遗传算法优化神经网络实现数据预测 |
您所在的位置:网站首页 › narx神经网络训练完了怎么预测新数据 › 遗传算法优化神经网络实现数据预测 |
遗传算法优化神经网络实现数据预测
|
作者 | 李秋键 责编 | 寇雪芹 头图 | 下载于视觉中国 出品 | AI科技大本营(ID:rgznai100)
随着人工智能和大数据的发展,大量实验和数据处理等流程对算法的要求也随之变得越来越高,故综合以及灵活运用不同的算法以实现更高效的算法将会是一个很重要的突破点。 传统的优化算法一般都是基于梯度信息,但一般这种方法都是用在约束条件和目标函数可以求导的时候,而且容易陷入局部最优解的循环。但进化算法与之不同,其中最为典型的就是遗传算法,遗传进化算法模拟了自然选择的过程,它用单个个体来代表待求解问题的最优解,将初始化好的大量不同个体组成种群。按照初始化种群、变异、交叉、选择等流程,通过模拟自然界中的优胜劣汰的法则,引导种群因子不断进化,从而使得种群中的个体逐步接近问题的最优解。 与传统优化算法比较而言,遗传算法是一种在群体基础上搜索最优化个体的算法,具有鲁棒性强、搜索效率高、不易陷入局部最优等特点。因此,将他与神经网络算法相结合在一起,能够更好地利用神经网络去解决问题。 近几年来,大量学者研究发展也提出了很多新的优化算法,如邱宁佳提出的多头注意力评论量化的聚类优化推荐算法,他利用BiGRU网络的特征时序性与CNN网络的强局部特征有效性联合提取评论深度特征,并利用多头注意力机制的多维语义特征筛选对评论进行深度语义特征挖掘;然后经过多层感知机非线性转换进行多特征融合完成准确量化;最后使用PCA对差分进化变异选择进行优化完成相似用户聚类优化操作,寻找相似用户完成项目推荐,当然还有赵今越提出的垃圾分类收运路径问题的新型混合蚁群算法求解, 改进灰狼算法优化LSSVM的交通流量预测, 杨文强提出的求解仓储作业优化问题的多物种协同进化算法等等。
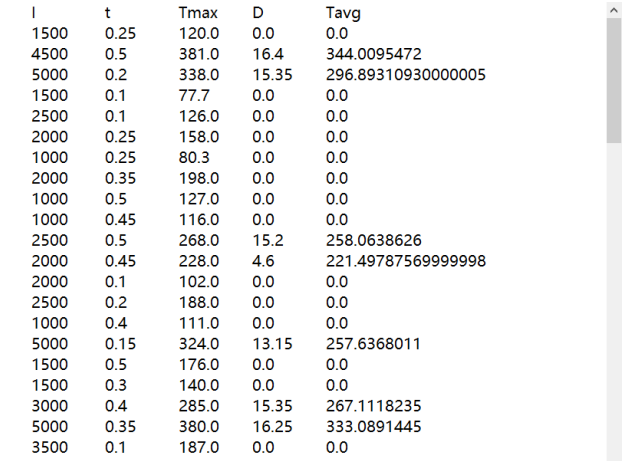
模型的搭建,按照神经网络搭建和遗传算法优化的顺序进行。 2.1 神经网络的搭建(1)数据集阐述: 本文所使用的测试数据集,是为二输入三输出的数据集,数据如图1可见:
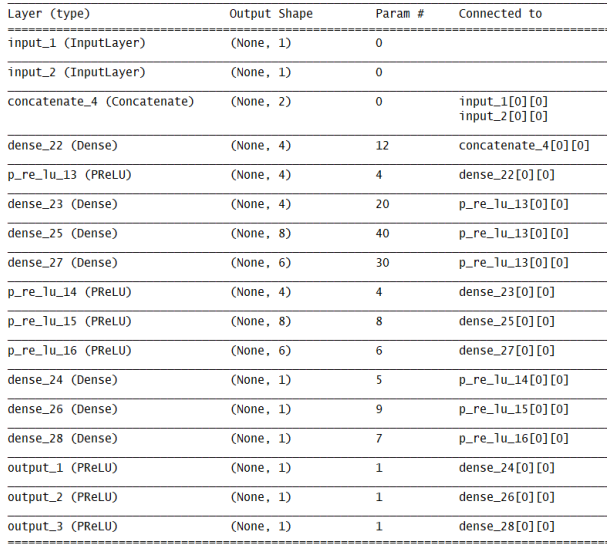
图1 数据集图片 如图1可见,其中参数l和t为输入的影响参数x,Tmax、D和Tavg为输出y。 首先要读入数据: 1K.set_image_data_format("channels_last") 2data_tr=pd.read_table('ALL-BPTrain.txt') 3x_1= data_tr.iloc[:, 0] 4x_2= data_tr.iloc[:, 1] 5y_1= data_tr.iloc[:, 2] 6y_2= data_tr.iloc[:, 3] 7y_3= data_tr.iloc[:, 4] 8data_tr=pd.read_table('predict input.txt') 9x_input1= data_tr.iloc[:, 0] 10x_input2= data_tr.iloc[:, 1] 11y_output1= data_tr.iloc[:, 2] 12y_output2= data_tr.iloc[:, 3] 13y_output3= data_tr.iloc[:, 4](2)网络结构的搭建: 搭建的神经网络如下图,图2可见:
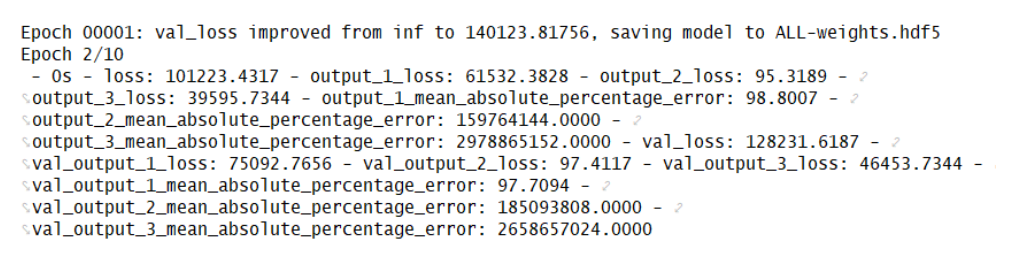
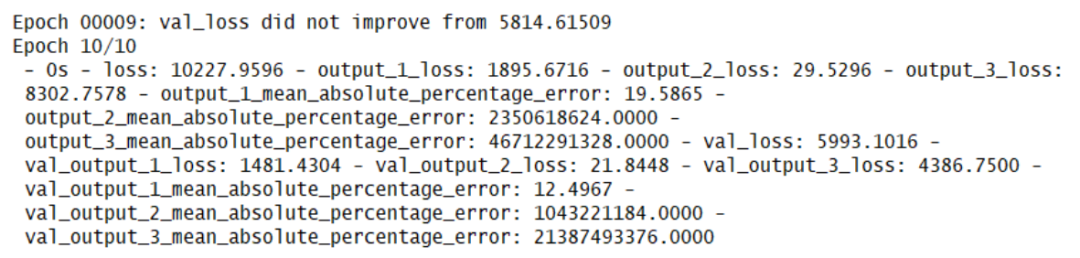
图2 网络结构图 其中设定kernel_initializer为RandomNormal来初始化权重,即定义为正态分布初始化。 代码如下: 1# 建立模型 2inputs_01 = Input((1,), name='input_1') 3inputs_02 = Input((1,), name='input_2') 4merge = Concatenate()([inputs_01, inputs_02]) 5hide_1 = Dense(units=4, use_bias=True, kernel_initializer='RandomNormal', bias_initializer='zeros')(merge) 6hide_1 = layers.PReLU(alpha_initializer='zeros',alpha_regularizer=None,alpha_constraint=None,shared_axes=None)(hide_1) 7output_01 = Dense(units=4, use_bias=True, kernel_initializer='RandomNormal', bias_initializer='zeros')(hide_1) 8output_01 = layers.PReLU(alpha_initializer="zeros",alpha_regularizer=None,alpha_constraint=None,shared_axes=None)(output_01) 9output_01 = Dense(units=1, use_bias=True, kernel_initializer='RandomNormal', bias_initializer='zeros')(output_01) 10output_01 = layers.PReLU(alpha_initializer='zeros',alpha_regularizer=None,alpha_constraint=None,shared_axes=None, name='output_1')(output_01) 11output_02 = Dense(units=8, use_bias=True, kernel_initializer='RandomNormal', bias_initializer='zeros')(hide_1) 12output_02 = layers.PReLU(alpha_initializer='zeros',alpha_regularizer=None,alpha_constraint=None,shared_axes=None)(output_02) 13output_02 = Dense(units=1, use_bias=True, kernel_initializer='RandomNormal', bias_initializer='zeros')(output_02) 14output_02 = layers.PReLU(alpha_initializer='zeros',alpha_regularizer=None,alpha_constraint=None,shared_axes=None, name='output_2')(output_02) 15output_03 = Dense(units=6, use_bias=True, kernel_initializer='RandomNormal', bias_initializer='zeros')(hide_1) 16output_03 = layers.PReLU(alpha_initializer='zeros',alpha_regularizer=None,alpha_constraint=None,shared_axes=None)(output_03) 17output_03 = Dense(units=1, use_bias=True, kernel_initializer='RandomNormal', bias_initializer='zeros')(output_03) 18output_03 = layers.PReLU(alpha_initializer='zeros',alpha_regularizer=None,alpha_constraint=None,shared_axes=None, name='output_3')(output_03) 19model = Model(inputs=[inputs_01, inputs_02], outputs=[output_01, output_02 , output_03])(3)模型训练保存: 模型优化器选择使用Adam优化器,Adam 算法是一种对随机目标函数执行一阶梯度优化的算法,该算法基于适应性低阶矩估计。Adam 算法很容易实现,并且有很高的计算效率和较低的内存需求。Adam 算法梯度的对角缩放(diagonal rescaling)具有不变性,因此很适合求解带有大规模数据或参数的问题。该算法同样适用于解决大噪声和稀疏梯度的非稳态问题。 1Adam=optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08) 2model.compile(optimizer=Adam, 3 loss={'output_1': 'mean_squared_error', 4 'output_2': 'mean_squared_error', 5 'output_3': 'mean_squared_error'}, 6 loss_weights={'output_1': 1.0, 'output_2': 1.0, 'output_3': 1.0}, 7 metrics={'output_1': 'mean_absolute_percentage_error', 8 'output_2': 'mean_absolute_percentage_error', 9 'output_3': 'mean_absolute_percentage_error'}) 10filepath = "ALL-weights.hdf5" 11checkpoint = ModelCheckpoint(filepath, monitor='val_loss', verbose=1, save_best_only=True, mode='min', period=1) 12callbacks_list = [checkpoint] 13history = model.fit({'input_1': x_1, 'input_2': x_2}, {'output_1': y_1, 'output_2': y_2, 'output_3': y_3}, 14 batch_size=2, 15 callbacks=callbacks_list, 16 validation_split=0.2,最终模型的运行效果如下图可见:
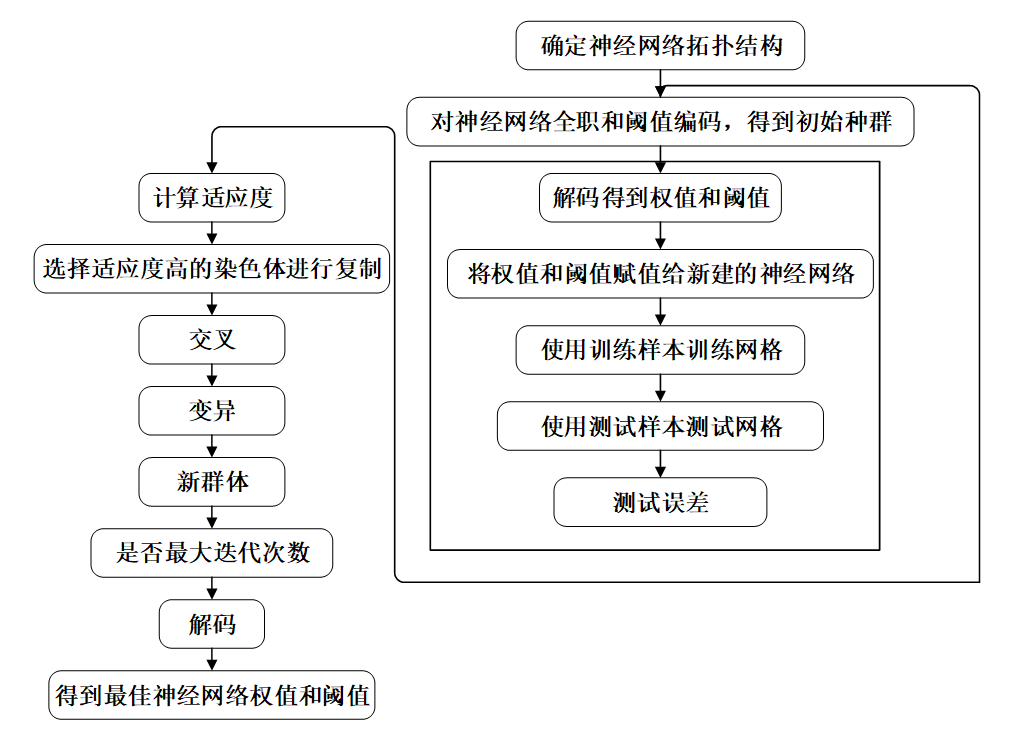
图3 神经网络运行过程图 2.2 遗传算法优化神经网络: 在定义完神经网络结构之后,需要确定遗传算法的优化参数的数目,进而确定遗传算法个体的编码长度。因为神经网络的初始权值和阈值是遗传算法优化的参数,只要网络的结构已知,权值和阈值的个数也就已知。种群中的每个个体都包含了一个网络所有权值和阈值,个体通过适应度函数计算个体适应度值,遗传算法通过选择、交叉和变异操作找到最优适应度值对应的个体。神经网络预测用遗传算法得到最优个体对网络进行初始权值和阈值的赋值,网络经训练后预测样本输出。神经网络的权值和阈值一般是通过初始化为【-0.5,0.5】区间的随机数,这个初始化参数对网络训练的影响很大,但是又无法准确获得,对于相同的初始权重值和阈值,网络的训练结果是一样的,引入遗传算法就是为了优化出最优的初始权值和阈值。遗传算法优化神经网络流程如下可见:
图4 遗传算法优化过程 定义配置并处理的转换和突变个人基因组。部分代码如下图: 1def denseParam(self, i): 2 key = self.dense_layer_shape[i] 3 return self.layer_params[key] 4def mutate(self, genome, num_mutations): 5 num_mutations = np.random.choice(num_mutations) 6 index=num_mutations 7 try: 8 genome[index] = np.random.choice(list(range(len(self.optimizer)))) 9 except: 10 pass 11 return genome定义遗传算法优化算法的运行等: 1 def set_objective(self, metric): 2 if metric == 'acc': 3 metric = 'accuracy' 4 if metric not in ['loss', 'accuracy']: 5 raise ValueError(('Invalid metric name {} provided - should be' 6 '"accuracy" or "loss"').format(metric)) 7 self._metric = metric 8 self._objective = "max" if self._metric == "accuracy" else "min" 9 self._metric_index = 1 if self._metric == 'loss' else -1 10 self._metric_op = METRIC_OPS[self._objective == 'max'] 11 self._metric_objective = METRIC_OBJECTIVES[self._objective == 'max'] 12 def run(self, num_generations, pop_size, epochs, fitness=None, 13 metric='accuracy'): 14 self.set_objective(metric) 15 members = self._generate_random_population(pop_size) 16 pop = self._evaluate_population(members, 17 epochs, 18 fitness, 19 0, 20 num_generations) 21 for gen in range(1, num_generations): 22 members = self._reproduce(pop, gen) 23 pop = self._evaluate_population(members, 24 epochs, 25 fitness, 26 gen, 27 num_generations) 28 return load_model('best-model.h5')程序运行效果图如下图可见:
图中generation为遗传算法的迭代,model为神经网络的迭代。
图5 遗传算法优化结果
神经网络是一种模仿生物神经网络(动物的中枢神经系统,特别是大脑)的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。神经网络由大量的人工神经元联结进行计算。大多数情况下人工神经网络能在外界信息的基础上改变内部结构,是一种自适应系统。现代神经网络是一种非线性统计性数据建模工具。典型的神经网络具有以下三个部分: 结构:其指定了网络中的变量和它们的拓扑关系。例如,神经网络中的变量可以是神经元连接的权重和神经元的激励值。 激励函数:大部分神经网络模型具有一个短时间尺度的动力学规则,来定义神经元如何根据其他神经元的活动来改变自己的激励值。一般激励函数依赖于网络中的权重(即该网络的参数)。 学习规则:学习规则指定了网络中的权重如何随着时间推进而调整。这一般被看做是一种长时间尺度的动力学规则。一般情况下,学习规则依赖于神经元的激励值。它也可能依赖于监督者提供的目标值和当前权重的值。 3.2 遗传算法遗传算法是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。 其主要特点是直接对结构对象进行操作,不存在求导和函数连续性的限定;具有内在的隐并行性和更好的全局寻优能力;采用概率化的寻优方法,不需要确定的规则就能自动获取和指导优化的搜索空间,自适应地调整搜索方向。 遗传算法以一种群体中的所有个体为对象,并利用随机化技术指导对一个被编码的参数空间进行高效搜索。其中,选择、交叉和变异构成了遗传算法的遗传操作;参数编码、初始群体的设定、适应度函数的设计、遗传操作设计、控制参数设定五个要素组成了遗传算法的核心内容。  仿真结果
仿真结果
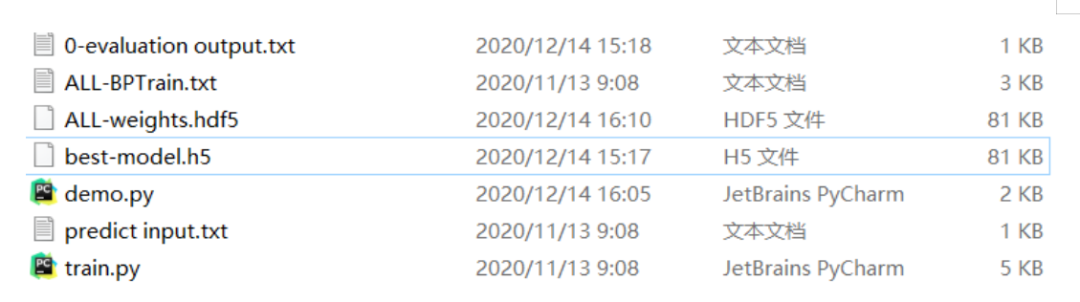
通过运行demo.py,会生成模型参数保存文件ALL-weights.hdf5,最优模型文件best-model.h5等。
图6 仿真结果生成文件 程序运行结果如图7可见:
图7 运行结果图
|








【本文地址】
今日新闻 |
推荐新闻 |