ChatGPT API使用说明官网译文 |
您所在的位置:网站首页 › mar和mad的换算 › ChatGPT API使用说明官网译文 |
ChatGPT API使用说明官网译文
|
ChatGPT API使用说明官网译文 原文网址:https://platform.openai.com/docs/guides/chat/introduction Chat completions(Beta) 聊天完成(测试版) ChatGPT is powered by gpt-3.5-turbo, OpenAI’s most advanced language model. ChatGPT被赋能于gpt-3.5-turbo,是OpenAI的最先进的语言模型。 Using the OpenAI API, you can build your own applications with gpt-3.5-turbo to do things like: 使用这一OpenAI API,你能建立你自己的应用,其使用gpt-3.5-turbo来做一些事情,比如: Draft an email or other piece of writing草拟一封电子邮件或者其他写作片段 Write Python code写Python代码 Answer questions about a set of documents围绕一系列文档来回答问题 Create conversational agents创建对话代理 Give your software a natural language interface给你的软件一个自然语言的接口 Tutor in a range of subjects专业领域指导 Translate languages语言翻译 Simulate characters for video games and much more包括但不限于在可视游戏扮演一个角色 This guide explains how to make an API call for chat-based language models and shares tips for getting good results. 这篇指导解释了如何为基于对话的语言模型做一个API调用,并分享了得到优化结果的一些小窍门。 Introduction 介绍 Chat models take a series of messages as input, and return a model-generated message as output. 对话模型接受一系列消息作为输入,并返回由模型生成的消息作为输出。 Although the chat format is designed to make multi-turn conversations easy, it’s just as useful for single-turn tasks without any conversations (such as those previously served by instruction following models like text-davinci-003). 尽管对话模式可以轻松设置为多轮对话,但目前仅支持单次对话(如同那些早期的模型一样,比如‘文本-达芬奇-003’)。 An example API call looks as follows: 一个API调用的示例如下: 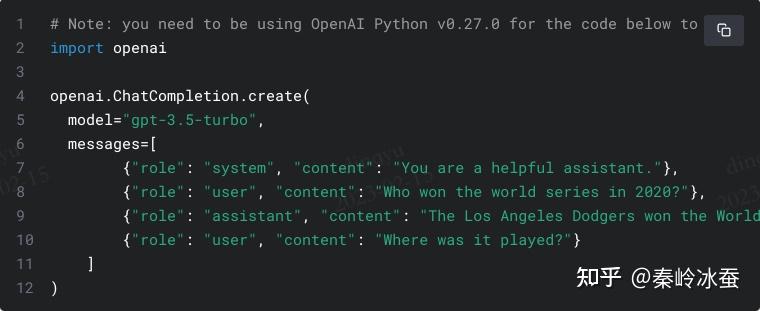 The main input is the messages parameter. Messages must be an array of message objects, where each object has a role (either “system”, “user”, or “assistant”) and content (the content of the message). Conversations can be as short as 1 message or fill many pages. 主要输入是消息参数。消息必须是由消息对象组成的数组,其中每个对象都有一个“role”键(其值可能是“system”,“user”,或“assistant”),以及一个“content”键(用于保存消息内容)。对话可以短为一条,也可以多达几页。 Typically, a conversation is formatted with a system message first, followed by alternating user and assistant messages. 典型的,一次对话被组织为先是一条system消息,紧跟着的是user消息,或者assistant消息。 The system message helps set the behavior of the assistant. In the example above, the assistant was instructed with “You are a helpful assistant.” system消息用来设置assistant的行为。在上面的例子中,assistant被“You are a helpful assistant.”引导。 The user messages help instruct the assistant. They can be generated by the end users of an application, or set by a developer as an instruction. user消息用于指导assistant。可以由应用的最终用户给出,也可以由开发者给出。 The assistant messages help store prior responses. They can also be written by a developer to help give examples of desired behavior. assistant消息帮助存储更早的响应。也可以被开发者重写作为示例来调整模型的预期行为。 Including the conversation history helps when user instructions refer to prior messages. In the example above, the user’s final question of “Where was it played?” only makes sense in the context of the prior messages about the World Series of 2020. Because the models have no memory of past requests, all relevant information must be supplied via the conversation. If a conversation cannot fit within the model’s token limit, it will need to be shortened in some way. 把历史对话涵盖进来会好一些,特别当用户的指导指向更早期的消息的时候。在上面的示例中,用户的最终问题是“Where was it played?”,仅仅在上下文中才有意义,这就是更早的消息,关于“he World Series of 2020”。因为模型没有对过去请求的记忆,因此所有相关信息必须在单次对话中全部呈现。如果对话超出了模型的token限制,那么必须想办法减少它们。 Response format 响应模式 An example API response looks as follows: 一个API响应的模式示例如下:  In Python, the assistant’s reply can be extracted with response[‘choices’][0][‘message’][‘content’]. 在Python里,assistant的回答可以用response[‘choices’][0][‘message’][‘content’]来得到。 Managing tokens 管理tokens Language models read text in chunks called tokens. In English, a token can be as short as one character or as long as one word (e.g., a or apple), and in some languages tokens can be even shorter than one character or even longer than one word. 语言模型会把文本切分为块,称为tokens。在英语中,一个token可以短至一个字符,或者长为一个字(例如,a或apple),在某些语言中,token甚至可以比一个字符还短,又或者比一个字还长。 For example, the string “ChatGPT is great!” is encoded into six tokens: [“Chat”, “G”, “PT”, “ is”, “ great”, “!”]. 举例来说,字符串“ChatGPT is great!”被编码为6个token:[“Chat”, “G”, “PT”, “ is”, “ great”, “!”]。 The total number of tokens in an API call affects: How much your API call costs, as you pay per token How long your API call takes, as writing more tokens takes more time Whether your API call works at all, as total tokens must be below the model’s maximum limit (4096 tokens for gpt-3.5-turbo-0301) 一次API调用中全部token数量会影响:你的API调用成本,因为按照token数量收费;也会影响调用的时长,因为处理更多的token需要更多的时间;甚至影响你的API调用是否成功,因为整个token数量必须在模型的最大处理能力之内(4096个token,就gpt-3.5-turbo-0301而言)。 Both input and output tokens count toward these quantities. For example, if your API call used 10 tokens in the message input and you received 20 tokens in the message output, you would be billed for 30 tokens. 输入与输出token都要计费。比如,你的API调用在消息输入中使用了10个token,在消息输出中接收到20个token,则按照30个token计费。 To see how many tokens are used by an API call, check the usage field in the API response (e.g., response[‘usage’][‘total_tokens’]). 想指导在一次API调用中使用了多少token,可以产看API响应中的usage field(例如,response[‘usage’][‘total_tokens’])。 To see how many tokens are in a text string without making an API call, use OpenAI’s tiktoken Python library. Example code can be found in the OpenAI Cookbook’s guide on how to count tokens with tiktoken. 想知道一段文本有多少token,但还不通过API调用,可以用OpenAI的“tiktoken” Python库。示例代码可以在OpenAI的Cookbook中找到,在“如何用tiktoken计算token”的章节。 Each message passed to the API consumes the number of tokens in the content, role, and other fields, plus a few extra for behind-the-scenes formatting. This may change slightly in the future. 每一条传递给API的消息都会消耗token,包括在content里,role里,和其他地方,另外还会附加一些冗余。这或许在未来会微调。 If a conversation has too many tokens to fit within a model’s maximum limit (e.g., more than 4096 tokens for gpt-3.5-turbo), you will have to truncate, omit, or otherwise shrink your text until it fits. Beware that if a message is removed from the messages input, the model will lose all knowledge of it. 如果一个对话有太多token而无法限定在模型允许范围内(例如,超过了4096个,对gpt-3.5-turbo模型而言),你必须截断、修改、或者缩减你的文本直到其满足要求。要知道,一旦消息从输入中被删除了,模型就将失去关于它的信息。 Note too that very long conversations are more likely to receive incomplete replies. For example, a gpt-3.5-turbo conversation that is 4090 tokens long will have its reply cut off after just 6 tokens. 也要注意,太长的对话也更可能得到不完整的回复。例如,一次gpt-3.5-turbo模型的对话,包含了4090个token,那么其回复就最多只能有6个token。 Instructing chat models 指导对话模型 Best practices for instructing models may change from model version to version. The advice that follows applies to gpt-3.5-turbo-0301 and may not apply to future models. 对于“指导”模型的最好实践或许会随着版本迭代。下面的建议是针对gpt-3.5-turbo-0301 模型的,不一定适用于未来的模型。 Many conversations begin with a system message to gently instruct the assistant. For example, here is one of the system messages used for ChatGPT: 许多对话开始于一个system消息,用来对assistant略作指导。例如,这里有一个system消息用于ChatGPT: You are ChatGPT, a large language model trained by OpenAI. Answer as concisely as possible. Knowledge cutoff: {knowledge_cutoff} Current date: {current_date} (这段是示例,就不翻译了。) In general, gpt-3.5-turbo-0301 does not pay strong attention to the system message, and therefore important instructions are often better placed in a user message. 总体而言,gpt-3.5-turbo-0301并不特别关注system消息,而且重要的指导通常会放在user消息里。 If the model isn’t generating the output you want, feel free to iterate and experiment with potential improvements. You can try approaches like: 如果模型生成的输出不是你想要的,而且你想帮助模型迭代演进。那么试试下面的方法: Make your instruction more explicit让你的指导更具体。 Specify the format you want the answer in细化你想要的答案的格式。 Ask the model to think step by step or debate pros and cons before settling on an answer让模型逐步思考,或者在稳定于一个答案前与之讨论优势与不足。 For more prompt engineering ideas, read the OpenAI Cookbook guide on techniques to improve reliability. 想要更敏捷的工程思想,阅读OpenAI的Cookbook指导,关于“提升可靠性的技术”章节。 Beyond the system message, the temperature and max tokens are two of many options developers have to influence the output of the chat models. For temperature, higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic. In the case of max tokens, if you want to limit a response to a certain length, max tokens can be set to an arbitrary number. This may cause issues for example if you set the max tokens value to 5 since the output will be cut-off and the result will not make sense to users. 除了system消息,温度和最大token也是开发者影响模型输出的“众选项中的两条”。对温度而言,高于0.8会使输出更随机,低于0.2则更聚焦。对于最大token,如果你想把响应限定在特定长度之内,则你可以人工指定这个最大token数。这也可能带来问题,比如你限定最大输出token为5,那么超过5个token的部分都被裁减掉了,对于用户而言,可能得到的是毫无意义的结果。 Chat vs Completions 对话vs完成 Because gpt-3.5-turbo performs at a similar capability to text-davinci-003 but at 10% the price per token, we recommend gpt-3.5-turbo for most use cases. 因为gpt-3.5-turbo在性能上与ext-davinci-003相似,但价格只有10%,我们推荐在大部分场景下使用前者。 For many developers, the transition is as simple as rewriting and retesting a prompt. 对于多数开发者,这一转换就像重写和重新测试一个提示那么简单。 For example, if you translated English to French with the following completions prompt: 例如,如果你把英文翻译为法文,用如下的完成提示:  An equivalent chat conversation could look like: 一个相应的对话则形如:  Or even just the user message: 或者仅仅是用户消息: FAQ 常见问题解答 Is fine-tuning available for gpt-3.5-turbo? 可以对gpt-3.5-turbo精调么? No. As of Mar 1, 2023, you can only fine-tune base GPT-3 models. See the fine-tuning guide for more details on how to use fine-tuned models. 不行。截止到2023年的3月1日,你只能对GPT-3模型进行精调。请查看“精调指导”以获得更多细节,关于如何使用精调模型。 Do you store the data that is passed into the API? 你们会存储传递给API的数据么? As of March 1st, 2023, we retain your API data for 30 days but no longer use your data sent via the API to improve our models. Learn more in our data usage policy. 就2023年3月1日这个时点的规则而言,我们会保留30天,但不会用来优化我们的模型。详情查看我们的“数据使用策略”。 Adding a moderation layer 添加调整层。 If you want to add a moderation layer to the outputs of the Chat API, you can follow our moderation guide to prevent content that violates OpenAI’s usage policies from being shown. 如果你想在模型输出上增加一个调整层,你可以查看我们的“调整指导”,避免所输出的内容触犯OpenAI的使用策略。 |
【本文地址】