Graph Hawkes Transformer(基于Transformer的时间知识图谱预测) |
您所在的位置:网站首页 › lstm输出怎么确定 › Graph Hawkes Transformer(基于Transformer的时间知识图谱预测) |
Graph Hawkes Transformer(基于Transformer的时间知识图谱预测)
|
本文是我22年在老师学长指导下参与完成的第一篇论文,有幸中稿EMNLP2022,最近比较闲就分享一下。 Graph Hawkes Transformer for Extrapolated Reasoning on Temporal Knowledge Graphs摘 要近年来,由于在危机预警、行为预测等领域巨大的潜在价值,时间知识图谱预测引起了越来越多的研究者的关注。现有的知识图谱预测模型集中采用将图快照编码到潜在向量空间中,然后进行启发式推演的方法,在实体预测任务上有了很好的效果。但是这样的模型无法完成时间预测任务,并且存在结构化信息中有大量与查询无关的事实、长期推演过程中容易造成信息遗忘等问题,极大地限制了模型预测的性能。 针对以上限制,我们提出了一种基于 Transformer 的时间点过程模型,用于时间知识图谱实体预测和时间预测任务。具体来说,上述两个问题分别由 Transformer的两种变形,即关系图Transformer和时序Transformer来解决。关系图Transformer能够基于注意力机制从历史快照序列中聚合实体与关系的结构化信息,生成基于历史信息的隐含向量。时序Transformer能够捕获序列中的时间推演信息,并集成到隐含向量中。最后,利用隐含向量以及实体、关系的嵌入构建条件强度函数,从而完成实体和时间预测任务。此外,还在连续时间域上设计了一个新的关系时间编码函数,使模型更加适合时间知识图谱中的特征推演,能够更好地捕获有价值的时序信息。 在三个流行的ICEWS数据集上进行了实验,模型在实体预测和时间预测任务上都表现出卓越的性能,在多项指标下超过了该领域目前最先进的模型。特别是在长期演化场景下明显超过了其他模型。通过消融实验以及参数敏感性分析,对模型进行了全面的评估,进一步展现出其优秀且全面的性能。 关键词:时间知识图谱;Transformer;时间点过程;未来链接预测;时间预测 1 绪 论本章首先说明时间知识图谱的研究背景以及目前面临的挑战并初步介绍了模型相关的知识背景。随后介绍近些年来知识图谱预测,特别是时间知识图谱预测领域的相关研究,并分析其优缺点。最后明确本文的主要研究内容和研究的意义,对下文的展开给出具体的安排。 1.1 课题背景1.1.1 研究背景 随着异构事件数据的增长,如何对动态演化的多关系图数据进行建模引发了研究者的兴趣。近些年来,针对知识图谱推理的研究也越来越多,研究人员采用嵌入向量,神经网络,强化学习,元学习等多种方法,在静态与动态的链接预测任务上作出了一定突破。然而,要想根据异构事件数据预测未来事件,需要模型随着时间推进进行全局的结构推断,并且要具有集成时间和结构信息的能力。现有的模型还有着不小的缺陷,如何构建更加优秀的模型来完成预测任务,是一个值得研究的课题。  图1-1 问题描述 图1-1 问题描述1.1.2 知识图谱与时间知识图谱 知识图谱[1]是一个多关系的有向图数据库,存储着不同种类的人类知识或事件,目前已经被推荐系统,网页搜素,问答等下游应用广泛使用。传统的知识图谱以三元组(主实体,关系,对象实体)的形式存储每一个事实。但是,在一个知识图中,许多事件是随着时间的推移逐渐改变的,其中可能包含一些基于事件的交互数据,需要时间信息作为补充。因此为了更好地研究这样的数据,需要引入时间知识图谱(Temporal Knowledge Graph,TKG)的概念。时间知识图谱在三元组的基础上加入了时间戳,构成了四元组(主实体,关系,对象实体,时间戳),每个四元组都对应着一个时间事件。通常将一个时间知识图谱表示为一组带有时间戳的静态知识图的快照,如图1-1所示。 TKG 的推理有两种类型,即内推推理和外推推理。 内推推理旨在补全已知历史快照上缺失的事实,而外推推理试图预测未来的事件或事实。相较而言外推推理更加复杂但也更有意义,可用于危机预警、用户行为预测和供应链管理等任务。现有的工作如xERTE[2]或TITer[3]通过对下一个时间戳的快照进行链接预测来验证其模型性能。然而,在实际场景中,通常需要预测未来相当长一段时间内可能发生的事件,因此需要模型具有长期演化的能力。此外,时间预测也同样是一项关键任务,能够预测重要事件的发生时间,无疑会在多个领域起到举足轻重的作用。基于已有的数据集,本文需要通过构建TKG模型解决以下两个预测任务: (1)实体预测:给定对象实体查询或主实体查询,可以是任何一个大于已知时间的时间戳。该模型需要预测丢失的对象实体或主实体,例如:谁可能是明年的图灵奖得主? (2)时间预测:给定查询,该任务要求指定该事件下一次可能发生的时间。例如:小明下一次购买洗手液会是什么时候? 1.1.3 时间点过程 霍克斯过程[4]是一个自激励的时间点过程,用于模拟连续时间内发生的连续离散事件。时间点过程是用于连续时间序列的概率生成模型,在多个领域得到了广泛的应用,例如用户回归时间预测[5]。研究人员将神经网络中涉及到的深度学习方法,特别是循环神经网络,应用于时间点过程,以建立更灵活、更高效的模型,也就是神经时间点过程模型[6]。RMTPP[7]将序列数据嵌入RNN中,考虑历史非线性依赖性因素,对条件强度函数进行建模。Mei和Eisner[8]提出了一种状态随时间衰减的连续时间长短期记忆网络(Long Short-Term Memory,LSTM),并提出了一种基于LSTM的神经霍克斯过程来建模异步事件序列。随后,注意力机制也被有效地应用于神经时间点过程[9]。进一步地,Zo等人提出了Transformer Hawkes过程[10],利用Transformer捕捉复杂的短期和长期时间依赖关系。然而,这些工作并没有对复杂的关系结构信息进行建模,在大规模多关系图上的表现一般。 1.1.4 图Transformer Transformer[11]因为具有强大的建模能力,在多个领域被广泛地应用[12]。然而目前少有相关工作使用 Transformer 或其变体来解决 TKG 推理预测问题。 近年来,一些研究人员研究了将 Transformer 应用于图表示任务的模型。Transformer的注意力模块或位置编码功能经过重新设计,更适合对图结构信息进行建模。例如,GT[13]通过 Transformer 中的注意力机制聚合邻域信息,并使用拉普拉斯特征向量作为位置编码。Graphormer[14]使用具有全局感受野的注意力机制,并引入了三种空间编码方法,以弥补 Transformer 对图结构感知能力的不足。 GTN[15]和 HGT[16]专注于在不同类型的图上设计注意力机制。 到目前为止,很少有专为时间多关系图演化表示学习而设计的 Graph Transformer 模型。 1.1.5 研究遇到的挑战 (1)现有的时间预测模型对出现的事件预测效果较好,而对未知事件的效果一般,特别是在长时间窗口下做出预测的能力很弱。因此本次研究期望能够在长的时间窗口上做出突破。 (2)在时间知识图谱中,复杂结构化数据中的许多事实与查询无关。之前的SOTA模型中广泛采用的关系图卷积网络(Relational-GCN,R-GCN)无法处理这样复杂的数据,因此需要设计一个更好的信息聚合模块,能够容纳更多有用的信息。 (3)现有的模型需要通过多步推理来预测多个时间戳上的未来事件。这意味着更高的时消耗和模型复杂度。也会在训练过程中累积错误。 (4)传统模型主要能解决实体预测任务,在时间预测任务上建树很少。如何利用好时间信息,做出时间预测也是一个挑战。 (5)基于RNN的模型认为图序列是等距的,与现实不符 1.2 国内外研究现状1.2.1 基于嵌入的模型 基于嵌入的方法是是解决知识图谱补全的一个常见方法,它将知识图内的实体和关系以一定的方式映射到连续向量空间,从而在方便计算的同时保留知识图谱的结构信息。基于嵌入的方法大致可分为基于距离的模型,语义匹配模型以及神经网络模型。 距离度量模型的一个代表是TransE[17],它使头实体和关系的向量和表示与尾实体向量接近。由于尾实体是头实体经过关系平移获得的,所以TransE不适合多对一和多对多的情况,在复杂关系上的表现很差。 语义匹配模型有RESCAL、DistMult[18]、ComplEx[19]等,它们使用基于相似度的评分函数,通过匹配实体的潜在语义和向量空间表示中包含的关系来度量事实的可信性。RESCAL用向量表示实体,用矩阵表示关系,并通过自定义的打分函数捕捉三元组的内部交互,其主要思想为三维张量分解,但其参数较多,有一定的复杂性。DistMult通过将RESCAL的关系矩阵限制为对角矩阵进行模型的简化。但是这种过度简化的模型只能处理对称的关系,对于一般的知识图谱数据集显然是不能完全适用的。HolE 结合了RESCAL的表示能力与DistMult的简洁高效,将实体和关系都表示为空间中的向量,并且还定义了头尾实体的循环关联操作实现交互,操作的结果与关系的表示进行匹配以计算备选三元组的得分。ComplEx在DistMult的基础上引入了复值嵌入,实体和关系的向量嵌入不再位于实值空间,而是在复空间内。此外ComplEx的三元组打分函数并非对称形式,对于非对称关系类型的三元组可根据头尾实体的位置关系取得不同的得分,从而可以更好地建模非对称关系。 1.2.2 基于卷积的模型 图是一个常见的数据结构。现实生活中的许多事件或者任务都可以通过图结构来表达,如交通网络、物品推荐等。图卷积神经网络(Graph Convolutional Networks,GCN)是针对对图数据进行操作的一个卷积神经网络架构,可以很好地利用图的结构信息。一个随机初始化的两层GCN就可以有效地生成图网络中节点的特征表示。基于GCN,研究人员进一步提出了R-GCN[20]和CompGCN[21]等模型来解决多关系图问题。R-GCN模型能够应用于链路预测和实体分类两项任务。针对链路预测,R-GCN在关系图中的多个推理过程中采用编码器模型来积累信息,可以显著地优化链路预测模型;对于实体分类任务,R-GCN对每个节点使用一个softmax分类器,通过卷积网络来提取每个节点的表示,用于对节点类别做出预测。但是随着关系数的增多,模型会引入过多关系矩阵Wr,导致参数爆炸,模型难以训练。CompGCN是针对多关系图提出的异质图表征算法,它将边的信息考虑到整个关系的计算中,联合的学习图中节点和边的向量表示。它能够同时对节点和关系进行表征学习,增加了边的种类,引入了反向关系以及自循环关系,并且不会引入过多参数。 1.2.3 时间知识图谱模型 针对时间知识图谱任务,有TTransE[22]、TA-DistMult[23]、DE-SimplE[24]、 TNTComplEx[25]、RE-NET[26]、RE-GCN[27]、CyGNet[28]、xERTE等模型。这些方法的主要思想是显式地去学习时间戳的嵌入表示或将时间信息集成到实体或关系嵌入中。然而,向量嵌入的黑盒特性使得对于人类来说,其信息难以用于理解预测。 此外,那些采用浅嵌入的方法不适合数据中含有训练集没有见过的实体、关系或时间戳情况下的归纳推理。在上述提到的方法中,RE-NET、RE-GCN、CyGNet、xERTE 被设计用于推理预测任务。 RE-NET对于多关系图的时间序列建模,对未来的时间戳执行顺序的全局结构推断,预测新事件。其中的编码器能够对事件序列的时间条件联合概率分布进行建模并且为事件编码配备邻域聚合器,以对每个实体相关的时间窗口内的并发事件进行建模。该模型将强制学习应用在对历史数据的模型训练中,并通过按顺序从学习的联合分布中采样推断未来时间戳的图形序列。实验证明在未来时间戳的多步推断上,RE-NET有很大的优势。 CyGNet采用一个新颖的时间感知的副本生成机制,它不仅可以根据全部的实体词库预测事件,还能够识别重复的事实并且相应地预测与过去已知事件相关的未来事件,这与自然语言处理中抽象复制的机制类似。然而,这些方法仅使用随机向量来表示之前未见过的实体,并将链接预测任务视为多类分类任务,导致其无法很好地解决针对未见过实体的预测。此外,它们不能明确指出历史事实对预测事实的影响。 解释模型 xERTE使用子图采样技术来构建推理图。尽管它参考 GraphSAGE中提到的表示方法,具备处理未见实体的可能,但所构建推理图的不断扩展严重限制了推理的速度。 RE-GCN使用 R-GCN捕获结构信息,然后使用 RNN 执行表征推演,相比前面的模型性能取得了更大的突破,但仍然未解决上述固有的缺陷。 1.2.4 基于时间点过程的模型 基于嵌入的方法如TransE、ComlEx在静态知识图谱上取得了出色的效果,这些方法已扩展到时间知识图谱上。但是,这些方法无法都处理外推推理任务。因为在外推中,测试数据集包含的时间戳在训练数据集中不存在,现有的模型很难学到足够的信息来处理这样复杂的情况。因此外推模型如Know-Evolve[29]和GHNN[30]使用时间点过程来估计条件概率,从而进一步去从备选实体中选出答案。 Know-Evolve使用 Rayleigh 过程学习不断发展的实体表示,能够捕捉时间知识图谱的动态特征。该模型提出了一个多元点过程框架来模拟连续时间中事实(边)的出现。为了促进时间推理,学习的嵌入向量会被用做计算关系分数,从而进一步参数化为时间点过程的强度函数。但是之后的研究发现Know-Evolve论文中的公式存在错误,导致该模型的参考价值变低。 GHNN提出了一种用于时间知识图谱预测的图霍克斯神经网络,从而预测大规模时间知识图谱上的未来事件。这是第一个使用霍克斯过程来捕捉和解释时间知识图谱中潜在时间动态信息的工作。与之前只具有具有离散状态空间的TKG模型不同,GHNN对事件在连续时间内的发生概率进行建模。通过这种方式它可以计算任意时间戳下事件发生概率,大大提高了模型的灵活性。但是以上两种模型都无法对历史图结构信息进行建模,导致它们的性能受限严重。 1.2.5 基于强化学习的路径预测模型 TITer是第一个基于强化学习方法进行时间知识图谱预测的模型,通过智能体在历史知识图谱的快照上游走来寻找答案。TITer定义了一个相对时间编码函数来捕获时间跨度信息,并设计了一种基于狄利克雷分布的新型奖励来指导模型学习。TITer开创性地设计了一种搜索机制,在测试过程中更新未见过实体的表示,以提高模型的归纳推理能力。模型可以用于未来时间戳的链接预测任务。相比其他模型具有更高的可解释性、更少的计算和更少的参数。但是这种方法将答案的值域限制在阶邻居内,预测时受数据集的制约很大。如果数据集中答案实体大多分布在阶邻居外,模型性能会骤降,并且TITer不能捕获进化的表示,也使得其性能受到了限制。 2 相关技术基础在设计并实现模型之前,首先需要明确一下模型相关的一些重要技术。本章主要介绍时间知识图谱预测模型的技术基础,包括知识图谱预测的概述与基本结构,Transformer在时间知识图谱预测任务上的应用和神经时间点过程方法的概念与使用。这些技术会在设计的连续时间域上的知识图谱预测模型中被应用或者得到进一步的优化改进。 2.1 时间知识图谱预测2.1.1 基本结构 正如前文1.1.2 知识图谱与时间知识图谱中所说,时间知识图谱中的信息是由四元组(主实体,关系,对象实体,时间戳)的形式存储的,通常实体名和关系名都会被数字代替。这些四元组会被划分成训练集、验证集以及测试集,分割好的数据会被进一步的预处理。为了对任务做简化,需要加入反边将对象实体预测问题也转化为主实体预测问题,无需更改模型。随后可以通过取N阶邻居,基于置信度选取等方法去构建一系列子图,每一张子图都对应一个时间戳下的实体和关系组成的知识网络。这里的N阶邻居图是指与查询实体相关的节点、其N阶邻居节点以及所有相关的边组成的。边置信度筛选是指要计算每条边的联合分布概率,可以用与头实体有关的边出现次数除以这条边出现总次数来计算,最终生成子图。这些取样和筛选可以辅助剔除冗余信息,根据这些子图可以生成历史快照,用于模型训练。 训练过程中,模型首先需要从生成的图中汇聚实体和关系的信息,特别是结构信息。因此首先要利用实体和关系生成嵌入向量,然后对时间信息进行编码,集成到嵌入向量中。随后模型通过特定的结构聚合历史快照的结构信息和时间信息,生成特殊的隐含向量。该隐含向量包含的信息量会直接影响到模型是否能针对复杂的数据集中的查询做出合理的预测。对于实体预测任务,如果模型采用编码器——解码器结构的话,就需要设计合适的解码器将隐含变量解码输出,通过计算距离或权重得到答案实体。而对于时间预测任务,按照时间点过程的方法,则需要先计算出强度函数,利用强度函数计算条件概率。通过积分的方式在连续时间域上计算出预测的时间。 整个时间知识图谱预测的流程可以用下图2-1来表示。  图2-1时间知识图谱预测流程 图2-1时间知识图谱预测流程2.1.2 符号定义 为了更好地说明任务需求,理清文章脉络,需要在这里对文章使用的符号进行定义与说明,其中必要的符号如表 2-1-1 所示。 让 \mathcal{E},\mathcal{R} 分别表示实体和关系的集合。 \mathcal{F}_t 表示t时刻的事实集合。随后,一个时间知识图就可以表示为一组静态知识图谱快照的序列。例如,一个已知的从1时刻到t时刻的时间知识图可以被表示为 \mathcal{G}_{\left(1,\mathcal{t}\right)}=\mathcal{G}_1,\mathcal{G}_2,\ldots,\mathcal{G}_\mathcal{t}\} ,其中是时刻的KG快照,一个多关系有向图。中的每一个事实都会以一个四元组 \left(e_s,r,e_o,t\right) ,其中 e_s,e_o\in\mathcal{E} ,并且 r\in\mathcal{R} 。四元组就可以被视为图 \mathcal{G}_\mathcal{t} 中一条类型为 r 的从 e_s 到 e_o 的边。 接下来,针对要解决的任务说明相关符号。基于历史时间知识图 \mathcal{G}_{\left(1,\mathcal{t}\right)} ,模型需要在时间 t_q 预测事实,其中 t_q\ \in(t+\mathrm{\Delta t}] , \mathrm{\Delta t} 是预测时间窗口大小。先前大多数工作考虑的都是 \mathrm{\Delta t}=1 对应的任务,即在下一个时间戳进行实体预测。而时间预测任务是在 ( , +\ \mathrm{\Delta t}] 时间段内即将发生的事件的具体发生时刻。 对于一个特定的事实,这两个任务定义如下。 任务1 实体预测 给定一个查询 \left(e_{qs},r_q,?,t_q\right) 或 \left(?,r_q,e_{qo},t_q\right) ,其中 2.2 Transformer的应用 2.2.1 注意力机制 注意力机制[31]又被称为神经注意力。它通过注意力汇聚将自主性的提示(查询)和非自主性的提示(键)进行了结合,从而实现了对感官输入(值)的有偏向的选择。以为查询,作为键值对,进行注意力汇聚,其汇聚力函数可以是平均池化,也可以是岭回归,具体公式如下式2-1。 f\left(x\right)=\sum_{i=1}^{n}\frac{K\left(x-x_i\right)}{\sum_{j=1}^{n}K\left(x-x_j\right)}y_i (2-1) 这里的可以看做核函数,常用的是高斯核函数。进一步可以得到一个更一般的公式2-2。 f\left(x\right)=\sum_{i=1}^{n}{\alpha\left(x,x_i\right)y_i}=\sum_{i=1}^{n}{\mathrm{softmax}\left(-\frac{1}{2}\left(\left(x-x_i\right)w\right)^2\right)y_i} (2-2) 此处的是注意力权重,它本质上是键与相对应的值的一个概率分布。softmax内部的内容,也就是高斯核的指数部分,可以被称为注意力分数,整个注意力框架可以由下图2-2来表示。  图2-2注意力机制框架 图2-2注意力机制框架常见的评分函数主要有两种,分别是加性注意力和缩放点积注意力。给定查询以及键,那么加性注意力所对应的得分函数是 a\left(q,k\right)=w_v^\top\mathrm{tanh}\left(W_qq+W_kk\right)\in R (2-3) 将键和查询相拼接,一起输入到多层感知机(Multilayer Perceptron,MLP)中,MLP里还含有隐藏层,以超参数来表征隐藏单元的数量。这里的激活函数常使用禁用偏置项的双曲正切函数。 为了提高计算注意力评分的效率,可以使用点积操作。但是点积操作要求查询和键保持相同的长度。如果所有元素都满足期望为0、方差为1,那么点积的均值为0、方差为d。为了使方差仍然保持为1,可以将点积除以。因此缩放点积注意力的评分函数如下式所示。 a\left(q,k\right)=q^\top k/\sqrt d (2-4) 2.2.2 多头注意力自注意力与位置编码 介绍Transformer,需要引入多头注意力、自注意力以及位置编码的概念。 多头注意力是指模型单独地学习n组不同的线性投影来对查询、值和键进行变换。然后将他们并行地送入注意力池化中,将n个经过注意力汇聚所得的输出拼接起来,再次通过一个全连接层去学习线性投影进行变换,从而输出最后的结果。 所谓自注意力,指的是输入的词元序列同时作为查询、值和键,即每一个查询都会注意每组键-值对,同时生成一个基于注意力的输出。具体来说,给定一个输入序列, 其中,自注意力会输出长度相同的序列,如式2-5所示。 y_i=f\left(x_i,\left(x_1,x_1\right),\ldots,\left(x_n,x_n\right)\right)\in R^d (2-5) 引入自注意力后,就可以采取类似循环神经网络的方法去处理序列数据,其过程如下图2-3所示。  图2-3自注意力图解 图2-3自注意力图解自注意力没有记录位置信息,这一点与卷积神经网络或者循环神经网络均不同,因此需要通过位置编码来将相对或者绝对的位置信息加入到输入中。位置编码可以通过学习获得,也开可以在训练前人为的去固定。最典型的固定位置编码就是基于正弦函数和余弦函数的编码。这样的位置编码也允许引入相对位置信息,基于确定的位置偏移,将位置编码进行线性投影来得到相对位置编码。这两种编码是目前Transformer相关研究中最为常见的位置编码。 2.2.3 Transformer Transformer基于编码器-解码器的架构去处理序列对,与使用注意力的其他模型不同,Transformer是纯基于自注意力的,没有循环神经网络结构。输入序列和目标序列的嵌入向量加上位置编码。分别输入到编码器和解码器中。编码器和解码器都有个Transformer块,每个块里会使用多头(自)注意力,基于位置的前馈网络和层归一化。 Transformer中也采用了多头注意力,希望多头能够抽取不同的信息,如长距离信息和短距离信息。其中针对查询,键和值都有可学习的参数,最终输出对应的参数为。为了保证解码器输出的序列中,针对每个元素的输出又不需要考虑到该元素之后的元素,需要在多头注意力中加入掩码来对输入加以信息规范。 在编码器的自注意力中,查询和键都来自相同的输入序列。因为作为填充的词元是不含有信息的,通过说明输入序列的生效长度可以避免查询在使用填充词元的位置执行注意力的计算。模型中的逐位前馈网络其实就是一个全连接层,它对序列内每个位置的表示进行变换时使用的是同一个MLP。通过前馈网络后,就要进行残差连接和层归一化[32]。残差连接是一种加法计算。在计算过程中,对于任何位置的一个序列输入,都要满足和在同一个实数空间内。紧接着应用层归一化。层归一化是对每个样本里的元素进行归一化,按维度去切,因此在序列对应的各个位置编码器都将输出维表示向量。 Transformer的解码器也是由n个完全相同的层组成的,层中同样用到了残差连接和层归一化。除了Transformer编码器中的两个子层之外,解码器还插入了编码器-解码器注意力层。在编码器-解码器注意力中,查询来自上一个解码器层的输出,而键和值来自整个编码器的输出。在解码器自注意力中,查询、键和值都来自上一个解码器层的输出。但是,解码器中的每个位置只能考虑该位置之前的所有位置。这种掩蔽注意力保留了自回归属性,保证预测仅仅依赖于已生成的输出词元。 整个Transformer的结构可以通过图2-4来详细的描述:  图片源自动手学深度学习v2 https://zh-v2.d2l.ai/chapter_attention-mechanisms/transformer.html 图片源自动手学深度学习v2 https://zh-v2.d2l.ai/chapter_attention-mechanisms/transformer.html图2-4 Transformer结构 2.2.4 图Transformer 自从Transformer问世后,其应用领域不断扩大,在很多课题的研究中都发挥了很好的效果,也随之引起了图神经网络领域的关注。一些研究人员通过研究发现Transformer 的注意力模块或位置编码功能经过重新设计,更适合对图结构信息进行建模。 针对NLP任务设计的Transformer是在一个表征序列中词元相互连接的全连接图上运行。这种架构没有利用图连通性归纳偏差,并且在没有将拓扑图信息编码到节点特征中时表现不佳。GT引入了具有四个新属性的图Transformer,通过Transformer 中的注意力机制聚合邻域信息,使用拉普拉斯特征向量作为位置编码。原有的层归一化被批量归一化层取代,新的归一化层提供了更快的训练速度和更好的泛化性能。该架构可以被扩展到边特征表示,这对于链接预测任务来说可能是至关重要的。在baseline上的相关实验证明了GT的图Transformer架构的良好性能。该项工作缩小了针对有限的线性图设计的Transformer与可以处理任意图的图神经网络之间的差距,为后续的工作做出了开创性示范。 Graphormer使用度中心度作为神经网络的附加信号。它开发了一个中心性编码,根据每个节点的入度和出度给该节点分配两个实值嵌入向量。如式2-6所示。 h_i^{\left(0\right)}=x_i+z_{deg^-\left(v_i\right)}^-+z_{deg^+\left(v_i\right)}^+\ \ (2-6) Transformer 的一个优势是它的全局感受野。在每个 Transformer 层中,每个token都可以关注任何位置的信息,然后处理其表示。在中心性编码后,需要进行空间编码。传统的Transformer处理的是序列数据。但是图中的节点不是序列,因此需要针对注意力重新进行空间编码。为了丰富结构化特征,还可以将边信息加入到注意力编码中,并加入合适的偏差,得到最终的注意力编码表达。 A_{ij}=\frac{\left(h_iW_Q\right)\left(h_iW_K\right)^T}{\sqrt{d}}+b_{\phi\left(v_i,v_j\right)}+c_{ij}\ \ (2-7) 以上的编码方法一定程度上弥补了Transformer对图结构感知能力不足的局限。 2.3 神经时间点过程方法霍克斯过程假设过去的事件可以暂时地激发未来的事件,以强度函数为特征。强度函数最初表示时间戳( , + ]中期望发生的事件数,可定义为: \lambda_k^\ast\left(t\right)=\lim _{\Delta t\rightarrow0}{\frac{P\left(event\ of\ type\ k\ in\left[t,t+\Delta t\right)\middle|\mathcal{H}_\mathcal{t}\right)}{\Delta t}} (2-8) 这里的*可以看做历史条件的简写。 在霍克斯过程的基础上,进一步衍生出时间点过程,并且被应用到地质研究,数学统计,金融等诸多领域。这是因为地震学中的地震事件、神经科学中的神经脉冲序列、金融市场中的交易和订单以及网络上的用户活动日志,都可以表示为连续时间观察到的离散(瞬时)事件序列。现在机器学习界也开始广泛使用这个工具来解决实际问题,例如基于点过程的用户回归时间预测通过以不同的方式去构建强度函数,就可以将时间点过程应用到经典的机器学习模型上,辅助模型更好地捕捉时间信息。 传统的时间点过程只能捕捉事件发生的简单模式,在机器学习的任务上效果有限。相比之下,神经时间点过程引入神经网络来参数化强度函数,在复杂的现实生活场景中表现出很高的模型容量。神经时间点过程可以定义为一个自回归模型,通过顺序预测下一个事件\left(t_i,m_i\right)的时间和标记来运行。通常,可以将此过程分解为3个步骤: (1)将每一个事件 \left(t_i,m_i\right) 作为未来向量。 (2)将未来向量序列\left(\mathbf{y}_1,\ldots,\mathbf{y}_{i-1}\right)\mathcal{H}_{\mathcal{t}_\mathcal{i}}表示为\mathcal{H}_{\mathcal{t}_\mathcal{i}} ,作为历史生成一个固定维度的嵌入向量\mathbf{h}_i。 (3)使用历史嵌入向量 \mathbf{h}_i 去参数化下一个事件的条件分布 P_i\left(t_i,m_i\middle|\mathcal{H}_{\mathcal{t}_\mathcal{i}}\right) 。 后面的章节就会继续按照这个步骤去构建模型,如图2-5所示,过往的许多实验已经证明,神经时间点过程可以捕获到更多有用的信息。  图2-5 神经时间点过程建模3 Graph Hawkes Transformer模型设计与实现 图2-5 神经时间点过程建模3 Graph Hawkes Transformer模型设计与实现第二章论述了建立时间知识图谱预测模型所涉及到的一些技术知识与学术背景。本章将在这些背景技术的基础上,进行算法改进与模型优化,设计一个更加优秀的模型,即Graph Hawkes Transformer模型(GHT)。模型的设计与实现将在下文中被具体的阐述。 3.1 模型总体框架TKG预测的流程已在2.1 时间知识图谱预测节给出了说明。其中,新模型中数据集加载与划分,以及过程中使用的过滤机制均按照前文提到的常规方法进行。GHT通过DGL库建立子图生成历史子图序列,并在子图创建过程中对边做了取样,去除了部分置信度过低的边。模型首先要从向量序列中捕获并发的结构依赖信息并输出对应的隐含向量,同时捕获时间推演信息,然后构建条件强度函数来完成预测任务。模型的整体架构如图3-1所示,关系图Transformer(Relation Graph Transformer,RGT)对每个历史快照的图结构进行编码。时序Transformer根据历史状态序列将隐藏状态更新为任意一个未来的时间戳。基于演化状态来计算条件强度和概率密度。 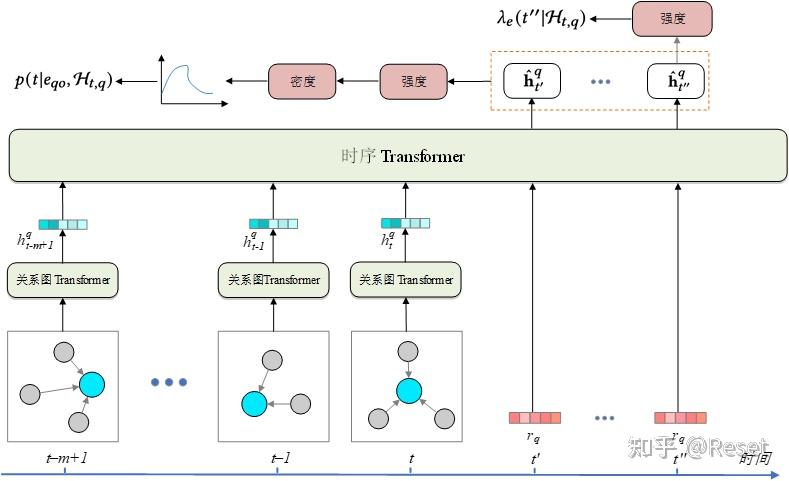 图3-1连续时间Transformer框架结构 图3-1连续时间Transformer框架结构相比以前的推演表示学习方法如RE-NET和RE-GCN,GHT希望能够解决前文提到的限制与挑战。借鉴Transformer和神经时间点过程的思想,设计了两种不同的Transformer来学习条件强度函数。关系图Transformer能够处理挑战1中提及的未见实体问题,并且捕获结构依赖信息。而时序Transformer去解决挑战2、3并捕获时间演化信息。最后使用条件强度函数来预测需要的的实体或时间从而解决挑战4。 在介绍模型前,先对数据预处理做一个简单的说明。所有的数据集都是以四元组的形式记录的。 首先要读取四元组同时获取数据集的基本信息(如实体数、关系数等),加入反边,随后将四元组按照时间戳进行划分,建立snapshot,同时获取实体出现过得时间的倒排索引表,(e, r)出现过的时间索引表,以及关系-时间字典,用于后续的训练。然后利用dgl框架创建子图以及相应的历史图history_graph。 在GHT中我们引入了时间窗口delta_t_windows,预测将在一个时间窗口下进行,基于历史数据预测dt个time_span后发生的事件。创建历史图要首先确立时间戳,针对不同的数据集,会选取存在查询头实体 e_{qs}或者头实体与关系二元组的子图对应的时间戳,同时还要满足timestamp - x > dt *ime_span这一限制。这里还会设置history_length,记忆最近的N个子图。超过history_length的图会舍弃,不足的会用空图补足。 对于每个子图,在创建过程中都会取头实体的N阶邻居子图,按照边(relation)置信度进行取样。对于节点不足的子图也会把每个graph补全到max_nodes_num。 置信度计算方法:(e, r)中关系出现的次数/头节点出现次数 3.2 关系图Transformer的设计与实现3.2.1 RGT设计思路 捕获历史快照的结构信息是回答查询的第一个关键步骤。先前的工作如RENET,RE-GCN使用 R-GCN进行信息聚合,将节点之间的交互信息存储在节点的隐藏向量中。然而,在历史快照中,一个实体上可能同时发生许多事件,但其中只有一小部分信息有助于回答查询,如何尽可能的去提取那小部分有用的信息,是信息聚合的关键。R-GCN 很难处理此问题,因为它认为每条消息都是同等重要的。 因此,本文设计了一个关系图Transformer(RGT)模块,让模型知道哪些并发事件在具有注意力机制的快照中更为关键。这个 Transformer 中使用了两种形式的图表示,分别具有全局感受野和局部感受野。全局形式无法处理节点过多的图。因此,为了最大限度地保留图的结构信息,与以前的局部图Transformer的模型相同,RGT 在局部邻域图上进行操作,它本质上是一个基于注意力的图神经网络。 3.2.2 RGT结构 让 \mathbf{E} \in R^{\left|\mathcal{E}\right| \times d} 和 \mathbf{R}\in R^{\left|\mathcal{R}\right|\times d} 分别代表实体和关系的初始嵌入矩阵,其中 表示嵌入的维度。 e_i=\mathbf{E}\left[i\right] 是实体的嵌入, r_i=\mathbf{R}\left[i\right] 是关系的嵌入。为了降低训练的复杂度,对模型进行简化,在查询实体的 阶邻居子图上执行演化。对于具体的查询实体 e_q 和查询关系 r_q ,可以将 层RGT的功能描述简化为如下输入输出。 输入: 实体嵌入向量矩阵 \mathbf{E} ,关系嵌入向量矩阵 \mathbf{R} ,查询关系 r_q ,以及 e_q 的阶子图序列 \{\mathcal{G}_{t-m+1}^q,...,\mathcal{G}_t^q\} ,其中 m 是预先定义的最大窗口history_length。输出:经过结构信息聚合后的隐藏状态向量序列具体来说,对于 \mathcal{G}_\mathcal{t}^\mathcal{q} ,每个节点会通过DGL的消息传递框架更新其隐藏状态。消息函数可以获得出发节点和边的特征信息,描述了需要发给目标节点做下一步计算的信息。目标节点在获得其他节点以及边的特征信息之后,通过累和函数计算出一个新的表示。 例如,对于一个事件,将头实体和边的隐含向量拼接后先后通过线性层,leaky_relu激活函数以及dropout层,作为的每个入边的消息msg,也是相对应的值矩阵 V \in \mathbb{R}^{|M| \times 2d} 。其中| |是消息的数量。关系向量通过线性层得到的关系矩阵作为每条消息的查询,查询矩阵 Q\in R^{\left|M\right|\times d} ,将头结点和边的隐含向量拼接后通过线性层获得键矩阵 K\in R^{\left|M\right|\times2d}\ 。利用Q,K,V可以计算得到多头注意力att,消息函数的任务就是完成msg和att的计算。在累和函数中,通过softmax层计算出注意力权重,随后通过残差连接和层规范化得到隐含状态向量序列。 这样的RGT层会重复多次完成编码工作,见公式3-1 \mathbf{h}^{l}_{t} = LN(FFN(MHA(Q,K,V)+\mathbf{h}^{l-1}_{t}), (3-1)注意这里并没有在查询矩阵中引入查询实体信息,因为随着 TKG中事件的不断发展,知识图上可能会出现新实体,但是模型还没有学习到它们的初始嵌入。相较而言,关系的语义是稳定,并且与上下文无关,每一层都会共享一个关系嵌入矩阵。整个RGT的模型流程如图3-2 所示,需要注意的是RGT可以被设置重复多层,以加深网络,方便模型学习更多的信息。 3.3 时序Transformer设计与实现3.3.1 TT设计思路模型设计了时间Transformer(Temporal Transformer,TT)来模拟连续时间域中实体表示的时间演化,也可以看做Transformer中的解码器。因为 RGT 的输出已经可以反映实体在每个时间戳的结构化信息,所以 TT想要在解码过程中尽量学习序列的演化信息。先前的工作采用门控循环单元来完成类似的功能。但是,他们的方法仅仅能捕获序列信息,却不能捕获时间信息,具有很大的局限性。此外,他们的方法只能逐步推演,预测效率很低。相反,Transformer结构可以并行计算并通过位置编码捕获位置信息,使用一个基于Transformer的架构来提取信息可能会有很好的效果。定义TT模块的输入和输出如下: 输入: RGT的隐藏状态向量序列以及对应时间戳序列 ;查询关系 r_q ;未来时间戳的集合输出: 在每个未来时间戳的演化隐藏状态 图3-2 关系图Transformer结构3.3.2 TT模块结构 图3-2 关系图Transformer结构3.3.2 TT模块结构下面定义 TT 的整体结构。TT可以看做传统Transformer架构中的解码器,不同的是,TT中减少了一层多头注意力,保留了一个带掩码的多头注意力层和基于位置的前馈网络。不同之处在于,原有的位置编码在这里被改进为正余弦时间编码,输入的K和V均为RGT的输出,Q则为查询关系向量的embedding。 Transformer是通过接下来介绍关系连续时间编码函数及其具体应用方法。尽管研究人员设计了多种位置编码方法[33][34][35],但由于以下两个原因,它们中的大多数都不适用于本模型应用的场景。 (1)这些位置编码方法大多数是在离散域中执行的,可能不适合基于Hawkes过程的建模。 (2)与离散的token不同,TT的输入是经过图信息聚合后的连续向量,训练集和测试集之间的分布偏移[36]会使模型表现出较差的泛化性能。 此外,对于不同的查询事件类型,注意力的时间分布可能不同。例如,一个人腹泻可能是前一天吃了变质的食物引起的,而肥胖更可能是由长期的饮食习惯导致的。因此,我们重新设计了一个关系连续时间编码函数来辅助注意力计算。请注意,在模型训练期间看不到未来的时间戳,因此需要保证函数的归纳能力。基于Transformer 注意力的计算原理,需要保证下面的公式[37]成立。 \langle TE(t_k + c), TE(t_q +c) \rangle = \langle TE(t_k), TE(t_q) \rangle, (3-2) 其中 表示时间编码函数, \left\langle\cdot,\cdot\right\rangle 表示内积, t_k 和 t_q 分别表示注意力计算中键的时间和查询的时间。上述方法表示可以使用绝对时间编码来表示相对时间信息。贯彻这个思路,设计了一个满足上述条件的可学习正弦函数,并使用查询关系 r_q 来控制函数的幅值。详细的函数如下: TE_r\left(t\right)=\left[\alpha_1^rcos\left(w_1t\right),\alpha_1^rsin\left(w_1t\right),\ldots,\alpha_d^rcos\left(w_dt\right),\alpha_d^rsin\left(w_dt\right)\right]\ (3-3) 其中 \left[\alpha_1^r,\ldots,\alpha_d^r\right] 是关系嵌入的线性投影, \left[w_1,\ldots,w_d\right] 是 维的可学习向量。我们使用这个时间信息来计算注意力矩阵的偏置项。 T_q = [TE_{r_q}(t_{q_1}); ...; TE_{r_q}(t_{q_s})] 表示查询层的时间编码矩阵, T_k = [TE_{r_q}(t_{k_1}); ...; TE_{r_q}(t_{k_m})] 表示键时间编码矩阵,进一步就可以计算得到注意力矩阵。 A = \frac{(H_q W_Q)(H_e W_K)^T + (T_q) (T_k)^T}{\sqrt{2d}}, (3-4) 这里的 W_Q , W_K 都是加权矩阵, H_q 是查询关系的嵌入矩阵, H_e 是RGT获得的查询实体的压缩矩阵,最终整个TT的结构框图如下:  图3-3 时序Transformer结构3.4 时间点过程的应用与模型训练3.4.1 构建条件强度 图3-3 时序Transformer结构3.4 时间点过程的应用与模型训练3.4.1 构建条件强度在明确3.3节中描述的时间编码之后,就可以在未来的任意一个时间戳下生成一个隐含向量表示。然后,就可以使用这个隐含向量表示为所有候选实体构建连续时间条件强度函数,见式3-5。 \lambda_{t_q}^{e_i} = f( \langle [\textbf{e}_{s}, \textbf{r}_{q}, {\textbf{h}}_{t_q}] W_{\lambda}, \, \textbf{e}_i \rangle), (3-5) 其中 W_\lambda \in \mathbb{R}^{3d \times d} 是投影矩阵, \textbf{h}_{t_q} 是从TT中获得的 t_q 时刻的隐含状态 f(x) = \beta \cdot log (1 + exp( \frac{x}{\beta})) 是softplus函数,参数 确保模型可以获得一个正的强度,而和分别是查询实体、查询关系和候选实体的嵌入向量。 3.4.2任务实现方案利用构建好的条件函数,就可以同时完成实体预测与时间预测两项任务。因为所有候选实体共享相同的生存期[30],因此实际上可以直接通过比较条件强度值的大小来得到答案实体,如式3-6所示。条件强度最大的备选实体将作为实体预测的答案。 e_{qo}=argmax_{e\in\mathcal{E}}\{\lambda_e\left(t_q\middle|\mathcal{H}_{\mathcal{t},\mathcal{q}}\right)\}\ \ \ \ (3-6) 式3-7是相应的条件时间概率密度函数,据此可以通过积分来对时间做出预测。这里的 t 为时间窗口的起始时刻, t_q 为需要预测的时间。 p\left(t_q\middle| e_{qo},\mathcal{H}_{\mathcal{t},\mathcal{q}}\right)=\lambda_{e_{qo}}\left(t_q\middle|\mathcal{H}_{\mathcal{t},\mathcal{q}}\right)exp\left(-\int_{t}^{t_q}{\tau\lambda_{e_{qo}}\left(\tau\middle|\mathcal{H}_{\mathcal{t},\mathcal{q}}\right)d}\tau\right)\ \ \ (3-7) 时间估计的积分如下式所示。 t_q=\int_{t}^{+\infty}{\tau p\left(\tau\middle| e_{qo},\mathcal{H}_{\mathcal{t},\mathcal{q}}\right)d\tau}\ \ \ \ \ (3-8) 实际实验时,很难用Python去实现积分,因此对于积分运算,使用梯形规则进行近似计算。以式9为例。 t_q = \sum\limits_{j=1}^L \frac{t_j - t_{j-1}}{2} \left(t_j p(t_j|e_{o}, \mathcal{H}_{t}^{q}) +\right. \left. t_{j-1} p(t_{j-1}|e_{o}, \mathcal{H}_{t}^{q})\right) (3-9) 其中 t_j∈[ , +∞) , 是样本数。这里也可以使用其他近似估计积分的方法,例如 Simpson 规则和Monte Carlo积分[38]。 3.4.3设计损失函数GHT模型将实体预测任务视为多分类任务,将时间预测任务视为回归任务。然后,对实体预测任务使用交叉熵作为损失,对时间预测任务使用均方误差 (MSE)作为损失。令 \mathcal{D}_{train} 表示训练集, L_e 是实体预测的损失, L_t 是时间预测的损失。训练过程中的损失定义如下式3-10和3-11。 L_e=-\sum_{i=1}^{\left|\mathcal{D}_{train}\right|}\sum_{c=0}^{\left|\mathcal{E}\right|-1}{y_clog\left(p\left(e_{o_i}=c\middle|\mathcal{H}_{t_i}^q\right)\right)}\ \ \ \ \ \ \ \ \ (3-10) L_t=\sum_{i=1}^{\left|\mathcal{D}_{train}\right|}\left(t_i-\widehat{t_i}\right)^2\ (3-11) 这里 p(e_{o_i}|\mathcal{H}_{t_i}^q) 是候选实体的概率得分, \hat{t}_i 是估计时间。针对上述两个任务进行联合训练,最终损失 L = L_e + \mu L_t ,其中 是一个超参数。为了防止过拟合,在实际应用时采取了标签平滑的方法。 4 实验测试与模型评估本章将在第三章中构造的GHT模型的基础上进行实验测试,并且给出对新模型的合理评估。本章首先会说明实验的环境与基本设置,随后在多个经典数据集对模型性能进行分析,后面还会给出消融实验,以尽可能客观的展现该模型的真实性能,展现所做的模型创新的效果。 4.1 实验环境4.1.1 硬件环境测试过程使用了2台不同的服务器以及自己的台式电脑,主要区别是服务器使用的显卡是NVIDIA GeForce RTX3090和NVIDIA Tesla P100,自己的台式电脑使用的是NVIDIA GeForce RTX3070。 NVIDIA Tesla P100 服务器的硬件配置见表4-1。 表4-1 P100服务器主要硬件配置表 硬件名称硬件参数CPUIntel Core i9 12900KGPUNVIDIA Tesla P100内存64GB硬盘SSD 200GBNVIDIA RTX 3090服务器的硬件配置见表4-2。 表4-2 3090服务器主要硬件配置表 硬件名称硬件参数CPUAMD EPYC 7642 48-Core ProcessorGPUNVIDIA GeForce RTX3090内存80GB硬盘SSD 100GB在服务器上运行了大多数实验,但仍有部分实验是在个人电脑上运行的,个人电脑的硬件配置信息见表4-3。 表4-3个人电脑主要硬件配置表 硬件名称硬件参数CPUAMD Ryzen5 5600X 3.70 GHzGPUNVIDIA GeForce RTX3070内存16GB硬盘SSD 1TB4.1.2 软件环境与实验相关的主要软件有操作系统,Python,CUDA,图机器学习一些必要的库等,软件环境具体的信息见表4-4。 表4-4 软件环境信息 软件名称软件信息Ubuntu 20.04 LTS操作系统,Linux 内核版本:5.8.0-50-genericPythonPython解释器,版本:3.8.10CUDACUDA版本:11.1PytorchPytorch版本:1.10DGL图机器学习DGL库 版本:v0.8.04.2 实验设置整个实验在Pytorch框架上实现,所有代码都使用Python语言。这一小节主要说明实验相关的设置,包括使用的数据集,相关评估指标,参数设置以及用于对比的基准模型。 4.2.1 数据集在三个流行的 TKG 数据集 ICEWS14、ICEWS18 、ICEWS05-15上评估GHT模型。综合危机预警系统 (ICEWS[39])是一个国际事件数据集,记载了一定时间段内不同种类的国际事件,并且前后事件有一定的关联,能够通过学习挖掘出很多有价值的信息。它的三个子集ICEWS14、ICEWS18 和 ICEWS05-15 分别包含了2014年、2018年和2005年至2015年发生的国际事件。是评估 TKG 推理模型的性能时最为常用的模型。作为一个开源的知识图谱数据集,ICEWS包含的事件种类丰富,其时间粒度为24小时。 效仿RE-NET,将数据集按时间戳分为训练集、验证集和测试集,并且。这些数据集的统计数据如表4-5所示。 表4-5 数据集统计信息 数据集实体数关系数训练集验证集测试集时间戳ICEWS147128.230636851382313222365ICEWS18230332563730184599549545304ICEWS05-1510488251322958692246914740174.2.2 评估指标MRR和Hits@ ( ∈{1, 3, 10})是实体预测任务下的标准度量指标。MRR 是正确查询答案的排名的平均倒数。模型会按分数排序后输出每个备选实体,找到答案实体在其中的位置,将这个数取倒数以后,再将所有查询样本对应的值求平均,就可以得到MRR。Hits@ 表示在前 个候选实体中正确答案的比例,例如Hits@ =0.25就表示有25%的查询对应的答案排名在前3位。如GHNN中所述,静态过滤设置根据三元组从候选者中删除实体而不考虑时间,不适合 TKG 推理任务。因此,采用时间感知过滤设置,相比静态过滤设置要更加合理适用。 针对时间预测任务,本文采取的评估指标为MSE和MAE。MSE是均方误差,MAE是平均绝对误差,都是一些基本的误差分析指标。此外,大多数以前的工作只评估他们的模型在下一个时间戳进行实体预测的性能。这样的评估不能充分反映模型在未来预测中的性能。因此,我们通过设置时间预测窗口Δ 的大小来评估模型的短期和长期演变. 对于时间预测任务,我们使用预测时间和地面实况时间之间的平均绝对误差(MAE)作为度量。 4.2.3 基准模型针对实体预测任务,将GHT模型与三种类型的知识图谱推理预测模型进行比较。 (1)静态 KG 推理模型,包括 TransE、DistMult和 ComplEx。忽略时间信息,就可以得到一个静态知识图谱,然后在静态图上应用这些模型; (2)TKG内推推理模型,包括TTransE、TA-DistMult、DE-SimplE和TNTComplEx,内推推理模型主要是静态模型的变种。 (3)TKG外推推理模型,包括RE-NET、CyGNet、RE-GCN和TITer。值得注意的是,RE-NET和RE-GCN是与GHT模型最为相关的模型,它们同样也会学习演化表征。因此后续会与这两个模型进行更多的对比分析,来更加客观的反映 对于时间预测任务,现有的模型较少,这里仅将GHT模型与之前的时间点过程模型GHNN进行比较。而Know-Evolve 的模型中有一个公式是存在错误,这一点在RE-NET和GHNN中都已经被讨论过,因此不选择它作为进行对比的基准模型。 4.2.4 参数设置连续时间Transformer(GHT)模型中主要参数如下表4-6。 表4-6 模型参数表 参数名称参数含义batch_size一批样本的大小grad_norm梯度范数值weight_decay权重衰减率d_model模型中出现的嵌入或隐含状态的维度值history_len历史长度,决定了时间窗口大小seqTransformerLayerNum时序Transformer的层数seqTransformerHeadNum时序Transformer的注意头数edge_sample知识图构建选取边的方法lr学习率time_span时间粒度eps计算交叉熵时的参数将所有嵌入向量和隐藏状态的维度都默认设置为100。时间知识图的历史长度限制为10。关系图Transformer 的层数设置为 2,注意力头数为 1。对于时序Transformer,层数为 2,注意头数为2。模型对每一层应用dropout,dropout率为50%,并使用标签平滑来抑制过拟合,标签平滑的交叉熵中的参数eps设为0.1。两个任务损失的超参数 设置为 0.2。模型采用warmup lr进行学习率的预热。我们使用 Adam 优化器来优化参数,学习率为 0.003,权重衰减为 0.0001。它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳,对内存需求也比较小,很适合大数据集的训练。训练过程中批量大小设置为 256,最大epoch数为30,每训练5个epoch保存一次模型。 在推理过程中,静态推理模型、内推推理模型和CyGNet不对历史信息进行编码。因此,它们在短期和长期进化任务中的表现是相同的,因此我们直接使用以前工作中报告的结果。对于TITer、RE-NET、RE-GCN和GHNN,使用它们发布的带有默认超参数的源代码,我们在四个基准上重新运行这些模型。为了确保公平性,对于RE-GCN,我们不使用对节点类型信息进行编码的模块。 4.3 实验结果与评估这一小节将会给出两个任务的实验结果和相应的分析,从整体上评估模型的性能。评估的角度包括模型的准确率、各个模块功能的消融实验、模型超参数的敏感性分析以及模型的效率分析。 4.3.1 实体预测首先通过一系列表格来说明GHT模型针对不同数据集的各项指标并与4.1提到的基准数据集进行对比。这些表格详细报告了Δ =5和Δ =10的情况下预测的结果。为了探究推演时间跨度对模型性能的影响,文章汇报了三个数据集上模型随着推演时间跨度的增长的MRR,其中 表示模型将在时间 后对未来事件进行预测。 下面的表4-7 、表4-8、表4-9分别说明了Δ = 5时模型在ICEWS14、ICEWS18以及ICEWS05-15上实体预测任务的表现: 表4-7 Δ = 5时ICEWS14上实体预测的结果 数据集MRRH@1H@3H@10TransE22.4813.3625.6341.23Distmult27.6718.1631.1546.96ComplEx30.8421.5134.4849.59TTransE13.433.1117.3234.55TA-DistMult26.4717.0930.2245.41DE-SimplE32.6724.4335.6949.11TNTComplEx32.1223.3536.0349.13表4-7(续) Δ = 5时ICEWS14上实体预测的结果 数据集MRRH@1H@3H@10CyGNet32.7323.6936.3150.67TITer37.4928.6941.8853.93RE-NET36.2827.1940.1653.51RE-GCN36.9528.0440.9254.07GHT38.2828.4342.8557.47±0.25±0.21±0.18±0.09表4-8 Δ = 5时ICEWS18上实体预测的结果 数据集MRRH@1H@3H@10TransE12.245.8412.8125.1Distmult10.174.5210.3321.25ComplEx21.0111.8723.4739.97TTransE8.311.928.5621.89TA-DistMult16.758.6118.4133.59DE-SimplE19.3011.5321.8634.80TNTComplEx21.2313.2824.0236.91CyGNet24.9315.9028.2842.61TITer26.5118.9829.5940.59RE-NET27.3817.9331.0445.65RE-GCN28.0118.9731.8945.84GHT28.3818.7832.0147.27±0.18±0.15±0.17±0.11可以看出在ICEWS18数据集、ICEWS05-15上模型的表现与ICEW14类似,都有着非常好的性能。GHT的MRR、H@3、H@10全面高于现有模型,仅在H@1上略逊于部分其他模型。可以说GHT在实体预测任务上取得了出色的效果,有着很高的应用价值。 表4-9 Δ = 5时ICEWS05-15上实体预测的结果 数据集MRRH@1H@3H@10TransE22.5513.0525.6142.05Distmult28.7319.3332.1947.54ComplEx31.6921.4435.7452.04TTransE15.715.0019.7238.02TA-DistMult24.3114.5818.4133.59DE-SimplE35.0225.9138.9952.75TNTComplEx27.5419.5230.8042.86CyGNet34.9725.6739.0952.94TITer40.1529.5545.7560.49RE-NET40.2830.1145.5460.67RE-GCN41.1931.3246.0860.33GHT42.9031.7648.7764.64±0.20±0.19±0.21±0.17后续表格仅显示了 TKG 外推推理的模型的实验结果,因为其他模型的结果不受时间窗口大小的影响。它们的结果可以在表4-7、表4-8、表4-9中找到。因此后面的三个表格将集中在Δ = 10时几个外推模型之间的对比。将由表4-10、表4-11、表4-12说明。 表4-10 Δ = 10时ICEWS14上实体预测的结果 数据集MRRH@1H@3H@10CyGNet32.7323.6936.3150.67TITer36.0627.5140.1652.05RE-NET35.7126.7939.5752.81RE-GCN36.0827.3039.8653.01GHT37.4027.7741.6656.19±0.13±0.10±0.09±0.07表4-11 Δ = 10时ICEWS18上实体预测的结果 数据集MRRH@1H@3H@10CyGNet24.9315.9028.2842.61TITer25.3418.0928.1738.95RE-NET26.8817.7030.3545.04RE-GCN27.3418.4430.4844.85GHT27.4018.0830.7645.76±0.12±0.09±0.12±0.14表4-12 Δ = 10时ICEWS05-15上实体预测的结果 数据集MRRH@1H@3H@10CyGNet34.9725.6739.0952.94TITer38.1126.8344.4359.44RE-NET39.1129.0444.1058.90RE-GCN39.8930.1044.6356.98GHT41.5030.7946.8562.73±0.15±0.17±0.19±0.15在论文中还补充了GDELT数据集上的实验结果与分析。 上述表格的结果表明,GHT 优于所有静态 KG 推理模型和 TKG内推推理模型,因为这些基准模型无法利用时间信息。静态方法没有在连续时间域上进行建模的能力,故不难理解它们的表现很差。内推推理方法需要学习每个时间戳的嵌入表示。然而,在实验任务设置中,模型在训练期间看不到推理的时间戳,导致模型只能使用随机初始化的时间戳嵌入。针对外推推理的方法可以处理看不见的时间戳,但GHT模型在指标 MRR、Hits@3 和 Hits@10 上也优于所有这些方法。在Hits@1指标下,GHT也达到了先进 (SOTA)的性能。 以往的模型只在下一时刻做出预测,这与显示不符,因为一个事件在明天发生和一个月后发生的意义明显是完全不同的。因此模型不仅要考虑预测未发生的是哪个事件,还要考虑是在哪个时刻发生。因此实验中引入了时间窗口这一概念,由图4-1、图4-2以及图4-3说明几个模型随着时间预测间隔dt变化的MRR值。  图4-1 ICEWS14上不同模型随dt变化的MRR 图4-1 ICEWS14上不同模型随dt变化的MRR 图4-2 ICEWS18上不同模型随dt变化的MRR图4-3 ICEWS05-15上不同模型随dt变化的MRR 图4-2 ICEWS18上不同模型随dt变化的MRR图4-3 ICEWS05-15上不同模型随dt变化的MRR通过上面三个曲线图进一步分析和比较这些模型。可以看出,虽然 TITer在dt=1时优于其他模型,但它在更长期的未来预测中衰减得更快。这是因为它在局部子图中搜索查询答案,更多地关注显式的线索。随着推演时间跨度的增长,那些显式线索将逐渐减少,而隐性线索将变得更加重要。此外,从相邻子图中检索答案会限制候选答案空间,这在长期进化任务中更为明显。模型在预测未来事件全面优于 RE-NET 和 RE-GCN,因为它们使用启发式进化方法通过渐进进化来预测长期事件,在进化过程中忘记了先前的知识。相比之下,GHT在编码结构信息时引入了注意力机制,这有助于模型捕获更多有用的信息来回答查询。总体而言,GHT具有出色的性能,在执行实体预测任务时提供了更好的选择,特别是在时间间隔较长的情况下。 4.3.2 时间预测图4-4显示了时间预测任务的结果。结果表明了GHT模型利用 Transformer进行条件强度函数构建的优越性。这是因为GHNN 通过简单的均值池聚合邻居信息,并且只关注最相关的一阶邻居。相比之下,GHT中的RGT 具有更好的结构信息提取能力。此外,GHNN 使用连续时间 LSTM来估计强度函数,在捕获复杂的长期和短期依赖关系方面不如 Transformer 结构。因此,GHT 的时间预测性能优于 GHNN。 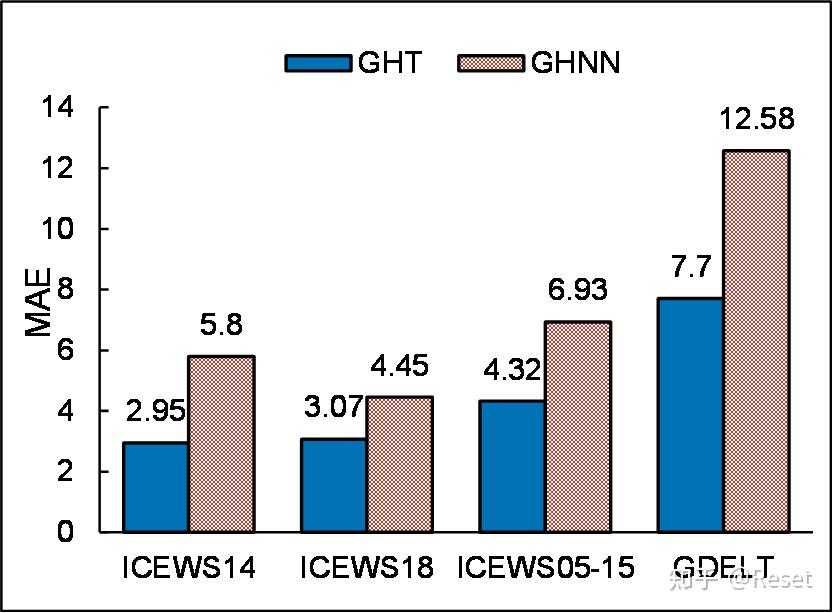 图4-4 时间预测MAE对比图4.3.3 效率分析 图4-4 时间预测MAE对比图4.3.3 效率分析本节分析每个模块的GHT 的计算复杂度。RGT的计算复杂度是,其中 是层数, 是消息数(图的度数), 是维度。对于TT,计算复杂度为, 是序列长度。因此,GHT的计算复杂度为。  图4-5 ICEWS14上模型的推演时间 图4-5 ICEWS14上模型的推演时间图4-5以Δ =5时ICEWS14 上的实验结果为例说明了RE-NET、RE-GCN 和 GHT的推理时间。采取这样的选取策略是因为这三个模型相似度更高,在效率分析上更有代表性。可以看到 RE-NET 推理是最慢的,因为它需要逐个处理每个时间戳的查询。RE-GCN 同样也是一个启发式模型,它也需要一步一步地在下一个时间戳上完成预测。相比之下,GHT模型可以并行预测在多个不同时间戳发生的事件。因此,与 RE-NET 和 RE-GCN 相比,进化过程越长,GHT推理所需的时间相对就越少。 4.4 消融实验与分析在本小节中,分别研究 GHT 中每个模块对结果的影响,结果将会汇总在表4-13和图4-6中。所有消融实验都是在以ICEWS14 数据集为例进行,其他数据集上的情况类似。特别地,尝试了各种编码函数来展示GHT模型中关系时间编码函数的有效性,并使用其他GNN 代替 RGT 来验证 RGT 的性能。表4-13中报告了实体预测消融实验结果,图4-6中报告了时间预测上的消融实验结果。 表4-13 ICEWS14上实体预测的消融实验 数据集MRRH@1H@3H@10GHT w.o. TE36.2126.5240.3155.69GHT w. APE36.4226.9140.4655.20GHT w. RPE36.4926.8840.7355.24GHT w. RGCN33.8624.2537.8752.75GHT37.4027.7741.6656.19 图4-6 时间预测的消融实验4.4.1 图聚合器的消融实验 图4-6 时间预测的消融实验4.4.1 图聚合器的消融实验R-GCN 是最常见的关系图聚合器,用于 RE-NET 和 RE-GCN。用R-GCN代替RGT并表示为模型 GHT w. RGCN。图表中的结果表明 GHT在实体和时间预测任务上显著优于 GHT w. RGCN。进一步表明 RGT 比 R-GCN 更适合 TKG 外推推理。这是因为相比 R-GCN,RGT 可以从复杂的结构信息中提取更多有用的信息用于查询回答。 4.4.2 时间编码函数的消融实验为了验证GHT中设计的关系连续时间编码函数是否有效,将 GHT 与几个使用不同位置编码方法的变体进行了比较。(1)不使用时间编码函数,表示为 GHT w.o. TE。(2)将编码替换为绝对位置编码,记为 GHT w. APE。(3)将编码替换为相对位置编码,记为 GHT w. RPE。在表4-12和图4-6中,可以观察到 GHT 在实体和时间预测任务上都优于所有其他变体。值得注意的是GHT w. APE 和GHT w. RPE 的效果与不使用位置编码功能几乎相同。这表明他们没有学习到相关位置或时间信息。相比之下,关系连续时间编码可以有效地捕获时间信息并帮助模型取得更好的性能。 4.5 参数敏感性分析本节讨论GHT 的超参数敏感性,包括 RGT 的层数和注意力头数,TT 的层数和注意力头数以及历史长度等。图4-7中汇报了ICEWS14()上的各个参数敏感性分析的结果。  图4-7 超参数研究4.5.1 历史长度敏感性分析 图4-7 超参数研究4.5.1 历史长度敏感性分析GHT 需要对历史序列信息进行建模,固定一个超参数来限制最大序列长度。图4-7a显示了不同历史长度下的MRR性能。如果历史长度低于6,则历史越长,GHT 性能越好。但是,继续延长会使 MRR 下降。它表明有效信息密度会在某一个历史长度下达到最优。 4.5.2 RGT参数敏感性分析RGT 的层数对应于聚合的邻居顺序。图4-7c显示注意力头数为2时模型性能最高,但注意力头数量对实验影响很小。而图4-7e说明了RGT注意力层数的影响。实验表明模型在层数为2时表现最佳,相比1层聚合的结构信息更多。但是,随着层数的增加,模型的性能会下降。这可能是因为在 ICEWS数据集中,三阶以上的邻居很少提供更多信息,反而会引入噪声。 4.5.3 TT敏感性分析图4-7b和图4-7d显示了具有不同 TT 层数和注意力头数下的GHT的性能。可以注意到拥有 TT注意力头为1的模型比其他模型表现更好。但与RGT 的层数相比,模型对 TT 的注意力层数不太敏感。 4.6 Case Study以ICEWS14数据集为例,Oman是查询(Catherine Ashton,Make a visit,?,2014/11/09)的正确答案。在过去的十天里,凯瑟琳·阿什顿有114个一步邻居和658个两步邻居。RE-NET和RE-GCN预测答案为“John Kerry”(与“Catherine Ashton”互动最多的候选节点)。只有GHT做出了正确的预测。就历史事件而言,GHT最为关注('Catherine Ashton,' 'Express intent to meet or negotiate,' Oman,' 2014/11/05),其中RGT的权重为0.789,TT的权重为0.478。它证明了GHT可以挖掘出其他模型无法挖掘的历史事件信息。 4.7 本章小结本章对GHT模型的实体预测和时间预测功能进行了实验以及评估。首先明确了实验环境和实验的基本设置。本章通过使用大量图表,说明了GHT模型在实体预测和时间预测两个任务上的卓越性能,展现了GHT的优越性,证明其已经超越了之前的SOTA方法。接着又进行消融实验和参数敏感性的分析,明确了新加模块的作用,了解了GHT对于超参数的敏感程度,为进一步改进提供了基础。 5 总结与展望5.1 全文总结最近几年,时间知识图谱预测领域发展迅速,更加先进的模型不断出现。这些方法基于迥异的方法,但都不能同时很好的捕捉图数据中的时间信息和结构信息,并存在着诸多局限性。本文针对这些限制,提出了一个新的TKG预测模型GHT,这是一种基于 Transformer的神经时间点过程模型,它主要完成了如下几点工作: (1)设计了两个 Transformer 模块,即RGT和TT,分别用于捕获结构信息和时序信息。其中RGT模块通过注意力机制聚合节点和边的信息生成携带结构化信息的隐含向量。TT模块引入了正余弦时间编码机制,将时间编码加入到隐含向量中,使得模型在学习序列向量时也学习到了时间戳的信息。 (2)基于时间点过程,通过注意力机制和提出的关系连续时间编码函数学习条件强度函数,并利用生成的强度函数完成了实体预测和时间预测任务。将神经时间点过程与Transformer巧妙的进行了结合。 (3)设置了不同的预测时间窗口大小来全面评估模型,使得模型具备了在未来任意时间戳下完成推理预测的能力。在三个ICEWS 数据集上的实验结果证明了GHT模型在实体预测和时间预测任务上的优越性能。相比已有的SOTA模型,GHT在长期演化场景下的表现更为突出。 (4)进行了消融实验和敏感性分析。反映了RGT和TT的实际效果,明确了各个超参数对模型效果的影响,证明了GHT具有更好的并行计算效率。 本文有如下创新点: (1)第一个使用Transformer架构的时间知识图谱预测模型,在提取多关系图数据的结构信息与时序信息的场景下表现出色。 (2)第一个将神经时间点过程与TKG任务结合,通过构建条件强度去完成实体预测和时间预测。 (3)能在未来多个时刻,做出差异化的事件预测 5.2 未来展望尽管本文提出的GHT时间知识图谱预测模型在ICEWS的多个数据集上已经实现了SOTA的性能,并且证明了其在长期演化场景下预测能力全面领先当前模型,但它仍然存在这以下几个方面的不足,有待进一步地改进。 (1)目前的模型在短期任务上性能还未达到最优,这是因为模型还没有将邻居信息完全利用。下一步要更新子图创建时的取样规则,优化Transformer的结构,采用更合适的时间编码,让模型能够更好地挖掘时间与结构信息。 (2)针对目前模型受数据集特征影响较大的问题,在此工作的基础上,可以为 TKG 演化任务设计一个自监督学习任务,例如自动编码器,从而进一步提高模型性能。 (3)目前仅在ICEWS数据集上进行了实验,后续考虑在不同时间粒度的更多数据集上进行实验,WIKI,YAGO等。以更加客观全面的反映GHT模型的性能。 (4)基于大模型,进一步解决相关任务 参考文献Zhen Han, Peng Chen, Volker Tresp et al. Explainable Subgraph Reasoning for Forecasting on Temporal Knowledge Graphs[C]. In International Conference on Learning Representations. 2021. Haohai Sun, Jialun Zhong, Kun He et al. TimeTraveler: Reinforcement Learning for Temporal Knowledge Graph Forecasting[C]. In Empirical Methods in Natural Language Processing. 2021. 8306–8319. Alan G Hawkes. Point Spectra of Some Mutually Exciting Point Processes[J]. Journal of the Royal Statistical Society: Series B (Methodological) 33, 3. 1971. 438–443. 李嘉程. 基于点过程的用户回归时间预测 [D].电子科技大学, 2020. DOI:10.27005/d.cnki.gdzku. 2020.000383. Oleksandr Shchur, Ali Caner Türkmen, Tim Januschowski et al. Neural Temporal Point Processes: A Review[C]. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence. 2021. 4585–4593. Zhou K, Zha H, Song L. Learning Social Infectivity in Sparse Low-rank Networks Using Multi-dimensional Hawkes Processes[C]. In Artificial Intelligence and Statistics. PMLR, 2013. 641-649. Mei H, Eisner J M. The Neural Hawkes Process: A Neurally Self-modulating Multivariate Point Process[J]. Advances in neural information processing systems, 2017. 30. Zhang Q, Lipani A, Kirnap O, et al. Self-attentive Hawkes process[C]. In International conference on machine learning. PMLR, 2020. 11183-11193. Zuo S, Jiang H, Li Z, et al. Transformer Hawkes Process[C]. In International conference on machine learning. PMLR, 2020. 11692-11702. Ashish Vaswani, Noam Shazeer, Niki Parmar et al. Attention is All You Need. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems. 2017. 5998–6008. Tianyang Lin, Yuxin Wang, Xipeng Qiu et al. A Survey of Transformers[J]. arXiv:2106.04554, 2021. Vijay Prakash Dwivedi and Xavier Bresson. A Generalization of Transformer Networks to Graphs[J]. arXiv preprint arXiv:2012.09699, 2020. Chengxuan Ying, Tianle Cai, Tie-Yan Liu et al. Do Transformers Really Perform Bad for Graph Representation?[J]. arXiv preprint arXiv:2106.05234, 2021. Seongjun Yun, Minbyul Jeong, Hyunwoo J Kim et al. 2019. Graph Transformer Networks. Advances in Neural Information Processing Systems 32. 2019. 11983–11993. Ziniu Hu, Yuxiao Dong Yizhou Sun et al. 2020. Heterogeneous Graph Transformer. In WWW ’20: The Web Conference 2020. 2704–2710. Antoine Bordes, Nicolas Usunier, Oksana Yakhnenko et al. 2013. Translating embeddings for modeling multi-relational data. In Neural Information Processing Systems. 2787–2795. Bishan Yang, Wen-tau Yih, Li Deng et al. Embedding Entities and Relations for Learning and Inference in Knowledge Bases[J]. arXiv preprint arXiv:1412.6575, 2014. Théo Trouillon, Johannes Welbl, Guillaume Bouchard et al. 2016. Complex Embeddings for Simple Link Prediction. In Proceedings of the 33rd International Conference on Machine Learning. 2071–2080. Schlichtkrull M, Kipf T N, Bloem P, et al. Modeling Relational Data with Graph Convolutional Networks[C]. In European semantic web conference. Springer, Cham, 2018. 593-607. Vashishth S, Sanyal S, Nitin V, et al. Composition-based multi-relational graph convolutional networks[J]. arXiv preprint arXiv:1911.03082, 2019. Leblay J, Chekol M W. Deriving validity time in knowledge graph[C]. In Companion Proceedings of the The Web Conference 2018. 2018. 1771-1776. García-Durán A, Dumančić S, Niepert M. Learning Sequence Encoders for Temporal Knowledge Graph Completion[J]. arXiv preprint arXiv: 1809.03202, 2018. Goel R, Kazemi S M, Brubaker M, et al. Diachronic Embedding for Temporal Knowledge Graph Completion[C]. In Proceedings of the AAAI Conference on Artificial Intelligence. 2020. 34(04): 3988-3995. Lacroix T, Obozinski G, Usunier N. Tensor Decompositions for Temporal Knowledge Base Completion[J]. arXiv preprint arXiv:2004.04926, 2020. Jin W, Qu M, Jin X, et al. Recurrent Event Network: Autoregressive Structure Inference over Temporal Knowledge Graphs[C]. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. 6669-6683. Li Z, Jin X, Li W et al. Temporal Knowledge Graph Reasoning Based on Evolutional Representation Learning[C]. In Proceedings of the 44th international ACM SIGIR Conference on Research and Development in Information Retrieval. 2021. 408-417. Zhu C, Chen M, Fan C, et al. Learning from History: Modeling Temporal Knowledge Graphs with Sequential Copy-Generation Networks[C]. In Proceedings of the AAAI Conference on Artificial Intelligence. 2021, 35(5): 4732-4740. Trivedi R, Dai H, Wang Y, et al. Know-evolve: Deep temporal reasoning for dynamic knowledge graphs[C]. In international conference on machine learning. PMLR, 2017. 3462-3471. Han Z, Ma Y, Wang Y, et al. Graph Hawkes Neural Network for Forecasting on Temporal Knowledge Graphs[J]. arXiv preprint arXiv:2003.13432, 2020. 任欢,王旭光. 注意力机制综述[J]. 计算机应用, 2021. 41(S1):1-6. Ba J L, Kiros J R, Hinton G E. Layer Normalization[J]. arXiv preprint arXiv:1607.06450, 2016. Dai Z, Yang Z, Yang Y, et al. Transformer-xl: Attentive Language Models beyond a Fixed-length Context[J]. arXiv preprint arXiv:1901.02860, 2019. Ke G, He D, Liu T Y. Rethinking Positional Encoding in Language Pre-training[C]. International Conference on Learning Representations. 2020. Shaw P, Uszkoreit J, Vaswani A. Self-Attention with Relative Position Representations[C]. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). 2018. 464-468. Jacob Devlin, Ming-Wei Chang, Kristina Toutanova et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In NAACL-HLT. 2019. 4171–4186. Da Xu, Chuanwei Ruan, Evren Körpeoglu, Sushant Kumar, and Kannan Achan. Inductive Representation Learning on Temporal Graphs[C]. In 8th International Conference on Learning Representations. 2020. Josef Stoer and Roland Bulirsch. Introduction to Numerical Analysis. Vol. 12[J]. Springer Science & Business Media. 2013. Boschee E, Lautenschlager J, O’Brien S, et al. ICEWS Coded Event Data[J]. Harvard Dataverse, 2015.12. |
【本文地址】
今日新闻 |
推荐新闻 |