MySql巨量数据造成性能下降的原因 |
您所在的位置:网站首页 › mysql单表一亿数据性能 › MySql巨量数据造成性能下降的原因 |
MySql巨量数据造成性能下降的原因
|
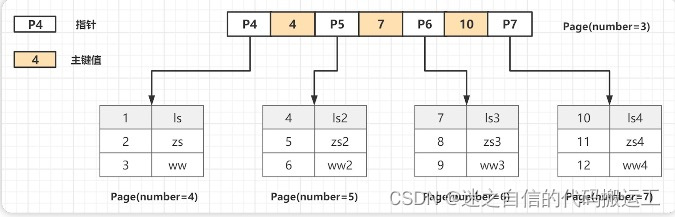
互联网江湖上的确流传着一个说法:单表数据量超过500万行时就要进行分表分库,已经超过2000万行时MySQL的性能就会急剧下降。 1.1 MySQL一张表最多能存多少数据?MySQL设计者将⼀个B+Tree的节点的⼤⼩设置为等于⼀个⻚. (这样做的⽬ 的是每个节点只需要⼀次I/O就可以完全载⼊), InnoDB的⼀个⻚的⼤⼩是 16KB,所以每个节点的⼤⼩也是16KB, 并且B+Tree的根节点是保存在内存中 的,⼦节点才是存储在磁盘上.
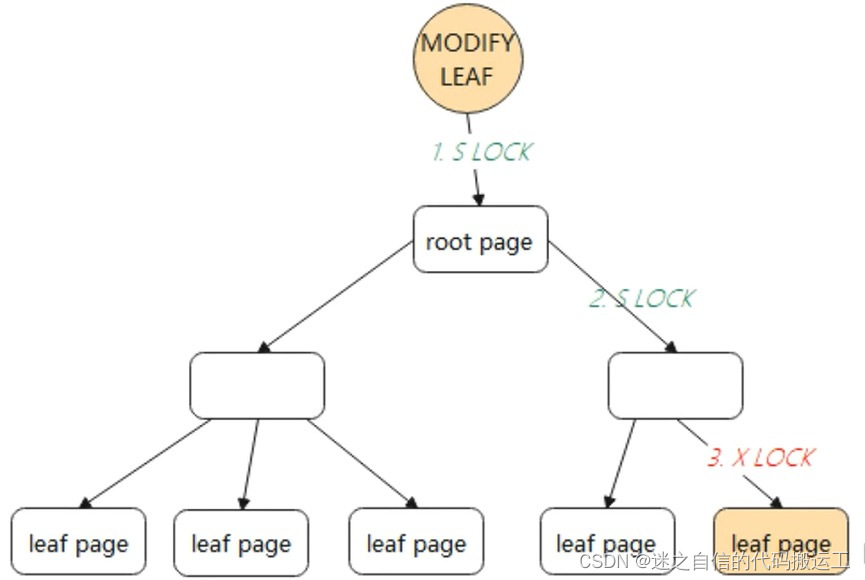
假设⼀个B+树⾼为2,即存在⼀个根节点和若⼲个叶⼦节点,那么这棵 B+树的存放总记录数为: 根节点指针数*单个叶⼦节点记录⾏数 计算根节点指针书:假设表的主键为INT类型,占用的就是4个字节,或者是BIGINT占用8个字节。指针大小为6个字节。一个查询页(B+Tree中的一个节点)16KB,大概可以存储:16384B/(4B+6B)=1638,一个节点最多可以存储1638个索引指针。 计算没个椰子节点的记录数:假如一行记录的数据大小为1k,那么一个页就可以存储16行数据,16kb/1kb=16. 一颗高度为2的B+Tree可以存放的记录数为:1638*16=26208条数据记录,同样的原理可以推算出⼀个⾼度3的B+Tree可以存放: 1638 *1638 * 16 = 42928704条这样的记录 所以InnoDB中的B+Tree⾼度⼀般为1-3层,就可以满⾜千万级别的数据存储,在查找数据时⼀次⻚的查找代表⼀次 IO,通过主键索引查询通常只需要 1-3 次 IO 操作即可查找到数据。 2. MySQL单表数据不能过大的根本原因是什么? 2.1 猜想一:是索引深度吗?根据上面所讲的,索引深度没有那么容易增加。 搜索路径延长导致性能下降的说法,与当时的机械硬盘和内存条件不无关系。 之前机械硬盘的IOPS在100左右,而现在普遍使用的SSD的IOPS已经过万,之前的内存最大几十G,现在服务器内存最大可达到TB级。 因此,即使深度增加,以目前的硬件资源,IO也不会成为限制MySQL单表数据量的根本性因素。 2.2 猜想二:是SMO无法并发吗?我们可以尝试从MySQL所采用的存储引擎InnoDB本身来探究一下。 大家知道InnoDB引擎使用的是索引组织表,它是通过索引来组织数据的,而它采用B+tree作为索引的数据结构。 B+Tree操作非原子,所以当一个线程做结构调整(SMO,Struction-Modification-Operation)时一般会涉及多个节点的改动。 SMO动作过程中,此时若有另一个线程进来可能会访问到错误的B+Tree结构,InnoDB为了解决这个问题采用了乐观锁和悲观锁的并发控制协议。 InnoDB对于叶子节点的修改操作如下: 方式一,先采用乐观锁的方式尝试进行修改 对根节点加S锁(shared lock,叫共享锁,也称读锁),依次对非叶子节点加S锁。 如果叶子节点的修改不会引起B+Tree结构变动,如分裂、合并等操作,那么只需要对叶子节点进行加X锁(exclusive lock,叫排他锁,也称为写锁)即可完成修改。如下图中所示 :
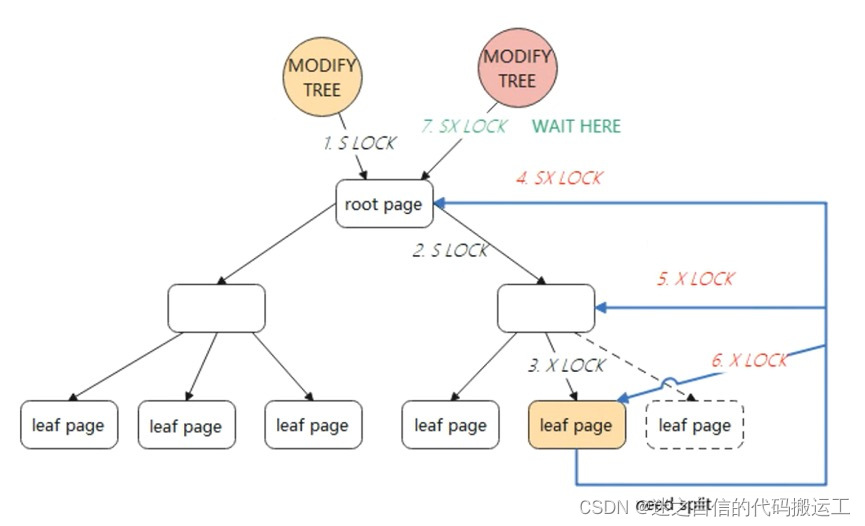
方式二,采用悲观锁的方式 如果对叶子结点的修改会触发SMO,那么会采用悲观锁的方式。 采用悲观锁,需要重新遍历B+Tree,对根节点加全局SX锁(SX锁是行锁),然后从根节点到叶子节点可能修改的节点加X锁。 在整个SMO过程中,根节点始终持有SX锁(SX锁表示有意向修改这个保护的范围,SX锁与SX锁、X锁冲突,与S锁不冲突),此时其他的SMO则需要等待。
因此,InnoDB对于简单的主键查询比较快,因为数据都存储在叶子节点中,但对于数据量大且改操作比较多的TP型业务,并发会有很严重的瓶颈问题。 在对叶子节点的修改操作中,InnoDB可以实现较好的1与1、1与2的并发,但是无法解决2的并发。因为在方式2中,根节点始终持有SX锁,必须串行执行,等待上一个SMO操作完成。这样在具有大量的SMO操作时,InnoDB的B+Tree实现就会出现很严重的性能瓶颈。
|
【本文地址】
今日新闻 |
推荐新闻 |