大数据Hadoop学习(4) |
您所在的位置:网站首页 › mapreduce入门案例 › 大数据Hadoop学习(4) |
大数据Hadoop学习(4)
|
大数据Hadoop学习(4)-MapReduce经典案例-单词统计 MapReduce单词统计案例(分别使用样例带的jar包和自己编写代码实现的jar包运行) 1. Hadoop经典案例——单词统计1) 打开HDFS的UI界面,选择Utilities-Browse the file system可查看文件系统里的文件。使用-cat也可。
2) 准备文本文件,执行vi word.txt指令新建word.txt文本文件: hello kdl hello world hello hadoop3) 在HDFS上创建目录,上传文件 hadoop fs -mkdir -p /wordcount/input hadoop fs -put /export/data/word.txt /wordcount/input
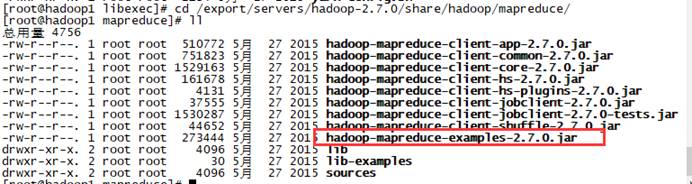
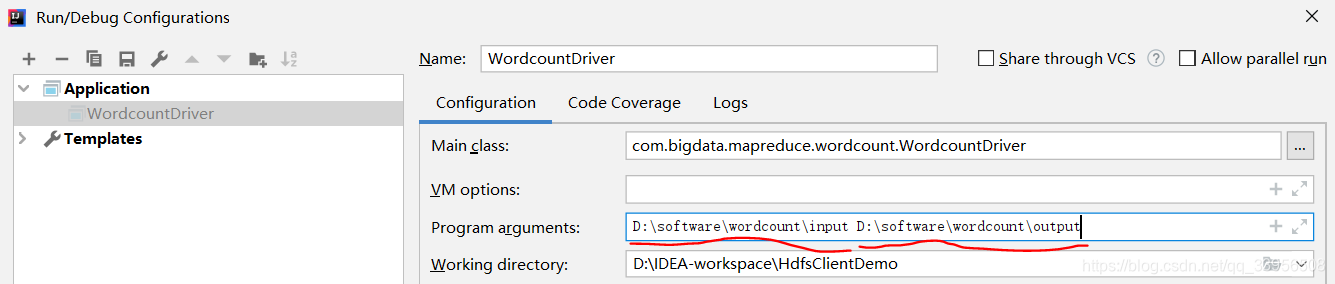
运行hadoop-mapreduce-examples-2.7.0.jar包,实现词频统计。 hadoop jar hadoop-mapreduce-examples-2.7.0.jar wordcount /wordcount/input /wordcount/output4) 查看UI界面,Yarn集群UI界面出现程序运行成功的信息。HDFS集群UI界面出现了结果文件。 或使用-cat hadoop fs -cat /wordcount/output/part-r-00000 2.WordCount案例实操 1.需求在给定的文本文件中统计输出每一个单词出现的总次数 2.数据准备需要统计单词的文本 3.分析 按照mapreduce编程规范,分别编写Mapper,Reducer,Driver,如图4-2所示。 图4-2 需求分析 4.导入相应的依赖坐标+日志添加 junit junit RELEASE org.apache.logging.log4j log4j-core 2.8.2 org.apache.hadoop hadoop-common 2.7.2 org.apache.hadoop hadoop-client 2.7.2 org.apache.hadoop hadoop-hdfs 2.7.2在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,在文件中填入 log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n 5.编写程序 (1)编写mapper类 package com.bigdata.mapreduce.wordcount; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class WordcountMapper extends Mapper{ Text k = new Text(); IntWritable v = new IntWritable(1); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 获取一行 String line = value.toString(); // 2 切割 String[] words = line.split(" "); // 3 输出 for (String word : words) { k.set(word); context.write(k, v); } } } (2)编写reducer类 package com.bigdata.mapreduce.wordcount; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WordcountReducer extends Reducer{ int sum; IntWritable v = new IntWritable(); @Override protected void reduce(Text key, Iterable value, Context context) throws IOException, InterruptedException { // 1 累加求和 sum = 0; for (IntWritable count : value) { sum += count.get(); } // 2 输出 v.set(sum); context.write(key,v); } } (3)编写驱动类 package com.bigdata.mapreduce.wordcount; import java.io.File; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordcountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { // 1 获取配置信息以及封装任务 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); // 2 设置jar加载路径 job.setJarByClass(WordcountDriver.class); // 3 设置map和reduce类 job.setMapperClass(WordcountMapper.class); job.setReducerClass(WordcountReducer.class); // 4 设置map输出 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); // 5 设置Reduce输出 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 6 设置输入和输出路径 /*测试 FileInputFormat.setInputPaths(job, new Path("D:\\software\\wordcount\\input")); FileOutputFormat.setOutputPath(job, new Path("D:\\software\\wordcount\\output"));*/ FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 7 提交 boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } } 6.本地测试(1)在windows环境上配置HADOOP_HOME环境变量(见前一文章) (2)在eclipse/idea上运行程序。 创建输入目录,数据文本放在输入目录下。注意 output目录不要手动创建! 传入参数 可以使用提供的设置程序参数的功能
或直接在程序中修改(记得导出jar包前改回来 //测试 FileInputFormat.setInputPaths(job, new Path("D:\\software\\wordcount\\input")); FileOutputFormat.setOutputPath(job, new Path("D:\\software\\wordcount\\output")); //FileInputFormat.setInputPaths(job, new Path(args[0])); //FileOutputFormat.setOutputPath(job, new Path(args[1])); 7.集群上测试(1)将程序打成jar包(package),然后拷贝到hadoop集群中
(2)启动hadoop集群 (3)执行wordcount程序 hadoop jar HdfsClientDemo-1.0-SNAPSHOT.jar com.bigdata.mapreduce.wordcount /wordcount/input /wordcount/output1片转存中…(img-Ru4PgBd1-1588495850120)]-MapReduce经典案例-单词统计.assets/导出jar包.png) (2)启动hadoop集群 (3)执行wordcount程序 hadoop jar HdfsClientDemo-1.0-SNAPSHOT.jar com.bigdata.mapreduce.wordcount /wordcount/input /wordcount/output1 |





【本文地址】
今日新闻 |
推荐新闻 |