机器学习:mAP评价指标 |
您所在的位置:网站首页 › ma指标是什么意思 › 机器学习:mAP评价指标 |
机器学习:mAP评价指标
|
一、前言
mAP是目标检测模型中常用的评价指标,它的英文全称是(Mean Average Precision),翻译过来就是平均精确率的平均。 首先我们需要知道精确率(Precision)和召回率(Recall),也称为查准率和查全率的定义 Precision衡量你的预测有多准确。也就是说,你的预测正确的百分比。 Recall衡量您发现所有正例的能力。 例如,我们可以在前K个预测中找到80%的正例。 下面是它们的数学定义:
如果对此不太清楚,具体介绍请看精确率和召回率的介绍。 接下来我们需要知道交并比IoU(Intersection over union) IoU度量两个边界之间的重叠。我们使用它来度量我们的预测边界与ground truth(实际对象边界)的重叠程度。在一些数据集中,我们预先定义了一个IoU阈值(比如0.5)来分类预测是真阳性还是假阳性。
首先介绍的是最简单的AP的一般化定义和计算。我们通过举例说明,在本例中,整个数据集仅包含5个苹果。我们收集了所有图片中所有对苹果的预测,并根据预测的置信度按降序排列。第二列表示预测是否正确。在本例中,如果
I
o
U
≥
0.5
IoU\geq 0.5
IoU≥0.5,则预测是正确的。 这里略加解释一下,以SSD模型为例,输入一张图片进行预测,模型最后的输出的形状是(锚框数,6),6代表着每个锚框对应的类别标签+置信度+锚框的四个坐标。 上表数据集当中只有5个苹果,但是在对数据集的预测过程中,一共得到了10个类别标签是苹果的锚框。那么我们我们怎么去获取该锚框的真实label,或称真实值,也就是它实际上是不是一个苹果? 方法是计算模型预测出来的锚框和人工标注的锚框(我们称之为Groud truth,真实值)的交并比,如果交并比超过0.5,那么认为该预测是正确的,即实际上该锚框框起来的是一个苹果。但是在实际预测当中,经常会出现多个预测锚框跟同一个GT(Groud Truth)的IoU值都大于0.5, 这个时候只将这些预测框中置信度最大的算是一个苹果,其他不算苹果。 上面的过程是获取锚框的真实label,因为目标检测和普通的分类任务不一样,锚框是模型生成的,而非人工输入,我们只有一个groud truth,所以只能用groud truth去获取锚框的真实label。 接下来就是锚框的预测值,上面我们得到了10个锚框,它们都说自己是苹果,但是我们知道置信度很低我们很难相信它就是一个苹果,所以需要设定一个阈值,大于等于该阈值的我们把该锚框设为是苹果,低于该阈值的我们把该锚框设为不是苹果。(模型的目的是生成一些预测值高的锚框,同时它们确实是该类别的锚框,也就是跟GT的交并比很高)。 然后回到上面关于苹果那张表,首先我们把阈值就设定为rank1的置信度,会得到下面这张表: Rank预测值真实值1是苹果是苹果2不是苹果是苹果3不是苹果不是苹果4不是苹果不是苹果5不是苹果不是苹果6不是苹果是苹果7不是苹果是苹果8不是苹果不是苹果9不是苹果不是苹果10不是苹果是苹果T P = 1 , F P = 0 , F N = 4 TP=1,FP=0,FN=4 TP=1,FP=0,FN=4 P r e c i s i o n = T P T P + F P = 1 , R e c a l l = T P T P + F N = 0.2 Precision=\frac{TP}{TP+FP}=1,\quad Recall=\frac{TP}{TP+FN}=0.2 Precision=TP+FPTP=1,Recall=TP+FNTP=0.2 这里TP+FP=计算集合的大小,FN=整个数据集中没有被识别出来的Groud Truth。 同理,我们可以计算包括了rank1,rank2,rank3的集合的PR值。 T P = 2 , F P = 1 , F N = 2 TP=2,FP=1,FN=2 TP=2,FP=1,FN=2 P r e c i s i o n = T P T P + F P = 0.667 , R e c a l l = T P T P + F N = 0.4 Precision=\frac{TP}{TP+FP}=0.667,\quad Recall=\frac{TP}{TP+FN}=0.4 Precision=TP+FPTP=0.667,Recall=TP+FNTP=0.4 于是通过计算每一步,我们得到了下面的PR曲线。 好了,到这里我们就了解了最一般化的AP值的计算方式,就是求PR曲线跟两坐标轴围起来的面积,我们称之为PR曲线下面积 PR-AUC(Area Under Curve)。但是去做这样的积分是很难的,因为我们只能得到离散的点,所以只能通过离散的点去拟合AUC。下面介绍几种拟合的方法。 2.Interpolated AP 插值AP在Pascal VOC2008中,计算的是11点插值AP。(注:PASCAL VOC是一个流行的对象检测数据集) 以下是更精确的数学定义。 然而,这种插值方法是一种近似值,它存在两个问题。 第一、它不那么精确,上面的例子之所以感觉衡量的挺好是因为例子中的召回率的离散值只有五个,PR曲线的褶皱最多只有五个。我们取11个点来计算面积效果是好的,但是当召回率离散值的数量远大于11时(现实情况往往如此),褶皱也大于11时,用11个点拟合的面积和真实情况下的面积就差很多,精确性就下降。从另外一个角度讲,AP可理解成不同召回率的情况下所有精确率的平均值,当召回率的离散值个数远大于11时,这时11个点的平均精确率无法代表所有召回值的平均精确率。 其次,它失去了测量低AP方法差异的能力,该缺点也是由低精确率引发的。 因此,2008年以后,PASCAL VOC采用了不同的AP计算方法。 3.VOC2010-2012中AP的计算方法相对于11点采样,在后来的Pascal VOC竞赛中,AP的计算更接近AUC。 在11点插值AP当中,是用10个长为0.1,宽为 P i n t e r p ( r i ) , i = 1 , 2 , . . . , 10 P_{interp}(r_i),i=1,2,...,10 Pinterp(ri),i=1,2,...,10来拟合该面积。 为了提高精确性,在新的计算方式中,使用m个长度为 r n + 1 − r n r_{n+1}-r_n rn+1−rn,宽为 P i n t e r p ( r n + ) , i = 1 , 2 , . . . , m P_{interp}(r_{n+}),i=1,2,...,m Pinterp(rn+),i=1,2,...,m来拟合该面积,这里m是召回率离散值的数量。 因为在现实情况中 m > > 11 m>>11 m>>11,所以后者的计算更精确,更接近AUC。 注意到,这里一共是有m个矩形。m是召回率的数量,其实也是数据集中所有正例的数量。因为召回率就是目前获得的TP/数据集中的所有正例,它的取值就是1/m,2/m,一直到m/m。 此时每个矩形的长都是1/m,所以求曲线下面积就是把每个召回率r对应的
p
(
r
)
=
max
r
^
≥
r
p
(
r
^
)
p(r)=\max _{\hat r \geq r}p(\hat r)
p(r)=maxr^≥rp(r^)加起来,再除以m。下面给出一个例子。 最后到我们开始谈论的mAP,上面我们计算的AP都是针对一个类别而言的,如苹果,当我们把所有类别的AP都计算出来后,再对它们求平均值,即可得到mAP。 四、总结 1.为什么要用AP或者mAP我们希望一个模型的Precision和Recall都很高,所以需要综合考虑这两个因素,我们可以联想到用调和平均数F1-beta值来衡量,另一种方法正是PR曲线下的面积AUC,这也就是AP。AUC面积越接近1性能越好。曲线下的面积理解为不同召回值的情况下所有精度的平均值。 五、参考文献【1】https://medium.com/@jonathan_hui/map-mean-average-precision-for-object-detection-45c121a31173 【2】http://blog.sina.com.cn/s/blog_9db078090102whzw.html 【3】https://zhuanlan.zhihu.com/p/107989173?from_voters_page=true |



 平均精度(AP)的广义定义是找到上面的PR曲线下的面积。
A
P
=
∫
0
1
p
(
r
)
d
r
AP=\int _0^1p(r)dr
AP=∫01p(r)dr 精确度和召回率总是在0到1之间。因此,AP也在0和1之间。在计算用于目标检测的AP之前,我们通常先将锯齿状的图形平滑化。
平均精度(AP)的广义定义是找到上面的PR曲线下的面积。
A
P
=
∫
0
1
p
(
r
)
d
r
AP=\int _0^1p(r)dr
AP=∫01p(r)dr 精确度和召回率总是在0到1之间。因此,AP也在0和1之间。在计算用于目标检测的AP之前,我们通常先将锯齿状的图形平滑化。  从图上看,在每个召回率上,我们将它的精确率替换为该召回率右侧的所有召回率对应的精确率的最大值。因此,橙色的线被转换成绿色的线,曲线会单调地减少,而不是之字形。这时因为一般来讲PR曲线的变化情形都是下面这样的,进行平滑是为了让其符合一般化规律。
从图上看,在每个召回率上,我们将它的精确率替换为该召回率右侧的所有召回率对应的精确率的最大值。因此,橙色的线被转换成绿色的线,曲线会单调地减少,而不是之字形。这时因为一般来讲PR曲线的变化情形都是下面这样的,进行平滑是为了让其符合一般化规律。  所以经过平滑后召回率r对应的精确率
p
(
r
)
p(r)
p(r)的修正是:
p
(
r
)
=
max
r
~
≥
r
p
(
r
~
)
p(r)=\max _{\widetilde r\geq r}p(\widetilde r)
p(r)=r
≥rmaxp(r
)
所以经过平滑后召回率r对应的精确率
p
(
r
)
p(r)
p(r)的修正是:
p
(
r
)
=
max
r
~
≥
r
p
(
r
~
)
p(r)=\max _{\widetilde r\geq r}p(\widetilde r)
p(r)=r
≥rmaxp(r
) 首先,我们将0到1.0的召回值分为11个点:0、0.1、0.2、…、0.9和1.0。接下来,我们计算这11个召回值的最大精度值的平均值。
首先,我们将0到1.0的召回值分为11个点:0、0.1、0.2、…、0.9和1.0。接下来,我们计算这11个召回值的最大精度值的平均值。 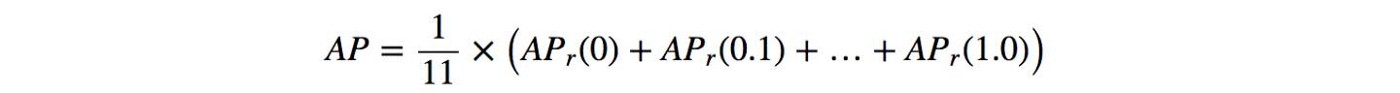 在我们的示例中,AP =(5×1.0 + 4×0.57 + 2×0.5)/ 11
在我们的示例中,AP =(5×1.0 + 4×0.57 + 2×0.5)/ 11 我们看到实际上11点插值法求AP就是在进行了平滑的PR曲线上取十一个点,求平均值,这跟实际我们想要求的AUC很接近了。如果求进行了平滑的PR曲线的AUC的话,应该是
A
P
r
(
1
)
∗
0.1
+
A
P
r
(
2
)
∗
0.1
+
.
.
.
+
A
P
r
(
10
)
∗
0.1
=
1
10
(
A
P
r
(
1
)
+
A
P
r
(
2
)
+
.
.
.
+
A
P
r
(
10
)
)
AP_r(1)*0.1+AP_r(2)*0.1+...+AP_r(10)*0.1=\frac{1}{10}(AP_r(1)+AP_r(2)+...+AP_r(10))
APr(1)∗0.1+APr(2)∗0.1+...+APr(10)∗0.1=101(APr(1)+APr(2)+...+APr(10)) 这个上式上面的AP值很接近。
我们看到实际上11点插值法求AP就是在进行了平滑的PR曲线上取十一个点,求平均值,这跟实际我们想要求的AUC很接近了。如果求进行了平滑的PR曲线的AUC的话,应该是
A
P
r
(
1
)
∗
0.1
+
A
P
r
(
2
)
∗
0.1
+
.
.
.
+
A
P
r
(
10
)
∗
0.1
=
1
10
(
A
P
r
(
1
)
+
A
P
r
(
2
)
+
.
.
.
+
A
P
r
(
10
)
)
AP_r(1)*0.1+AP_r(2)*0.1+...+AP_r(10)*0.1=\frac{1}{10}(AP_r(1)+AP_r(2)+...+AP_r(10))
APr(1)∗0.1+APr(2)∗0.1+...+APr(10)∗0.1=101(APr(1)+APr(2)+...+APr(10)) 这个上式上面的AP值很接近。 该方法中,AP的计算公式为:
该方法中,AP的计算公式为:  AP其实是衡量所有召回率下的平均精确率。而PR-AUC正是所有召回率下的平均精确率。
AP其实是衡量所有召回率下的平均精确率。而PR-AUC正是所有召回率下的平均精确率。 看到第六行这里,
r
=
3
/
6
r=3/6
r=3/6,它实际上对应的
p
(
r
)
=
3
/
6
p(r)=3/6
p(r)=3/6,但修正后的
p
(
r
)
=
4
/
7
p(r)=4/7
p(r)=4/7,因为它右边的
r
=
4
/
6
r=4/6
r=4/6对应的
p
(
r
)
=
4
/
7
p(r)=4/7
p(r)=4/7比
3
/
6
3/6
3/6大。然后把第四列的所有
p
(
r
)
p(r)
p(r)值加起来再除以6,即可得到最终的AP值。
看到第六行这里,
r
=
3
/
6
r=3/6
r=3/6,它实际上对应的
p
(
r
)
=
3
/
6
p(r)=3/6
p(r)=3/6,但修正后的
p
(
r
)
=
4
/
7
p(r)=4/7
p(r)=4/7,因为它右边的
r
=
4
/
6
r=4/6
r=4/6对应的
p
(
r
)
=
4
/
7
p(r)=4/7
p(r)=4/7比
3
/
6
3/6
3/6大。然后把第四列的所有
p
(
r
)
p(r)
p(r)值加起来再除以6,即可得到最终的AP值。【本文地址】
今日新闻 |
推荐新闻 |