数据挖掘 |
您所在的位置:网站首页 › modeler数据预处理 › 数据挖掘 |
数据挖掘
|
《数据挖掘》国防科技大学 《数据挖掘》青岛大学 《数据挖掘与python实践》 数据挖掘之数据预处理 1. 数据清洗 Data Cleaning数据清洗:缺失值、噪声数据、离群点、不一致数据 (1)对于丢失数据: 忽略元组(对象),特别是缺少类标签时删除缺失值比例较大的属性手动补全:麻烦自动插值:均值、众数等 (2)对于噪声数据和离群点:识别噪声数据并去除:聚类、回归使用箱线图检测离群点并删除平滑噪音以降低噪声数据的影响:分箱法binning、概念分层 分箱法: 按箱平均值平滑 按箱中值平滑 按箱边界平滑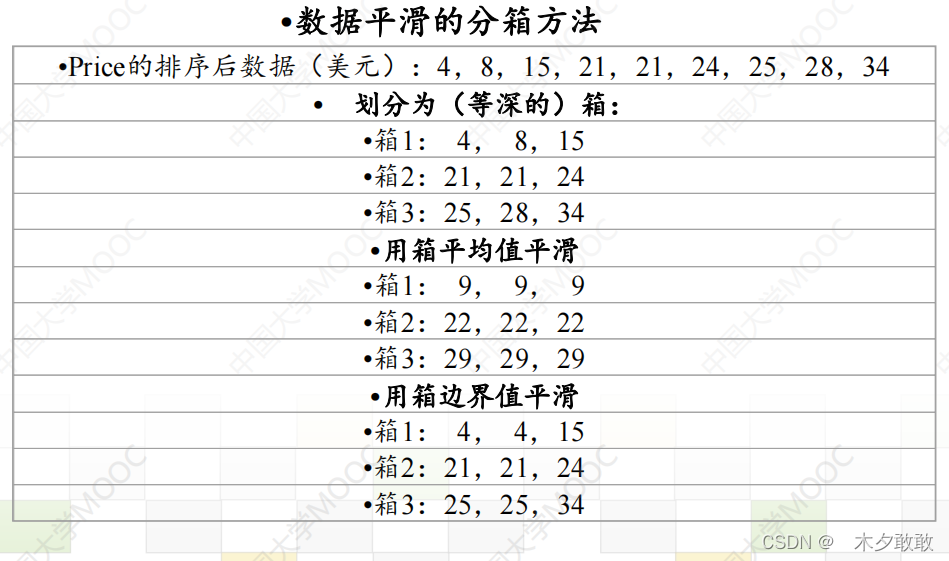 (3)对于不一致数据 计算推理、替换、全局替换
2. 数据集成 (3)对于不一致数据 计算推理、替换、全局替换
2. 数据集成
数据集成:整合多个数据库、多维数据集或文件 (1)模式集成:统一同一含义的字段名 (2)实体识别:统一同一对象的不同称呼 (3)数据冲突和解决:统一单位 (4)冗余信息处理:相同对象或属性的不同名称、表征同一特征的多个属性 相关性分析 ① 卡方检验——离散变量——越大越相关 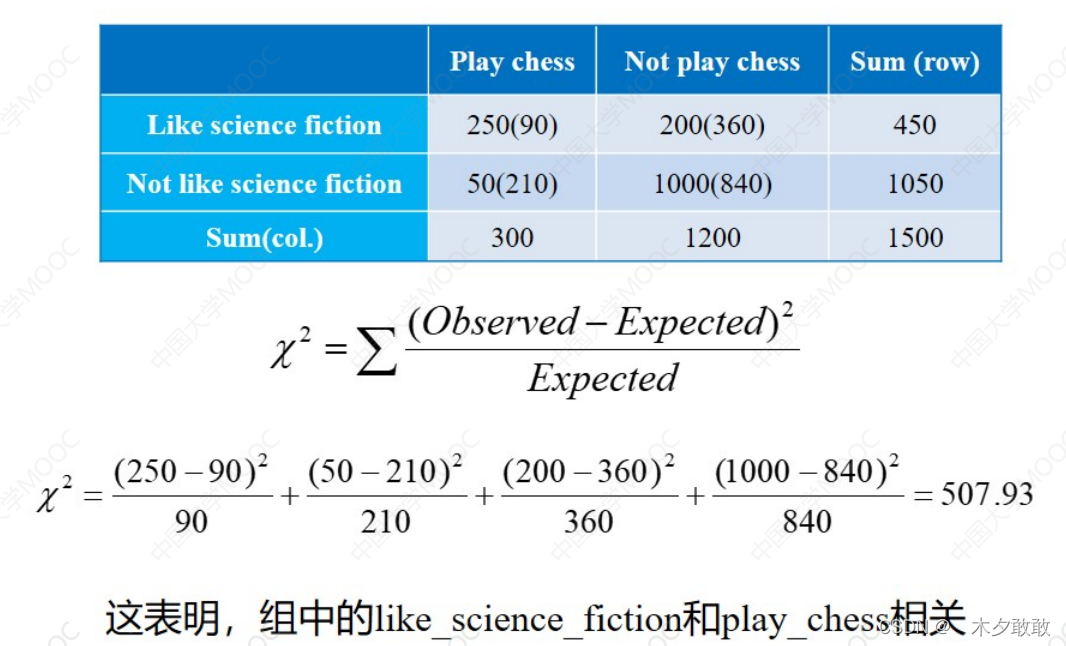 观测值(期望值),期望值=行合计×列合计/总数 ② 相关系数(皮尔逊相关系数)——连续变量——越大越相关 观测值(期望值),期望值=行合计×列合计/总数 ② 相关系数(皮尔逊相关系数)——连续变量——越大越相关  协方差分析 协方差分析  3. 数据缩减
3. 数据缩减
数据缩减/规约/压缩:降维、降数据 ➢用于数据归约的时间不应当超过或“抵消”在归约后的数据集上挖掘节省的时间。 ➢归约得到的数据比原数据小得多,但可以产生相同或几乎相同的分析结果。 (1)降维/维归约(检测并删除不想管、弱相关或冗余的属性维) 主成分分析PCA(将多个相同的属性合并成一个) 计算花费低,可以用于有序和无序的属性,并且可以处理稀疏和倾斜数据。属性子集选择 属性子集选择的目标是找出最小属性集,使得数据类的概率分布尽可能地接近使用所有属性的原分布。通常使用压缩搜索空间的启发式算法,策略是做局部最优选择,期望由此导致全局最优解。 ① 逐步向前选择 该过程由空属性集开始,选择原属性集中最好的属性,并将它添加到该集合中。在其后的每一次迭代,将原属性集剩下的最好的属性添加到该集合中。 ② 逐步向后删除 该过程由整个属性集开始。在每一步,删除掉尚在属性集中的最坏属性。如:粗糙集理论 ③ 向前选择和向后删除的结合 将向前选择和向后删除方法结合在一起; 每一步选择一个最好的属性,并在剩余属性中删除一个最坏的属性。 ④ 判定树归纳 判定树归纳构造一个类似于流程图的结构,其每个内部(非树叶)节点表示一个属性上的测试,每个分枝对应于测试的一个输出;每个外部(树 叶)节点表示一个判定类。在每个节点,算法选择“最好”的属性,将数据划分成类。数据立方体聚集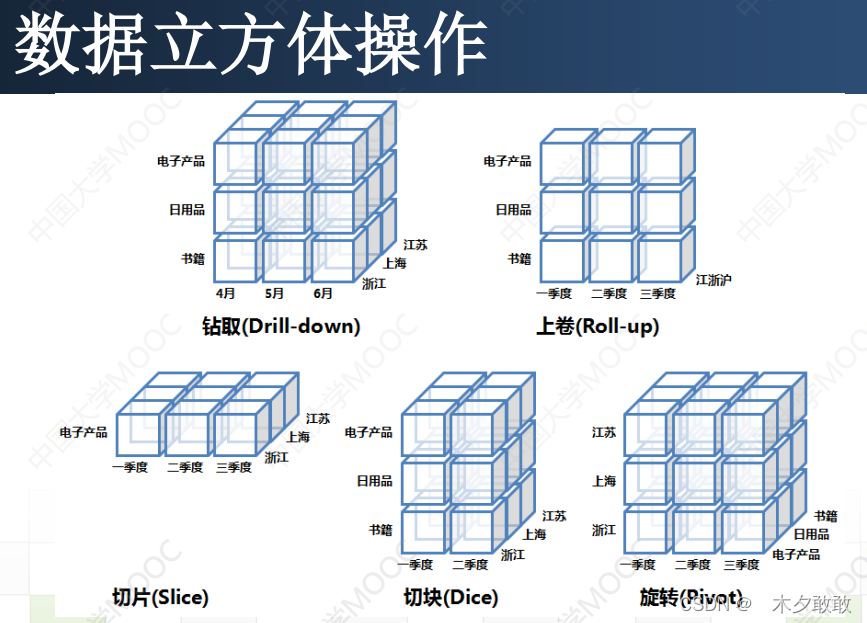 (2)降数据:数据规模太大时简单抽样:放回/不放回随机抽样分层抽样:先分层后取样聚类抽样:先聚类后取样 (3)数据压缩无损压缩有损压缩 小波变换: 可用于多维数据;对于稀疏或倾斜数据和具有有序属性的数据,小波变换可以给出很好的结果。 主成分分析
4. 数据转换和数据离散化 (2)降数据:数据规模太大时简单抽样:放回/不放回随机抽样分层抽样:先分层后取样聚类抽样:先聚类后取样 (3)数据压缩无损压缩有损压缩 小波变换: 可用于多维数据;对于稀疏或倾斜数据和具有有序属性的数据,小波变换可以给出很好的结果。 主成分分析
4. 数据转换和数据离散化
规范化、离散化、生成概念层次结构 (1)规范化 最小最大规范化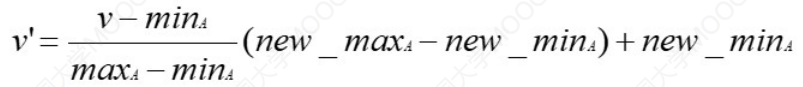 Z得分规范化:书用于分布不变的流式数据 Z得分规范化:书用于分布不变的流式数据  小数定标规范化 小数定标规范化 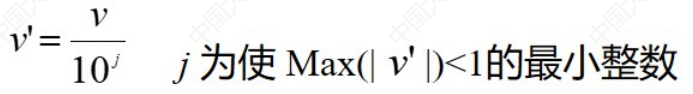 移动位数依赖于最大绝对数 (2)离散化非监督离散
等宽法:根据属性的值域划分,每个区间的宽度相等等频法:根据取值出现的频数划分,并要求落在每个区间的样本数目相等聚类:利用聚类将数据划分到不同的离散类别 有监督离散
基于熵的离散化 移动位数依赖于最大绝对数 (2)离散化非监督离散
等宽法:根据属性的值域划分,每个区间的宽度相等等频法:根据取值出现的频数划分,并要求落在每个区间的样本数目相等聚类:利用聚类将数据划分到不同的离散类别 有监督离散
基于熵的离散化   ChiMerge方法:合并相邻小区间为大区间,基于统计量卡方检验实现 ChiMerge方法:合并相邻小区间为大区间,基于统计量卡方检验实现 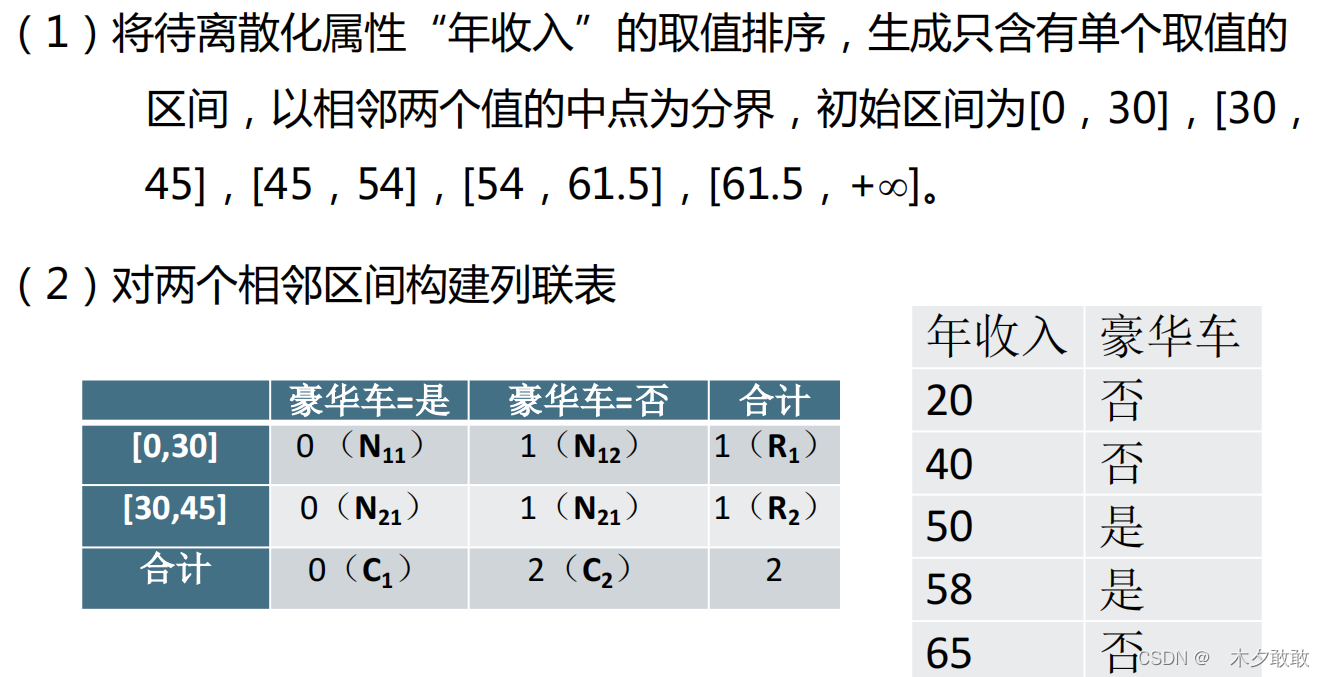  (3)数据概化:使用概念分层用更抽样的概念取代低层次或数据层的数据对象。 如数值型的年龄属性映射到年轻、中年和老年。 如街道属性繁华到更高层次的城市、国家等。 (3)数据概化:使用概念分层用更抽样的概念取代低层次或数据层的数据对象。 如数值型的年龄属性映射到年轻、中年和老年。 如街道属性繁华到更高层次的城市、国家等。
|
【本文地址】
今日新闻 |
推荐新闻 |