|
@ 目录API说明:注意事项如何获取音乐MP3下载地址免费歌曲付费歌曲下载歌曲requests解析网页例程注意这里的MP3的url会随时间过期变化,你要通过前面的教程自己手动获取!根据MP3地址下载音乐例程注意这里的MP3下载的url会随时间过期变化,你要通过前面的教程自己手动获取!完整实战:根据音乐播放地址下载音乐例程完整学习例程总结
欢迎关注 『Python』 系列,持续更新中
欢迎关注 『Python』 系列,持续更新中
爬虫实战之免费爬取付费音乐(保姆级图文+详细代码注释+完整项目代码)
免责声明:本文的初衷是学习爬虫知识的一个实例,通过程序下载的版权音乐24小时侵删。
你是不是在pc端上经常遇到这种情况——音乐无法下载,必须下载客户端才能下载?
爬虫可以解决这个麻烦!
API说明:
response=requests.get(参数1,headers=参数2)
参数1:url 存放被爬取的网页url地址
参数2:可选参数,访问头,模拟浏览器访问信息
返回值:200表示爬取解析网页成功
注意事项
用了反爬机制,自定义headers
time模块用于获取当前时间,给文件命名,其实也可以爬取歌曲名字来命令下载好的歌曲文件(给大家提供一个思路)
因为这只是学习测试,只支持单个歌曲的下载,很简陋,严禁使用本程序大面积下载收费音乐营利!
如何获取音乐MP3下载地址
爬取数据的前提首先是别人让你爬取才行,问题在于找到音乐文件的下载地址!
我们先从免费歌曲开始(付费歌曲在免费歌曲的基础上演变而来)
免费歌曲
谷歌浏览器右键检查(有些浏览器叫审查元素)
在新打开的这个页面中选择网络(network)选项卡,点击刷新(如果你之后下载第二首音乐不刷新的话总是显示第一首音乐)
 随便找一首歌曲:http://www.kuwo.cn/play_detail/197789527打开网页
随便找一首歌曲:http://www.kuwo.cn/play_detail/197789527打开网页
 在这个网络窗口中按F5刷新,注意确保音乐播放的歌曲是你想要的歌曲
你会发现原来空白的网络多了很多东西
然后搜索MP3,找到playurl
在这个网络窗口中按F5刷新,注意确保音乐播放的歌曲是你想要的歌曲
你会发现原来空白的网络多了很多东西
然后搜索MP3,找到playurl
 右键,在新标签页中打开
右键,在新标签页中打开
 到这里,我们得到了一个存放MP3文件地址的json地址
http://www.kuwo.cn/api/v1/www/music/playUrl?mid=197789527&type=music&httpsStatus=1&reqId=23762b30-5e0f-11ec-857c-dfb0b0613858
到这里,我们得到了一个存放MP3文件地址的json地址
http://www.kuwo.cn/api/v1/www/music/playUrl?mid=197789527&type=music&httpsStatus=1&reqId=23762b30-5e0f-11ec-857c-dfb0b0613858
 得到了音乐的下载地址
https://cr-sycdn.kuwo.cn/6ca645b59ddbbda92b20cb7484ce8d60/61ba9655/resource/n2/50/97/3993078800.mp3
得到了音乐的下载地址
https://cr-sycdn.kuwo.cn/6ca645b59ddbbda92b20cb7484ce8d60/61ba9655/resource/n2/50/97/3993078800.mp3
{
"code": 200,
"msg": "success",
"reqId": "a50a453b634c48f7c8b34f155e1b9112",
"data": {
"url": "https://cr-sycdn.kuwo.cn/6ca645b59ddbbda92b20cb7484ce8d60/61ba9655/resource/n2/50/97/3993078800.mp3"
},
"profileId": "site",
"curTime": 1639618133536,
"success": true
}

付费歌曲
和免费歌曲类似,但是你会发现无法获取到他的playurl!
做法:你先获取到一个免费歌曲的存放MP3文件地址的json地址
http://www.kuwo.cn/api/v1/www/music/playUrl?mid=197789527&type=music&httpsStatus=1&reqId=23762b30-5e0f-11ec-857c-dfb0b0613858
你可以多试试几首歌曲,你会发现这里的mid参数是歌曲的一个标志参数
那么你把免费歌曲的mid参数换成付费的试试看:(把197789527换成了228908)
https://www.kuwo.cn/api/v1/www/music/playUrl?mid=228908&type=music&httpsStatus=1&reqId=23762b30-5e0f-11ec-857c-dfb0b0613858
 把其中的type=music改变成type=mp3
https://www.kuwo.cn/api/v1/www/music/playUrl?mid=228908&type=mp3&httpsStatus=1&reqId=23762b30-5e0f-11ec-857c-dfb0b0613858出现了MP3的下载地址
把其中的type=music改变成type=mp3
https://www.kuwo.cn/api/v1/www/music/playUrl?mid=228908&type=mp3&httpsStatus=1&reqId=23762b30-5e0f-11ec-857c-dfb0b0613858出现了MP3的下载地址

下载歌曲
打开MP3地址


requests解析网页例程
注意这里的MP3的url会随时间过期变化,你要通过前面的教程自己手动获取!
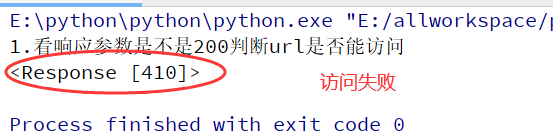
#1.看响应参数是不是200判断url是否能访问
import requests
print("1.看响应参数是不是200判断url是否能访问")
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
'Referer': 'http://www.kuwo.cn/search/list?key=%E5%91%A8%E6%9D%B0%E4%BC%A6',
'csrf': 'RUJ53PGJ4ZD',
'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1577029678,1577034191,1577034210,1577076651; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1577080777; kw_token=RUJ53PGJ4ZD'
}
response=requests.get("https://other-web-ra01-sycdn.kuwo.cn/1647fce2c2c049bf4ef8462545763e61/61ba7d80/resource/n2/128/98/58/4249925507.mp3",headers=headers)
print(response)
根据MP3地址下载音乐例程
注意这里的MP3下载的url会随时间过期变化,你要通过前面的教程自己手动获取!
#2.试着根据黄昏音乐MP3地址url解析成功的结果下载一首音乐,存放在本程序目录下
import requests
print("2.试着根据音乐MP3地址url解析成功的结果下载一首音乐,存放在本程序目录下")
#注意这里的MP3的url会随时间过期变化,你要通过前面的教程自己手动获取!
with open("下载的一首歌曲.mp3","wb") as file:
url="https://other-web-ra01-sycdn.kuwo.cn/1647fce2c2c049bf4ef8462545763e61/61ba7d80/resource/n2/128/98/58/4249925507.mp3"
music = requests.get(url)#获取解析到的数据
file.write(music.content)#把数据写入缓冲区文件
file.flush()#把数据存入缓冲区
file.close()#关闭文件
下图情况有可能是因为url有时效性,我的url你肯定用不了,你得通过上面的获取url教程自己手动获取。
完整实战:根据音乐播放地址下载音乐例程
随便找一个音乐的播放网址:http://www.kuwo.cn/play_detail/197789527
 下载成功
下载成功

#3.输入一首歌曲的地址(不是MP3地址),解析得到音乐,完整项目
import time
import requests
print("3.输入一首歌曲的地址(不是MP3地址),解析得到音乐")
def get_mp3_name():
data_time=time.strftime('%Y-%m-%d-%H-%M-%S', time.localtime())#格式化获取的当地时间
mp3_name=data_time+".mp3"
return mp3_name
def downMusic(url):
# 该网站有反爬机制,要模拟浏览器来进行伪装。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
'Referer': 'http://www.kuwo.cn/search/list?key=%E5%91%A8%E6%9D%B0%E4%BC%A6',
'csrf': 'RUJ53PGJ4ZD',
'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1577029678,1577034191,1577034210,1577076651; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1577080777; kw_token=RUJ53PGJ4ZD'
}
mid=url.split("/")[-1]#假设url是http://www.kuwo.cn/play_detail/196835141,得到mid196835141
#把得到的mid参数填入指定位置得到了存放MP3文件地址的json地址
save_mp3_url="http://www.kuwo.cn/api/v1/www/music/playUrl?mid=%s&type=mp3&httpsStatus=1&reqId=66231ca1-5e04-11ec-96d1-d1bbc17ab269" % mid
mp3_response=requests.get(save_mp3_url,headers=headers)#解析存放MP3文件地址的json地址
mp3_url =mp3_response.json().get("data").get("url")#根据解析存放MP3文件地址的json地址的内容,获取MP3地址
with open(get_mp3_name(), "wb") as file:
music = requests.get(mp3_url,headers=headers) # 获取解析到的数据
file.write(music.content) # 把数据写入缓冲区文件
file.flush() # 把数据存入缓冲区
file.close() # 关闭文件
url = input("输入一首歌曲的播放地址下载歌曲:")
downMusic(url)
完整学习例程
# @Time : 2021/12/16 7:15
# @Author : 南黎
# @FileName: 爬取音乐程序.py
#测试时如果发现歌曲地址解析得到的不是自己想要的歌曲,可能是因为你没有刷新网页的解析结果导致!
#这些地址仅供学习参考,会随时间过期,授人以鱼不如授人以渔
#免费歌曲(以下地址有部分会随时间变化,主要是提供一个思路)
#金玉良缘 歌曲播放地址:http://www.kuwo.cn/play_detail/196835141
#金玉良缘 歌曲播放id: 196835141
#金玉良缘 歌曲MP3地址的存放地址: http://www.kuwo.cn/api/v1/www/music/playUrl?mid=196835141&type=music&httpsStatus=1&reqId=66231ca1-5e04-11ec-96d1-d1bbc17ab269
#金玉良缘 歌曲MP3地址: https://other-web-nf01-sycdn.kuwo.cn/593dddbc7e2c3d8e42c3ad0349ec219b/61ba83b5/resource/n3/68/45/237017447.mp3
#收费歌曲
#你会发现无法获取到网页的playurl
#黄昏 歌曲播放地址:http://www.kuwo.cn/play_detail/1044318
#黄昏 歌曲播放id: 1044318
#黄昏 歌曲MP3地址的原来的存放地址: http://www.kuwo.cn/api/v1/www/music/playUrl?mid=1044318&type=music&httpsStatus=1&reqId=66231ca1-5e04-11ec-96d1-d1bbc17ab269
#黄昏 歌曲MP3地址的修改后存放地址: https://www.kuwo.cn/api/v1/www/music/playUrl?mid=1044318&type=mp3&httpsStatus=1&reqId=66231ca1-5e04-11ec-96d1-d1bbc17ab269
#黄昏 歌曲MP3地址: https://other-web-ra01-sycdn.kuwo.cn/9613a15eacfc54710a0762b566b3235a/61ba850e/resource/n2/128/98/58/4249925507.mp3
#1.看响应参数是不是200判断url是否能访问
import requests
print("1.看响应参数是不是200判断url是否能访问")
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
'Referer': 'http://www.kuwo.cn/search/list?key=%E5%91%A8%E6%9D%B0%E4%BC%A6',
'csrf': 'RUJ53PGJ4ZD',
'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1577029678,1577034191,1577034210,1577076651; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1577080777; kw_token=RUJ53PGJ4ZD'
}
response=requests.get("https://other-web-ra01-sycdn.kuwo.cn/1647fce2c2c049bf4ef8462545763e61/61ba7d80/resource/n2/128/98/58/4249925507.mp3",headers=headers)
print(response)
# 2.试着根据黄昏音乐MP3地址url解析成功的结果下载一首音乐,存放在本程序目录下
import requests
print("2.试着根据音乐MP3地址url解析成功的结果下载一首音乐,存放在本程序目录下")
#注意这里的url会随时间过期变化,你要通过前面的教程自己手动获取!
with open("下载的一首歌曲.mp3","wb") as file:
url="https://other-web-ra01-sycdn.kuwo.cn/1647fce2c2c049bf4ef8462545763e61/61ba7d80/resource/n2/128/98/58/4249925507.mp3"
music = requests.get(url)#获取解析到的数据
file.write(music.content)#把数据写入缓冲区文件
file.flush()#把数据存入缓冲区
file.close()#关闭文件
#3.输入一首歌曲的地址(不是MP3地址),解析得到音乐,完整项目
import time
import requests
print("3.输入一首歌曲的地址(不是MP3地址),解析得到音乐")
def get_mp3_name():
data_time=time.strftime('%Y-%m-%d-%H-%M-%S', time.localtime())#格式化获取的当地时间
mp3_name=data_time+".mp3"
return mp3_name
def downMusic(url):
# 该网站有反爬机制,要模拟浏览器来进行伪装。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
'Referer': 'http://www.kuwo.cn/search/list?key=%E5%91%A8%E6%9D%B0%E4%BC%A6',
'csrf': 'RUJ53PGJ4ZD',
'Cookie': 'Hm_lvt_cdb524f42f0ce19b169a8071123a4797=1577029678,1577034191,1577034210,1577076651; Hm_lpvt_cdb524f42f0ce19b169a8071123a4797=1577080777; kw_token=RUJ53PGJ4ZD'
}
mid=url.split("/")[-1]#假设url是http://www.kuwo.cn/play_detail/196835141,得到mid196835141
#把得到的mid参数填入指定位置得到了存放MP3文件地址的json地址
save_mp3_url="http://www.kuwo.cn/api/v1/www/music/playUrl?mid=%s&type=mp3&httpsStatus=1&reqId=66231ca1-5e04-11ec-96d1-d1bbc17ab269" % mid
mp3_response=requests.get(save_mp3_url,headers=headers)#解析存放MP3文件地址的json地址
mp3_url =mp3_response.json().get("data").get("url")#根据解析存放MP3文件地址的json地址的内容,获取MP3地址
with open(get_mp3_name(), "wb") as file:
music = requests.get(mp3_url,headers=headers) # 获取解析到的数据
file.write(music.content) # 把数据写入缓冲区文件
file.flush() # 把数据存入缓冲区
file.close() # 关闭文件
url = input("输入一首歌曲的播放地址下载歌曲:")
downMusic(url)
总结
大家喜欢的话,给个👍,点个关注!继续跟大家分享敲代码过程中遇到的问题!
版权声明:
发现你走远了@mzh原创作品,转载必须标注原文链接
Copyright 2021 mzh
Crated:2021-12-16
欢迎关注 『Python』 系列,持续更新中
欢迎关注 『Python』 系列,持续更新中
【Python安装第三方库一行命令永久提高速度】
【使用PyInstaller打包Python文件】
【更多内容敬请期待】
|