写出比系统库更快的memcpy |
您所在的位置:网站首页 › memcpy乱码 › 写出比系统库更快的memcpy |
写出比系统库更快的memcpy
|
前几天在思考一个有意思的问题:如何写出一个更快的memcpy,尝试了多种解法 下面就整理一下这几种不同的写法,并简要说明背后的原理,不当之处希望大家批评指正。 ———————————————————— 更新1:发现自己考虑的比较简单,更详细的可参考评论区 https://www.zhihu.com/question/35172305 需求:请你实现一个memcpy ·输入是地址1、地址2、拷贝的长度; ·输出是地址1先放实验结论:说明:以下memcpy版本是层层递进的,使用10w长度大于256的随机字符串,gcc开-O 0优化 测试表明,性能:版本1 < 版本2 < 版本3 < 版本4 其中版本4比版本1快了近乎3倍 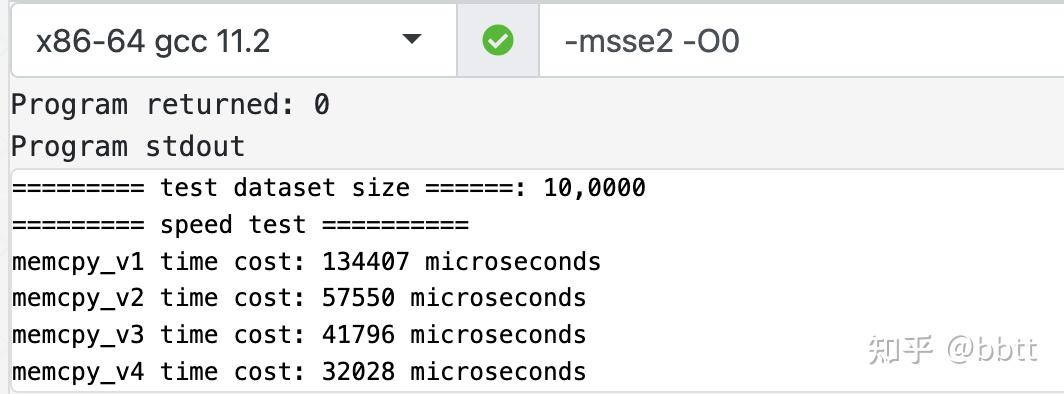 数据量 10w随机生成的字符串版本1:标准版 数据量 10w随机生成的字符串版本1:标准版这是源码的标准版,朴实无华 循环次数:n void* memcpy_v1(void* dst, const void* src, size_t len) { char* d = (char*) dst; const char* s = (const char*) src; while (len--) *d++ = *s++; return dst; } 版本2:循环展开利用CPU流水线处理的指令的能力,解除数据依赖,(原理是前一条指令在译码,后一条语句在取指,充分压榨CPU处理器)  循环次数:n/4 void* memcpy_v2(void* dst, const void* src, size_t len) { char* d = (char*) dst; const char* s = (const char*) src; size_t i = 0; for (; i + 4 = 128) { c0 = _mm_loadu_si128(reinterpret_cast(src) + 0); c1 = _mm_loadu_si128(reinterpret_cast(src) + 1); c2 = _mm_loadu_si128(reinterpret_cast(src) + 2); c3 = _mm_loadu_si128(reinterpret_cast(src) + 3); c4 = _mm_loadu_si128(reinterpret_cast(src) + 4); c5 = _mm_loadu_si128(reinterpret_cast(src) + 5); c6 = _mm_loadu_si128(reinterpret_cast(src) + 6); c7 = _mm_loadu_si128(reinterpret_cast(src) + 7); src += 128; _mm_store_si128((reinterpret_cast(dst) + 0), c0); _mm_store_si128((reinterpret_cast(dst) + 1), c1); _mm_store_si128((reinterpret_cast(dst) + 2), c2); _mm_store_si128((reinterpret_cast(dst) + 3), c3); _mm_store_si128((reinterpret_cast(dst) + 4), c4); _mm_store_si128((reinterpret_cast(dst) + 5), c5); _mm_store_si128((reinterpret_cast(dst) + 6), c6); _mm_store_si128((reinterpret_cast(dst) + 7), c7); dst += 128; size -= 128; } /// The latest remaining 0..127 bytes will be processed as usual. goto tail; } } return ret; }完结撒花(优雅,永不过时 —— 卡密尔) 参考:ClickHouse - Fast Open-Source OLAP DBMS https://github.com/ClickHouse/ClickHouse/blob/master/base/glibc-compatibility/memcpy/memcpy.h 漫谈SIMD、SSE指令集与ClickHouse向量化执行 Compiler Explorer |
【本文地址】
今日新闻 |
推荐新闻 |