MangoDB与HBase对比 |
您所在的位置:网站首页 › mongdb和redis的区别 › MangoDB与HBase对比 |
MangoDB与HBase对比
|
前言
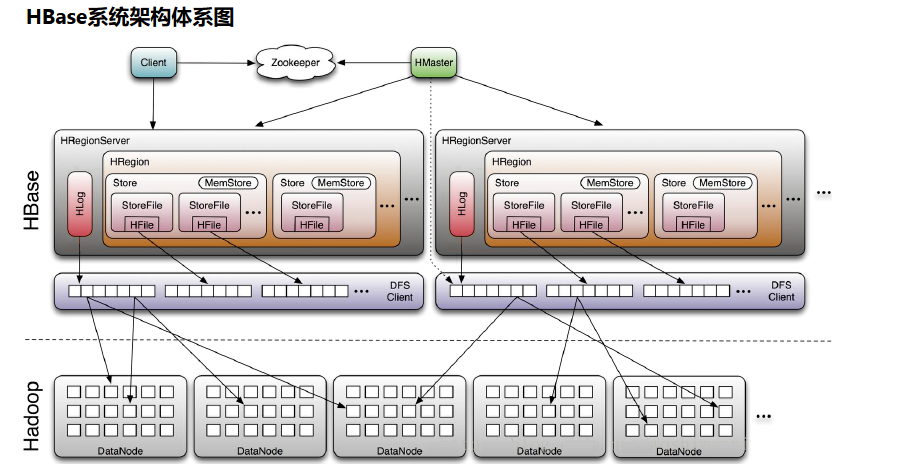
传统数据库遇到的问题,数据量很大的时候无法存储;没有很好的备份机制;数据达到一定数量开始缓慢,很大的话基本无法支撑;因此我们需要探究更加合适的数据库来支撑我们的业务。 HBase 什么是HBaseHbase(Hadoop Database)是建立在HDFS之上的分布式、面向列的NoSQL的数据库系统。 HBase特点优点: 海量存储:适合存储PB级别的海量数据,采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。列式存储(半结构化或非结构化数据):即列族存储,对于数据结构字段不够确定或杂乱无章非常难按一个概念去进行抽取的数据适合用。极易扩展:一个是基于上层处理能力(RegionServer)的扩展,提升Hbsae服务更多Region的能力。一个是基于存储的扩展(HDFS),通过横向添加Datanode的机器,进行存储层扩容,提升Hbase的数据存储能力和提升后端存储的读写能力。高并发:采用廉价PC,能获得高并发、低延迟、高性能的服务。稀疏:列族中,可以指定任意多的列,列数据为空不会占用存储空间的,也提高了读性能。多版本号数据:依据Row key和Column key定位到的Value能够有随意数量的版本号值,版本号默认是单元格插入时的时间戳。适用于插入比查询操作更频繁的情况:比如,对于历史记录表和日志文件。数据类型单一:HBase中数据类型都是字符串。无模式:每一行都有一个可以排序的rowKey和任意多的截然不同的列。缺点: 单一RowKey固有的局限性决定了它不可能有效地支持多条件查询。不适合于大范围扫描查询。不直接支持 SQL 的语句查询。仅支持行级(单行)事务(HBase的事务是行级事务,可以保证行级数据的原子性、一致性、隔离性以及持久性)。HBase的配置非常麻烦,最低的限度都需要包括Zookeeper ensemble、primary HMaster、secondary HMaster、RegionServers、active NameNode、standby NameNode、HDFS quorum journal manager及DataNodes。使用HBase需求大量的专业知识——甚至是最简单的监视。RegionServer存在单点故障,当它发生故障时,一个新的RegionServer必须被选举出,而在可以投入之前,必须重新完成write-ahead日志里的内容,即故障恢复较慢,WAL回放较慢。HBase的API非常笨拙并且具有太强的Java特色,非Java客户端只能委托给Thrit或者REST。 HBase的体系结构
值得参考的网址:HBase基本概念与基本使用 - 牧梦者 - 博客园 HBase使用场景Hbase是一个通过廉价PC机器集群来存储海量数据的分布式数据库解决方案。它比较适合的场景概括如下: 是巨量大(百T、PB级别)查询简单(基于rowkey或者rowkey范围查询)不涉及到复杂的关联有几个典型的场景特别适合使用Hbase来存储: 海量订单流水数据(长久保存)交易记录数据库历史数据 如何使用HBase三种模式:单机模式,伪分布式模式,分布式模式 一般生产环境用的是分布式模式,如果是学习的话,可以用单机模式和伪分布式模式。 安装zookeeper zookeeper 安装及配置_CN-LILU的博客-CSDN博客_zookeeper配置 全分布式模式的Hbase集群需要运行ZooKeeper实例,默认情况下HBase自身维护着一组默认的ZooKeeper实例,可以自己配置实例,这样Hbase会更加健壮 注意:使用默认的实例时,HBase将自动启动或停止ZooKeeper,当使用独立的ZooKeeper实例时,需要用户手动启动和停止ZooKeeper实例 安装Hadoop hadoop分布式安装 安装HBase Hbase学习笔记(安装和基础知识及操作) - wishyouhappy - 博客园 hbase_home/conf/hbase-site.xml文件中的configuration加入:
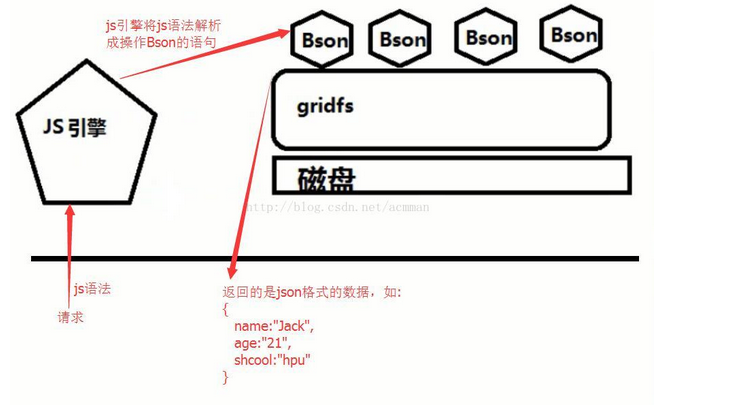
注意事项: 1.关于Hadoop 1. 目前的HBase只能依赖特定的Hadoop版本,HBae和Hadoop之间的RPC是版本话的,需要调用方与被调用方相互匹配,细微的差异可能导致通信失败 2. 由于Hadoop依赖于Hadoop,它要求Hadoop的JAR必须部署在HBase的lib目录下。HBase使用的Hadoop版本必须与底层Hadoop集群上使用的Hadoop版本一直,因而使用Hadoop集群上运行的JAR替换HBase的lib目录中依赖的Hadoop的JAR可以避免版本不匹配的问题 3. 集群中所有的节点都要更新为一样的JAR,否则版本不匹配问题可能造成集群无法启动或者假死现象 2.关于HBase Shell 1.如果使用的分布式模式,那么在关闭Hadoop之前一定要确认HBase已经被正常关闭了 2. 使用stop-hbase.sh关闭HBase时,控制台会打印关于停止的信息,会周期性的打印 ".",关闭脚本需要几分钟完成,如果集群中机器数量很多,那么执行时间会更长 介绍比较全面的网址:hbase总结~hbase配置和使用 - 皇族极炫 - 博客园 了解完HBase后,可带着问题看这一篇文章:https://blog.csdn.net/nosqlnotes/article/details/79647096 MongoDB 什么是MongoDBMongoDB是一个介于关系数据库和非关系数据库之间,基于分布式文件存储,由C 语言编写的数据库。 MongoDB特点优点 高性能 MongoDB提供高性能的数据持久性。特别是, 对嵌入式数据模型的支持减少了数据库系统上的I / O活动。 索引支持更快的查询,并且可以包括来自嵌入式文档和数组的键。 丰富的查询语言 MongoDB支持丰富的查询语言,以支持读写操作(CRUD)以及: 资料汇总 文本搜索和地理空间查询。 SQL到MongoDB的映射图 SQL到聚合的映射图 高可用性 MongoDB的复制工具(称为副本集)提供: 自动故障转移 数据冗余。 甲副本集是一组保持相同的数据集,从而提供冗余和提高数据可用性的MongoDB服务器。 水平可伸缩性 MongoDB提供水平可伸缩性作为其核心 功能的一部分: 分片在一组计算机集群分布数据。 从3.4开始,MongoDB支持基于shard键创建数据区域。在平衡的集群中,MongoDB仅将区域覆盖的读写定向到区域内的那些分片。 支持多种存储引擎 MongoDB支持多个存储引擎: WiredTiger存储引擎(包括对静态加密的支持 ) 内存中存储引擎。 此外,MongoDB提供可插拔的存储引擎API,允许第三方为MongoDB开发存储引擎。 MongoDB原理mongodb在电脑磁盘文件系统之上,又包装了自己的一套文件系统---gridfs,里面存储的是一个一个的json二进制对象,也就是Bson。
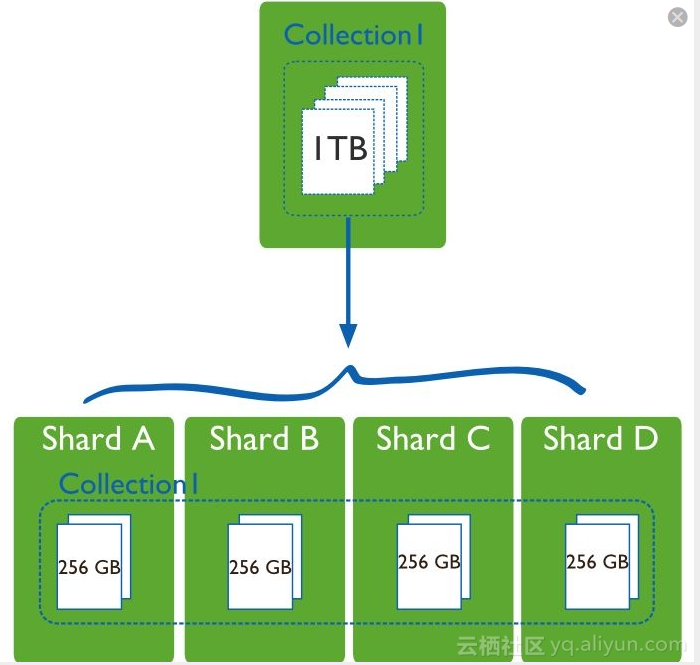
存储容量需求超出单机磁盘容量时,用分片技术去解决
详情可参考网址: MongoDB分片原理篇 - 王守昌 - 博客园 mongodb主要用来干嘛,什么时候用,存什么样的数据?_justlpf的专栏-CSDN博客_mongodb一般用来干啥 场景适用 适用场景 MongoDB 的主要目标是在键/值存储方式(提供了高性能和高度伸缩性)和传统的RDBMS 系统(具有丰富的功能)之间架起一座桥梁,它集两者的优势于一身。根据官方网站的描述,Mongo 适用于以下场景。 ● 网站数据:Mongo 非常适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。 ● 缓存:由于性能很高,Mongo 也适合作为信息基础设施的缓存层。在系统重启之后,由Mongo 搭建的持久化缓存层可以避免下层的数据源过载。 ● 大尺寸、低价值的数据:使用传统的关系型数据库存储一些数据时可能会比较昂贵,在此之前,很多时候程序员往往会选择传统的文件进行存储。 ● 高伸缩性的场景:Mongo 非常适合由数十或数百台服务器组成的数据库,Mongo 的路线图中已经包含对MapReduce 引擎的内置支持。 ● 用于对象及JSON 数据的存储:Mongo 的BSON 数据格式非常适合文档化格式的存储及查询。 不适场景 ● 传统的商业智能应用:针对特定问题的BI 数据库会产生高度优化的查询方式。对于此类应用,数据仓库可能是更合适的选择。 ● 需要SQL 的问题。 如何使用MongoDBlinux平台安装MongoDB Linux 平台安装 MongoDB | 菜鸟教程 spring中集成MongoDB,通过引入MongoDB的maven依赖,引入约束mongo来配置spring托管 xmlns:mongo="http://www.springframework.org/schema/data/mongo" xsi:schemaLocation=" http://www.springframework.org/schema/data/mongo http://www.springframework.org/schema/data/mongo/spring-mongo-1.0.xsd"配置连接池
在实体类中加入相应的@Document、@id、@Indexed、@PersistenceConstructor注解,来实现对数据实例化对象进行增删改查的操作。 详细信息可参考网址:在Spring项目中集成使用MongoDB_禤永豪-CSDN博客 |




【本文地址】
今日新闻 |
推荐新闻 |