基于linux的Hadoop配置文件修改和启动 |
您所在的位置:网站首页 › linux重新加载配置文件怎么弄 › 基于linux的Hadoop配置文件修改和启动 |
基于linux的Hadoop配置文件修改和启动
|
前言
之前安装的步骤是安装hadoop的前置工作,现在我们来到了真正的操作环节,目前的操作只需要在master上进行执行,然后可以通过复制到s1,s2。 eg:root/admin,三台都是 eg:master/admin eg:worker1/admii 解压hadoop-2.7.7文件到/usr/local/ 目录下之前我已经上传了hadoop配置文件在/opt目录下
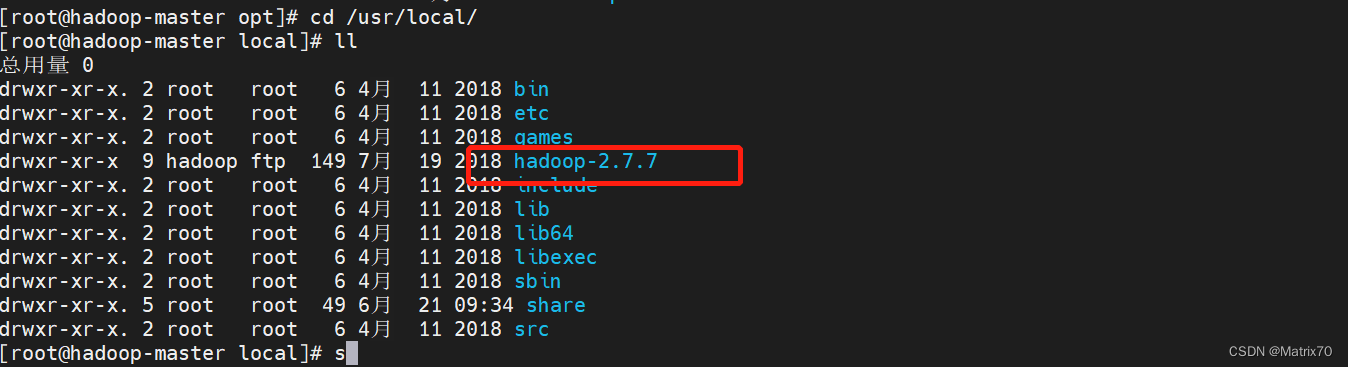
现在我要将他解压到/usr/local目录下 命令: tar -xzvf /opt/hadoop-2.7.7.tar.gz -C /usr/local/,即将opt下hadoop文件解压到/usr/local目录下 
进入/usr/local目录下查看一下
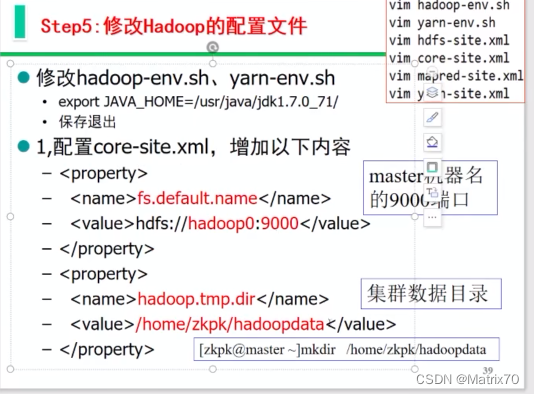
这一次是修改它的配置文件了,本次有hadoop-env.sh yarn-env.sh coresite.xml 三个xml文件。
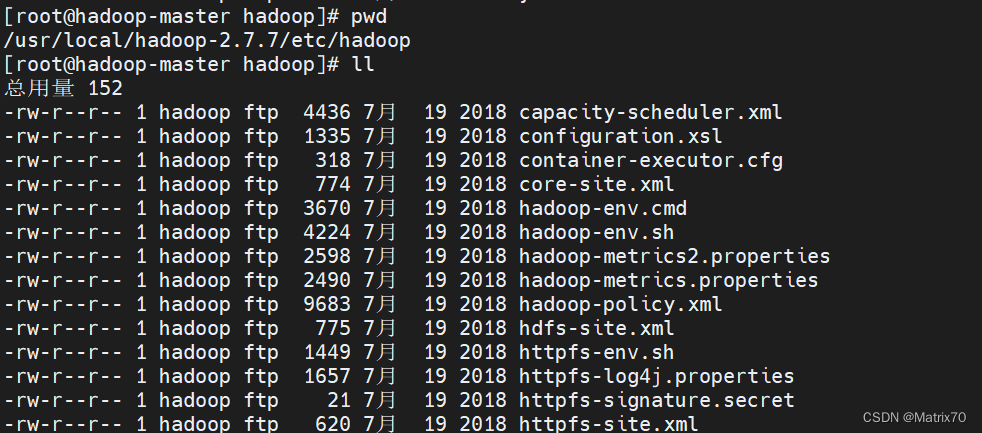
进入到hadoop配置文件界面 /usr/local/hadoop-2.7.7/etc/hadoop
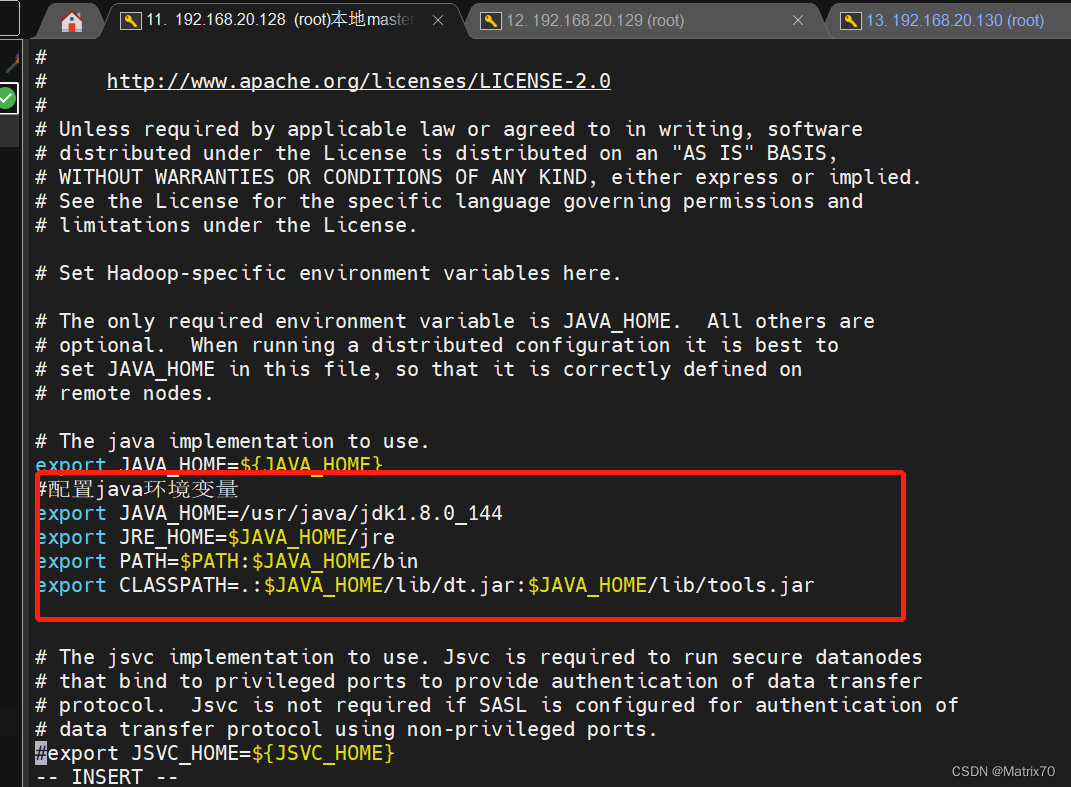
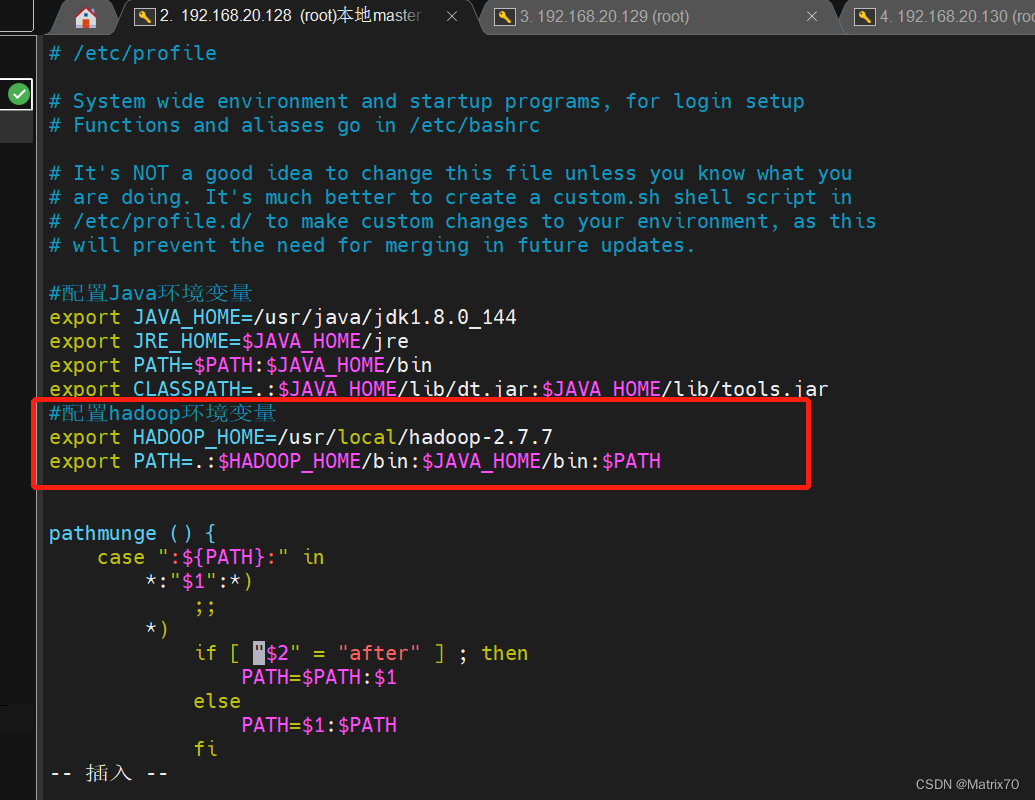
添加环境变量,这个环境变量是JDK的 #配置java环境变量 export JAVA_HOME=/usr/java/jdk1.8.0_144 export JRE_HOME=$JAVA_HOME/jre export PATH=$PATH:$JAVA_HOME/bin export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
修改完,保存退出,source一下,让文件生效 source hadoop-env.sh
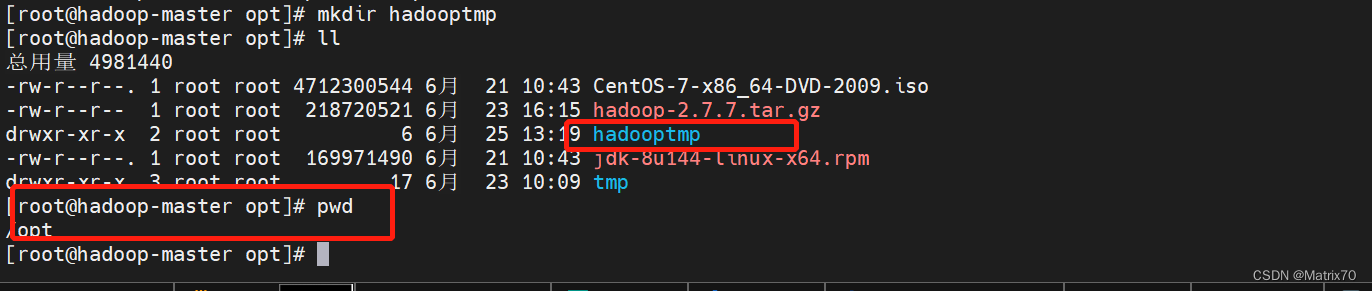
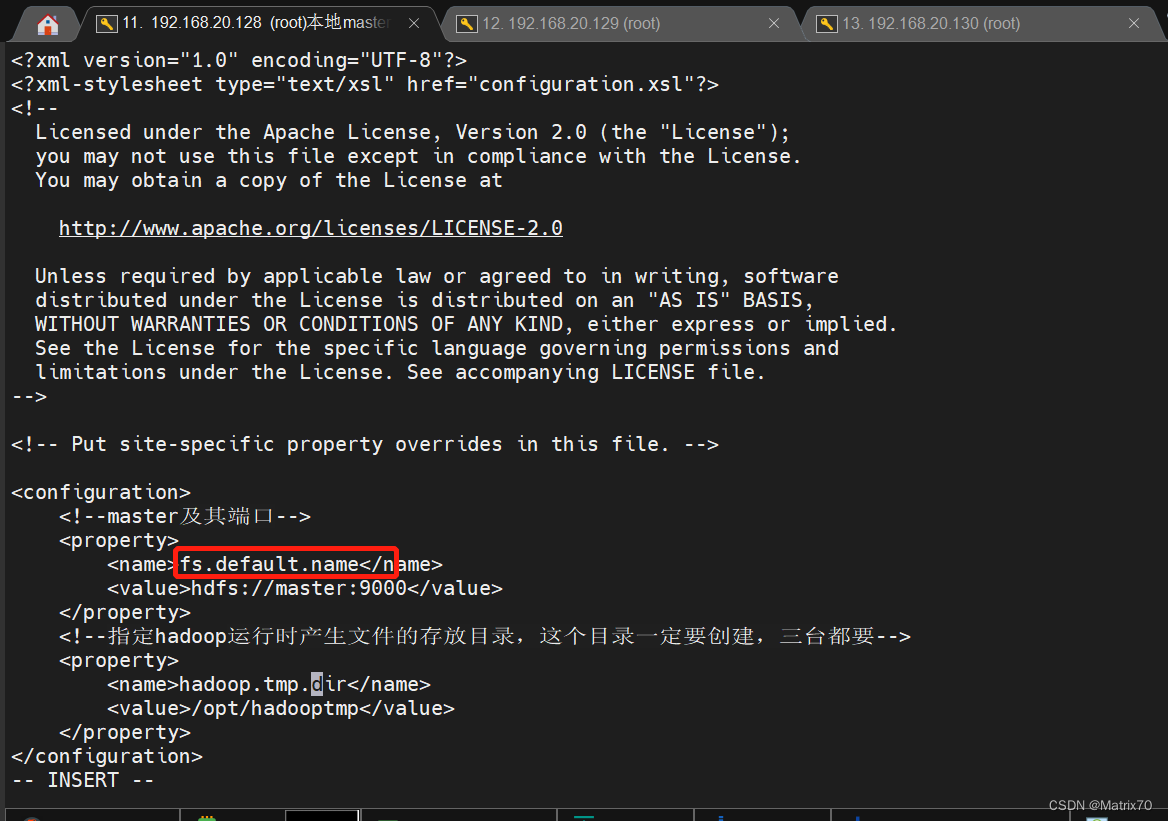
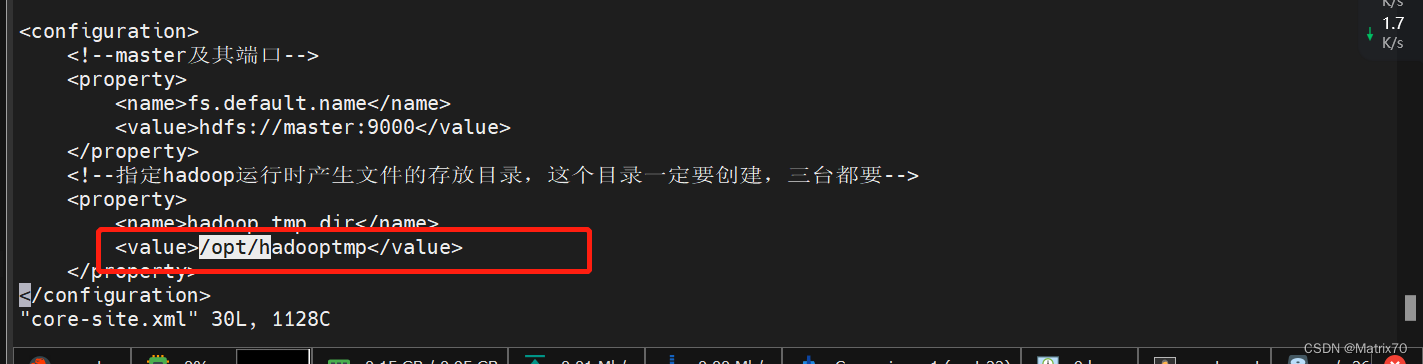
添加如下内容: fs.default.name hdfs://master:9000 hadoop.tmp.dir /opt/hadooptmp完事后保存配置 ,记得创建目录
注意:FS是给两个主机用的,单节点的用defaultname
如下图,配置到name,下面的value是主机名,9000端口 下面的这个地址临时文件。hadoop运行的临时文件地址,我们自己指定一个目录,我想放在opt目录下:
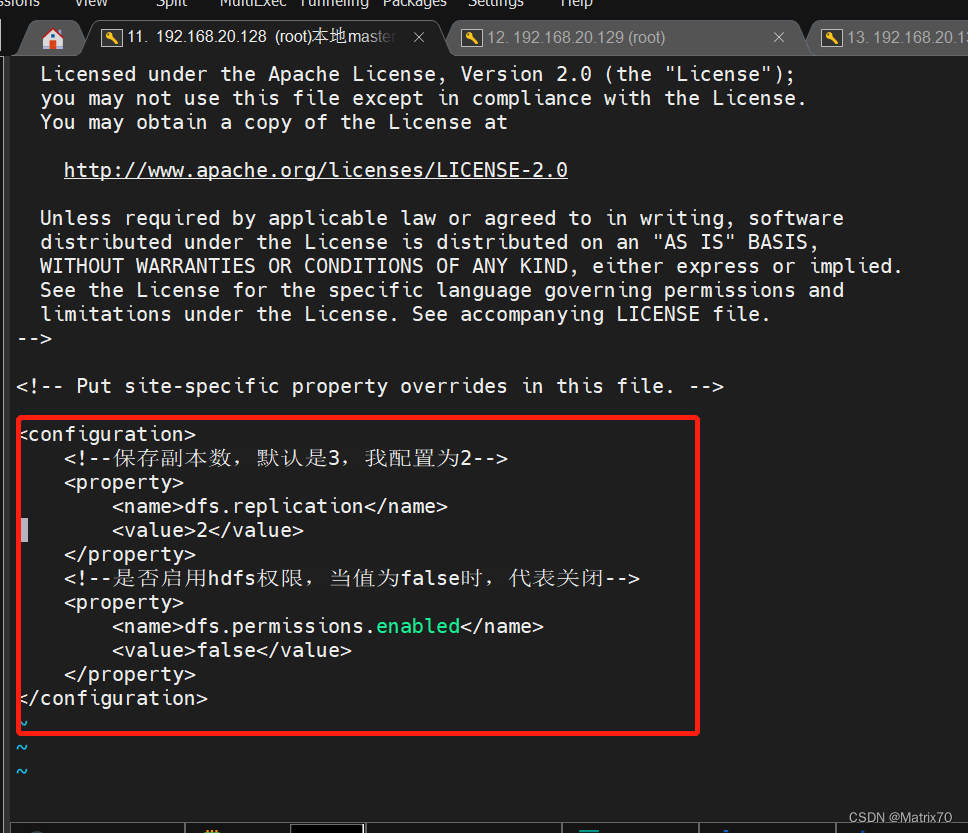
小技巧:注意hdfs-site.xml 中配置的副本在不同机器上,一般设置2~3就行,我们两台从机,就是增加容错性 vi hdfs-site.xml
修改如下图: dfs.replication 2 dfs.permissions.enabled false
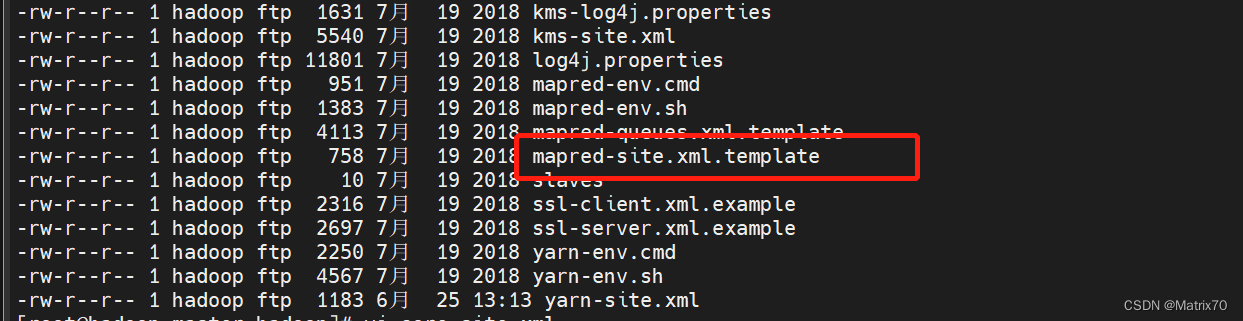
保存配置。 mapred-site.xml对于mapred-site.xml ,如果我们这里没有这个文件怎么办:目录下是mapred-site.xml.tmplate,可以改完此配置后为其重命名mapred-site.xml 。我这里就没有,如果有,就不必重命名,直接修改就好。
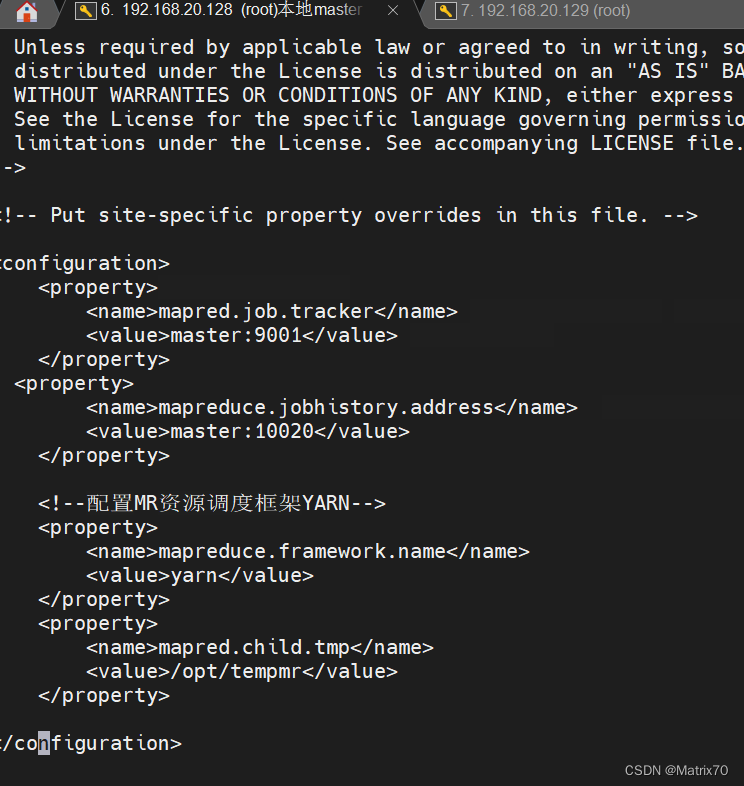
修改配置: mapred.job.tracker master:9001 mapreduce.jobhistory.address master:10020 mapreduce.framework.name yarn mapred.child.tmp /opt/tempmr如下图
修改完保存配置,随后重命名为 mapred-site.xml mv mapred-site.xml.template mapred-site.xml
功能 配置这个是干啥用的,framework有三个模式,第一个class,yarn,local,这个最好看官网,我的解释能力有限。已知的是class已经淘汰了,yarn是计算系统,local是本地的,我们用的是yarn,构建框架,使用yarn进行资源配置和管理。 编辑yarn配置文件 yarn-site.xml在这里,资源管理器的hostname我们指定机器名,设置为主机,我的是master;还有一个shuffle参数,它的值是对shuffle的一个命名,高本版后只允许 字符,数字,下划线等,以前有. ,我们把.改为_ vi yarn-site.xml
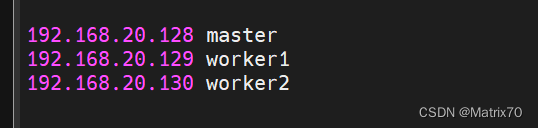
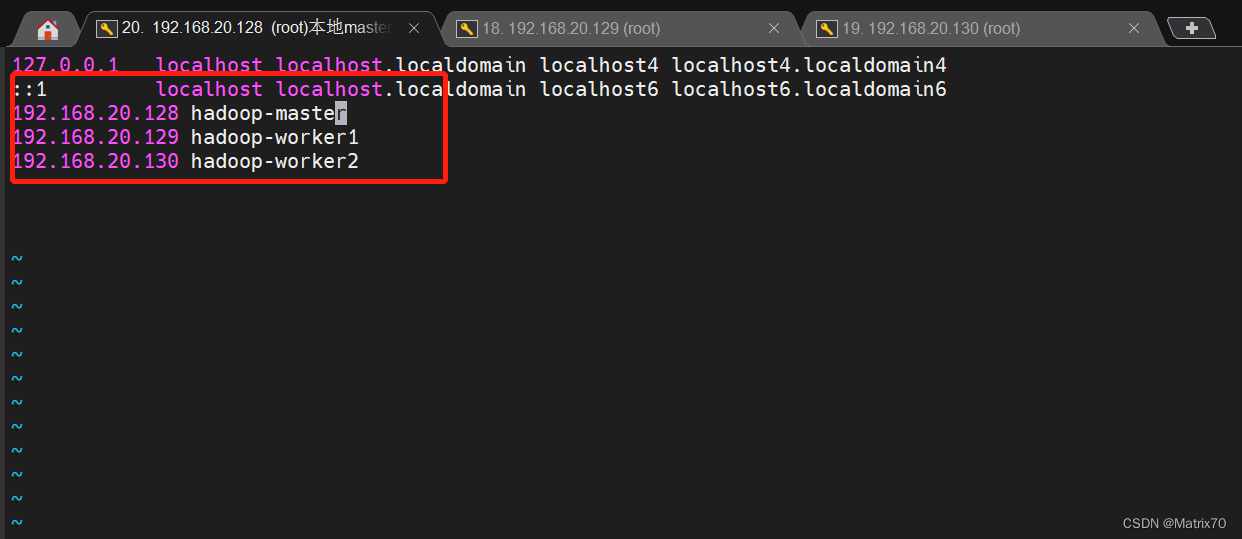
修改完保存一下配置 slaves文件(注:现在由于非洲老表那边,在3.几版本的hadoop,都叫做worker,我现在用的是2.7.7,所以这个文件名还是slaves ) 这个文件里文件名和ip地址都行,我的叫做worker1,worker2,填进slaves就行,一行一个主机名 (注:我之前主机名前都带一个hadoop-,我现在简化了把他删了。) 主:namenode ,用来管理NN机器的名称 从:datanode ,数据节点的机器名称
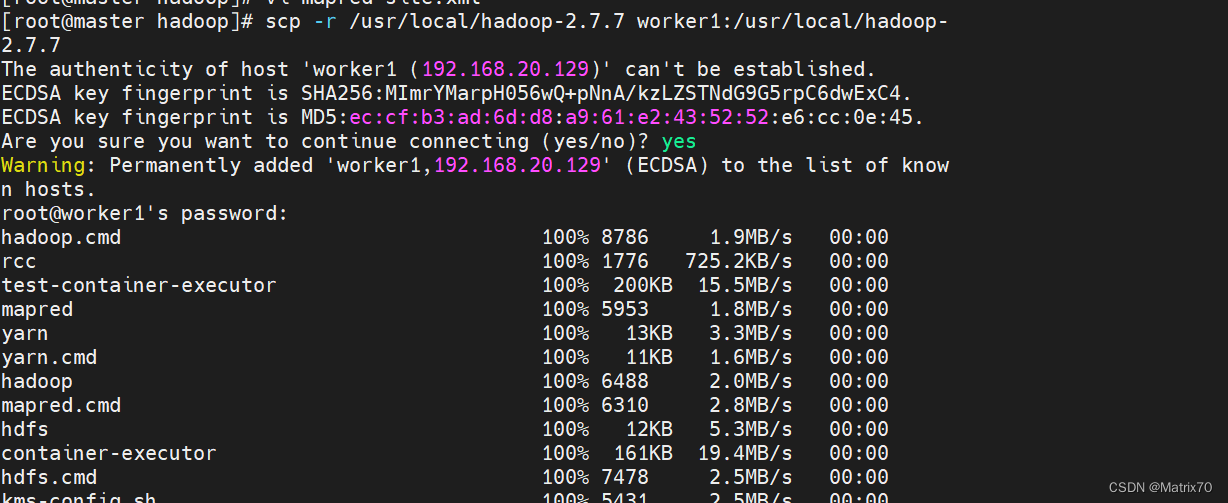
将master文件夹拷贝到worker1及worker2中了。 在master上使用scp -r 命令递归的复制到worker中,如果之前有直接覆盖就行 scp -r /usr/local/hadoop-2.7.7 worker1:/usr/local/hadoop-2.7.7 scp -r /usr/local/hadoop-2.7.7 worker2:/usr/local/hadoop-2.7.7
。。 备注:1、如果此命令报错,我的问题是我在后面把三台的hostname改了,因此主机找到不worker地址,需要把三台的/etc/hosts中对应的主机名改了就行,当然可以直接使用hadoop-worker1也行。原来的是
改过后
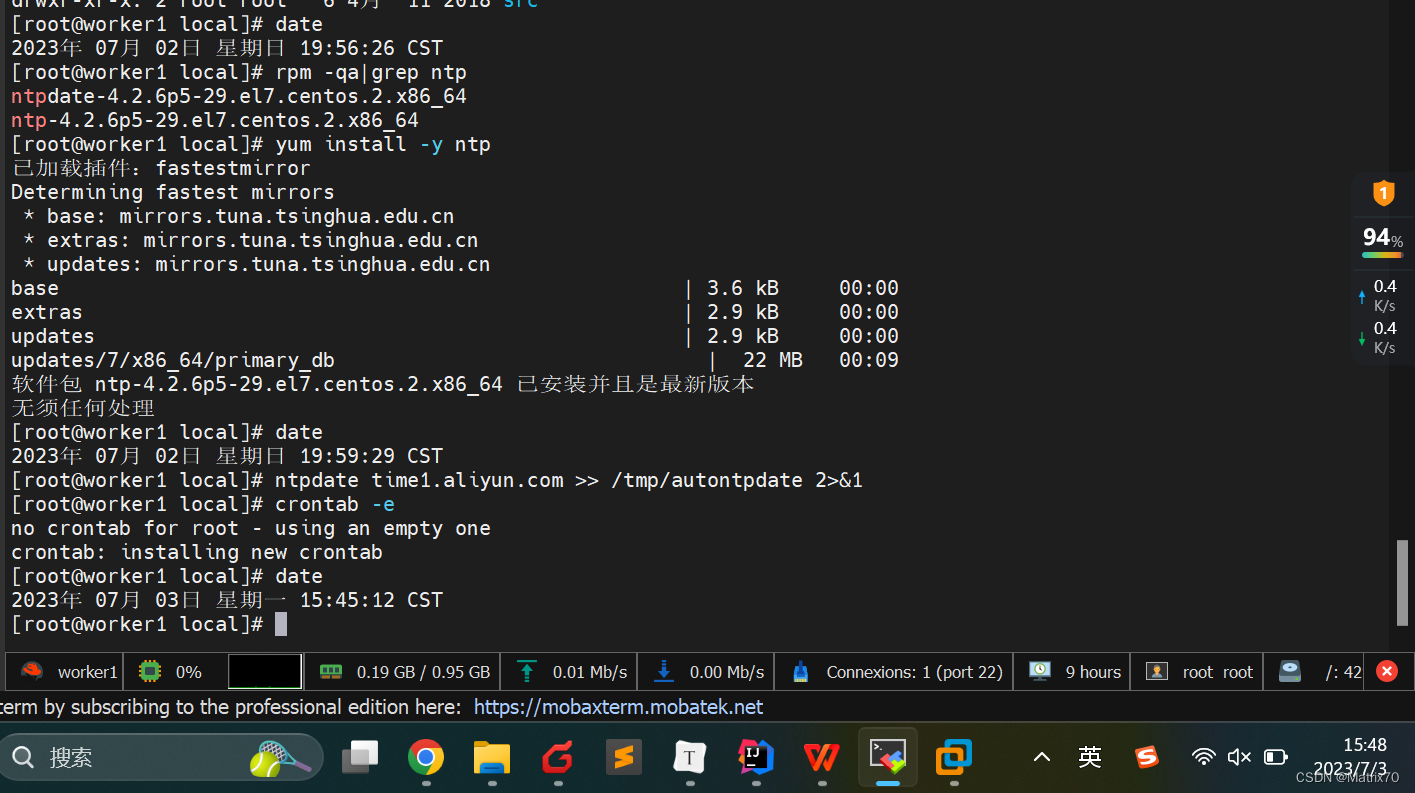
2、还有一点,我使用scp命令传输文件时,出现传输过去了,但是在另一台机器上打开时发现不是我传输过去的文件,需要我讲源文件删除,再重新scp发送就可以了。 一开始我以为传输不过去,于是我做了一个小demo,将文件传输到/opt文件下,scp命令没问题,因此我意识到是文件未删除无法进行覆盖的缘故。 (希望后续随水平提高能够有更好的解释) 记录一个问题在后续进行测试时:发现三台机子的时间对不上,只有master是正确的,如图所示,定位问题为 我只在master上配置了时间,忘记在worker上配置时间同步了,因此需要在这两台机器上进行对应的时间同步操作。
三台都要配置,现在master上,追加到文件末尾就行,我之前实在/etc/profile中添加的
source 文件才会生效,不然会找不到命令 source /etc/profile
这个配置好文件其实就可以创建了,三台都要配置i 之前修改 core-site.xml文件时,我们有一个hadoop.tmp.dir,要建立好这个文件夹,三台机器都要建立。
会出现如下错误,因此需要格式化一下,保存快照
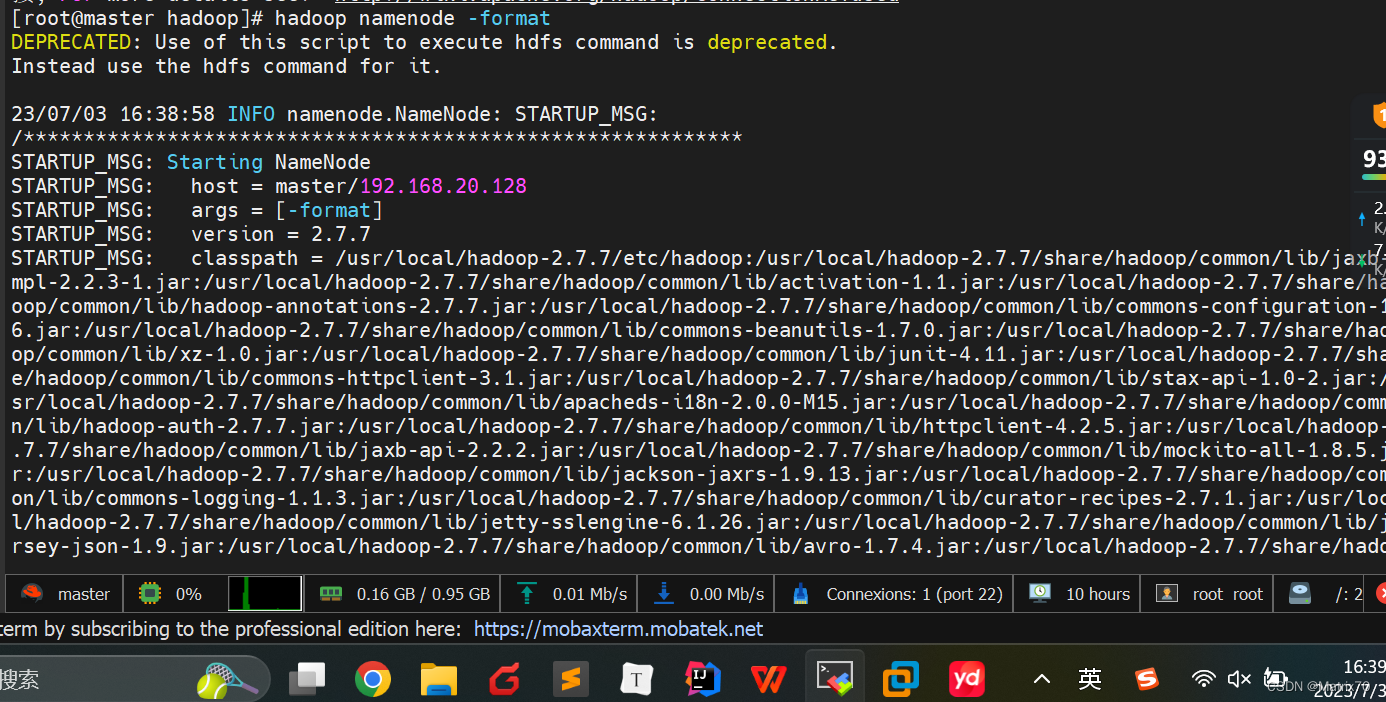
启动hadoop集群以此检验我们的配置是否正确 格式化文件系统 在格式化之前最好给三台机子做一个快照,保存一次,因为格式化只能执行一次。在master节点上执行如下命令 hadoop namenode -format如果看到如下信息,则表示格式化成功,出现其他例如exception及error则表示出现异常
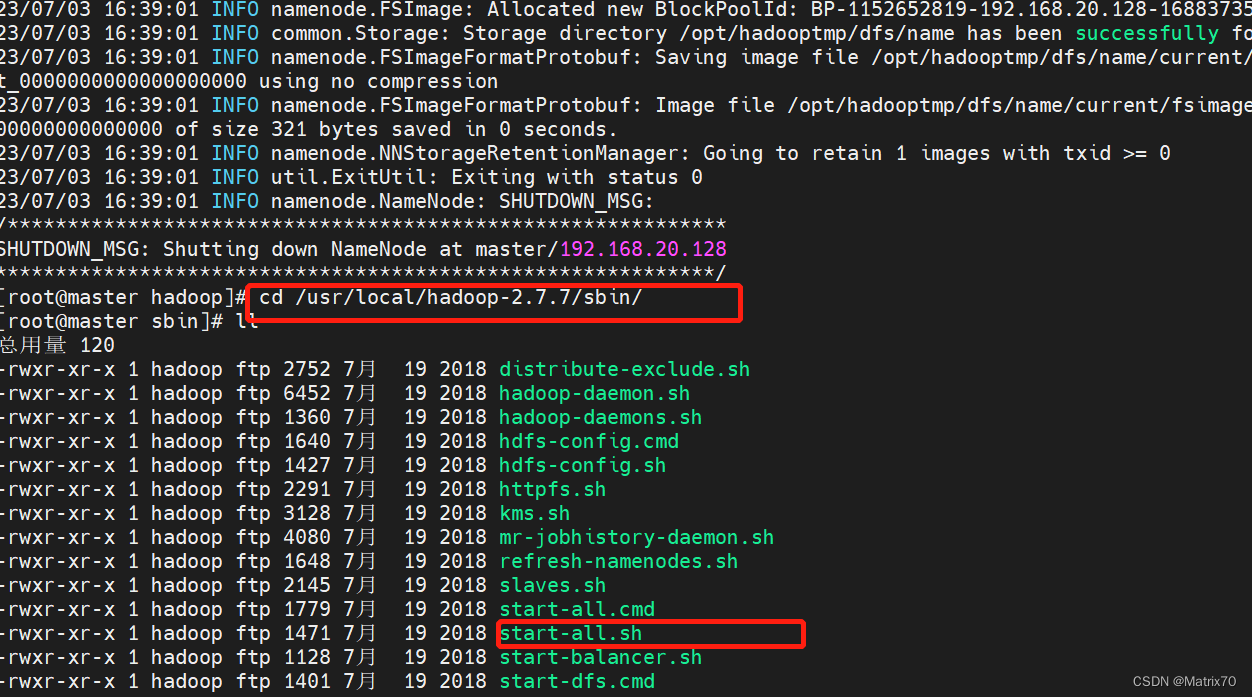
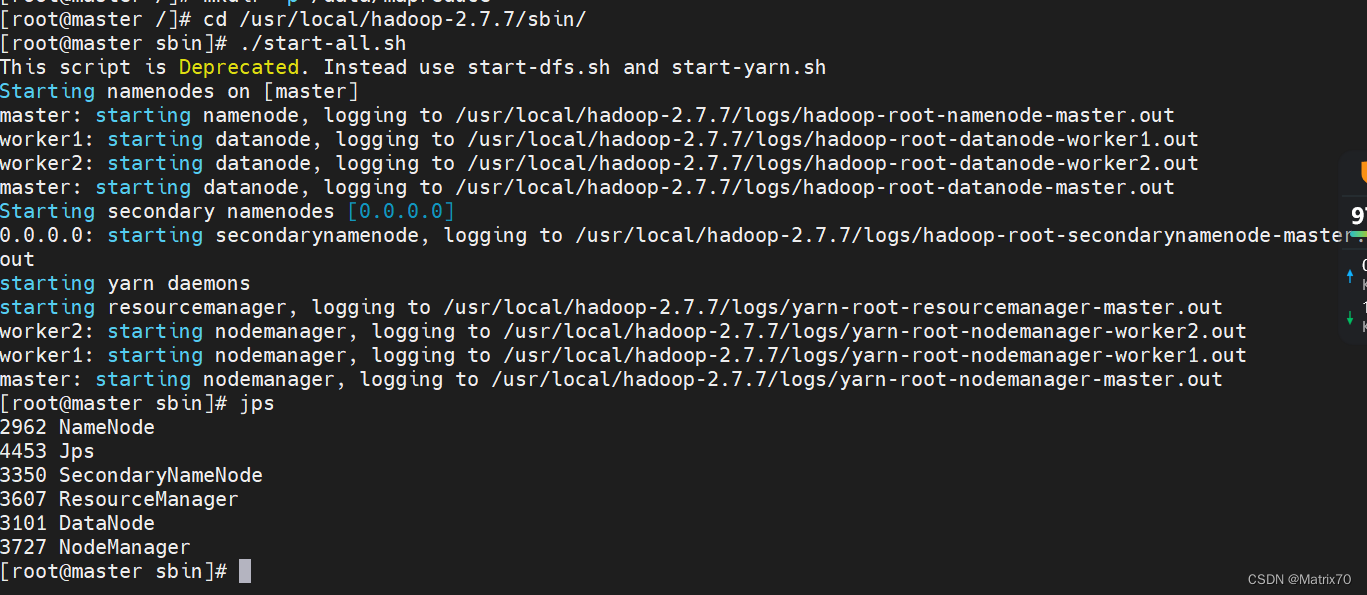
1、只需要在master上面启动,进入如下sbin目录下 cd /usr/local/hadoop-2.7.7/sbin/随后执行start-all.sh,启动所有,包括了start-dfs.sh及start-yarn.sh,启动完毕 ./start-all.sh
启动结果如下:
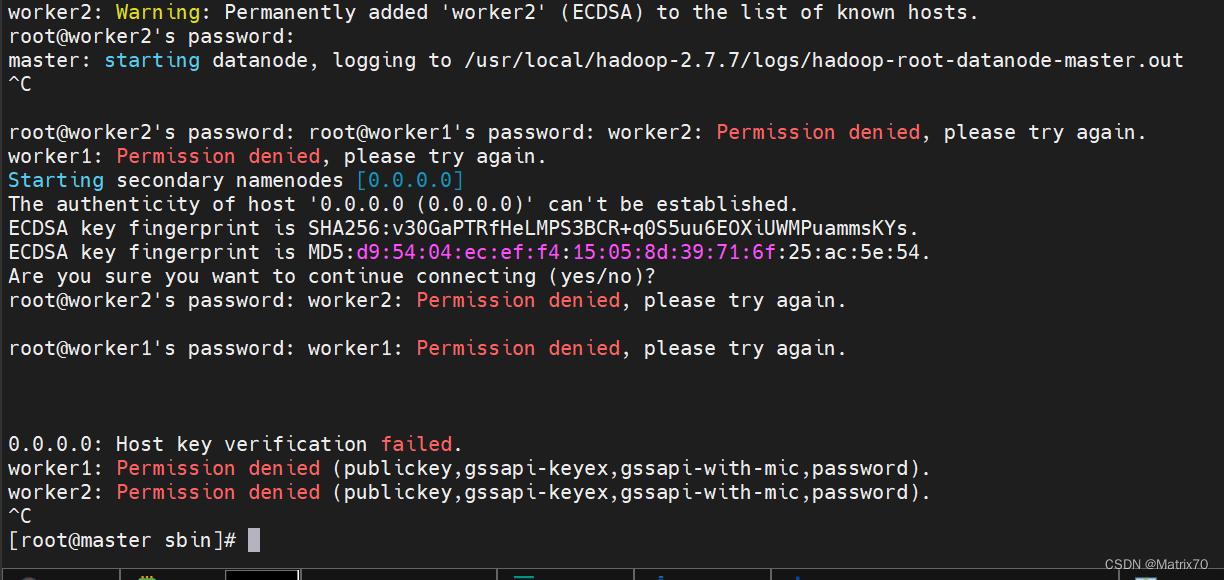
以上我们就启动完毕了,注意我使用root用户启动的。 2、另一种启动方式分布启动,分两步 1)第一步启动文件系统start-dfs.sh 如果报错,查看日志logs,并检查响应配置文件hdfs-site.xml及core-site.xml. 2)第二步启动yarn计算框架 如果报错,查看logs,并检查对应配置文件yarn-site.xml及mapred-site.xml。 启动集群可能会遇到ssh权限问题到这一步,能使得启动出现问题的无非是权限问题,另一个就是配置文件的问题,排除配置文件问题,那就是权限问题,搞定了,后面就可以了 报错如下: root@worker2's password: worker2: Permission denied, please try again. root@worker1's password: worker1: Permission denied, please try again. 0.0.0.0: Host key verification failed. worker1: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password). worker2: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
解决: 权限问题,我的解决方法比较暴力,我把root用户,hadoop用户的三台机子的ssh免密都配置了一遍,ssh公钥忘记追加到authorized_keys中了,将master节点的id_rsa.pub 文件内容追加到authorized_keys文件中。 关于ssh:如何使用id_rsa.pub密钥在远程服务器上附加authorized_keys | 码农家园
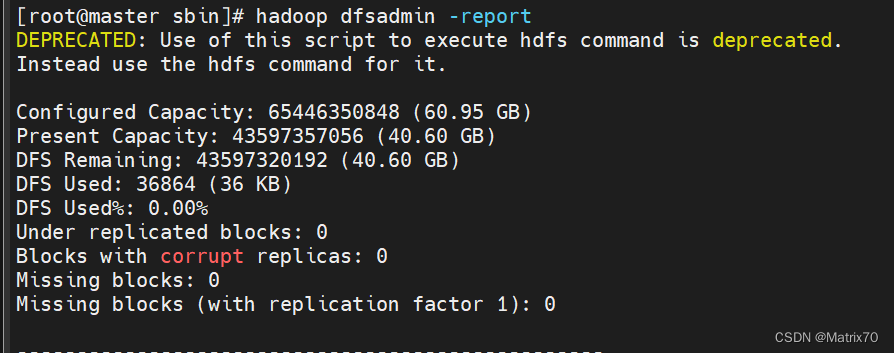
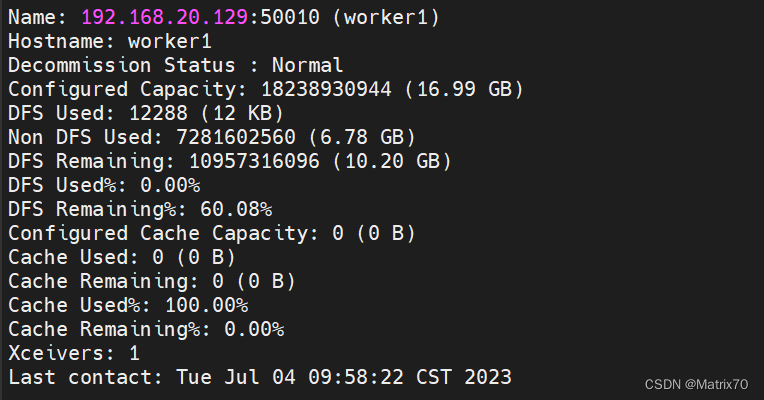
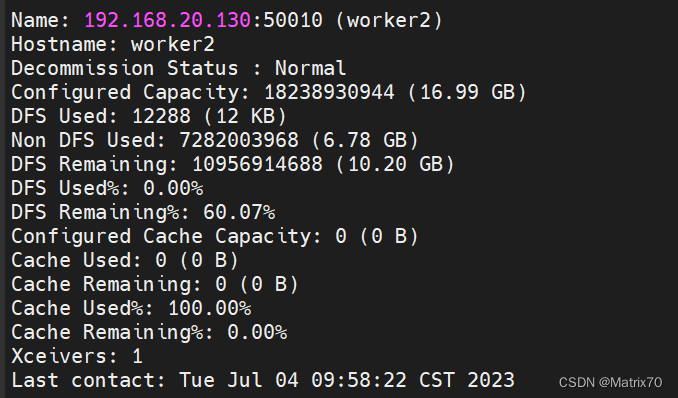
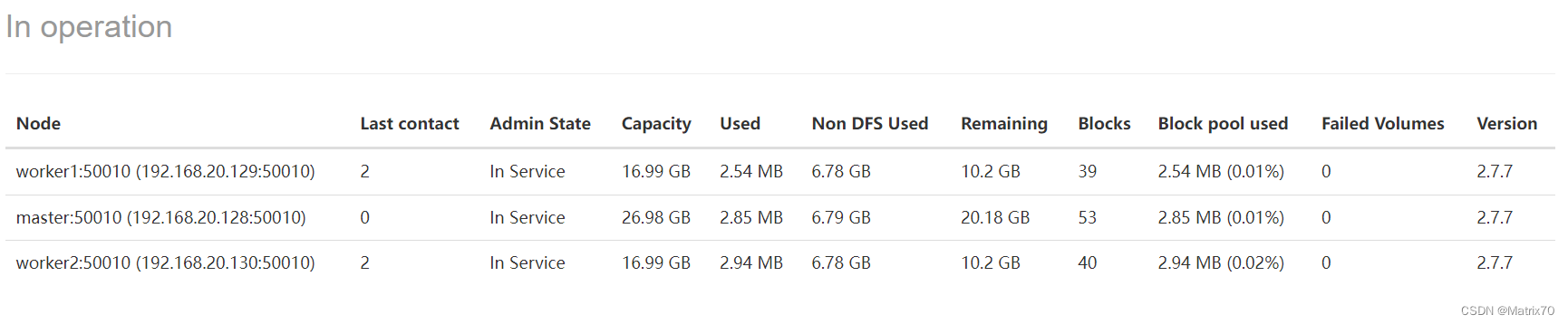
#使用终端查看集群状态 hadoop dfsadmin -report
jps查看进程 namenode,datanode, RM ,SN,NM,出现代表启动成功,安装一大半了。
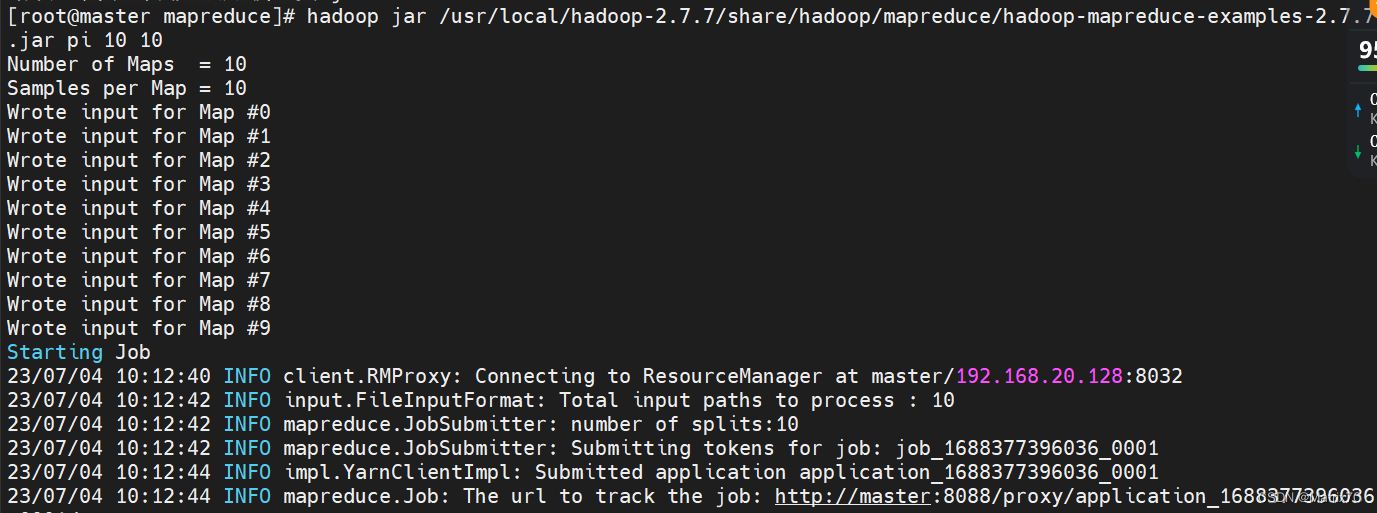
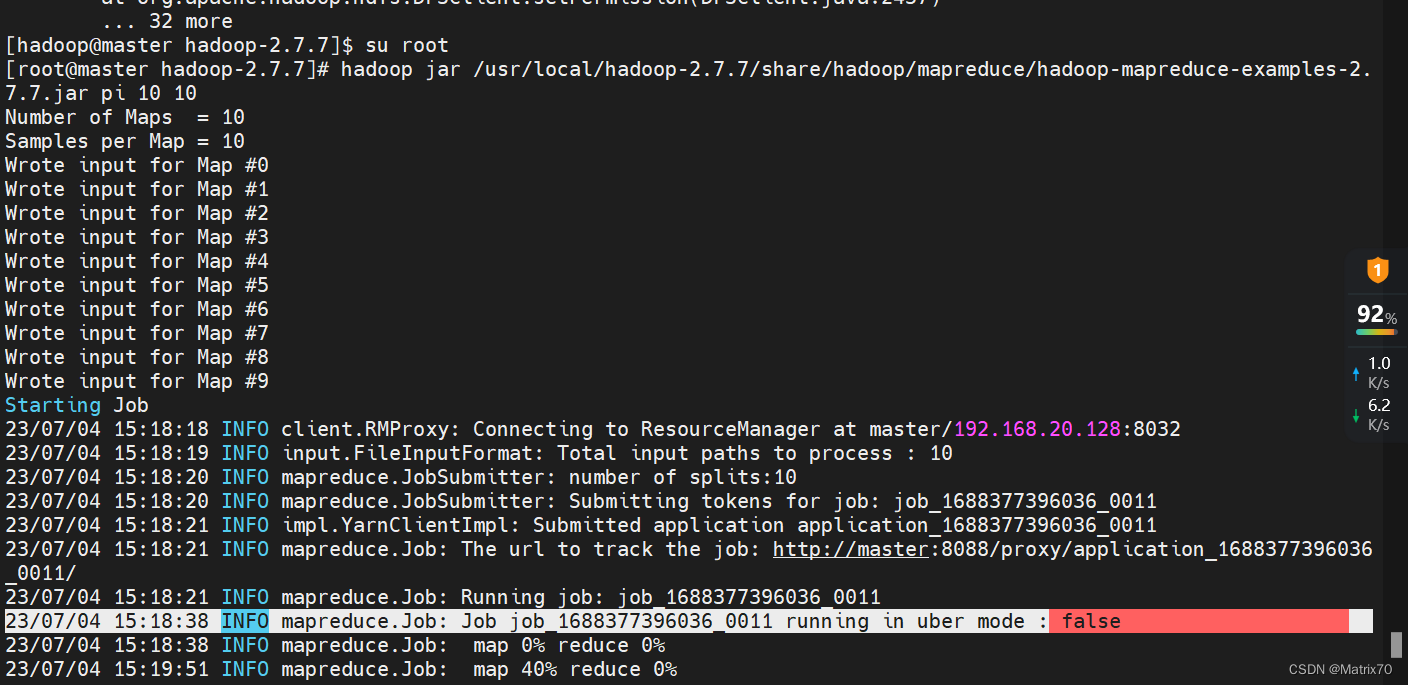
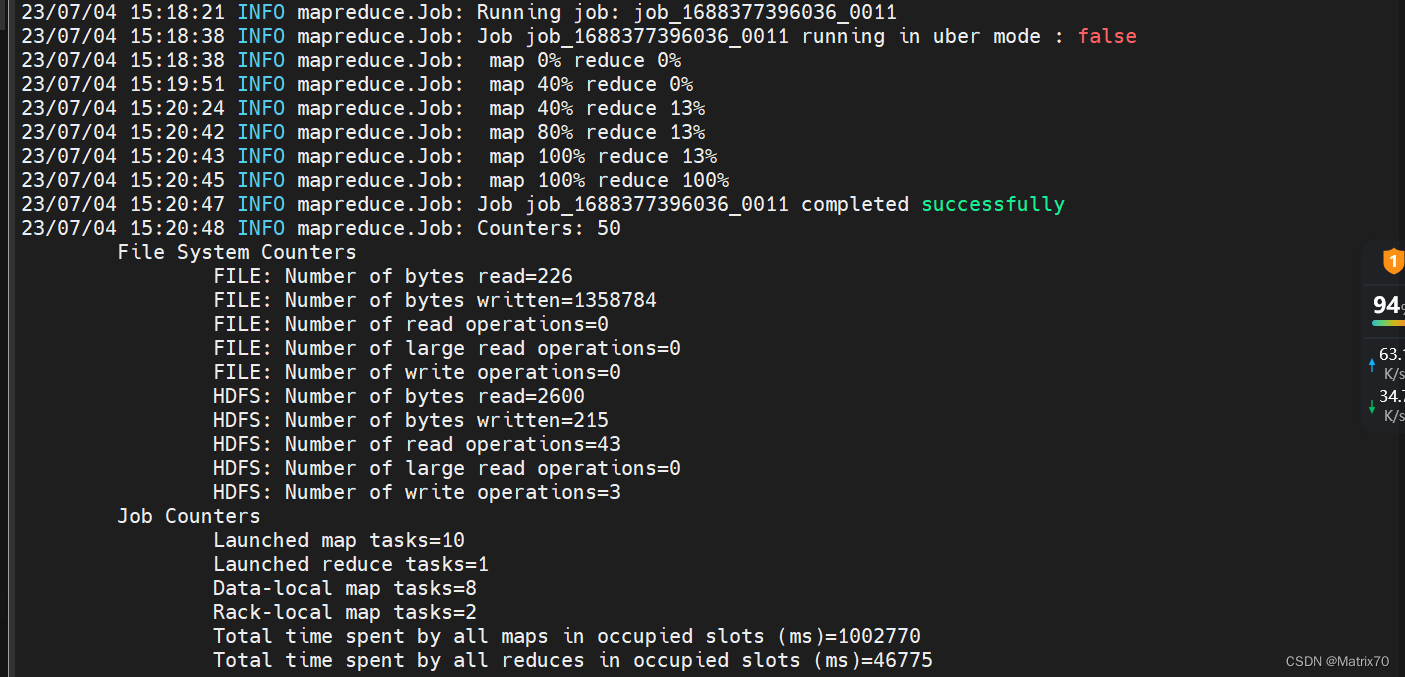
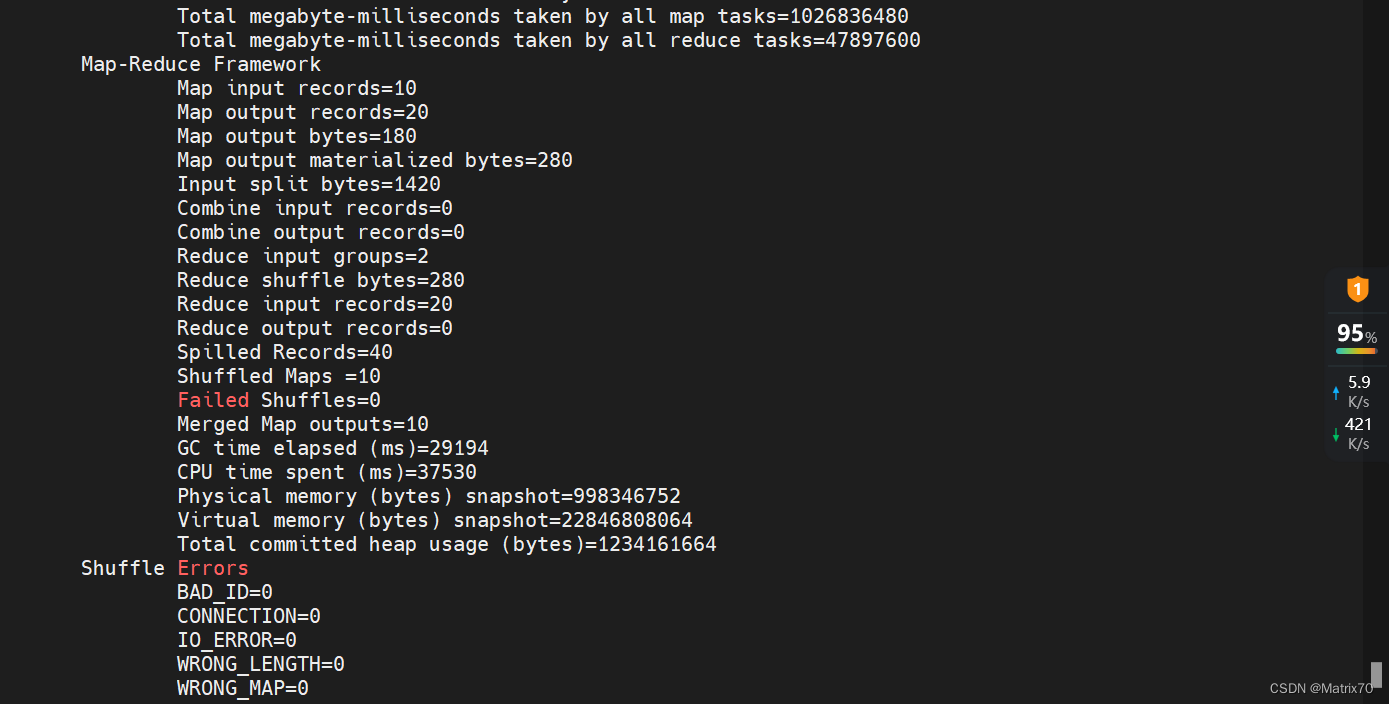
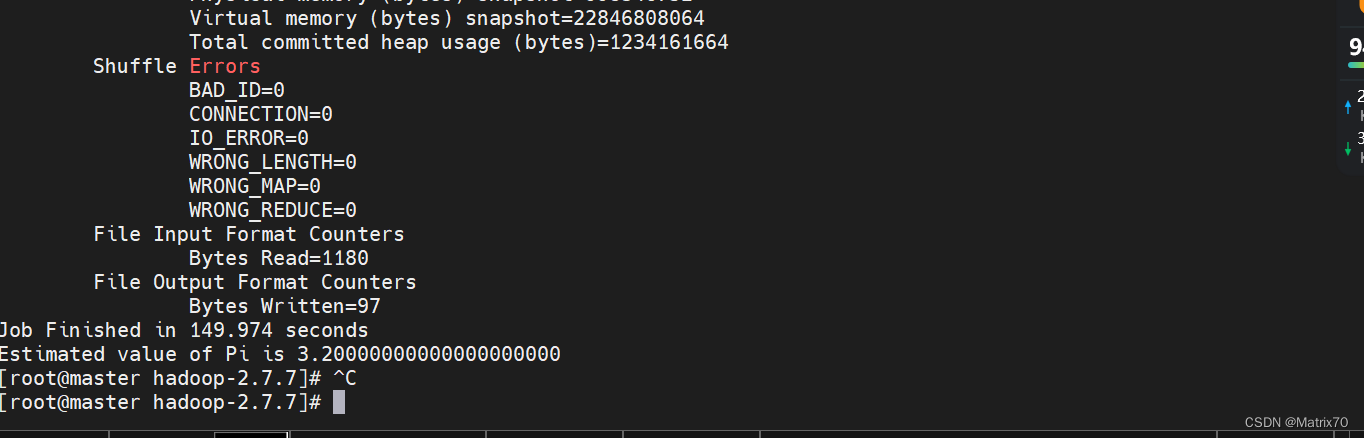
蒙特卡洛方法 进入到 /usr/local/hadoop-2.7.7/share/hadoop/mapreduce看看jar包是否存在,再执行下面语句: hadoop jar /usr/local/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar pi 10 10出现下面的情况,说明我们的hadoop安装成功了
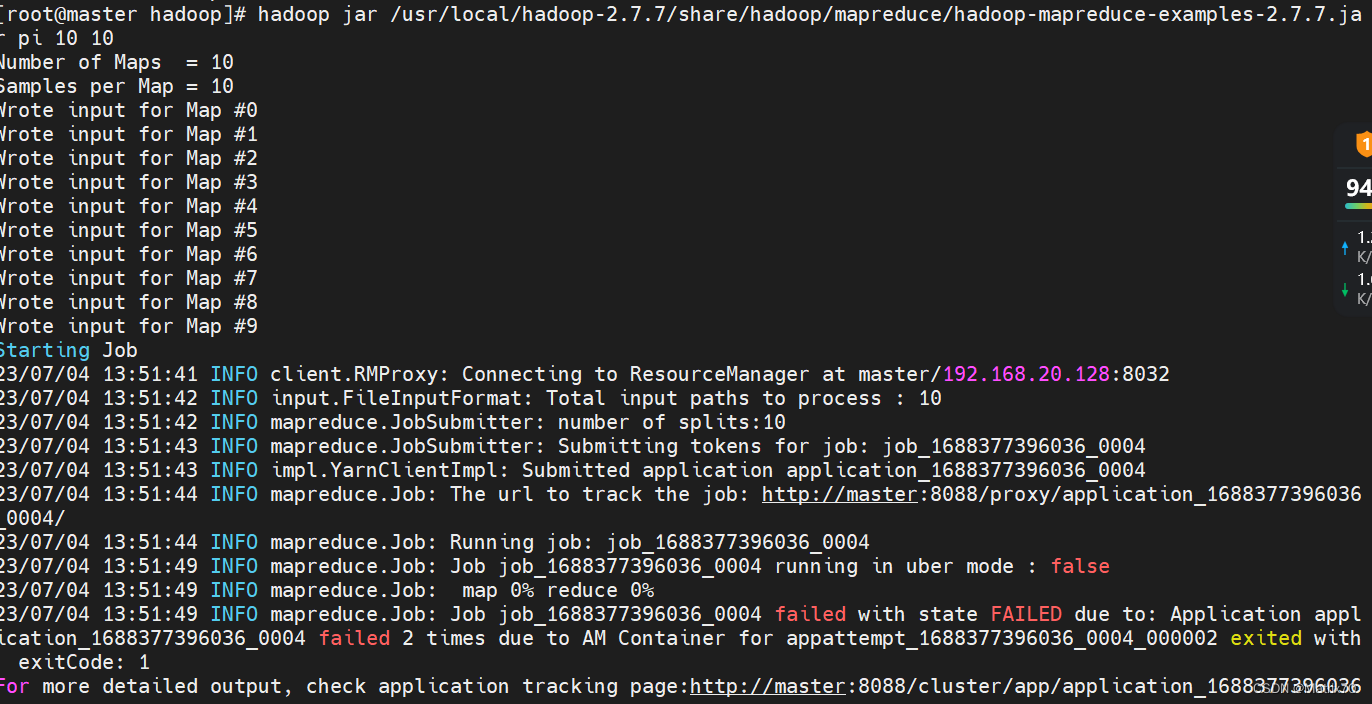
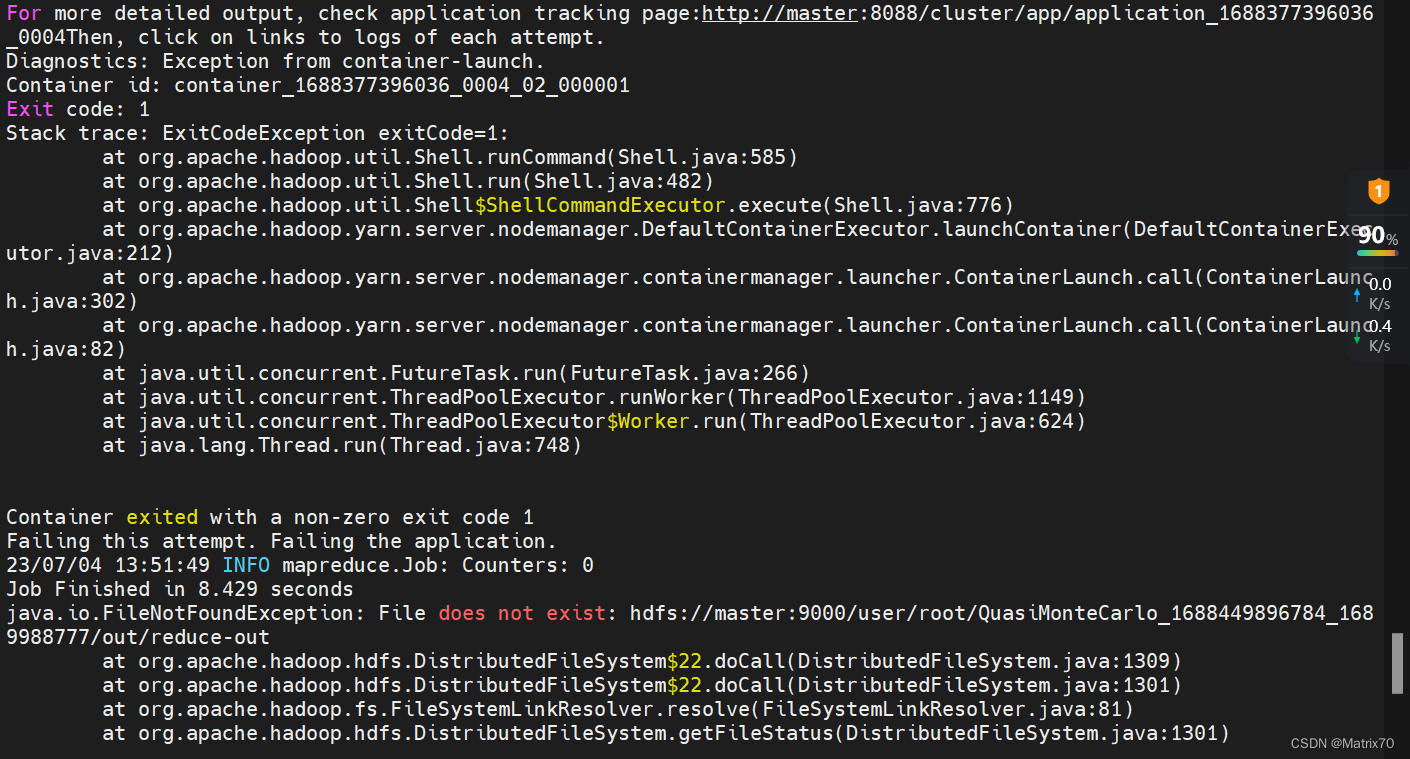
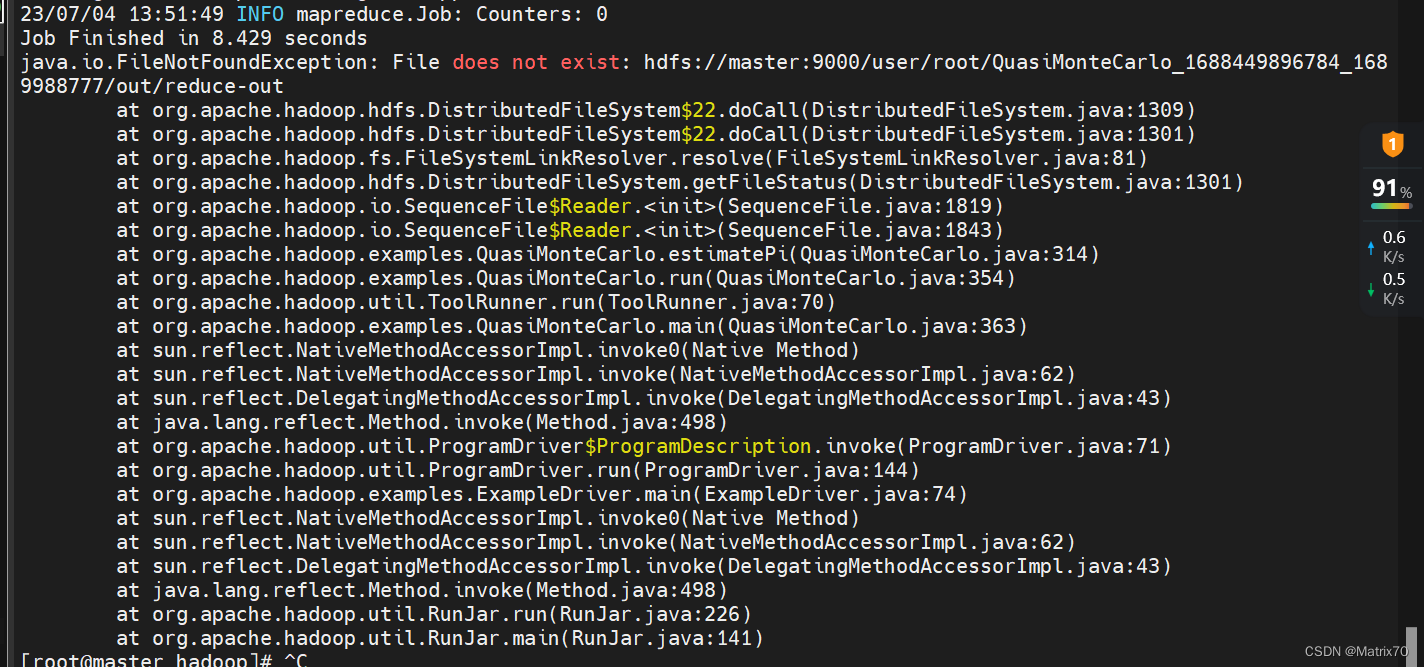
搭建好Hadoop环境后,执行命令测试MapReduce环境出现如下错误: Hadoop之hadoop-mapreduce-examples测试执行及报错处理_恒悦sunsite的博客-CSDN博客 hadoop :java.io.FileNotFoundException: File does not exist:_wx5caecf2ed0645的技术博客_51CTO博客 java.io.FileNotFoundException: File does not exist: hdfs://xxx_FishMAN_已存在的博客-CSDN博客 hadoop jar /usr/local/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar pi 10 10 ......java.io.FileNotFoundException: File does not exist: hdfs://master:9000/user/root/QuasiMonteCarlo_1688449896784_1689988777/out/reduce-out at org.apache.hadoop.hdfs.DistributedFileSystem$22.doCall(DistributedFileSystem.java:1301) at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81) ......
问题分析:看这条, java.io.FileNotFoundException: File does not exist: hdfs://master:9000/user/root/QuasiMonteCarlo_1688449896784_1689988777/out/reduce-out 说是找不到文件,什么文件?怎么创建?再查资料,可能是找不到主类?并不是,再查,是否是hadoop文件的配置和项目代码的引用配置文件是否冲突了?并没有, 可能是java环境配置问题,还有一个可能是执行语句写错了,检查配置文件,没啥问题啊!! 解决:我切换到hadoop用户,再切换回来root用户,在执行就行了?!!!!! 这是什么鬼?
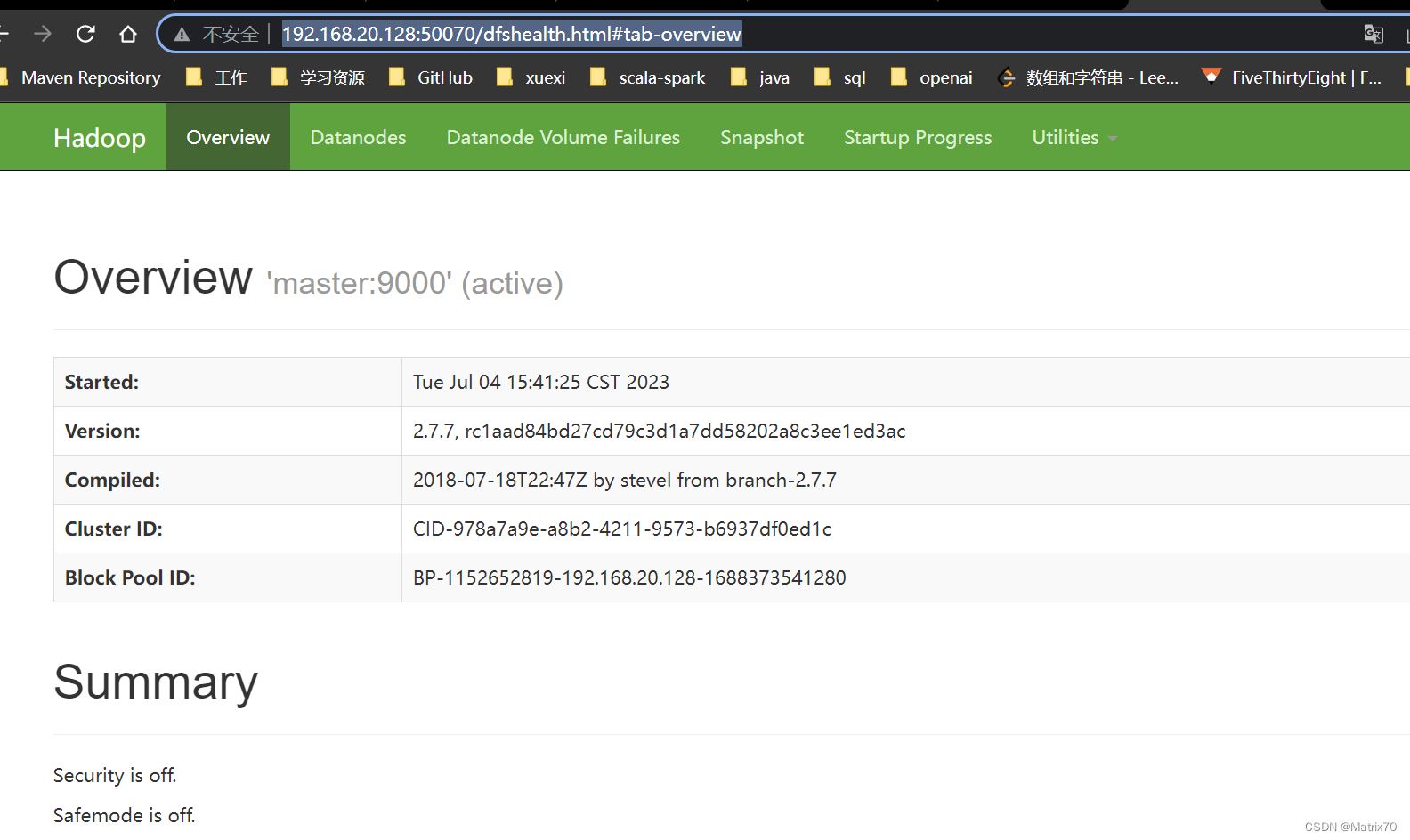
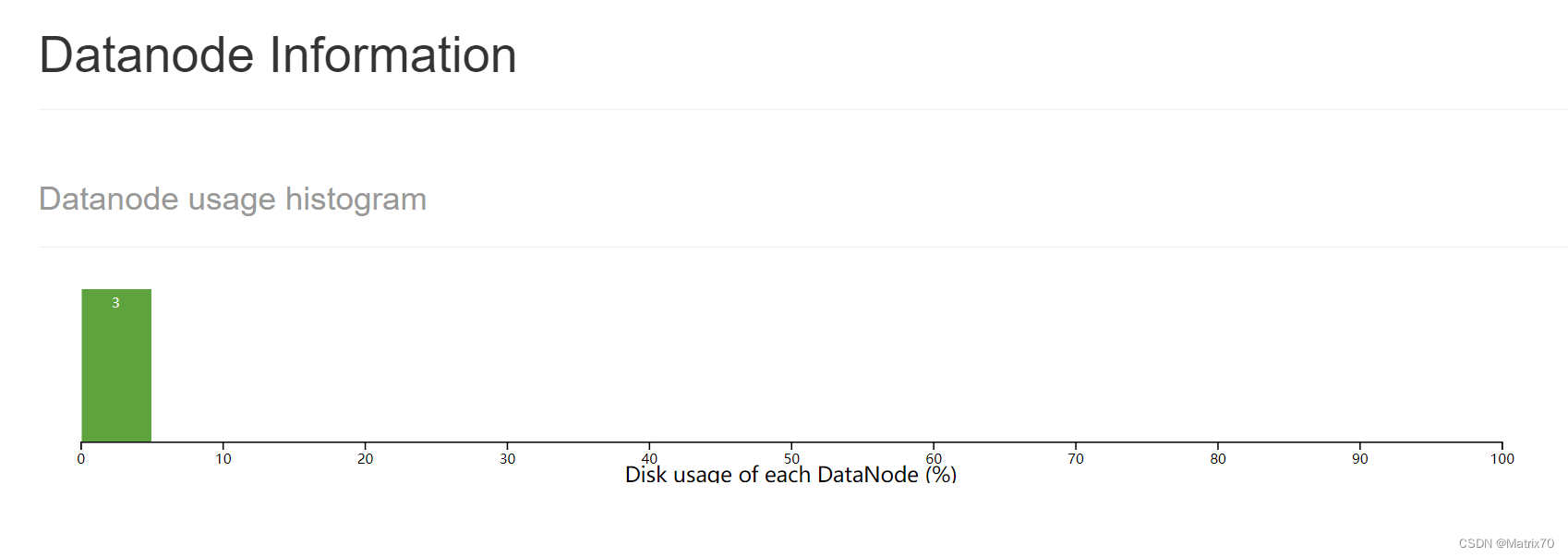
shit! 消耗好几个小时。。。。什么鬼。 Hadoop集群的状态查看我用的是谷歌浏览器,直接地址栏键入50070端口的链接 :http://master:50070/ 以此查看DataNode与NameNode是否正常。
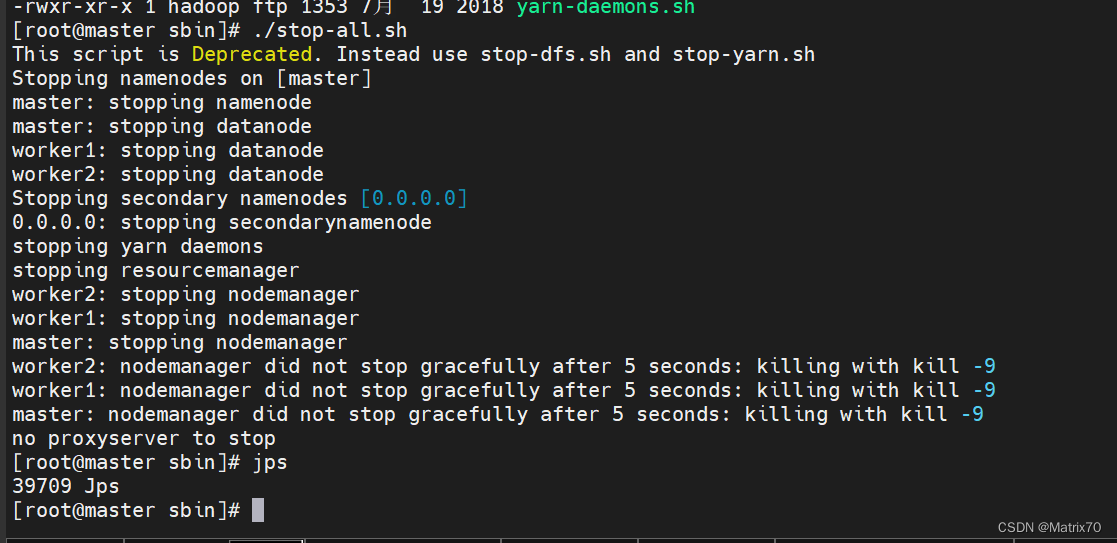
普通停止和分布式停止 1、普通停止: 在sbin目录下执行 ./stop-all.sh
2、分布停止hadoop集群: 在sbin目录下执行 ./stop-dfs.sh 停止文件系统 ./stop-yarn.sh 停止yarn调度 |







 vi
vi 

 加入下面的内容,如下图
加入下面的内容,如下图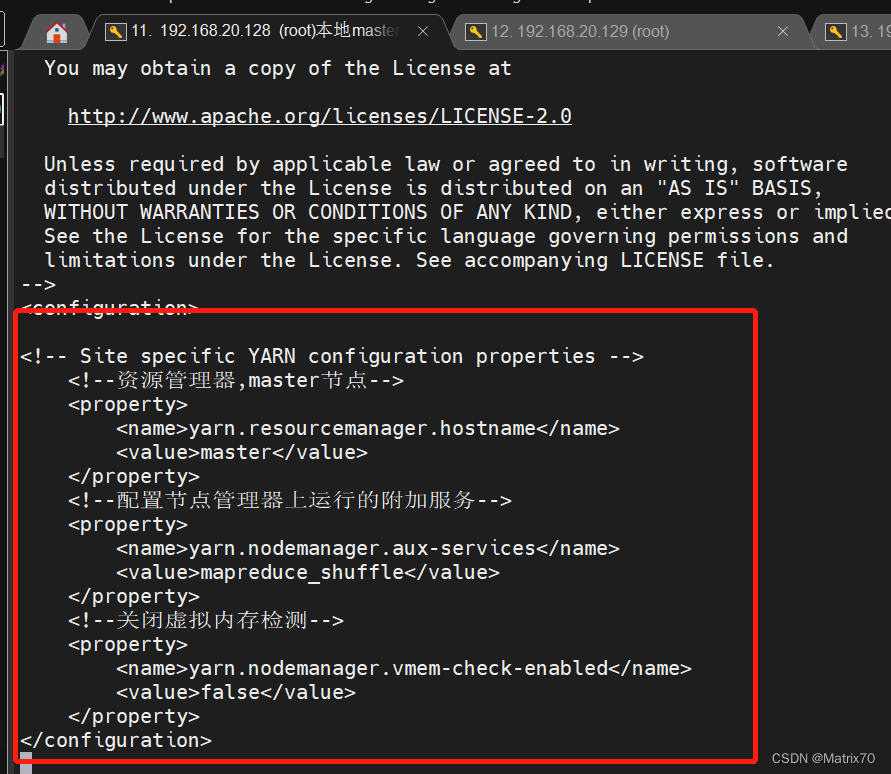






【本文地址】
今日新闻 |
推荐新闻 |