式给出: SELECT column1_name, column2_name, columnN_name FROM table_name; 在这里,column1_name,column2_name,…是您要获取其值的数据库表的列或字段的名称。但是,如果要获取表中所有可用列的值,则可以使用以下语法: SELECT * FROM table_name; 让我们将这些语句投入实际使用。假设我们在数据库中有一个名为employees的表,其中包含以下记录: SELECT * FROM employees; 执行后,输出将如下所示:  正如您看到的,这一次在结果集中没有dept_id列
2.3 SQL WHERE 子句 正如您看到的,这一次在结果集中没有dept_id列
2.3 SQL WHERE 子句
根据条件选择记录 WHERE子句与SELECT 语句一起使用,仅提取满足指定条件的那些记录。 基本语法可以通过以下方式给出: SELECT column_list FROM table_name WHERE condition; 在这里,column_list是要获取其值的数据库表的列/字段的名称,例如name,age,country等。 但是,如果要获取表中所有可用列的值,则可以使用以下语法: SELECT * FROM table_name WHERE condition; 现在,让我们看一些示例来演示其实际工作原理。 假设我们在数据库中有一个名为employees的表,其中包含以下记录: 使用WHERE子句过滤记录 以下SQL语句将从employees表中返回其薪水大于7000的所有employee 该WHERE子句只是过滤掉不需要的数据。 SELECT * FROM employees WHERE salary > 7000; 执行后,输出将如下所示: SQL支持许多可在WHERE子句中使用的运算符,下表总结了最重要的运算符。 操作员描述在线示例=等于WHERE id = 2 30>少于WHERE age < 18>=大于或等于大于或等于 WHERE rating >= 4 7000 OR dept_id = 1; 这次您将获得如下输出: 同时使用AND与OR运算符 您还可以组合 AND 和 OR 创建复杂的条件表达式。 以下SQL语句将返回薪水大于5000,并且dept_id等于1或5的所有雇员。 SELECT * FROM employees WHERE salary > 5000 AND (dept_id = 1 OR dept_id = 5); 执行完上面的查询后,您将获得如下输出: 同时使用AND与OR运算符 您还可以组合 AND 和 OR 创建复杂的条件表达式。 以下SQL语句将返回薪水大于5000,并且dept_id等于1或5的所有雇员。 SELECT * FROM employees WHERE salary > 5000 AND (dept_id = 1 OR dept_id = 5); 执行完上面的查询后,您将获得如下输出: 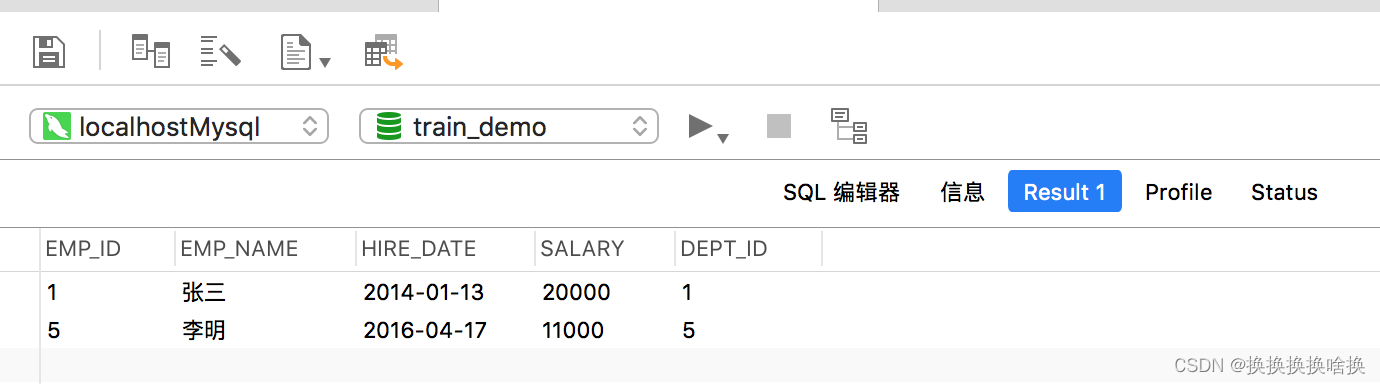 2.5 SQL IN & BETWEEN 运算符
IN运算符
2.5 SQL IN & BETWEEN 运算符
IN运算符
IN运算符是逻辑运算符,用于检查一组值中是否存在特定值。 其基本语法可以通过以下方式给出: SELECT column_list FROM table_name WHERE column_name IN (value1, value1,…); 在这里,column_list是要获取其值的数据库表的列/字段的名称,例如name,age,country等。好吧,让我们看看一些实例。 考虑我们在数据库中有一个employees表,该表具有以下记录: 如果列中的值落在特定范围内,有时您想选择一行。处理数字数据时,这种类型的条件很常见。 要基于这种条件执行查询,您可以利用BETWEEN运算符。它是一个逻辑运算符,可让您指定要测试的范围,如下所示: SELECT column1_name, column2_name, columnN_name FROM table_name WHERE column_name BETWEEN min_value AND max_value; 让我们根据雇员(employees)表上的范围条件构建和执行查询。 定义数值范围 以下SQL语句将仅返回employees表中薪水在7000到9000之间的那些雇员。 SELECT * FROM employees WHERE salary BETWEEN 7000 AND 9000; 执行后,您将获得如下输出: 将BETWEEN运算符与日期或时间值一起使用时,请使用==CAST()==函数将这些值显式转换为所需的数据类型,以获得最佳结果。例如,如果在与DATE的比较中使用诸如“ 2016-12-31”之类的字符串,则将其转换为DATE,如下所示: 以下SQL语句选择2016年1月1日(即“ 2016-01-01”)至2018年12月31日(即“ 2018-12-31”)之间雇用的所有雇员: SELECT * FROM employees WHERE hire_date BETWEEN CAST(‘2016-01-01’ AS DATE) AND CAST(‘2018-12-31’ AS DATE); 执行查询后,您将获得如下结果集: 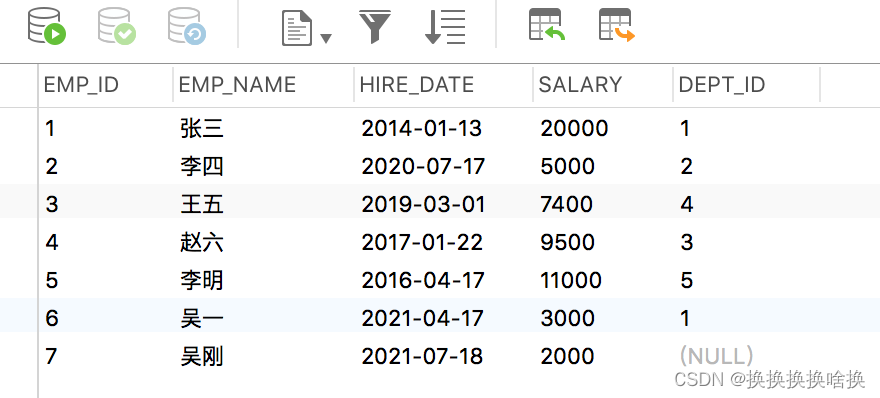 单列排序
单列排序
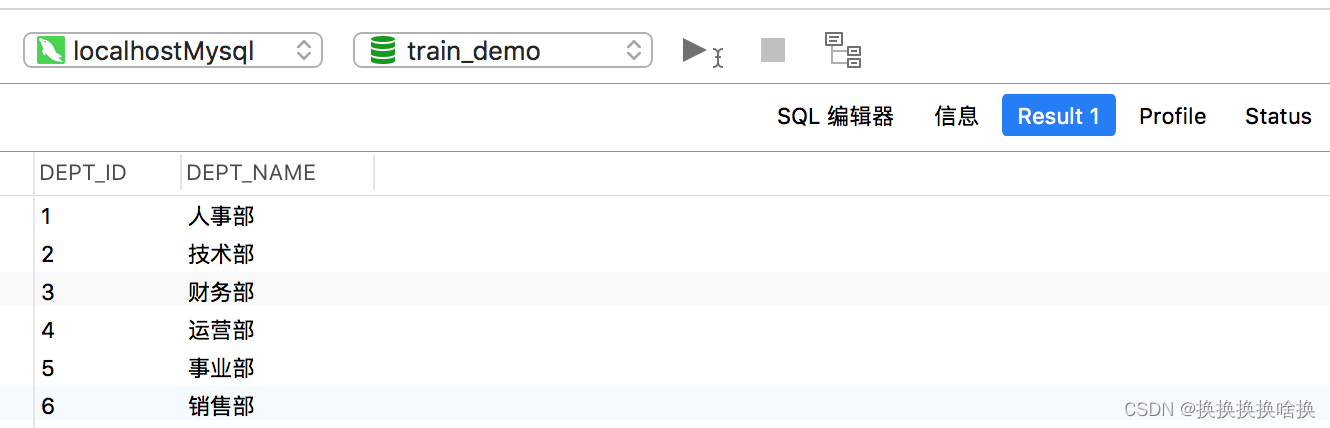
下面的SQL语句将从employees表中返回所有employee,并按emp_name列的升序对结果集进行排序。 SELECT * FROM employees ORDER BY emp_name ASC; 您可以跳过该ASC选项,而仅使用以下语法。它返回与上一条语句相同的结果集,因为SQL默认排序顺序是升序的: SELECT * FROM employees ORDER BY emp_name; 执行上述命令后,您将获得如下输出: 注意:当指定多个排序列时,结果集首先按第一列排序,然后按第二列对该有序列表排序,依此类推。 现在执行此语句,该语句按dept_id和salary列对结果集进行排序。 SELECT * FROM employees ORDER BY dept_id ASC,salary DESC; SQL LIMIT子句用于限制返回的行数。其基本语法为: SELECT column_list FROM table_name LIMIT number; 以下语句返回雇员(employees)表中收入最高的前三名雇员。 – MySQL 数据库的语法 SELECT * FROM employees ORDER BY salary DESC LIMIT 3; 执行后,您将获得如下输出: 在LIMIT子句中设置行偏移 LIMIT子句接受可选的第二个参数。 当指定了两个参数时,第一个参数指定要返回的第一行的偏移量,即起点,而第二个参数指定要返回的最大行数。初始行的偏移量是0(不是1)。 因此,如果要找出薪水第三高的员工,可以执行以下操作: – MySQL数据库的语法 SELECT * FROM employees ORDER BY salary DESC LIMIT 2, 1; 执行上述命令后,结果集中将仅获得一条记录: 从数据库表中获取数据时,结果集可能包含重复的行或值。 如果要删除这些重复的值,可以在SELECT关键字之后直接指定关键字DISTINCT,如下所示: SELECT DISTINCT column_list FROM table_name; 在这里,column_list是用逗号分隔的要获取其值的数据库表的列名或字段名的列表(例如name,age,country等)。 注意: DISTINCT子句的行为类似于UNIQUE约束,除了它对待null的方式不同。 两个NULL值被认为是唯一的,而同时又不认为它们是彼此不同的。 我们在数据库中有一个employees表,该表具有以下记录: SELECT dept_id FROM employees; 执行后,您将获得如下输出: 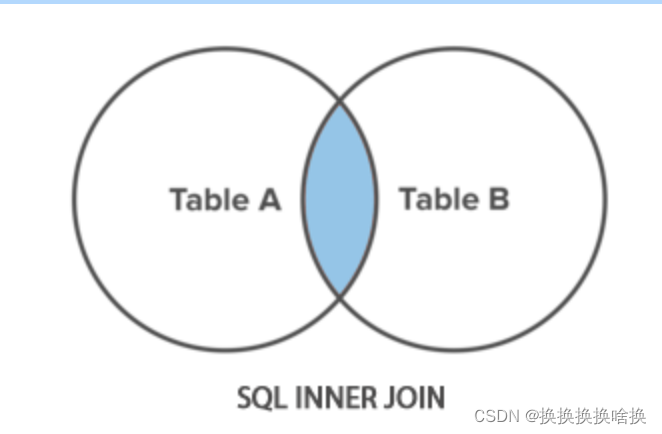 为了容易理解这一点,让我们来看看下面employees和departments表。在这里,employees表的dept id列是departments表的外键。因此,可以将这两个表连接起来,得到组合的数据。 为了容易理解这一点,让我们来看看下面employees和departments表。在这里,employees表的dept id列是departments表的外键。因此,可以将这两个表连接起来,得到组合的数据。  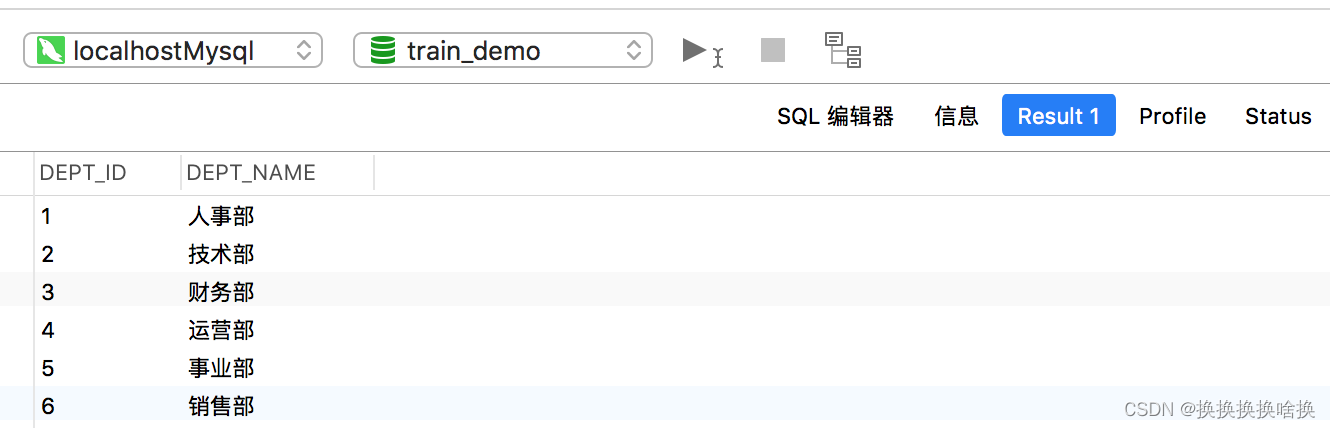 表: departments 现在,假设您只需要检索分配给特定部门的那些员工的emp_id ,emp_name,hire_date和dept_name。因为在实际情况中,可能有些雇员尚未分配到部门,例如我们employees表中的第七名雇员“吴刚” 。但是这里的问题是,如何在同一个SQL查询中从两个表中检索数据? 如果您看到employees表,您会注意到它有一个名为dept_id的列,该列保存每个雇员分配到的部门的ID,即按技术术语来说,employees表的dept_id列是departments表的外键, 因此,我们将使用此列作为这两个表之间的桥梁。 这是一个示例,该示例通过使用通用的dept_id列将employee 和departments表连接在一起来检索员工的id,姓名,雇用日期及其所属部门。 它不包括未分配给任何部门的那些雇员。 SELECT t1.emp_id, t1.emp_name, t1.hire_date, t2.dept_name FROM employees AS t1 INNER JOIN departments AS t2 ON t1.dept_id = t2.dept_id ORDER BY emp_id; 提示:联接表时,请在每个列名称前添加其所属表的名称(例如 employees.dept_id,departments.dept_id 或 t1.dept_id,t2.dept_id 如果您使用表别名),以避免万一不同表中的列存在混淆和歧义的列错误同名。 注意:为了节省时间,可以在查询中使用表别名代替键入长表名。 例如,您可以为employees表赋予别名t1,并使用t1.emp_name而不是employees.emp_name 来引用其列emp_name。执行完上述命令后,您将得到如下结果集: 表: departments 现在,假设您只需要检索分配给特定部门的那些员工的emp_id ,emp_name,hire_date和dept_name。因为在实际情况中,可能有些雇员尚未分配到部门,例如我们employees表中的第七名雇员“吴刚” 。但是这里的问题是,如何在同一个SQL查询中从两个表中检索数据? 如果您看到employees表,您会注意到它有一个名为dept_id的列,该列保存每个雇员分配到的部门的ID,即按技术术语来说,employees表的dept_id列是departments表的外键, 因此,我们将使用此列作为这两个表之间的桥梁。 这是一个示例,该示例通过使用通用的dept_id列将employee 和departments表连接在一起来检索员工的id,姓名,雇用日期及其所属部门。 它不包括未分配给任何部门的那些雇员。 SELECT t1.emp_id, t1.emp_name, t1.hire_date, t2.dept_name FROM employees AS t1 INNER JOIN departments AS t2 ON t1.dept_id = t2.dept_id ORDER BY emp_id; 提示:联接表时,请在每个列名称前添加其所属表的名称(例如 employees.dept_id,departments.dept_id 或 t1.dept_id,t2.dept_id 如果您使用表别名),以避免万一不同表中的列存在混淆和歧义的列错误同名。 注意:为了节省时间,可以在查询中使用表别名代替键入长表名。 例如,您可以为employees表赋予别名t1,并使用t1.emp_name而不是employees.emp_name 来引用其列emp_name。执行完上述命令后,您将得到如下结果集: 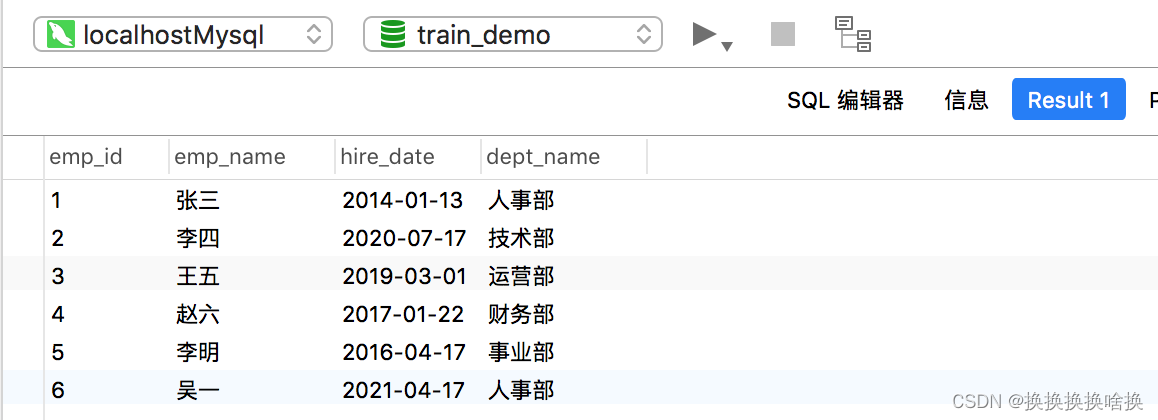 正如您看到的,结果集仅包含具有dept_id值的雇员,并且该值也存在于department表的dept_id列中
2.9.2 LEFT JOIN 语句 正如您看到的,结果集仅包含具有dept_id值的雇员,并且该值也存在于department表的dept_id列中
2.9.2 LEFT JOIN 语句
一条LEFT JOIN语句返回左表中的所有行以及右表中满足连接条件的行。左联接是外部联接的一种,因此也被称为left outer join。外部联接的其他变体是右联接和完全联接。 下维恩图说明了左联接的工作方式。 为了清楚地理解这一点,让我们来看看下面employees和departments表。 现在,假设您要检索所有雇员的ID,姓名和雇用日期以及他们的部门名称,而不管他们是否分配到任何部门。为了获得这种类型的结果集,我们需要应用左连接。 以下语句通过使用公用字段将员工(employees)和departments(部门)表连接在一起来检索员工的ID,姓名,雇用日期及其部门名称dept_id。它还包括未分配到部门的那些雇员。 SELECT t1.emp_id, t1.emp_name, t1.hire_date, t2.dept_name FROM employees AS t1 LEFT JOIN departments AS t2 ON t1.dept_id = t2.dept_id ORDER BY emp_id; 提示:在联接查询中,左表是该JOIN子句中最左侧出现的表,而右表是该子句中最右侧出现的表。 RIGHT JOIN是与LEFT JOIN完全相反。它返回右表中的所有行以及左表中满足连接条件的行。 右连接是外连接的一种,因此也被称为right outer join。外部联接的其他变体是左联接和完全联接。下维恩图说明了右联接的工作方式。 现在,假设您要检索所有部门的名称以及在该部门工作的员工的详细信息。但是,在实际情况下,可能有些部门目前没有员工在工作。好吧,让我们找出答案。 以下语句通过使用通用的dept_id字段将employee和department表连接在一起,检索所有可用部门以及该部门员工的id,名称,雇用日期。 提示:在联接查询中,左边的表是在JOIN子句中最左边出现的表,右边的表是在最右边出现的表。 执行上述命令后,您将获得如下输出: 到目前为止,您已经看到了标识确切字符串的条件,例如WHERE name=‘Lois Lane’。但是在SQL中,您也可以使用LIKE运算符执行部分或模式匹配。 LIKE运算符允许您为一个或多个字符指定通配符提供模式匹配的度量。您可以使用以下两个通配符: ● 百分号(%) - 匹配任意数量的字符,甚至零个字符。 ● 下划线(_) - 完全匹配一个字符 这是一些示例,显示了如何将LIKE运算符与通配符一起使用。 声明含义返回值WHERE name LIKE ‘Da%’查找以Da开头的名字David, DavidsonWHERE name LIKE ‘%th’查找以th结尾的名字查找以th结尾的名字 Elizabeth, SmithWHERE name LIKE ‘%on%’查找包含on的名字Davidson, ToniWHERE name LIKE ‘Sa_’查找以Sa开头且最多后跟一个字符的名字SaWHERE name LIKE ‘_oy’查找以oy结尾且最多包含一个字符的名字Joy, RoyWHERE name LIKE ‘an’查找包含an的名字,并以一个字符开头和结尾Dana, HansWHERE name LIKE ‘%ar_’查找包含ar的名字,该名字以任意数量的字符开头,并以最多一个字符结尾Richard, KarlWHERE name LIKE ‘_ar%’查找包含ar的名字,最多以一个字符开头,以任意数量的字符结尾Karl, Mariya通过搜索一些记录,让我们将上面讨论的语句投入实际应用中。 考虑我们employees在数据库中有一个包含以下记录的表: 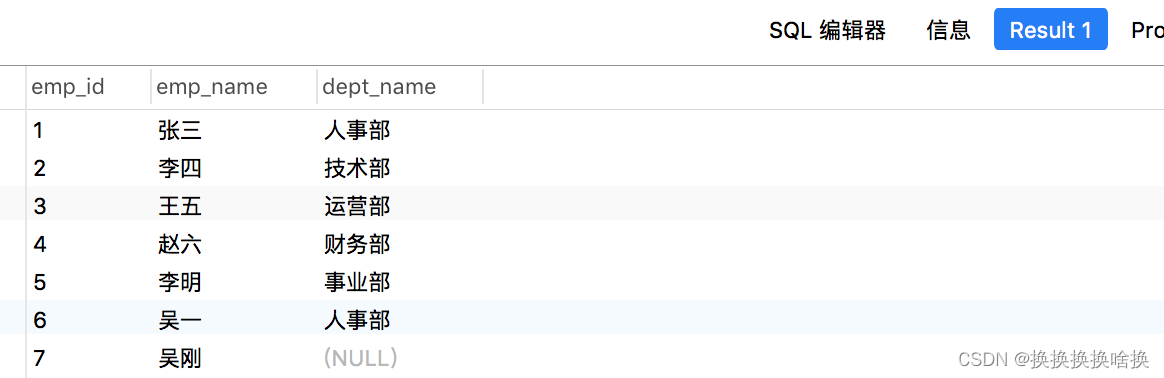 正如您看到的,使用表别名可以节省多少打字工作。
2.11.2定义表列的别名 正如您看到的,使用表别名可以节省多少打字工作。
2.11.2定义表列的别名
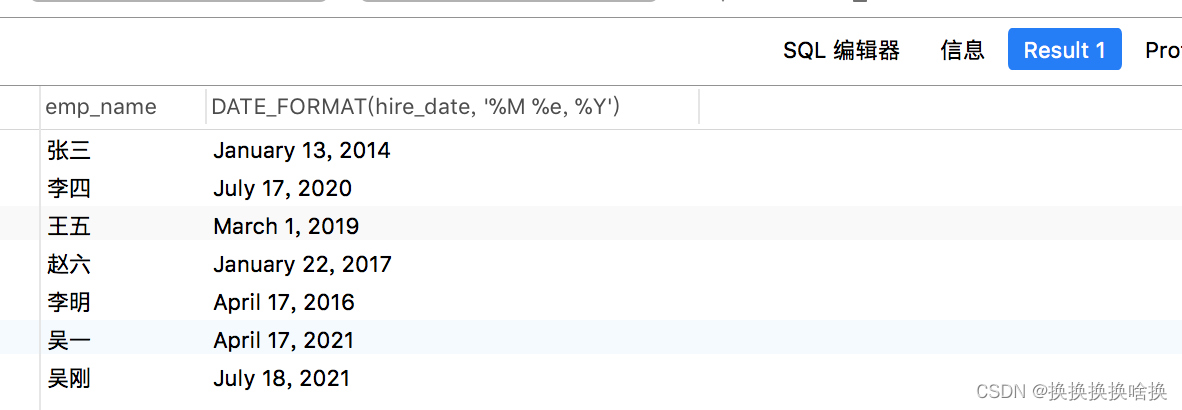
在MySQL中,当您使用SQL函数生成自定义输出时,输出列的名称可能难以理解或难以理解。在这种情况下,您可以使用别名为输出列临时命名。 考虑以下查询,在该查询中我们使用表达式重新格式化了hire_date列中的日期以生成自定义输出: – MySQL数据库的语法 SELECT emp_name, DATE_FORMAT(hire_date, ‘%M %e, %Y’) FROM employees; 如果执行上面的语句,您将获得如下输出: GROUP BY子句与SELECT语句和聚合函数结合使用,以按通用列值将行分组在一起 为了清楚地理解这一点,让我们来看看下面employees和departments表。 如果执行上面的语句,您将获得如下输出: 注意:在SQL SELECT语句中,GROUP BY子句必须出现在FROM和WHERE子句之后,并且出现在ORDER BY之前。 2.13 HAVING 子句根据条件过滤组 HAVING子句通常与GROUP BY子句一起使用,以指定组或集合的过滤条件。HAVING子句只能与SELECT语句一起使用。 为了清楚地理解这一点,让我们来看看下面employees和departments表。 表: departments 现在,不只是查找员工及其部门的名称,还要查找没有员工的部门的名称。 对于小型表,您可以简单地应用左连接并手动检查每个部门,但是假设一个表包含数千名员工,那将不是那么容易。 在这种情况下,可以将HAVING子句与GROUP BY子句一起使用,如下所示: SELECT t1.dept_name, count(t2.emp_id) AS total_employees FROM departments AS t1 LEFT JOIN employees AS t2 ON t1.dept_id = t2.dept_id GROUP BY t1.dept_name HAVING total_employees = 0; 如果执行上面的语句,您将获得如下输出: 提示:HAVING子句类似于WHERE子句,但仅适用于整个组,而WHERE子句适用于单独的行 SELECT查询可以包含WHERE和HAVING子句,但是在这种情况下,WHERE子句必须出现在GROUP BY子句之前,而HAVING子句必须出现在GROUP BY子句之后但在ORDER BY子句之前。 |
 正如您看到的,输出仅包含薪水大于7000的那些雇员。类似地,您可以从特定列中获取记录,如下所示: SELECT emp_id, emp_name, hire_date, salary FROM employees WHERE salary > 7000; 执行上面的语句后,您将获得如下输出:
正如您看到的,输出仅包含薪水大于7000的那些雇员。类似地,您可以从特定列中获取记录,如下所示: SELECT emp_id, emp_name, hire_date, salary FROM employees WHERE salary > 7000; 执行上面的语句后,您将获得如下输出: 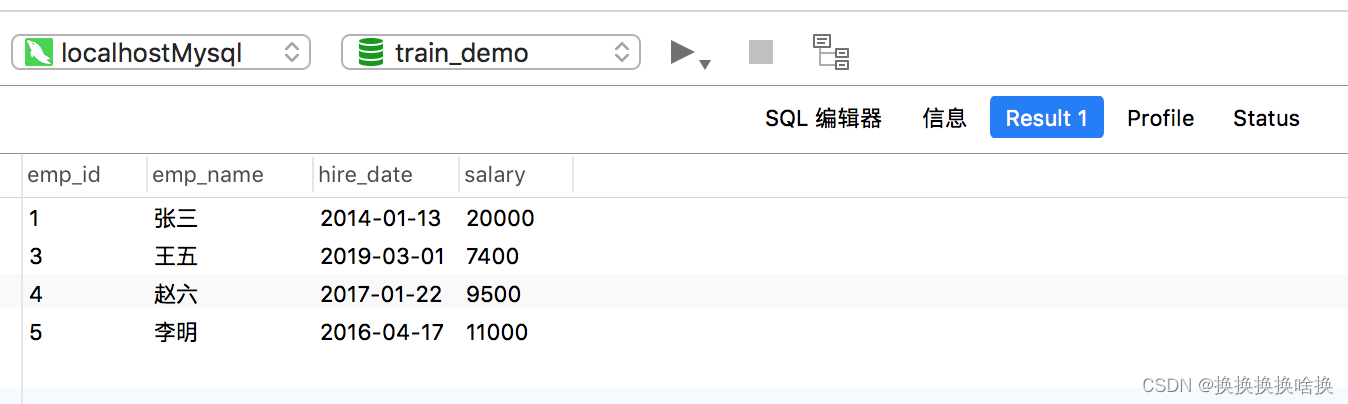 以下语句将获取其雇员ID为2的雇员的记录。 SELECT * FROM employees WHERE emp_id = 2; 该语句将产生以下输出:
以下语句将获取其雇员ID为2的雇员的记录。 SELECT * FROM employees WHERE emp_id = 2; 该语句将产生以下输出:  这次,我们在输出中仅获得一行,因为emp_id对每个员工都是唯一的。
这次,我们在输出中仅获得一行,因为emp_id对每个员工都是唯一的。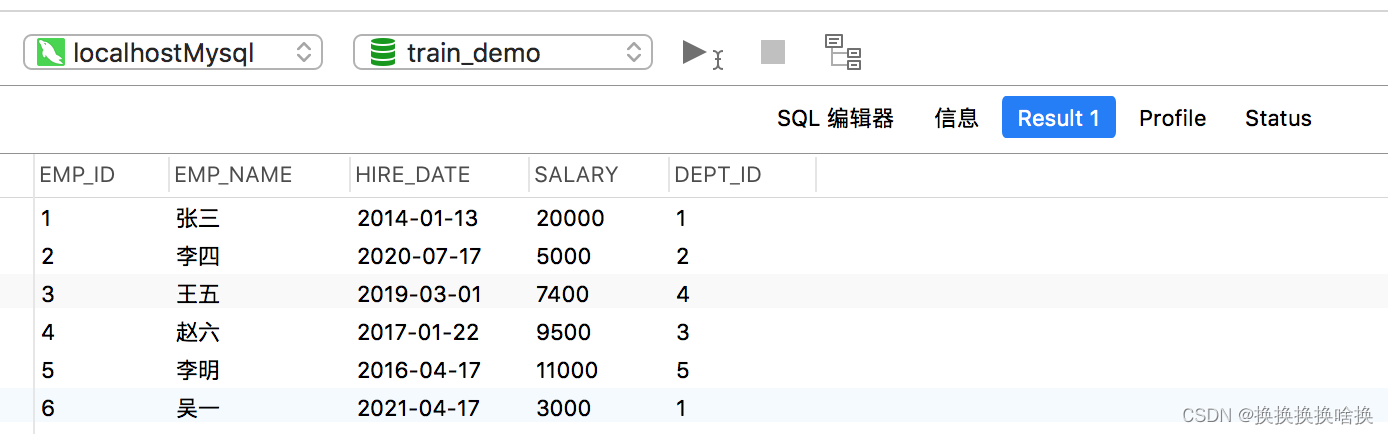 以下SQL语句将仅返回dept_id为1或3的那些雇员。 SELECT * FROM employees WHERE dept_id IN (1, 3); 执行查询后,您将获得如下结果集:
以下SQL语句将仅返回dept_id为1或3的那些雇员。 SELECT * FROM employees WHERE dept_id IN (1, 3); 执行查询后,您将获得如下结果集: 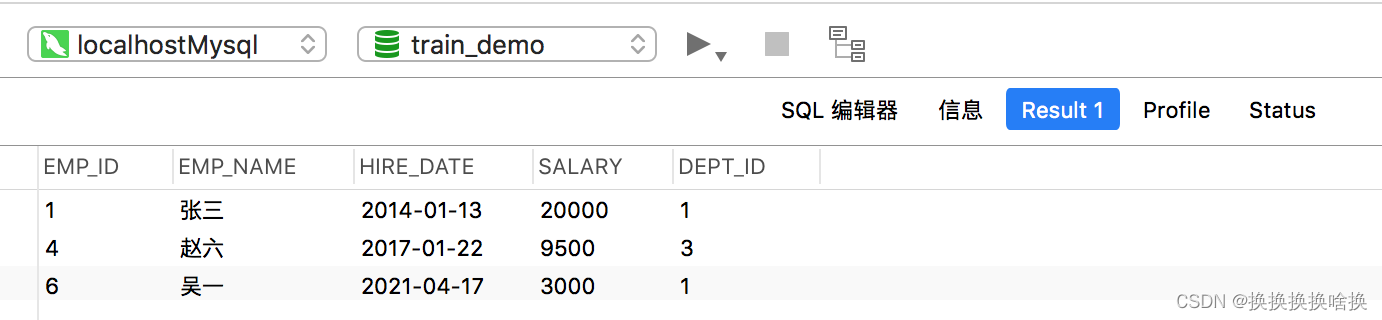 同样,您可以使用NOT IN运算符,则该运算符与IN运算符完全相反。以下SQL语句将返回除dept_id不是1或3的那些雇员以外的所有雇员。 SELECT * FROM employees WHERE dept_id NOT IN (1, 3); 执行查询后,这次您将获得如下结果集:
同样,您可以使用NOT IN运算符,则该运算符与IN运算符完全相反。以下SQL语句将返回除dept_id不是1或3的那些雇员以外的所有雇员。 SELECT * FROM employees WHERE dept_id NOT IN (1, 3); 执行查询后,这次您将获得如下结果集: 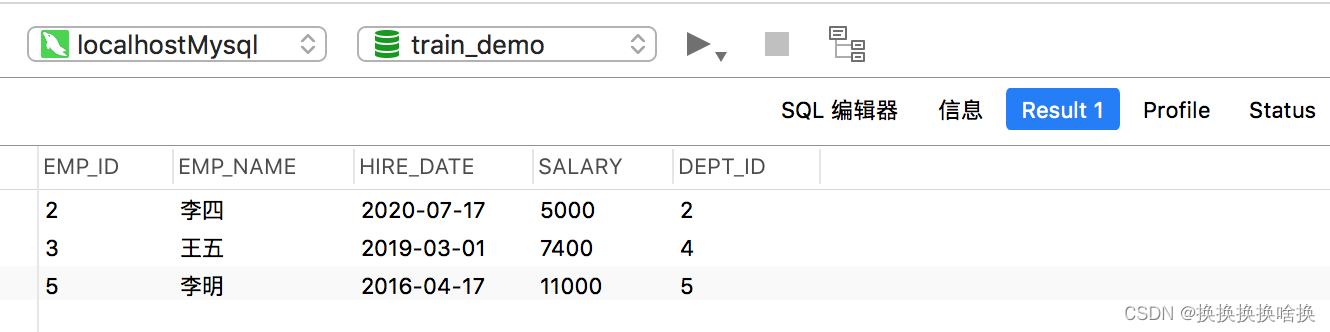


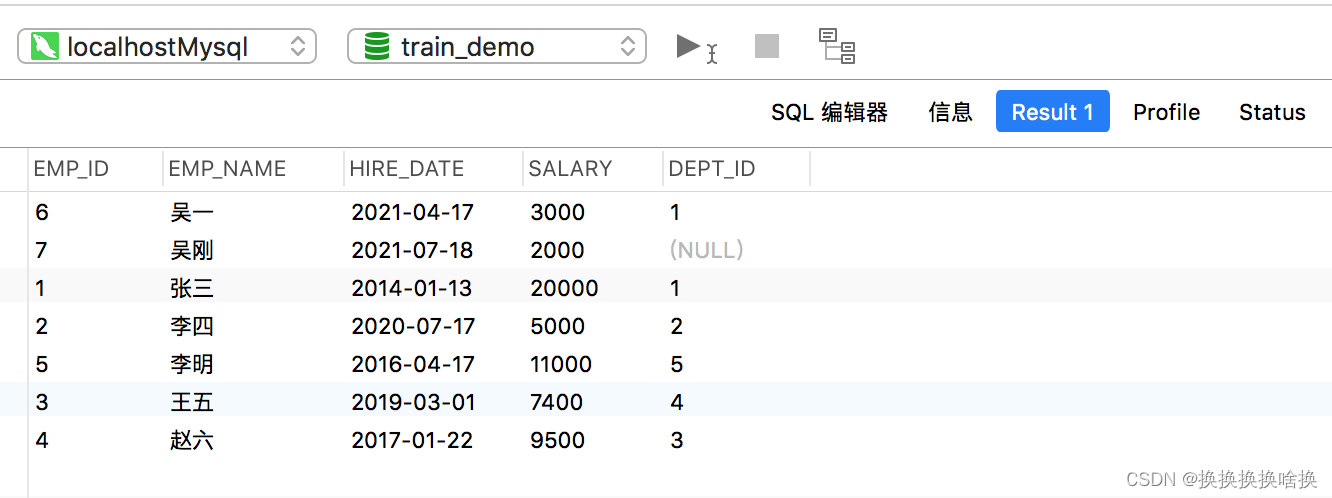 同样,您可以使用DESC选项以降序执行排序。以下语句将按数字薪水(salary)列的降序排列结果集。 SELECT * FROM employees ORDER BY salary DESC; 这次,您将获得如下结果集:
同样,您可以使用DESC选项以降序执行排序。以下语句将按数字薪水(salary)列的降序排列结果集。 SELECT * FROM employees ORDER BY salary DESC; 这次,您将获得如下结果集: 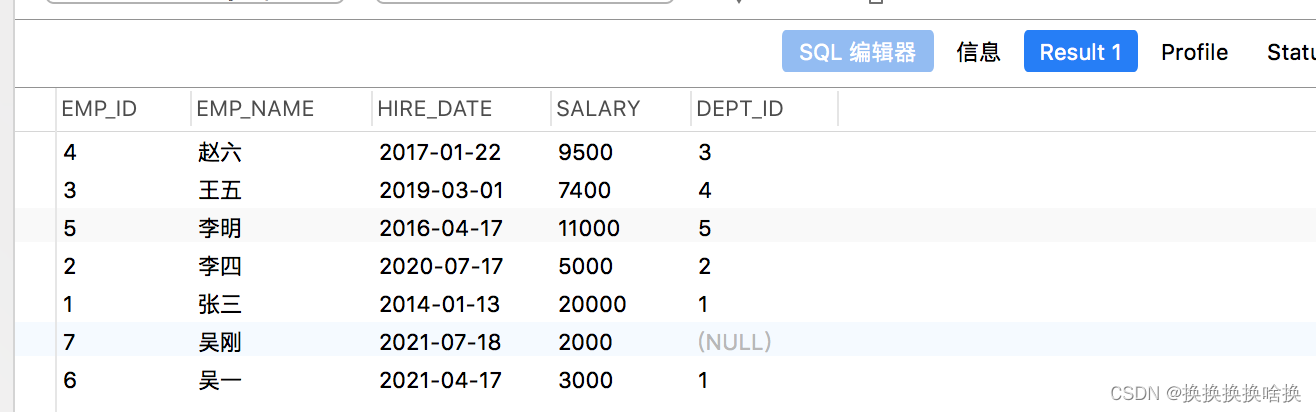
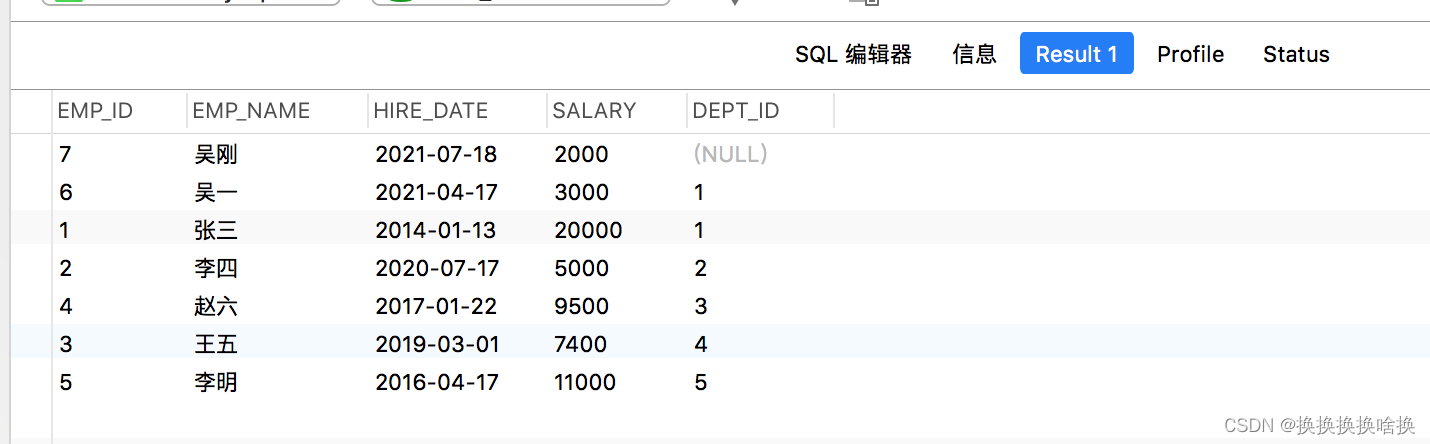
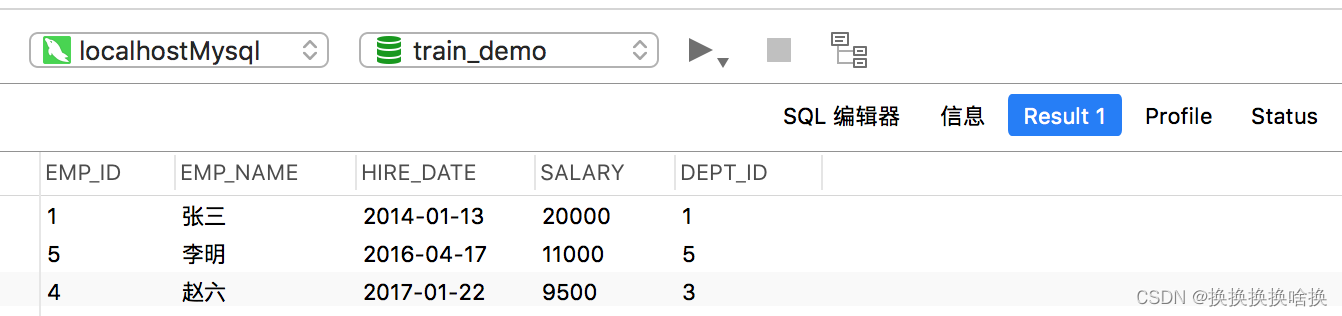 注意: 在SELECT语句中,始终将ORDER BY子句与LIMIT子句一起使用。 否则,您可能无法获得理想的结果。
注意: 在SELECT语句中,始终将ORDER BY子句与LIMIT子句一起使用。 否则,您可能无法获得理想的结果。
 现在执行以下语句,该语句返回此表的dept_id列中的所有行。
现在执行以下语句,该语句返回此表的dept_id列中的所有行。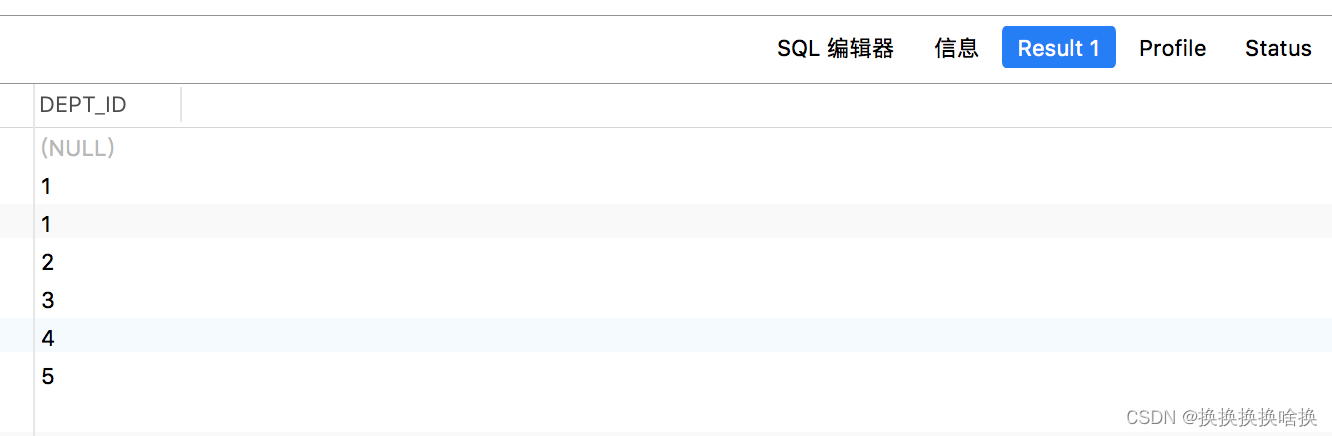 如果仔细查看输出,您会发现部门ID“1”在我们的结果集中出现了两次,这不好吧。好吧,让我们解决这个问题。 删除重复数据 SELECT DISTINCT dept_id FROM employees; 执行上述命令后,您将获得如下输出:
如果仔细查看输出,您会发现部门ID“1”在我们的结果集中出现了两次,这不好吧。好吧,让我们解决这个问题。 删除重复数据 SELECT DISTINCT dept_id FROM employees; 执行上述命令后,您将获得如下输出: 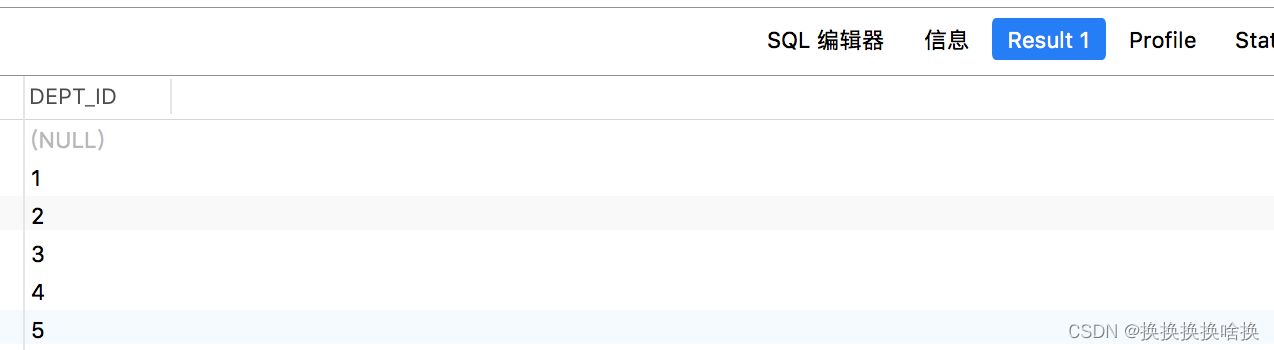 正如您看到的,这次的结果集中没有重复的值。 注意:如果将SELECT DISTINCT语句用于具有多个NULL值的列,则SQL保留一个NULL值,并从结果集中删除其他值,因为DISTINCT将所有NULL值视为相同的值。
正如您看到的,这次的结果集中没有重复的值。 注意:如果将SELECT DISTINCT语句用于具有多个NULL值的列,则SQL保留一个NULL值,并从结果集中删除其他值,因为DISTINCT将所有NULL值视为相同的值。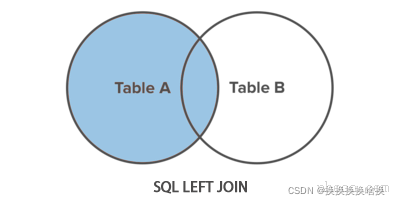 注意:外部联接是一种联接,它在结果集中包含行,即使要联接的两个表中的行之间可能不匹配。
注意:外部联接是一种联接,它在结果集中包含行,即使要联接的两个表中的行之间可能不匹配。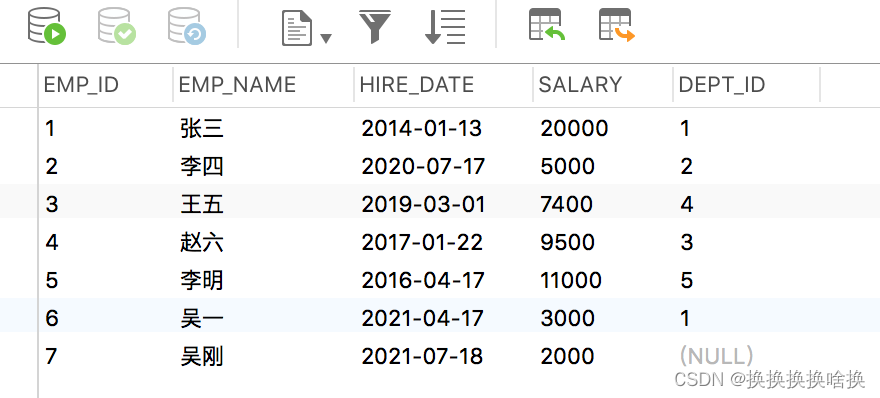
 正如您可以清楚地看到的那样,左联接包括雇员(employees)表中结果集中的所有行,无论departments表中的dept_id列是否匹配。 注意:如果左表中有一行,而右表中没有匹配项,则关联的结果行将包含NULL来自右表的所有列的值。
正如您可以清楚地看到的那样,左联接包括雇员(employees)表中结果集中的所有行,无论departments表中的dept_id列是否匹配。 注意:如果左表中有一行,而右表中没有匹配项,则关联的结果行将包含NULL来自右表的所有列的值。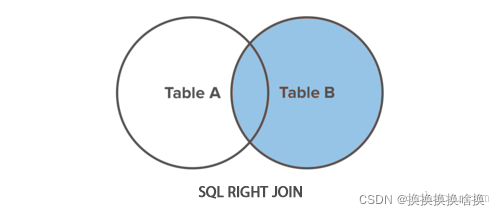 注意:外部联接是一种联接,它在结果集中包含行,即使要联接的两个表中的行之间可能不匹配。 为了清楚地理解这一点,让我们来看看下面employees和departments表。
注意:外部联接是一种联接,它在结果集中包含行,即使要联接的两个表中的行之间可能不匹配。 为了清楚地理解这一点,让我们来看看下面employees和departments表。 

 正确的联接包括结果集中部门表中的所有行,无论雇员表中的dept_id列是否匹配,因为您可以清楚地看到,即使该部门没有员工,也将包含“销售部”。 注意:如果右表中有一行,但左表中没有匹配项,则关联的结果行将包含来自左表的所有列的NULL值。
正确的联接包括结果集中部门表中的所有行,无论雇员表中的dept_id列是否匹配,因为您可以清楚地看到,即使该部门没有员工,也将包含“销售部”。 注意:如果右表中有一行,但左表中没有匹配项,则关联的结果行将包含来自左表的所有列的NULL值。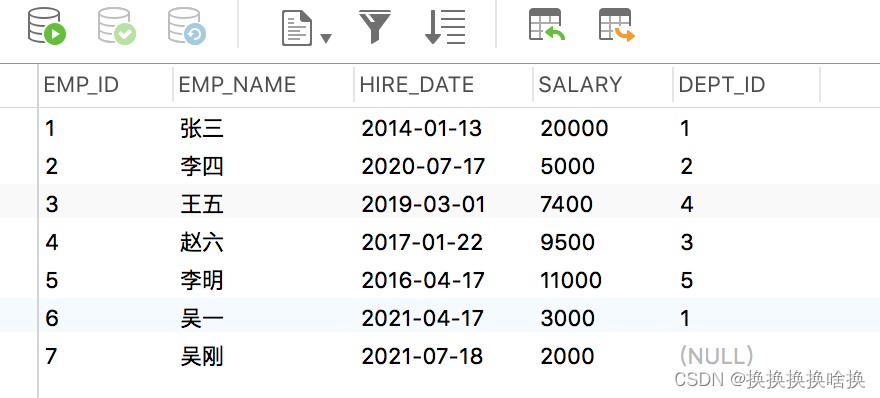 现在,假设您想找出所有以吴开头的员工。 SELECT * FROM employees WHERE emp_name LIKE ‘吴%’; 执行查询后,您将获得如下输出:
现在,假设您想找出所有以吴开头的员工。 SELECT * FROM employees WHERE emp_name LIKE ‘吴%’; 执行查询后,您将获得如下输出: 
 正如您看到的,输出中最后一列的标签很长而且很笨拙。我们可以使用列别名来解决此问题,如下所示: – MySQL数据库的语法 SELECT emp_name, DATE_FORMAT(hire_date, ‘%M %e, %Y’) AS hire_date FROM employees; 如果执行上面的语句,您将获得更具可读性的输出,如下所示:
正如您看到的,输出中最后一列的标签很长而且很笨拙。我们可以使用列别名来解决此问题,如下所示: – MySQL数据库的语法 SELECT emp_name, DATE_FORMAT(hire_date, ‘%M %e, %Y’) AS hire_date FROM employees; 如果执行上面的语句,您将获得更具可读性的输出,如下所示: 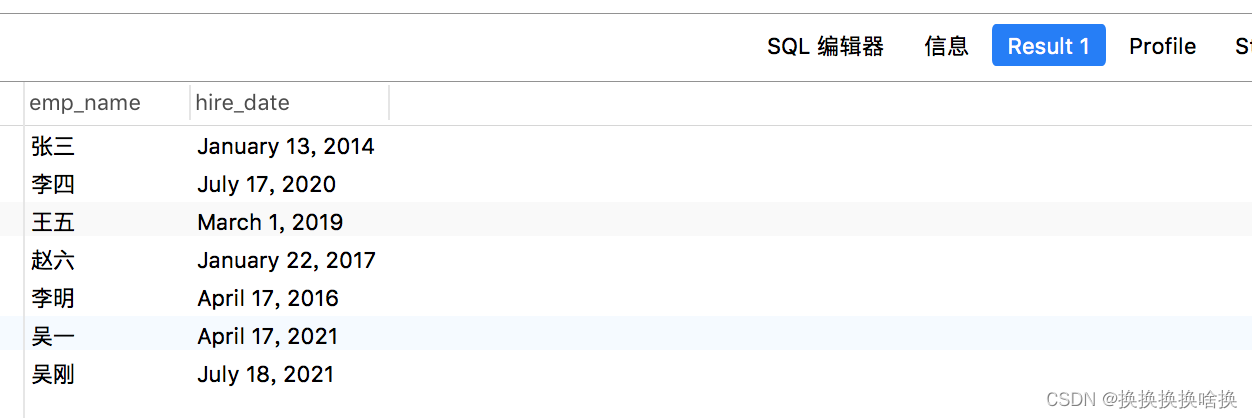 注意:您可以在GROUP BY,ORDER BY或HAVING子句中的使用别名来引用列。但是,不允许在WHERE子句中使用别名。
注意:您可以在GROUP BY,ORDER BY或HAVING子句中的使用别名来引用列。但是,不允许在WHERE子句中使用别名。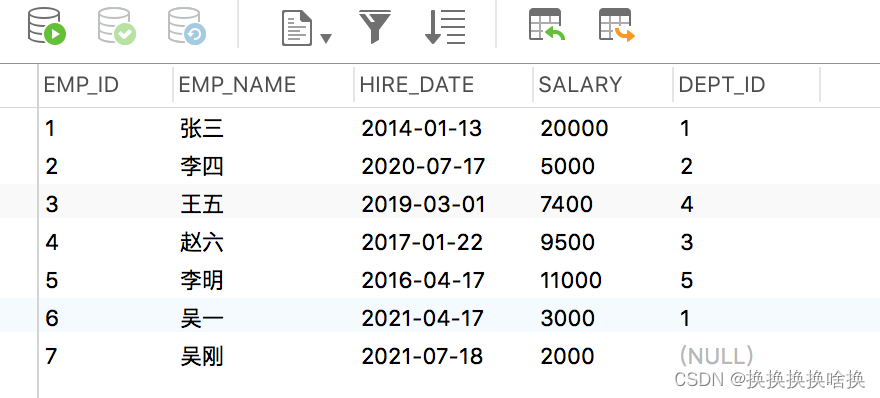
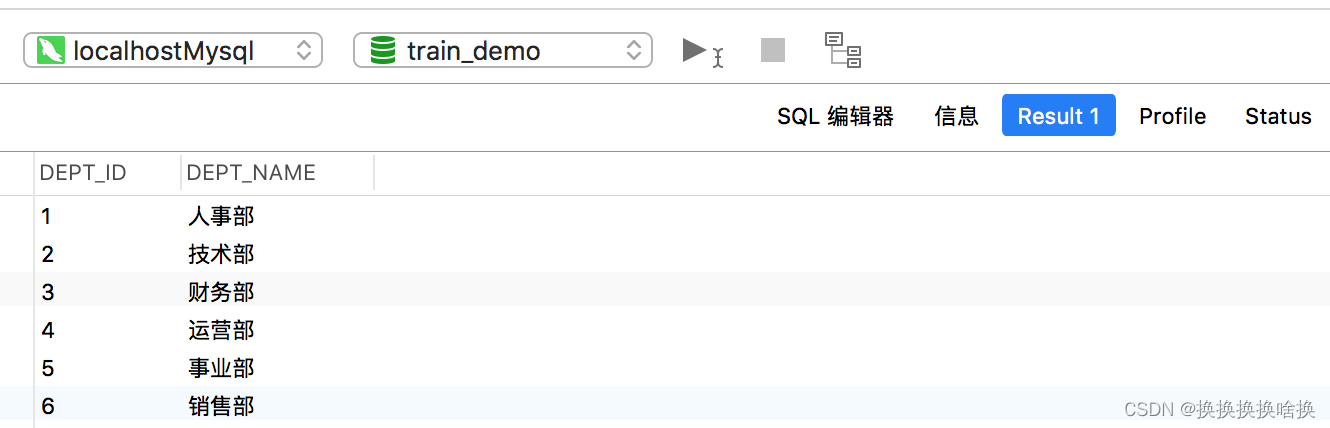
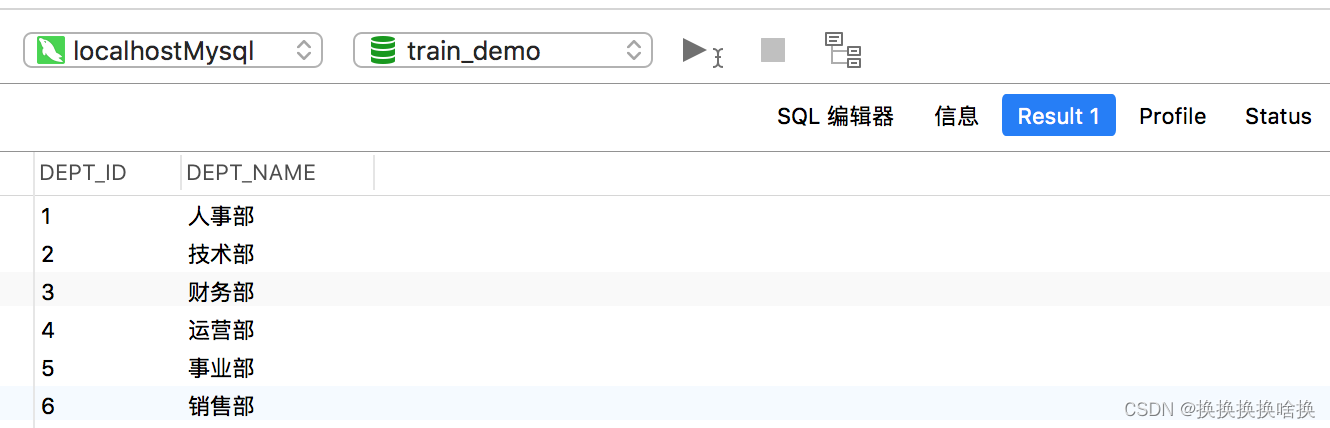 表: departments 现在,不只是查找雇员及其所在部门的名称,而是要查找每个部门中的雇员总数。 对于小型表,您可以简单地应用左联接并计算雇员数,但是假设如果一个表包含数千名雇员,那将不是那么容易。 在这种情况下,可以将GROUP BY子句与SELECT语句一起使用,如下所示: SELECT t1.dept_name, count(t2.emp_id) AS total_employees FROM departments AS t1 LEFT JOIN employees AS t2 ON t1.dept_id = t2.dept_id GROUP BY t1.dept_name;
表: departments 现在,不只是查找雇员及其所在部门的名称,而是要查找每个部门中的雇员总数。 对于小型表,您可以简单地应用左联接并计算雇员数,但是假设如果一个表包含数千名雇员,那将不是那么容易。 在这种情况下,可以将GROUP BY子句与SELECT语句一起使用,如下所示: SELECT t1.dept_name, count(t2.emp_id) AS total_employees FROM departments AS t1 LEFT JOIN employees AS t2 ON t1.dept_id = t2.dept_id GROUP BY t1.dept_name;

【本文地址】
今日新闻 |
推荐新闻 |