非关系型数据库 |
您所在的位置:网站首页 › mongodb是分布式的吗 › 非关系型数据库 |
非关系型数据库
|
在学习MongoDB之前,需要先了解一下什么是非关系型数据库。 非关系型数据库介绍非关系型数据库也叫NoSql数据库,(NoSQL = Not Only SQL ),意即"不仅仅是SQL"。NoSql用于超大规模数据的存储(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,通常指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定,常用于存储非结构化的数据。例如,以键值对存储,且结构不固定,每一个元组可以有不一样的字段,每个元组可以根据需要增加一些自己的键值对,这样就不会局限于固定的结构,可以减少一些时间和空间的开销。使用这种方式,用户可以根据需要去添加自己需要的字段,这样,为了获取用户的不同信息,不需要像关系型数据库中,要对多表进行关联查询。仅需要根据id取出相应的value就可以完成查询。 常见的NoSQL数据库:类型 部分代表 特点 列存储 Hbase Cassandra Hypertable 顾名思义,是按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的IO优势。 文档存储 MongoDB CouchDB 文档存储一般用类似json的格式存储,存储的内容是文档型的。这样也就有有机会对某些字段建立索引,实现关系数据库的某些功能。 key-value存储 Tokyo Cabinet / Tyrant Berkeley DB MemcacheDB Redis 可以通过key快速查询到其value。一般来说,存储不管value的格式,照单全收。(Redis包含了其他功能) 图存储 Neo4J FlockDB 图形关系的最佳存储。使用传统关系数据库来解决的话性能低下,而且设计使用不方便。 对象存储 db4o Versant 通过类似面向对象语言的语法操作数据库,通过对象的方式存取数据。 xml数据库 Berkeley DB XML BaseX 高效的存储XML数据,并支持XML的内部查询语法,比如XQuery,Xpath。 非关系型数据库与关系型数据库的区别区别 关系型数据库 非关系型数据库 存储方式 表格式存储。 存储在表的行和列中。他们之间很容易关联协作存储,提取数据很方便 通常存储在数据集中,如文档、键值对或者图结构。 存储结构 结构化数据。 数据表都预先定义了结构(列的定义),结构描述了数据的形式和内容。这一点对数据建模至关重要,虽然预定义结构带来了可靠性和稳定性(优点),但是修改这些数据比较困难(缺点)。 基于动态结构,使用非结构化数据。因为Nosql数据库是动态结构,可以很容易适应数据类型和结构的变化。 查询方式 使用结构化查询语言来操作数据库(就是我们通常说的SQL)关系型数据库使用预定义优化方式(比如索引)来加快查询操作 复杂查询可以用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询。 以块为单元操作数据,使用的是非结构化查询语言(UnQl),它是没有标准的 Nosql中存储文档的ID 更简单更精确的数据访问模式 事务 遵循ACID规则(原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)) 支持对事务原子性细粒度控制,并且易于回滚事务。 遵循BASE原则(基本可用(Basically Availble)、软/柔性事务(Soft-state )、最终一致性(Eventual Consistency)) 可在CAP定理(一致性、可用性、分区容忍度)中最多较好的同时满足两个,在基于节点的分布式系统中,很难全部满足,所以对事务的支持不是很好,虽然也可以使用事务,但是并不是Nosql的优势。 性能 为了维护数据的一致性付出了巨大的代价,读写性能比较差。在面对高并发情况时读写性能较差,面对海量数据的时候效率低。 Nosql存储的格式都是key-value类型的,并且存储在内存中,非常容易存储,而且对于数据的 一致性是 弱要求。Nosql无需sql的解析,提高了读写性能。 非关系型数据库的优缺点及使用场景 优点:非关系型数据库存储数据的格式可以是 key-value 形式、文档形式、图片形式等。使用灵活,应用场景广泛,而关系型数据库则只支持基础类型。 速度快,效率高。 NoSQL 可以使用硬盘或者随机存储器作为载体,而关系型数据库只能使用硬盘。 海量数据的维护和处理非常轻松,成本低。 非关系型数据库具有扩展简单、高并发、高稳定性、成本低廉的优势。 可以实现数据的分布式处理 缺点:非关系型数据库暂时不提供 SQL 支持,学习和使用成本较高。 非关系数据库没有事务处理,无法保证数据的完整性和安全性。适合处理海量数据,但是不一定安全。 功能没有关系型数据库完善。 复杂表关联查询不容易实现。 使用场景:随着互联网企业的不断发展,数据日益增多,因此关系型数据库面对海量的数据会存在很多的不足。 关系型数据库的最大优点就是事务的一致性,这个特性,使得关系型数据库中可以适用于一切要求一致性比较高的系统中,比如:银行系统。 但是在网页应用中,对这种一致性的要求不是那么的严格,允许有一定的时间间隔,所以关系型数据库这个特点不是那么的重要了。相反,关系型数据库为了维护一致性所付出的巨大代价就是读写性能比较差。而像微博、facebook这类应用,对于并发读写能力要求极高,关系型数据库已经无法应付。所以必须用一种新的数据结构存储来替代关系型数据库,非关系型数据库便应运而生。 对非关系型数据库的基本概念有了初步的了解后,以下内容将介绍一种目前最为流行的非关系型数据库之一——MongoDB。 什么是MongoDB? 简介MongoDB 是一个基于分布式文件存储的数据库。 由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。 MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。 MongoDB 将数据存储为一个文档,数据结构由键值(key=>value)对组成。MongoDB 文档类似于 JSON 对象。字段值可以包含其他文档,数组及文档数组。 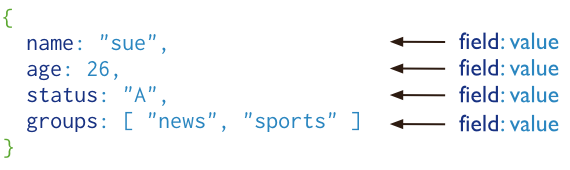 体系结构及操作
体系结构及操作
MongoDB被称之为最像关系数据库的NoSQL 数据概念: 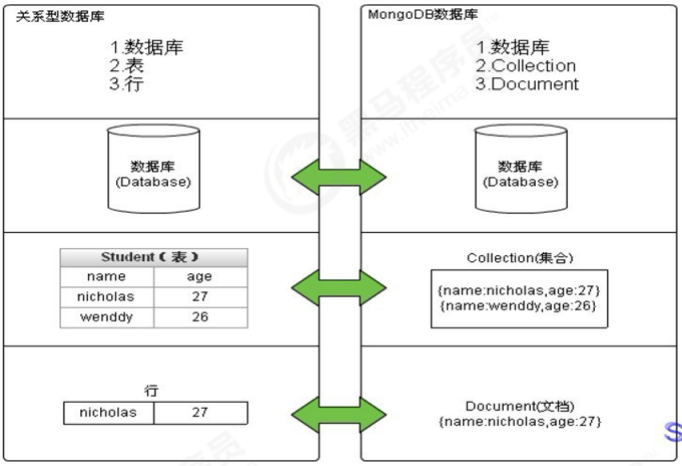
从这张图便可看出来,MongoDB的数据存储结构可谓与MySQL非常相似 SQL术语/概念 MongoDB术语/概念 解释/说明 database database 数据库 table collection 数据库表/集合 row document 数据记录行/文档 column field 数据字段/域 index index 索引 table joins 表连接,MongoDB不支持 primary key primary key 主键,MongoDB自动将_id字段设置为主键 实例:  数据库(Database)
数据库(Database)
一个mongodb中可以建立多个数据库。 MongoDB的默认数据库为"db",该数据库存储在data目录中。 MongoDB的单个实例可以容纳多个独立的数据库,每一个都有自己的集合和权限,不同的数据库也放置在不同的文件中。 选择和创建数据库 如果数据库不存在,则创建数据库,否则切换到指定数据库。 use 数据库名称查看有权限查看的所有数据库命令 show dbs 或者 show databasesMongoDB 中默认的数据库为 test,如果你没有创建新的数据库,集合将存放在 test 数据库中。 显示当前正在使用的数据库命令 db删除数据库 db.dropDatabase()删除数据库需要先使用use database切换到所要删除的数据库 注意: 在 MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。 数据库也通过名字来标识。数据库名可以是满足以下条件的任意UTF-8字符串。 不能是空字符串("")。 不得含有' '(空格)、.、$、/、\和\0 (空字符)。 应全部小写。 最多64字节。 有一些数据库名是保留的,可以直接访问这些有特殊作用的数据库。 admin: 从权限的角度来看,这是"root"数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。 local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合 config: 当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。 集合(Collection)集合就是MongoDB中的文档组,类似关系型数据库中的表。 集合存在于数据库中,集合没有固定的结构,这意味着你在对集合可以插入不同格式和类型的数据,但通常情况下我们插入集合的数据都会有一定的关联性。 集合可以显式的创建,也可以隐式的创建(创建文档时生成)。 集合的显式创建 db.createCollection(name,options)参数说明: name: 要创建的集合名称 options: 可选参数, 指定有关内存大小及索引的选项 options 可以是如下参数: 字段 类型 描述 capped 布尔 (可选)如果为 true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。 当该值为 true 时,必须指定 size 参数。 autoIndexId 布尔 3.2 之后不再支持该参数。(可选)如为 true,自动在 _id 字段创建索引。默认为 false。 size 数值 (可选)为固定集合指定一个最大值,即字节数。 如果 capped 为 true,也需要指定该字段。 max 数值 (可选)指定固定集合中包含文档的最大数量。 在插入文档时,MongoDB 首先检查固定集合的 size 字段,然后检查 max 字段。 集合的隐式创建 当向一个集合中插入一个文档的时候,如果集合不存在,则会自动创建集合。 详见文档的插入章节查看当前库中的集合 show collections 或 show tables集合的删除 db.collection.drop()返回值 如果成功删除选定集合,则 drop() 方法返回 true,否则返回 false。 例如:要删除mycollection集合 db.mycollection.drop()集合的命名规范: 集合名不能是空字符串""。 集合名不能含有\0字符(空字符),这个字符表示集合名的结尾。 集合名不能以"system."开头,这是为系统集合保留的前缀。 用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。 Capped collections Capped collections 就是固定大小的collection。 它有很高的性能以及队列过期的特性(过期按照插入的顺序). 有点和 "RRD" 概念类似。 Capped collections 是高性能自动的维护对象的插入顺序。它非常适合类似记录日志的功能和标准的 collection 不同,你必须要显式的创建一个capped collection,指定一个 collection 的大小,单位是字节。collection 的数据存储空间值提前分配的。 Capped collections 可以按照文档的插入顺序保存到集合中,而且这些文档在磁盘上存放位置也是按照插入顺序来保存的,所以当我们更新Capped collections 中文档的时候,更新后的文档不可以超过之前文档的大小,这样话就可以确保所有文档在磁盘上的位置一直保持不变。 由于 Capped collection 是按照文档的插入顺序而不是使用索引确定插入位置,这样的话可以提高增添数据的效率。MongoDB 的操作日志文件 oplog.rs 就是利用 Capped Collection 来实现的。 要注意的是指定的存储大小包含了数据库的头信息。 db.createCollection("mycoll",{capped:true,size:100000})在 capped collection 中,你能添加新的对象。 能进行更新,然而,对象不会增加存储空间。如果增加,更新就会失败 。 使用 Capped Collection 不能删除一个文档,可以使用 drop() 方法删除 collection 所有的行。 删除之后,你必须显式的重新创建这个 collection。 在32bit机器中,capped collection 最大存储为 1e9( 1X109)个字节。 文档(Document)文档是一组键值(key-value)对(即 BSON)。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。 文档的插入 MongoDB 使用 insert() 或 save() 方法向集合中插入文档,语法如下: db.collection.insert(, { writeConcern: , ordered: })参数说明: document:要写入的文档。 writeConcern:写入策略,默认为 1,即要求确认写操作,0 是不要求。 ordered:指定是否按顺序写入,默认 true,按顺序写入。 save():如果 _id 主键存在则更新数据,如果不存在就插入数据。该方法新版本中已废弃,可以使用 db.collection.insertOne() 或 db.collection.replaceOne() 来代替。 insert(): 若插入的数据主键已经存在,则会抛 org.springframework.dao.DuplicateKeyException 异常,提示主键重复,不保存当前数据 示例:要向comment的集合(表)中插入一条测试数据 db.comment.insert({"articleid":"100000","content":"今天天气真好,阳光明 媚","userid":"1001","nickname":"Rose","createdatetime":new Date(),"likenum":NumberInt(10),"state":null})提示: 1)comment集合如果不存在,则会隐式创建 2)mongo中的数字,默认情况下是double类型,如果要存整型,必须使用函数NumberInt(整型数字),否则取出来就有问题了。 3)插入当前日期使用 new Date() 4)插入的数据没有指定 _id ,会自动生成主键值 5)如果某字段没值,可以赋值为null,或不写该字段。 执行后,如下,说明插入一个数据成功了。 WriteResult({ "nInserted" : 1 })3.2 版本之后新增了 db.collection.insertOne() 和 db.collection.insertMany()。 db.collection.insertOne() 用于向集合插入一个新文档,语法格式如下: db.collection.insertOne( , { writeConcern: } )db.collection.insertMany() 用于向集合插入一个多个文档,语法格式如下: db.collection.insertMany( [ , , ... ], { writeConcern: , ordered: } )示例:批量插入多条文章评论 try { db.comment.insertMany([ {"_id":"1","articleid":"100001","content":"我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我 他。","userid":"1002","nickname":"相忘于江湖","createdatetime":new Date("2019-08- 05T22:08:15.522Z"),"likenum":NumberInt(1000),"state":"1"}, {"_id":"2","articleid":"100001","content":"我夏天空腹喝凉开水,冬天喝温开水","userid":"1005","nickname":"伊人憔 悴","createdatetime":new Date("2019-08-05T23:58:51.485Z"),"likenum":NumberInt(888),"state":"1"}, {"_id":"3","articleid":"100001","content":"我一直喝凉开水,冬天夏天都喝。","userid":"1004","nickname":"杰克船 长","createdatetime":new Date("2019-08-06T01:05:06.321Z"),"likenum":NumberInt(666),"state":"1"}, {"_id":"4","articleid":"100001","content":"专家说不能空腹吃饭,影响健康。","userid":"1003","nickname":"凯 撒","createdatetime":new Date("2019-08-06T08:18:35.288Z"),"likenum":NumberInt(2000),"state":"1"}, {"_id":"5","articleid":"100001","content":"研究表明,刚烧开的水千万不能喝,因为烫 嘴。","userid":"1003","nickname":"凯撒","createdatetime":new Date("2019-08- 06T11:01:02.521Z"),"likenum":NumberInt(3000),"state":"1"} ]); } catch (e) { print (e); }提示: 插入时指定了 _id ,则主键就是该值。 如果某条数据插入失败,将会终止插入,但已经插入成功的数据不会回滚掉。 因为批量插入由于数据较多容易出现失败,因此,可以使用try catch进行异常捕捉处理,测试的时候可以不处理。 文档的查询 MongoDB 查询文档使用 find() 方法。 查询数据的语法格式如下: db.collection.find(query, projection)参数说明: query :可选,使用查询操作符指定查询条件 projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)。 示例:查询comment集合中userid为1003的记录 db.comment.find({userid:'1003'})如果你只需要返回符合条件的第一条数据,我们可以使用fifindOne命令来实现,语法和fifind一样。 如果要查询结果返回部分字段,则需要使用投影查询(不显示所有字段,只显示指定的字段) 如:查询结果只显示 _id、userid、nickname : >db.comment.find({userid:"1003"},{userid:1,nickname:1}) { "_id" : "4", "userid" : "1003", "nickname" : "凯撒" } { "_id" : "5", "userid" : "1003", "nickname" : "凯撒" }默认 _id 会显示。 如:查询结果只显示 、userid、nickname ,不显示 _id : >db.comment.find({userid:"1003"},{userid:1,nickname:1,_id:0}) { "userid" : "1003", "nickname" : "凯撒" } { "userid" : "1003", "nickname" : "凯撒" }再例如:查询所有数据,但只显示 _id、userid、nickname : >db.comment.find({},{userid:1,nickname:1})如果你需要以易读的方式来读取数据,可以使用 pretty() 方法,语法格式如下: db.collection.find().pretty()pretty() 方法以格式化的方式来显示所有文档。 MongoDB中的条件查询 如果你熟悉常规的 SQL 数据,通过下表可以更好的理解 MongoDB 的条件语句查询: 操作 格式 范例 RDBMS中的类似语句 等于 {:} db.col.find({"by":"test"}).pretty() where by = 'test' 小于 {:{$lt:}} db.col.find({"likes":{$lt:50}}).pretty() where likes < 50 小于或等于 {:{$lte:}} db.col.find({"likes":{$lte:50}}).pretty() where likes 50 大于或等于 {:{$gte:}} db.col.find({"likes":{$gte:50}}).pretty() where likes >= 50 不等于 {:{$ne:}} db.col.find({"likes":{$ne:50}}).pretty() where likes != 50 MongoDB AND 条件 MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,即常规 SQL 的 AND 条件。 语法格式如下: >db.col.find({key1:value1, key2:value2}).pretty()MongoDB OR 条件 MongoDB OR 条件语句使用了关键字 $or,语法格式如下: >db.col.find( { $or: [ {key1: value1}, {key2:value2} ] } ).pretty()文档的更新 update() 方法 db.collection.update(query, update, options) //或 db.collection.update( , , { upsert: , multi: , writeConcern: , collation: , arrayFilters: [ , ... ], hint: // Available starting in MongoDB 4.2 } )参数说明: query : update的查询条件,类似sql update查询内where后面的。 update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的 upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。 multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。 writeConcern :可选,抛出异常的级别。 示例: (1)覆盖的修改 如果我们想修改_id为1的记录,点赞量为1001,输入以下语句: db.comment.update({_id:"1"},{likenum:NumberInt(1001)})执行后,我们会发现,这条文档除了likenum字段其它字段都不见了, (2)局部修改 为了解决这个问题,我们需要使用修改器$set来实现,命令如下: 我们想修改_id为2的记录,浏览量为889,输入以下语句: db.comment.update({_id:"2"},{$set:{likenum:NumberInt(889)}})(3)批量的修改 更新所有用户为 1003 的用户的昵称为 凯撒大帝 。 //默认只修改第一条数据 db.comment.update({userid:"1003"},{$set:{nickname:"凯撒2"}}) //修改所有符合条件的数据 db.comment.update({userid:"1003"},{$set:{nickname:"凯撒大帝"}},{multi:true})提示:如果不加后面的参数,则只更新符合条件的第一条记录 (4)列值增长的修改 如果我们想实现对某列值在原有值的基础上进行增加或减少,可以使用 $inc 运算符来实现。 需求:对3号数据的点赞数,每次递增1 db.comment.update({_id:"3"},{$inc:{likenum:NumberInt(1)}})文档的删除: MongoDB remove() 函数是用来移除集合中的数据。 MongoDB 数据更新可以使用 update() 函数。在执行 remove() 函数前先执行 find() 命令来判断执行的条件是否正确,这是一个比较好的习惯。 remove() 方法的基本语法格式如下所示: db.collection.remove( , )参数说明: query :(可选)删除的文档的条件。 justOne : (可选)如果设为 true 或 1,则只删除一个文档,如果不设置该参数,或使用默认值 false,则删除所有匹配条件的文档。 示例: 删除_id=1的记录,输入以下语句: db.comment.remove({_id:"1"})以上就是MongoDB数据库中文档增删改查的一些基本操作。 注意: 文档中的键/值对是有序的。 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。 MongoDB区分类型和大小写。 MongoDB的文档不能有重复的键。 文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符 文档键命名规范: 键不能含有\0 (空字符)。这个字符用来表示键的结尾。 .和$有特别的意义,只有在特定环境下才能使用。 以下划线"_"开头的键是保留的(不是严格要求的)。 参考地址: MongoDB 官网:https://www.mongodb.com/ MongoDB中文网:https://www.mongodb.org.cn/ MongoDBCompass使用手册:什么是MongoDB Compass?— MongoDB Compass 初次撰写博客,内容仅供参考学习,有待完善,若有不足之处,还望指出。 |
【本文地址】
今日新闻 |
推荐新闻 |