三样本孟德尔随机化简介 |
您所在的位置:网站首页 › mr孟德尔 › 三样本孟德尔随机化简介 |
三样本孟德尔随机化简介
|
在孟德尔随机化研究(Mendelian randomization,MR)中,最常见的是单样本和双样本孟德尔随机化设计。这两种类型的孟德尔随机化研究通常只选取一小部分和暴露密切相关的单核苷酸多态性位点(SNP)作为工具变量,并通过各种生物学或者统计学方法去说明这些SNP是符合如下的MR三原则: (1)工具变量与暴露密切相关; (2)工具变量与任何影响暴露-结局关联的混杂因素均不相关; (3)除非借助与暴露的关联,否则工具变量不会影响结局。 然而,我们需要注意两个问题: (1)MR的第三条假设需要充分了解相关基因的机制才能被证实为合理,而一些新的生物学发现很可能使得这第三条假设不成立; (2)如果只使用一小部分SNP作为工具变量(通常小于100个),那么这些SNP能解释暴露的程度就比较小,带来的统计效力也比较小。 在之前的推送中,米老鼠和大家介绍过“弱工具变量”的概念,这里我再和大家回顾一下:一般来说,MR的弱工具变量是指虽然和暴露的统计学关联不是很强,但是依然能提供有价值的信息的SNP,尤其是当弱工具变量较多时。这里的“弱工具变量”可能只是针对某一个特定的数据集而言,比如SNP rs123456在某个只有300例肥胖样本的全基因组关联研究(genome-wide association study,GWAS)中p值只有0.01,而这个SNP在同样表型的万人GWAS研究中的p值是0.00001。那么,如果使用300例样本GWAS的估计值,则该SNP就是一个弱工具变量,因为大样本中证实该SNP和肥胖密切相关了。因此,我们很有必要去使用这些弱工具变量来开展MR研究。 在上一期的推送中,米老鼠和大家推荐了mr.raps这个包(mr.raps包的实操与解读),该包最大的特征就是能在存在大量弱工具变量的情况下依旧给出稳健估计,并且能增大统计效力。这个包使用的其实就是一个三样本MR设计。三样本MR研究一般需要遵循如下要求: (1)工具变量挑选集(selection dataset):该数据集用于挑选合适的SNP,是关于暴露的GWAS数据集; (2)SNP-暴露关联集(exposure dataset):该数据集用于提供SNP-暴露的相关统计量(beta,se和p); (3)SNP-结局关联集(outcome dataset):该数据集用于提供SNP-结局的相关统计量(beta,se和p)。 需要注意的是,这三个数据集要求彼此独立,并且SNP-暴露关联集的研究质量要高。一般来说,在挑选集中选择工具变量时一般会把p值放的比较大,如0.001等,这样才能增加更多的SNP信息,因为增加这些SNP后,SNP能解释暴露的程度就更大了,具体如下图所示: 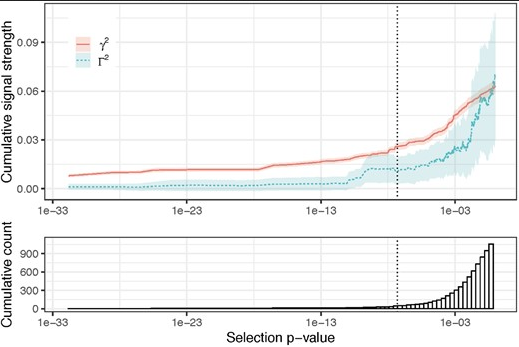 当依据p值选择好SNP后,我们再进行clump,这样我们就能获得大量工具变量,一般有1000个工具变量左右,然后利用分别提取这些工具变量在暴露和结局数据集中的信息,最后用mr.raps包进行分析即可。 关于三样本孟德尔随机化研究的设计和基本思路就和大家介绍到这里,有兴趣的小伙伴可以仔细研究研究! 参考文献: 1. Zhao Q, Chen Y, Wang J, Small DS. Powerful three-sample genome-wide design and robust statistical inference in summary-data Mendelian randomization. Int J Epidemiol. 2019 Oct 1;48(5):1478-1492.2. Qingyuan Zhao. Jingshu Wang. Gibran Hemani. Jack Bowden. Dylan S. Small. "Statistical inference in two-sample summary-data Mendelian randomization using robust adjusted profile score." Ann. Statist. 48 (3) 1742 - 1769, June 2020. |
【本文地址】
今日新闻 |
推荐新闻 |