使用MATLAB轻松享受GPU的强大功能 |
您所在的位置:网站首页 › matlab调用gpu加速 › 使用MATLAB轻松享受GPU的强大功能 |
使用MATLAB轻松享受GPU的强大功能
|
近年来,使用GPU(通用图形处理器)进行科学计算已变得十分普遍。GPU最初设计用于图像密集型视频游戏产业中的图形渲染绘制,但近年来GPU不断发展,现可用于更广泛的用途。研究人员可对其进行程序设计以执行计算,用于数据分析、数据可视化,以及金融和生物建模等应用。 MATLAB的GPU支持为活跃于许多学科的大量研究人员(不一定是CUDA编程专家)提供了一种加速科学计算的新方法。考虑到MATLAB主要是用于科学计算和工程计算,因此MATLAB最新提供的GPU支持是一种逻辑开发,以便让非编程专家同样能够使用此技术。 有了MATLAB的这些新功能之后,用户便可以利用GPU来实现其应用程序的显著提速,而无需进行低级的C语言程序设计。这一最新技术发展提供了现有方法以外的其他方法来加速特定硬件上的MATLAB算法执行。 使用MATLAB进行GPU程序设计 MATLAB中的CUDA支持为GPU加速后的MATLAB操作提供了基础,并实现了现有CUDA内核与MATLAB应用程序的集成。用户现在可以使用不同的程序设计技术来实现易用性与执行优化两者的适当平衡(参考文献1)。 MATLAB支持启用了CUDA的NVIDIA GPU(具有1.3或更高版本计算功能),例如Tesla 10系列和基于Fermi架构的尖端Tesla 20系列。GPU 1.3版提供的双浮点精度全面支持是保证大多数科学计算不因速度权衡而损失精度(loss Svb)的先决条件,并且可以将代码更改的需要减到最低。 在MATLAB中实现GPU计算的三种方法加速了整个应用程序的进度,并实现了所需的建模复杂度与执行控制间的权衡方案。 在GPU上执行重载的MATLAB函数 最简单的编程模式包括对GPU(GPU数组)上已加载数据的MATLAB函数直接调用。用户可以决定何时在MATLAB工作区和GPU之间移动数据或创建存储在GPU内存中的数据,以尽可能减少主机与设备间数据传输的开销。在第一个版本中,已重载了超过100个MATLAB函数(包括FFT和矩阵除法),以在GPU数组中无缝执行。用户可在同一函数调用中将在GPU上加载的数据和MATLAB工作区中的数据混合,以实现最优的灵活性与易用性。 这种方法提供了一个简单的接口,让用户可以在GPU上直接执行标准函数,从而获得性能提升,而无需花费任何时间开发专门的代码。
当处理存储在GPU内存中的数据时,会重载 \ 操作符以便在GPU上运行。在这种情况下,用户不得对函数进行任何更改,只能指定何时从GPU内存移动和检索数据,这两种操作分别通过gpuArray和gather命令来完成。 在MATLAB中定义GPU内核 作为第二种编程模式,用户可以定义MATLAB函数,执行要对GPU上的向量化数据执行的标量算术运算。使用这种方法,用户可以扩展和自定义在GPU上执行的函数集,以构建复杂应用程序并实现性能加速,因为需要进行的内核调用和数据传输比以前少。 这种编程模式允许用算术方法定义要在GPU上执行的复杂内核,只需使用MATLAB语言即可。使用这种方法,可在GPU上执行复杂的算术运算,充分利用数据并行化并最小化与内核调用和数据传输有关的开销。
同样,在这种情况下,用户不得对函数进行任何更改,只能指定何时从GPU内存移动和检索数据以及使用arrayfun命令调用函数。TaylorFun函数会在A_gpu矢量的各个元素上执行,充分利用数据并行化。 直接从MATLAB调用CUDA代码 为了进一步扩展在GPU上执行的集合函数,可以从CUDA或PTX代码中创建一个MATLAB可调用的GPU内核。第三种编程模式可以让用户轻松地从MATLAB直接调用已有CUDA代码,使非CUDA专家同样能够进行代码重用。 这种编程模式同样有助于CUDA开发人员的工作,因为它提供了直接从MATLAB进行CUDA代码测试的整体解决方案,无需使用GPU在环配置进行基于文件的数据交换。此外,用户还可以直接从MATLAB试用有关线程块大小和共享内存的参数。
对于精通CUDA的程序员而言,这种方法可实现轻松混合串行与高度并行代码的可能,从而获得最优的性能,而无需开发整个应用程序的C语言代码。 在编译代码并生成ptx文件之后,用户可向MATLAB声明该内核,设置有关线程块大小的属性,并直接对数据调用内核。同样,在这种情况下,用户可以决定何时在主机内存与设备之间移动数据,以尽可能减少数据传输的开销。 GPU和CPU间的执行权衡 相比多核处理器,GPU可显著地加速高度并行操作的执行。实践证明,GPU的大规模并行体系结构有助于从金融计算到分子动力学等许多领域的密集科学计算。通过将计算密集型内核映射到GPU并在CPU上运行应用程序的顺序部分,可以将整体执行加速5倍到超过100倍(参考文献2)。 MATLAB GPU支持可以通过无缝方式为大规模并行复杂应用程序提速,而不损失精度。通过支持1.3或更高版本的CUDA,MathWorks解决方案可完全实现GPU上的双浮点精度计算,从而保证不因任何速度权衡而损失精度。 可使用GPU实现的加速主要取决于主机内存和GPU设备间数据传输的开销。计算密集型并行应用程序可减少数据传输量,将能体验更快的程序执行。同样,以上考虑明显适用于在GPU上执行的MATLAB应用程序(参见图 1)。
根据计算复杂度和并行程度的不同,在所有GPU和CPU上执行复杂应用程序时,可以体验到最佳的加速效果。这视程序员的经验和水平而异,要看他是否能确定最佳的执行平台。基于这些原因,很难估计使用GPU可获得的最大加速效果。根据可用的硬件平台和应用程序的复杂性,程序员可以使用MATLAB配置代码以实现最快执行,并作出目标平台的最佳选择(图2)。
结论 为了实现GPU的最大灵活性和易用性,MathWorks提供了不同的编程模式来更好地满足开发人员的偏好。有了MATLAB GPU支持,用户便可以一种无缝且不费力的方式加速其应用程序。此外,GPU支持已集成在Parallel Computing Toolbox中,因此可以对所有具有并行性的应用程序进行加速,无论其位于GPU上还是CPU上,并可最终扩展到集群。因此,MATLAB GPU支持只需最少的编程工作,便可将 MATLAB的任务与数据并行化功能扩展到更多硬件平台。
|
 MATLAB代码示例1,在GPU上执行矩阵除法
MATLAB代码示例1,在GPU上执行矩阵除法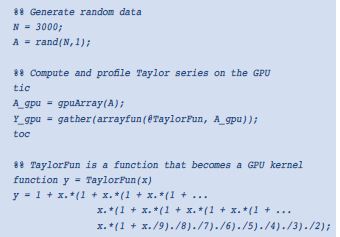 MATLAB代码示例2,将MATLAB函数定义为GPU内核
MATLAB代码示例2,将MATLAB函数定义为GPU内核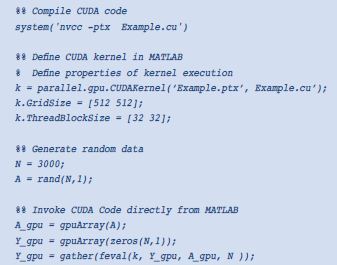 MATLAB代码示例3,直接从MATLAB调用CUDA代码
MATLAB代码示例3,直接从MATLAB调用CUDA代码
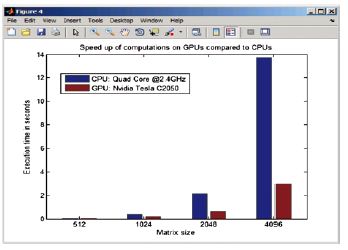 图1,使用双浮点精度实现矩阵除法的计算加速见MATLAB代码示例1所述。注意:对于小型矩阵而言,设备与主机间的数据传输开销是最主要的,因此可能不会发生任何加速,或者GPU上的程序执行甚至可能会比在CPU上的执行还要慢
图1,使用双浮点精度实现矩阵除法的计算加速见MATLAB代码示例1所述。注意:对于小型矩阵而言,设备与主机间的数据传输开销是最主要的,因此可能不会发生任何加速,或者GPU上的程序执行甚至可能会比在CPU上的执行还要慢 图2,计算不同内核大小的泰勒级数所需的执行时间见MATLAB代码示例2所述。注意:当在四核处理器上执行该函数时,MATLAB隐式多线程已对其进行了加速,无需修改应用程序代码。当计算加速大于数据传输的开销时,GPU对复杂函数更有帮助。GPU计算时间几乎与内核复杂度无关
图2,计算不同内核大小的泰勒级数所需的执行时间见MATLAB代码示例2所述。注意:当在四核处理器上执行该函数时,MATLAB隐式多线程已对其进行了加速,无需修改应用程序代码。当计算加速大于数据传输的开销时,GPU对复杂函数更有帮助。GPU计算时间几乎与内核复杂度无关【本文地址】
今日新闻 |
推荐新闻 |