机器学习基础 |
您所在的位置:网站首页 › names是什么词 › 机器学习基础 |
机器学习基础
|
文章目录
特征工程什么是特征工程
数据预处理缺失值的处理删除法填补法Pandas填充Sklearn填充
数据归一化什么是归一化归一化原理为什么要用归一化什么算法需要进行归一化sklearn库归一化处理归一化存在的问题
数据标准化什么是标准化标准化原理为什么要用标准化sklearn库标准化处理
标准化和归一化对比
特征抽取字典特征数据提取文本特征数据提取TF-IDF
做比赛或者做项目的时候,绞尽脑汁考虑到了所有问题,发现预测效果却总是不尽人意。用尽了各种高级算法,进行了各种创新,却依然无法将准确率提高。这是怎么回事……那可能是因为你忽略了最为重要的一点——
特征工程。所谓特征工程即模型搭建之前进行的数据预处理和特征提取。有时人们常常好高骛远,数据都没处理好就开始折腾各种算法,从第一开始就有问题,那岂不是还没开始就已经结束了。所以说啊,不积跬步无以至千里,生活中的每个细节,都可能创造人生的辉煌。
pdf版已放在下载专区
特征工程
什么是特征工程
特征工程是将原始数据转换为更好地代表预测模型的潜在问题的特征的过程,从而提高了对未知数据的预测准确性。直接决定了模型预测的结果好坏。 简单的说,就是一个特征提取和数据预处理的过程。 而机器学习中想要做好特征处理,一定离不开一个工具,那就是sklearn库,本文主要写的也是sklearn在特征工程中的应用。 数据预处理 缺失值的处理有时候,当我们拿到一份数据的时候,常常会发现有很多的缺失值。有缺失值的特征会给模型带来极大的噪音,对学习造成较大的干扰。这时候就需要我们对缺失数据进行一个处理。常用的处理方法有两种,删除法和填充法。 删除法如果缺失的数量很多,而又没有证据表明这个特征很重要,那么可将这列直接删除,否则会对结果造成不良影响。在确定是否删除特征之前,一般使用data.isnull().sum()统计所有各列各自共有多少缺失值,如果缺失的数量非常少,而且数据不是时间序列那种必须连续的,那么可以将缺失值对应的样本删除。 举个例子,下表有三个特征,很明显特征2缺失值较多。 运行结果 通过已有的数据对缺失值进行填补:针对数据的特点,选择用0、最大值、均值、中位数等填充。但是用这些方法来填补也会有一定的误差,因为等于人为增加了噪声。 Pandas填充pandas填充APIpandas.fillna(value=None, method=None……) 特殊值填充(以0填充为例) data['特征2'] = data['特征2'].fillna(0)
前向后向填充 data['特征2'].fillna(method='pad') #用前一个值填充 data['特征2'].fillna(method='bfill') #用后一个值填充以上都是最常用、最简单的填充方法。 Sklearn填充除了pandas有数据填充的功能,sklearn中也有填充功能。 sklearn填充API sklearn.imputer.SimpleImputer(missing_values=np.nan,strategy='mean',anix=0)#其中strategy为填充的方案 imputer.fit_transform(X) X:array格式的数据返回值:array举个例子,对[[1,2],[np.nan,3],[7,6]]进行缺失值填充,其中np.nan表示缺失值。这里以均值填充为例,即设置strategy=‘mean’。 1、调库 import pandas as pd import numpy as np from sklearn.impute import SimpleImputer2、填充函数 def im(): im = SimpleImputer(missing_values=np.nan, strategy='mean') data = im.fit_transform([[1,2],[np.nan,3],[7,6]]) print(data) return None3、结果 if __name__=="__main__": im()
简单的说归一化就是通过对原始数据进行变换把数据映射到某个区间(默认为[0,1])之内。 归一化原理
了解了归一化的定义之后,不免会产生一些问题,那就是为什么处理数据时非要把原始数据映射到某个区间呢?直接对原始数据进行处理不行吗?……下面用一个例子对其进行解释。 下表是一个相亲约会对象数据,此样本给出了相亲男士的三个特征,即飞机里程数、日常消费和玩游戏消耗时间占比。给出了女生对男生的评价结果。 飞机里程数日常消费玩游戏消耗时间占比评价316802000.8不喜欢124423000.7较喜欢221345000.4不喜欢544201000.9喜欢假如让我来根据三个特征来对该男士进行评价,我可能主观认为飞机里程数占比较大,因为我认为飞机里程数大的人是一个富翁,长时间在飞机上待着(这里只是以此举例),所以我会潜意识中把飞机里程数作为评价的首要因素。但是事实情况是这样吗?不一定,在飞机上长时间待着的也有可能是机长。所以,为了消除主观感觉上的错误我们应该把三个特征看作同等重要。而把特征同等化,就是归一化的本质。此外,在机器学习中,常默认为数据越大,占比越重,所以我们需要对数据进行归一化来保证数据的同等。综上得出归一化的目的:处理不同规模和量纲的数据,使其缩放到相同的数据区间和范围,以减少规模、特征、分布差异对模型的影响。 什么算法需要进行归一化机器学习中并不是所有算法都需要进行归一化处理,有些算法对各个特征的取值并不关心,例如一些概率模型:决策树、随机森林、朴素贝叶斯等。而有些算法对特征取值比较关心,比如回归、SVM等。 sklearn库归一化处理sklearn归一化API为sklearn.preprocessing.MinMaxScaler MinMaxScaler函数语法:MinMaxScaler(feature_range=(0,1))#其中feature_range指的是需要映射的区间,默认[0,1]。 MinMaxScaler.fit_transform(X):通过直接调用fit_transform即可进行归一化。 要求输入数据类型:二维数组,即array形式 举例: 对以下三个特征进行归一化处理 2、归一化函数 def mms(): mms = MinMaxScaler() data = mms.fit_transform([[100,150,130],[120,70,50],[30,70,20]]) print(data) return None3、运行结果 if __name__=="__main__": mms()
也可得出同样的结果。 有时操作dataframe时,需要首先转化为array数组才能操作。将dataframe转化为array类型的方式一般有三种 df.valuesdf.as_matrix()np.array(df) 归一化存在的问题归一化存在的主要问题就是,如果数据异常点较多,会造成很大的误差。 以刚才的三个特征为例,在特征1的基础上增加了两个异常点如下,那么公式中的max值和min值势必会发生很大的变化,那么会给归一化的计算带来很大的影响。 所以归一化的缺点是处理异常点能力差 。 而在某些场景下最大值和最小值是变化的并且极易受到异常点的影响,所以这种方法的鲁棒性较差,只适合于传统精确小数据场景。 那么,在数据处理中如何解决异常点的问题呢?就需要用到标准化。 要求输入数据类型:二维数组,即array形式 举例: 对以下三个特征进行标准化处理 数据标准化 什么是标准化通过对原始数据进行变换把数据变换到均值为0,方差为1的范围内。 标准化原理
因为标准差可以解决归一化存在的问题。标准差对异常点不敏感。 sklearn标准化API为sklearn.preprocessing.StandScaler StandScaler.fit_transform(X):通过直接调用fit_transform即可进行标准化。 要求输入数据类型:二维数组,即array形式 举例: 对以下三个特征进行归一化处理 2、标准化函数 #标准化 def stand(): stand = StandardScaler() data = stand.fit_transform([[100,150,130],[120,70,50],[30,70,20]]) print(data) return None3、运行结果 对于归一化来说:如果出现异常点,影响了最大值和最小值,那么结果显然会发生改变。 对于标准化来说:如果出现异常点,由于具有一定数据量, 少量的异常点对于平均值的影响并不大,从而方差改变较小。 特征抽取有时候,我们获取到一份数据时,原始数据的种类有很多种,除了我们熟悉的数值型数据,还有大量符号化的文本。然而,我们无法直接将符号化的文字本身用于计算任务,而是需要通过某些处理手段,预先将文本量化为特征向量。比如我们在判断一个目标值时,常常会出现一些文本,字符串的值。 身高头发目标值170短男160长女例如根据身高、发长等特征判断一个人的性别时,头发的‘长’、‘短’为文本值,需要先将其转化为数字。在sklearn库中也提供了特征抽取的APIsklearn.feature_extraction我们常常需要处理的数据类型包括字典特征提取、文本特征提取以及图像特征提取。 字典特征数据提取字典特征数据提取即对字典数据进行特征值化,sklearn中的字典特征数据提取API为 sklearn.feature_extraction.DictVectorizer DictVectorizer语法: DictVectorizer.fit_transform(X) X:字典类型返回值:sparse矩阵 DictVectorizer.inverse_transform(X) X:array数组或者sparse矩阵返回值:转化之前数据格式 DictVectorizer.get_feature_names() -返回特征类别名称举个例子: 例如给出以下三个城市信息: {‘city’:‘北京’,‘temperature’:35} {‘city’:‘上海’,‘temperature’:38} {‘city’:‘河北’,‘temperature’:32} 对其进行特征提取 1、调库 import pandas as pd import numpy as np from sklearn.feature_extraction import DictVectorizer2、字典特征提取函数 def dict(): dict = DictVectorizer() data = dict.fit_transform([{'city':'北京','temperature':35},{'city':'上海','temperature':38},{'city':'河北','temperature':32}]) print(data) return None3、运行结果
对文本数据进行特征值化。 sklearn文本特征抽取API sklearn.feature_extraction.text.CountVectorizer CountVectorizer.fit_transform(X) X:文本或者包含文本字符串的可迭代对象返回值:返回sparse矩阵 CountVectorizer.inverse_transform(X) X:array数据或者sparse矩阵 CountVectorizer.get_feature_names(X) 返回值:单词列表举例,对一个文本进行特征提取 “life is short,i like python”,“life is too long,i dislike python” 1、调库 import pandas as pd import numpy as np from sklearn.feature_extraction.text import CountVectorizer2、文本特征提取函数 #文本特征抽取 def count(): count = CountVectorizer() data = count.fit_transform(["life is short,i like python","life is too long,i dislike python"]) print(data) return None3、运行结果 if __name__=="__main__": count()
为了更好的理解第二个特点,我们将原来的文本改为 “life is is,i like python”,“life is too long,i dislike python” 再来举个例子 随便挑选《三体》中的三句经典语录 1、唯一不可阻挡的是时间,它像一把利刃,无声地切开了坚硬和柔软的一切,恒定的向前推进着,没有任何东西能够使它的行径产生丝毫颠簸,它却改变着一切。 2、我们都是阴沟里的虫子,但总还是得有人仰望星空。 3、要知道,一个文学人物十分钟的行为,可能是她十年的经历的反映。 1、调库 import jieba2、分词函数 def cut(): con1 = jieba.cut("唯一不可阻挡的是时间,它像一把利刃,无声地切开了坚硬和柔软的一切,恒定的向前推进着,没有任何东西能够使它的行径产生丝毫颠簸,它却改变着一切。") con2 = jieba.cut("我们都是阴沟里的虫子,但总还是得有人仰望星空。") con3 = jieba.cut("要知道,一个文学人物十分钟的行为,可能是她十年的经历的反映。") #转化成列表 content1 = list(con1) content2 = list(con2) content3 = list(con3) #把列表转化为字符串 c1 = ' '.join(content1) c2 = ' '.join(content2) c3 = ' '.join(content3) return c1,c2,c33、文本特征提取 def count(): c1,c2,c3 = cut() print(c1,c2,c3) count = CountVectorizer() data = count.fit_transform([c1,c2,c3]) print(count.get_feature_names()) print(data.toarray()) return None4、运行结果 if __name__=="__main__": count()
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。 词频(TF)表示关键字在文本中出现的频率。 逆向文件频率 (IDF) :是由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。所以,如果包含词条的文档越少, IDF越大,则说明词条具有很好的类别区分能力。 TF-IDF实际上是表示的词的重要程度,计算方式为:TF×IDF 某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。 TF-IDF的主要思想是: 如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。 sklearn中的API:sklearn.feature_extraction.text.TfidfVectorizer TfidfVectorizer(stop_words=None) #stop_words表示哪些词可以忽略TfidfVectorizer.fit_transform(X) X:文本或者包含文本字符串的可迭代对象返回值:返回sparse矩阵1、调库 import pandas as pd import numpy as np from sklearn.feature_extraction.text import TfidfVectorizer2、TF-IDF函数 #TF-IDF def tf(): c1,c2,c3 = cut() print(c1,c2,c3) tf = TfidfVectorizer() data = tf.fit_transform([c1,c2,c3]) print(tf.get_feature_names()) print(data.toarray()) return None3、结果 if __name__=="__main__": tf()
|
 统计缺失值数目
统计缺失值数目 总共有26组数据,特征2缺失12组,故可将其删除。 但是,由于删除法误差太大,所以一般在数据处理的时候很少使用删除法,多用填补法。
总共有26组数据,特征2缺失12组,故可将其删除。 但是,由于删除法误差太大,所以一般在数据处理的时候很少使用删除法,多用填补法。 中位数填充
中位数填充 需要注意的是:不论是pandas填充缺失值还是sklearn填充缺失值,需要保证缺失值的类型为np.nan,必须为float类型。如果需要处理的特征不属于float类型,需要先用np.array将其转化为float类型。
需要注意的是:不论是pandas填充缺失值还是sklearn填充缺失值,需要保证缺失值的类型为np.nan,必须为float类型。如果需要处理的特征不属于float类型,需要先用np.array将其转化为float类型。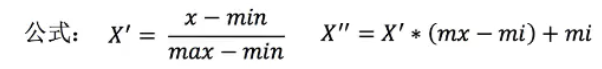 其中,max为一列的最大值,min为一列的最小值,X’‘为最终结果,mx,mi分别为指定区间值,默认mx=1,mi=0。 举个例子:
其中,max为一列的最大值,min为一列的最小值,X’‘为最终结果,mx,mi分别为指定区间值,默认mx=1,mi=0。 举个例子:  上表中有四个特征,我们对特征1中的90进行归一化。第一列的最大值就是90,即max=90,最小值为60,即min=60,x=90,设置映射的区间为[0,1],即mi=0,mx=1,带入式子可得: X’=(90-60)/(90-60)=1 X’'=1×(1-0)+0=1。 以此类推。
上表中有四个特征,我们对特征1中的90进行归一化。第一列的最大值就是90,即max=90,最小值为60,即min=60,x=90,设置映射的区间为[0,1],即mi=0,mx=1,带入式子可得: X’=(90-60)/(90-60)=1 X’'=1×(1-0)+0=1。 以此类推。 1、调库
1、调库 当然了,很多时候有大量的数据,需要直接读取csv或其他文件进行处理。 例如读取excel文件
当然了,很多时候有大量的数据,需要直接读取csv或其他文件进行处理。 例如读取excel文件 

 其中mean为平均值,σ为标准差。
其中mean为平均值,σ为标准差。 上图中红点为平均值,粉点为两个异常值。当异常点出现时,总体数据的平均值和标准差并不会有特别大的波动。这也是在机器学习中标准化应用广泛的主要原因。
上图中红点为平均值,粉点为两个异常值。当异常点出现时,总体数据的平均值和标准差并不会有特别大的波动。这也是在机器学习中标准化应用广泛的主要原因。 从上面的结果可知,每一列的和皆为0,即平均值为0,并且标准差为1。
从上面的结果可知,每一列的和皆为0,即平均值为0,并且标准差为1。 等一等,这是啥? 上面已经写到,其返回格式默认为sparse格式,检索数据下标。那么为什么这个函数要返回sparse格式?因为sparse矩阵节约内存,方便读取处理。但是这种格式我们并不常用,我们需要将其转换为我们熟悉的数组格式。 那么如何转化为数组格式呢? 只需要将函数中的语句dict = DictVectorizer()改成dict = DictVectorizer(sparse=False) 结果如下:
等一等,这是啥? 上面已经写到,其返回格式默认为sparse格式,检索数据下标。那么为什么这个函数要返回sparse格式?因为sparse矩阵节约内存,方便读取处理。但是这种格式我们并不常用,我们需要将其转换为我们熟悉的数组格式。 那么如何转化为数组格式呢? 只需要将函数中的语句dict = DictVectorizer()改成dict = DictVectorizer(sparse=False) 结果如下:  那么问题又来了,转化为的数组是什么意思呢?其实这些数组即为转化的特征值,为了更方便理解,我们用 DictVectorizer.get_feature_names()把特征值也打出来。
那么问题又来了,转化为的数组是什么意思呢?其实这些数组即为转化的特征值,为了更方便理解,我们用 DictVectorizer.get_feature_names()把特征值也打出来。 所以,该模型提取了四个特征。而数组中的数值对应的就是这四个特征,如果city为上海,则把数组第一个值置为1,否则为0。如果city为北京,则把数组第二个值置为1,否则为0,以此类推。而数字形式则不进行转换,直接使用原来的数字。 拿第一行[0,1,0,35]举例,city不为上海,故第一个值为0。city为北京,故第二个值为1。city不为河北,故第三个值为0。最后的温度为数字,直接用35。 所以字典数据提取的本质为:把字典中一些类别数据,分别进行转换特征,进而转化为数字。 字典转化为的数组值就是我们熟悉的one-hot编码,至于为什么机器学习中要用one-hot编码以及one-hot编码的意义,请去百度。
所以,该模型提取了四个特征。而数组中的数值对应的就是这四个特征,如果city为上海,则把数组第一个值置为1,否则为0。如果city为北京,则把数组第二个值置为1,否则为0,以此类推。而数字形式则不进行转换,直接使用原来的数字。 拿第一行[0,1,0,35]举例,city不为上海,故第一个值为0。city为北京,故第二个值为1。city不为河北,故第三个值为0。最后的温度为数字,直接用35。 所以字典数据提取的本质为:把字典中一些类别数据,分别进行转换特征,进而转化为数字。 字典转化为的数组值就是我们熟悉的one-hot编码,至于为什么机器学习中要用one-hot编码以及one-hot编码的意义,请去百度。 依然是sparse形式。之前字典特征提取sklearnAPI中可以直接将sparse调成False,但是文本提取特征API没有该功能,也算是函数的一个bug吧。所以我们只能将最后的data转化为array形式。将print(data)改成print(data.toarrary())即可。
依然是sparse形式。之前字典特征提取sklearnAPI中可以直接将sparse调成False,但是文本提取特征API没有该功能,也算是函数的一个bug吧。所以我们只能将最后的data转化为array形式。将print(data)改成print(data.toarrary())即可。  为了更好的理解上面数组的意义,将提取特征输出。
为了更好的理解上面数组的意义,将提取特征输出。 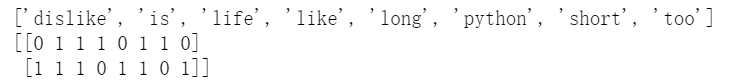 所以,文本特征提取的特点为
所以,文本特征提取的特点为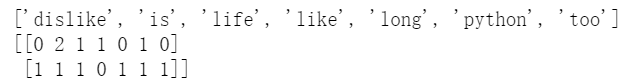 显然,is出现了两次,数组中显示2。 中文的提取道理类似,举一个例子。对下面一句话进行特征提取: “人生苦短,我喜欢 python”,“人生漫长,我不喜欢 python” 运行结果
显然,is出现了两次,数组中显示2。 中文的提取道理类似,举一个例子。对下面一句话进行特征提取: “人生苦短,我喜欢 python”,“人生漫长,我不喜欢 python” 运行结果  但是这是我们想要的结果吗?很显然不是,我们需要的是词语,而它对中文的处理默认为把逗号、空格等作为一个分隔。当然我们可以把词语利用空格进行分割,比如改成 人生 苦短,我 喜欢 python","人生 漫长,我 不喜欢 python 运行结果
但是这是我们想要的结果吗?很显然不是,我们需要的是词语,而它对中文的处理默认为把逗号、空格等作为一个分隔。当然我们可以把词语利用空格进行分割,比如改成 人生 苦短,我 喜欢 python","人生 漫长,我 不喜欢 python 运行结果  看来敲空格是有一定的用处,那么当我们处理大批的文字的时候呢,肯定就不能用这种方法来操作。所以我们需要对其进行分词,常用的分词工具就是jieba库。
看来敲空格是有一定的用处,那么当我们处理大批的文字的时候呢,肯定就不能用这种方法来操作。所以我们需要对其进行分词,常用的分词工具就是jieba库。 根据得到的结果一般就可以对句子或者文章进行分类。相类似的文章其关键词比较相似,即得到的数组比较相似。 但是在实际中,很少会用到统计词频的方式。因为在所有的文章中都会共存一些相同的高频词语,比如“我们”,“因为”,“所以”等等这些共性的词并不会对判断文章的类型有很大的帮助。所以,我们更需要的是那些可以反应文章类型的关键词,这就要用到TF-IDF。
根据得到的结果一般就可以对句子或者文章进行分类。相类似的文章其关键词比较相似,即得到的数组比较相似。 但是在实际中,很少会用到统计词频的方式。因为在所有的文章中都会共存一些相同的高频词语,比如“我们”,“因为”,“所以”等等这些共性的词并不会对判断文章的类型有很大的帮助。所以,我们更需要的是那些可以反应文章类型的关键词,这就要用到TF-IDF。 从得出的数组中可知,数字越大的,词就越重要。 总而言之,文本特征提取在自然语言处理领域是必不可少的一部分。
从得出的数组中可知,数字越大的,词就越重要。 总而言之,文本特征提取在自然语言处理领域是必不可少的一部分。【本文地址】
今日新闻 |
推荐新闻 |