单层LSTM和多层LSTM的输入与输出 |
您所在的位置:网站首页 › lstm多输入预测matlab程序 › 单层LSTM和多层LSTM的输入与输出 |
单层LSTM和多层LSTM的输入与输出
|
单层LSTM的输入与输出
RNN结构: 对应的代码为:(代码中没写偏置)
那么对于在pytorch中的函数LSTM的参数的输入情况如下: 输入数据: X的格式:(seq_len,batch,input_size) #batch是批次数,可以在LSTM()中设置batch_first,使得X的输入格式要求变为(batch,seq_len,input_size)h0的格式:(1,batch,hidden_size)c0的格式:(1,batch,hidden_size) 因为不管输入的数据X是多少个特征的,h0和c0的都只需要一个输入就行。对于输出,输出的hidden_size的大小是由门控中的隐藏的神经元的个数来确定的。 输出的格式: H的格式:(seq_len,batch,hidden_size) #如果按照(seq_len,batch,hidden_size) 的格式输出,需要在LSTM()中设置return_sequences=True,否则默认只输出最后一个时间步的输出结果(1,batch,hidden_size).hn的格式:(1,batch,hidden_size)cn的格式:(1,batch,hidden_size)这只是LSTM单元的输入输出格式,真实的其后还要跟一个全连接层,用于把LSTM的输出结果映射到自己想要的结果上,如分类:
如果是双向的,即在LSTM()函数中,添加关键字bidirectional=True,则: 单向则num_direction=1,双向则num_direction=2 输入数据格式: input(seq_len, batch, input_size) h0(num_layers * num_directions, batch, hidden_size) c0(num_layers * num_directions, batch, hidden_size) 输出数据格式: output(seq_len, batch, hidden_size * num_directions) hn(num_layers * num_directions, batch, hidden_size) cn(num_layers * num_directions, batch, hidden_size) 补充细节,下面是转载的: 版权声明:本文为CSDN博主「ssswill」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/ssswill/article/details/88429794 可以看到中间的 cell 里面有四个黄色小框,你如果理解了那个代表的含义一切就明白了,每一个小黄框代表一个前馈网络层,对,就是经典的神经网络的结构,num_units就是这个层的隐藏神经元个数,就这么简单。其中1、2、4的激活函数是 sigmoid,第三个的激活函数是 tanh。 另外几个需要注意的地方: 1、 cell 的状态是一个向量,是有多个值的。 2、 上一次的状态 h(t-1)是怎么和下一次的输入 x(t) 结合(concat)起来的,这也是很多资料没有明白讲的地方,也很简单,concat, 直白的说就是把二者直接拼起来,比如 x是28位的向量,h(t-1)是128位的,那么拼起来就是156位的向量。 3、 cell 的权重是共享的,这是什么意思呢?这是指这张图片上有三个绿色的大框,代表三个 cell 对吧,但是实际上,它只是代表了一个 cell 在不同时序时候的状态,所有的数据只会通过一个 cell,然后不断更新它的权重。 4、那么一层的 LSTM 的参数有多少个?根据第 3 点的说明,我们知道参数的数量是由 cell 的数量决定的,这里只有一个 cell,所以参数的数量就是这个 cell 里面用到的参数个数。假设 num_units 是128,输入是28位的,那么根据上面的第 2 点,可以得到,四个小黄框的参数一共有 (128+28)*(128*4),也就是156 * 512,可以看看 TensorFlow 的最简单的 LSTM 的案例,中间层的参数就是这样,不过还要加上输出的时候的激活函数的参数,假设是10个类的话,就是128*10的 W 参数和10个bias 参数 5、cell 最上面的一条线的状态即 s(t) 代表了长时记忆,而下面的 h(t)则代表了工作记忆或短时记忆。 LSTM的训练过程:
|
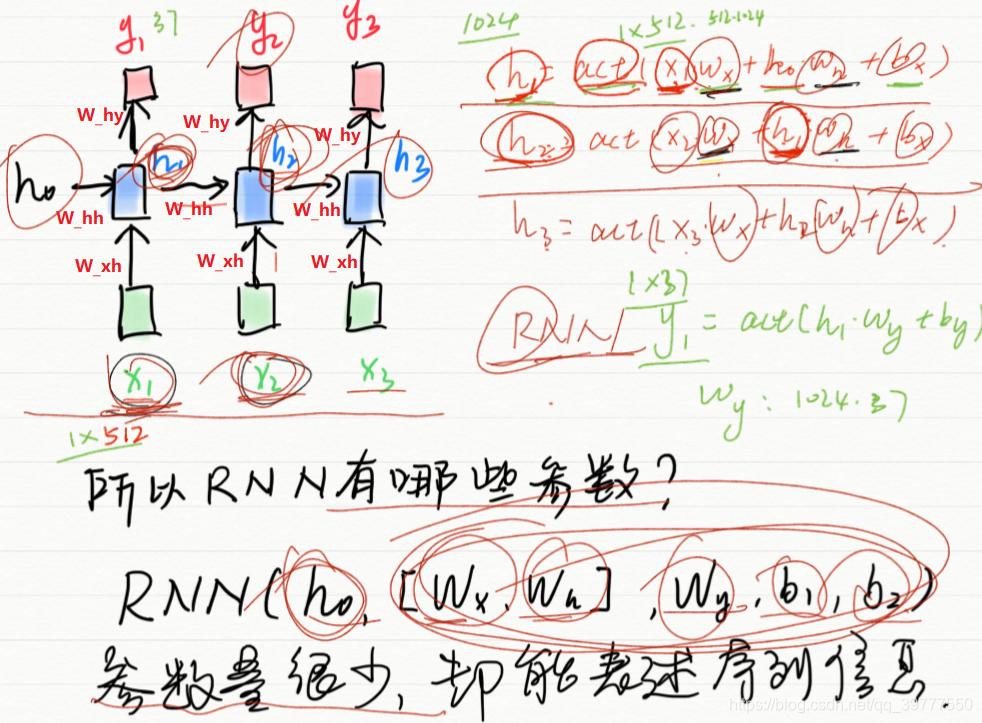

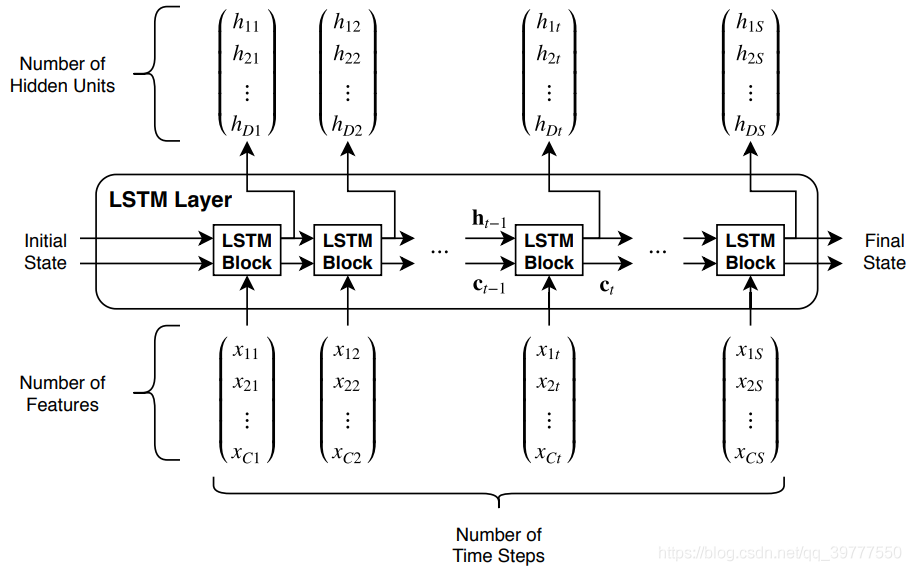 上图是单层LSTM的输入输出结构图。其实它是由一个LSTM单元的一个展开,如下图所示:
上图是单层LSTM的输入输出结构图。其实它是由一个LSTM单元的一个展开,如下图所示: 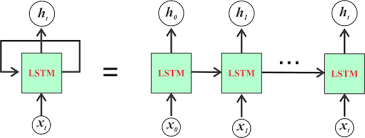 所以从左到右的每个LSTM Block只是对应一个时序中的不同的步。 在第一个图中,输入的时序特征有S个,长度记作:seq_len,每个特征是一个C维的向量,长度记作:input_size。而Initial State是LSTM的隐藏状态和内部状态的一个输入的初始化。分别记作:h0和c0。 输出可以通过设置,来决定是输出所有时序步的输出,还是只输出最后一个时序步的输出。Final_State是隐藏状态和内部状态的输出,记作:hn和cn.
所以从左到右的每个LSTM Block只是对应一个时序中的不同的步。 在第一个图中,输入的时序特征有S个,长度记作:seq_len,每个特征是一个C维的向量,长度记作:input_size。而Initial State是LSTM的隐藏状态和内部状态的一个输入的初始化。分别记作:h0和c0。 输出可以通过设置,来决定是输出所有时序步的输出,还是只输出最后一个时序步的输出。Final_State是隐藏状态和内部状态的输出,记作:hn和cn.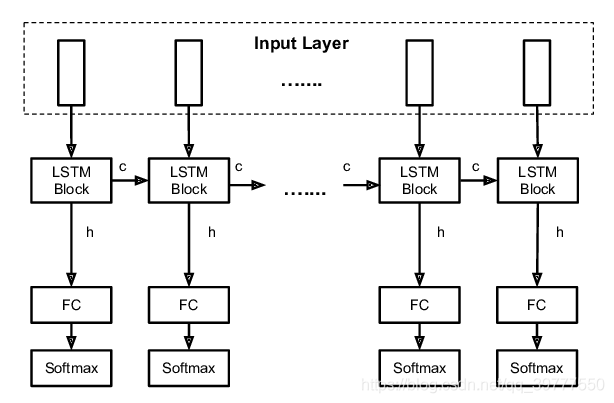 如果只想要研究最后一个时间步的输出结果,只需在最后一个时间步添加全连接即可。
如果只想要研究最后一个时间步的输出结果,只需在最后一个时间步添加全连接即可。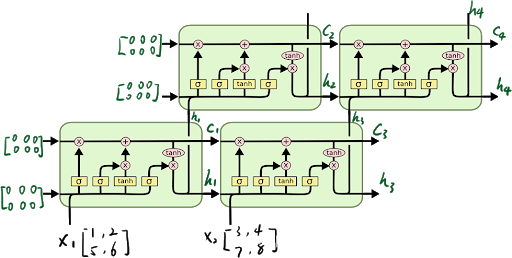 对于多层的LSTM,需要把第一层的每个时间步的输出作为第二层的时间步的输入,如上图所示。 对于num_layers层LSTM:
对于多层的LSTM,需要把第一层的每个时间步的输出作为第二层的时间步的输入,如上图所示。 对于num_layers层LSTM: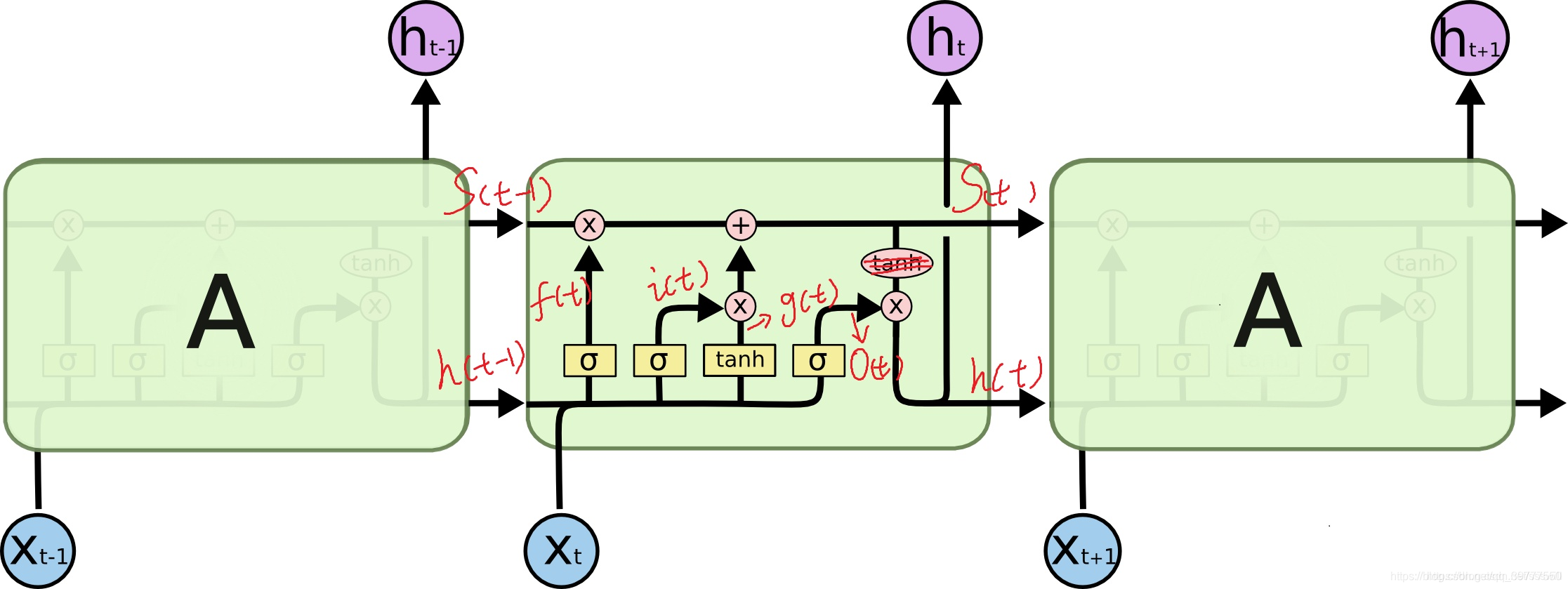 输出的y=act(h_t*W_y)+b_y(图中未显示!)
输出的y=act(h_t*W_y)+b_y(图中未显示!)
 说明:上面画红框的地方,如想输出如上的三维矩阵,需要指明参数:return_sequences=True
说明:上面画红框的地方,如想输出如上的三维矩阵,需要指明参数:return_sequences=True  再附一张图:
再附一张图:  白色框框中,第一行是实现细节,第二行是第一行输出结果的维度。 对于双向的Bi-LSTM网络:
白色框框中,第一行是实现细节,第二行是第一行输出结果的维度。 对于双向的Bi-LSTM网络: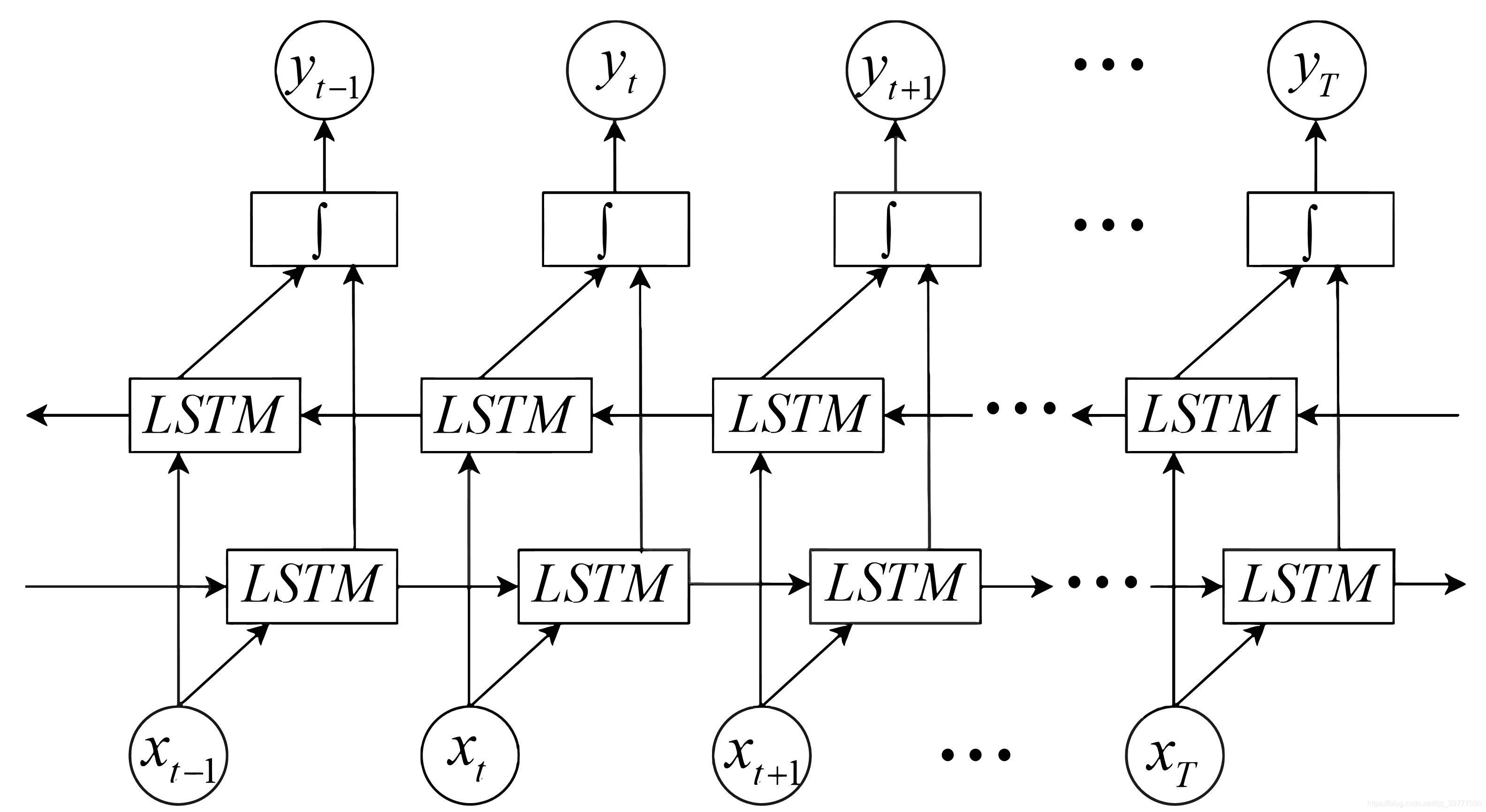 正向求得的第一个正h_1和反向求得的最后一个反h_-1,生成的结果进行对应位置相加,然后再经过act(W_y*h)+b_y得到对应的y.
正向求得的第一个正h_1和反向求得的最后一个反h_-1,生成的结果进行对应位置相加,然后再经过act(W_y*h)+b_y得到对应的y.【本文地址】
今日新闻 |
推荐新闻 |