【Linux】线程互斥 |
您所在的位置:网站首页 › linux查看目录有多大 › 【Linux】线程互斥 |
【Linux】线程互斥
|
文章目录
抢票系统互斥量mutex互斥量接口函数初始化互斥量:pthread_mutex_init销毁互斥量:pthread_mutex_destroy互斥量加锁-pthread_mutex_lock互斥量解锁-pthread_mutex_unlock
加锁版抢票系统注意事项
互斥量实现原理探究注意事项:
回忆 临界资源: 多线程执行流共享的资源叫做临界资源临界区: 每个线程内部,访问临界资源的代码,就叫做临界区互斥: 任何时刻,互斥保证有且只有一个执行流进入临界区,访问临界资源,通常对临界资源起保护作用原子性: 不会被任何调度机制打断的操作,该操作只有两态,要么完成,要么未完成例子: 临界资源和临界区 进程之间如果要进行通信我们需要先创建第三方资源,让不同的进程看到同一份资源,这份第三方资源可以由操作系统中的不同模块提供,所以进程间通信的方式有很多种 进程间通信中的第三方资源就叫做临界资源,访问第三方资源的代码就叫做临界区 因为多线程的大部分资源都是共享的,线程之间进行通信不需要费那么大的劲去创建第三方资源 例子:我们定义一个全局变量count,新线程每隔1s执行count++操作,主线程每隔1s获取count变量的值进行打印 #include #include #include int count = 0; void* Routine(void* arg) { while (1) { count++; sleep(1); } } int main() { pthread_t tid; pthread_create(&tid, NULL, Routine, NULL); while (1) { printf("count: %d\n", count); sleep(1); } pthread_join(tid, NULL); return 0; }此时我们相当于实现了主线程和新线程之间的通信,其中全局变量count就叫做临界资源,因为它被多个执行流共享 而访问临界资源count的位置就是临界区:主线程中的printf和新线程中count++就叫做临界区 
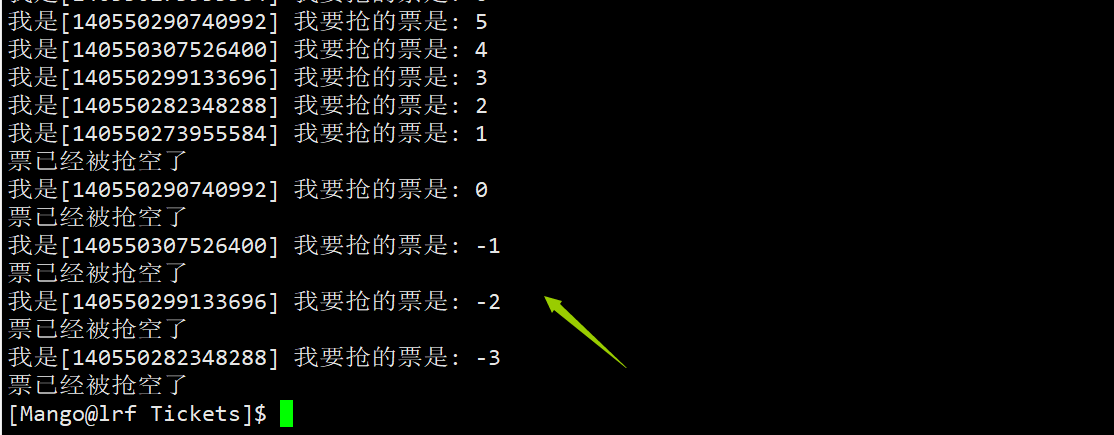
关于互斥和原子性 1)在多线程情况下,如果这多个执行流都自顾自的对临界资源进行操作,那么此时就可能导致数据不一致的问题解决该问题的方案就叫做互斥,互斥的作用就是,保证在任何时候有且只有一个执行流进入临界区对临界资源进行访问 2)原子性指的是不可被分割的操作,该操作不会被任何调度机制打断,该操作只有两态,要么完成,要么未完成 抢票系统我们模拟实现一个抢票系统:定义一个类Ticket, 主线程创建5个线程进行抢票,当票被抢完后这5个线程自动退出 class Ticket { public: Ticket():tickets(1000){} ~Ticket(){} bool GetTicket() { bool res = true; if(tickets>0) { usleep(1000); //1s == 1000ms 1ms = 1000us std::cout Ticket* t = (Ticket*)args; while(1) { if(!t->GetTicket()) { break;//没有票了才退出 } } } int main() { Ticket *t = new Ticket(); pthread_t tid[5]; //创建5个线程 for(int i = 0; i pthread_join(tid[i], nullptr); } return 0; }运行结果显然不符合我们的预期,因为其中出现了剩余票数为负数的情况
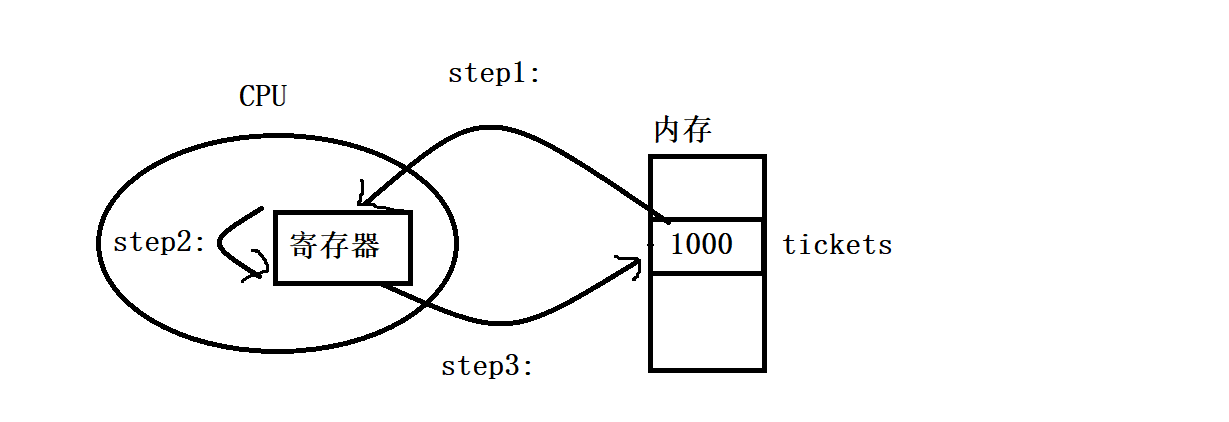
此时tickets变量就是临界资源,因为它被多个执行流同时访问,而判断tickets是否大于0, 打印剩余票数以及--tickets这些代码就是临界区,因为这些代码对临界资源进行了访问 出现负数的原因: if语句判断条件为真以后,代码可以并发的切换到其他线程,然后没有break usleep用于模拟漫长业务的过程,在这个漫长的业务过程中,可能有很多个线程会进入该代码段 --ticket(ticket--)操作本身就不是一个原子操作 问:为什么--ticket(ticket--)不是原子的? 对一个变量进行--,实际需要进行以下三个步骤 load :将共享变量ticket从内存加载到寄存器中update : 更新寄存器里面的值,然后执行-1操作store :将新值从寄存器写回共享变量ticket的内存地址
对应的汇编代码:
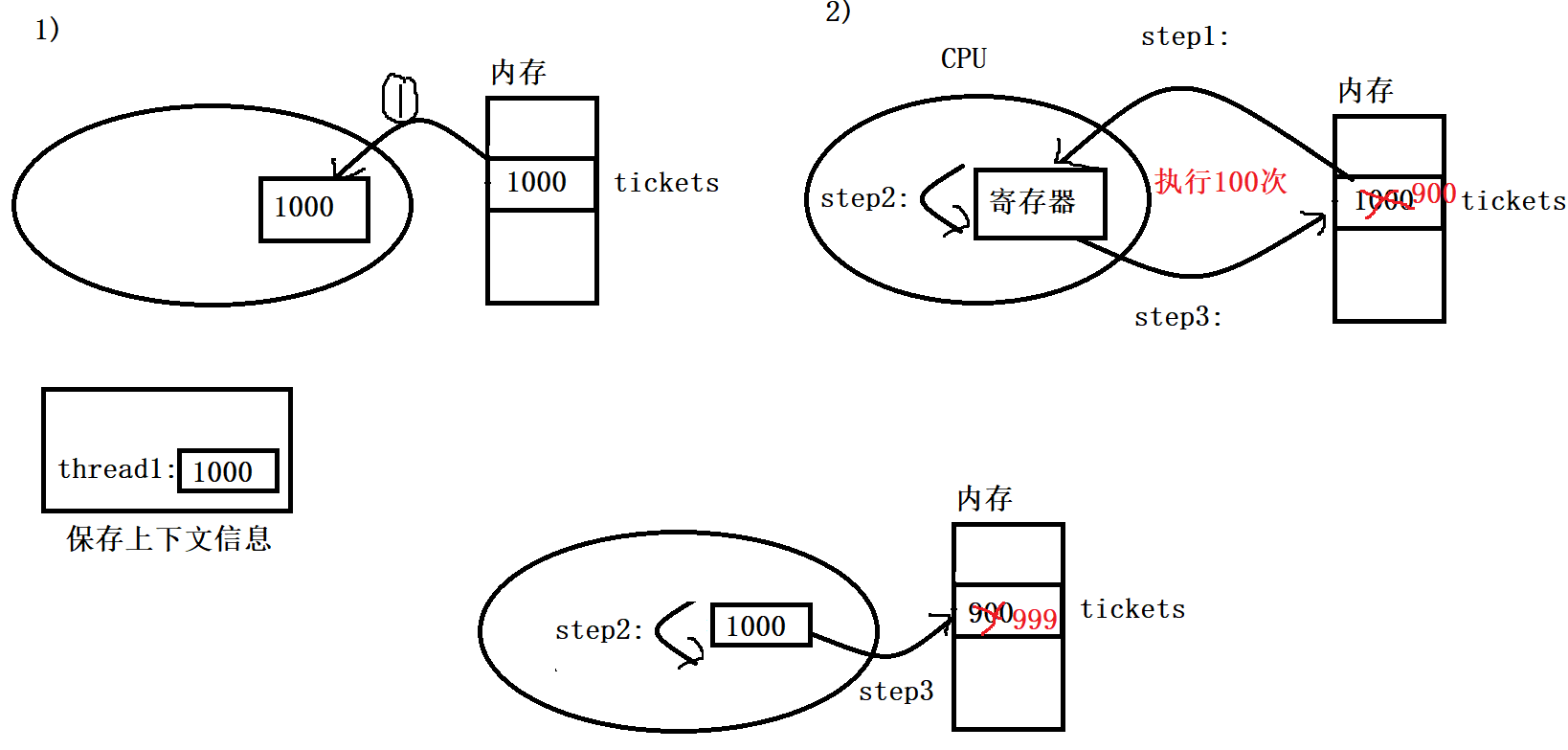
因为–过程需要3步才能完成,所以会存在下述的情况: 1)当thread1刚把tickets的值读进CPU就被切走了,也就是从CPU上剥离下来,假设此时thread1读取到的值就是1000,而当thread1被切走时,寄存器中的1000叫做thread1的上下文信息,因此需要被保存起来,之后thread1就被挂起了 2)假设此时thread2被调度了,由于thread1只进行了--操作的第一步,因此thread2此时看到tickets的值还是1000,而系统给thread2的时间片可能较多,导致thread2一次性执行了100次--才被切走,最终tickets由1000减到了900 3)此时系统再把thread1恢复上来,恢复的本质就是继续执行thread1的代码,并且要将thread1曾经的硬件上下文信息恢复出来,此时寄存器当中的值是恢复出来的1000,然后thread1继续执行--操作的第二步和第三步,最终将999写回内存
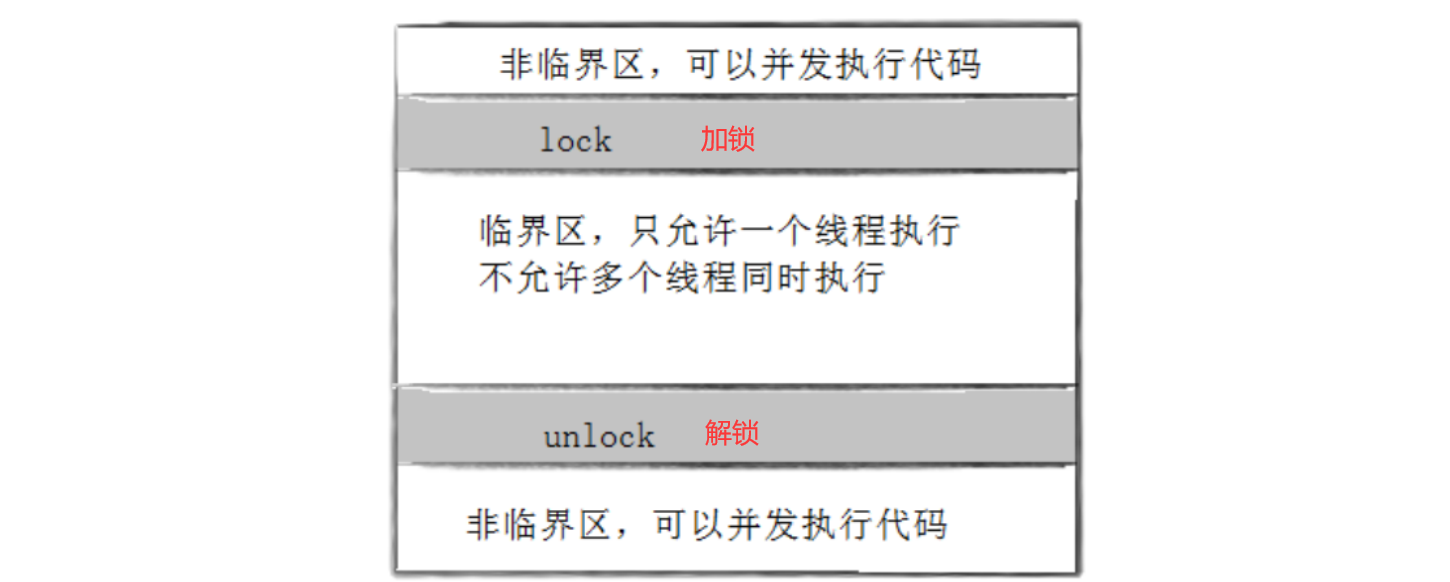
在上述过程中,thread1抢了1张票,thread2抢了100张票,而此时剩余的票数却是999,也就相当于多出了100张票 因此对一个变量进行--操作并不是原子的,虽然--tickets看起来就是一行代码,但这行代码被编译器编译后本质上是三行汇编,相反,对一个变量进行++也需要对应的三个步骤,即++操作也不是原子操作 互斥量mutex大部分情况,线程使用的数据都是局部变量,变量的地址空间在线程栈空间内,这种情况变量归属单个线程 (在线程自己的栈结构当中),其他线程无法获得这种变量 所以问:上述的bool变量res是否是被所有线程共享的呢? 不是的!,虽然每个线程都会执行GetTicket函数,但是res是局部变量,在栈上开辟!->被线程私有 在线程自己的线程栈中但有时候,很多变量都需要在线程间共享,这样的变量成为共享变量,可以通过数据的共享,完成线程之间的交互 多个线程并发的操作共享变量,就会带来一些问题 要解决上述抢票系统的问题,需要做到三点: 代码必须有互斥行为:当代码进入临界区执行时,不允许其他线程进入该临界区如果多个线程同时要求执行临界区的代码,并且此时临界区没有线程在执行,那么只能允许一个线程进入该临界区如果线程不在临界区中执行,那么该线程不能阻止其他线程进入临界区要做到这三点,本质上就是需要一把锁,Linux上提供的这把锁叫互斥量 具体过程:
初始化互斥量的函数为:pthread_mutex_init #include int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr);参数说明 第一个参数:需要初始化的互斥量 第二个参数:初始化互斥量的属性,一般设置为空 返回值说明 初始化成功返回0,失败返回错误码 注意:调用pthread_mutex_init函数初始化互斥量叫做动态分配, 我们还可以用下面静态分配的方式初始化互斥量 pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER; 销毁互斥量:pthread_mutex_destroy销毁互斥量的函数叫做pthread_mutex_destroy #include int pthread_mutex_destroy(pthread_mutex_t *mutex);参数说明 mutex:需要销毁的互斥量 返回值说明 互斥量销毁成功返回0,失败返回错误码 注意事项: 使用PTHREAD_MUTEX_INITIALIZER初始化的互斥量不需要销毁不要销毁一个已经加锁的互斥量已经销毁的互斥量,要确保后面不会有线程再尝试加锁 互斥量加锁-pthread_mutex_lock互斥量加锁的函数叫做pthread_mutex_lock #include int pthread_mutex_lock(pthread_mutex_t *mutex);参数说明 mutex:需要加锁的互斥量 返回值说明 互斥量加锁成功返回0,失败返回错误码 注意事项: 调用pthread_mutex_lock时,可能会遇到以下情况 1)互斥量处于未锁状态,该函数会将互斥量锁定,同时成功返回 2)发起函数调用时,其他线程已经锁定互斥量,或者存在其他线程同时申请互斥量,但没有竞争到互斥量,那么pthread_mutex_lock调用会陷入阻塞(执行流被挂起),等待互斥量解锁 互斥量解锁-pthread_mutex_unlock互斥量解锁的函数叫做pthread_mutex_unlock #include int pthread_mutex_unlock(pthread_mutex_t *mutex);参数说明 mutex:需要解锁的互斥量的地址 返回值说明 解锁成功返回0,失败返回错误码 加锁版抢票系统我们在上述的抢票系统中引入互斥量, 每一个线程要进入临界区之前都必须先申请锁,只有申请到锁的线程才可以进入临界区对临界资源进行访问,并且当线程出临界区的时候需要释放锁,这样才能让其余要进入临界区的线程继续竞争锁 #include #include #include #include #include #include #include #include class Ticket { public: Ticket():tickets(1000) { pthread_mutex_init(&mtx, nullptr);//初始化互斥锁 } ~Ticket() { pthread_mutex_destroy(&mtx);//销毁互斥锁 } bool GetTicket() { bool res = true; pthread_mutex_lock(&mtx); //加锁 //访问临界资源tickets if(tickets>0) { usleep(1000); //1s == 1000ms 1ms = 1000us std::cout Ticket* t = (Ticket*)args; while(1) { if(!t->GetTicket()) { break;//没有票了才退出 } } } int main() { Ticket *t = new Ticket(); pthread_t tid[5]; //创建5个线程 for(int i = 0; i pthread_join(tid[i], nullptr); } return 0; }此时在抢票过程中就不会出现票数剩余为负数的情况了
我们还可以使用C++内置的库函数进行加锁解锁: 引入:#include class Ticket { public: Ticket():tickets(1000){} ~Ticket(){} bool GetTicket() { bool res = true; mymtx.lock();//加锁 //访问临界资源tickets if(tickets>0) { usleep(1000); //1s == 1000ms 1ms = 1000us std::cout Ticket* t = (Ticket*)args; while(1) { if(!t->GetTicket()) { break;//没有票了才退出 } } } int main() { Ticket *t = new Ticket(); pthread_t tid[5]; //创建5个线程 for(int i = 0; i pthread_join(tid[i], nullptr); } return 0; }原生线程库的互斥锁和C++语言级别的互斥锁对比: pthread_mutex_t vs std::mutex pthread_mutex_t mtx; //原生线程库,系统级别 std::mutex mymtx; //C++ 语言级别语言级别的底层一定封装了系统级别的 注意事项 在大部分情况下,加锁本身都是有损于性能的事,它让多执行流由并行执行变为了串行执行,这几乎是不可避免的我们应该在合适的位置进行加锁和解锁,这样能尽可能减少加锁带来的性能开销成本进行临界资源的保护,是所有执行流都应该遵守的标准,这时程序员在编码时需要注意的 互斥量实现原理探究加锁后的原子性体现在哪里? 引入互斥量后,当一个线程申请到锁进入临界区时,在其他线程看来该线程只有两种状态,要么没有申请锁,要么锁已经释放了,因为只有这两种状态对其他线程才是有意义的 例如:当线程1进入临界区之后,在线程2~5看来,线程1要么没有申请锁,要么线程1已经将锁释放了,因为只有这两种状态对线程2~5才是有意义的,当线程2~5检测到其他状态时也就被阻塞了 此时对于线程2~5而言,它们就认为线程1的整个操作过程是原子的 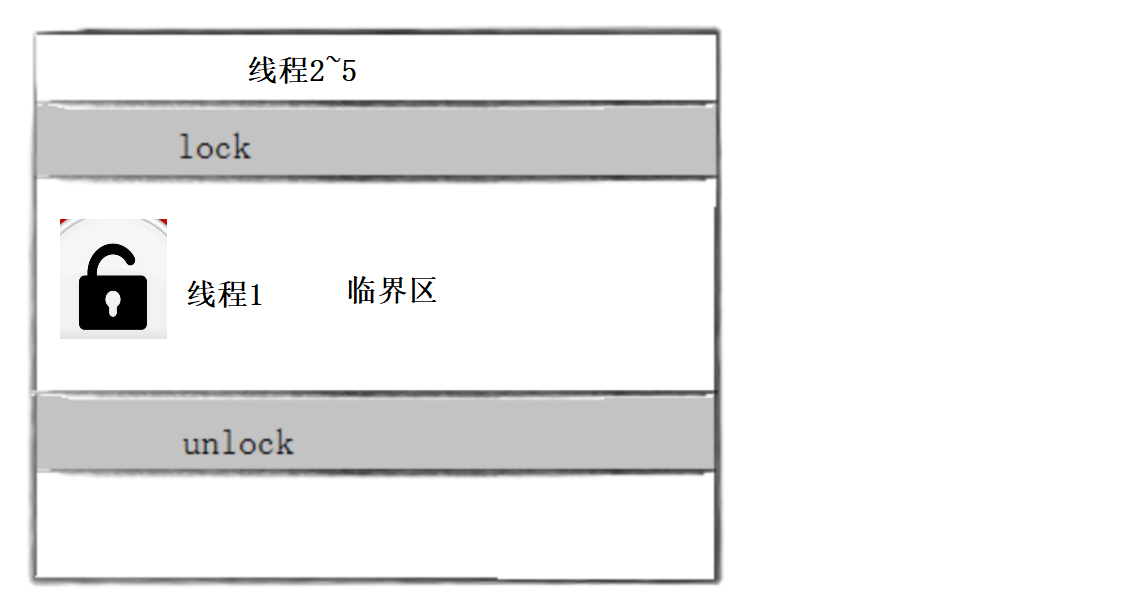
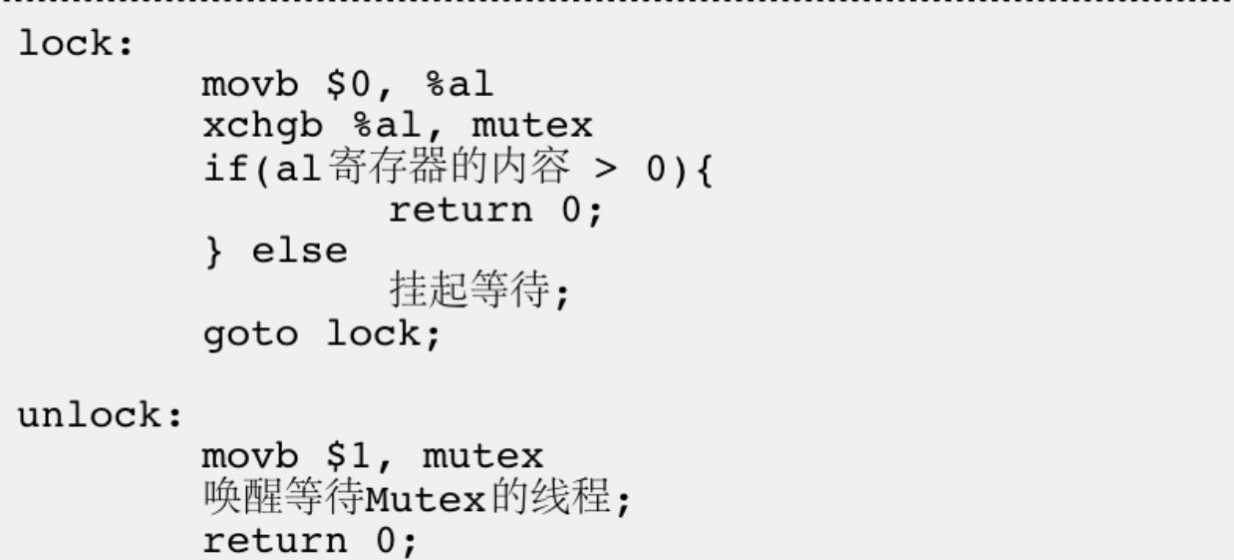
问题2:临界区内的线程可能进行线程切换吗 临界区内的线程完全可能进行线程切换,但即便该线程被切走,其他线程也无法进入临界区进行资源访问 因为此时该线程是拿着锁被切走的,锁没有被释放也就意味着其他线程无法申请到锁,也就无法进入临界区进行资源访问了 其他想进入该临界区进行资源访问的线程,必须等该线程执行完临界区的代码并释放锁之后,才能申请锁,申请到锁之后才能进入临界区 锁是否需要被保护 锁本质上也是临界资源 被多个执行流共享的资源叫做临界资源,访问临界资源的代码叫做临界区线程在进入临界区之前都必须竞争式的申请锁,因此锁也是被多个执行流共享的资源,所以锁本身就是临界资源既然锁是临界资源,那么锁就必须被保护起来,但锁本身就是用来保护临界资源的,那锁又由谁来保护的呢? 锁实际上是自己保护自己的,我们只需要加锁和解锁的过程是原子的,那么锁就是安全的 如何保证加锁和解锁是原子的 上面我们已经说明了--和++操作不是原子操作,可能会导致数据不一致问题为了实现互斥锁操作,大多数体系结构都提供了swap或exchange指令,该指令的作用就是把寄存器和内存单元的数据相交换由于只有一条指令,保证了原子性 **(一行代码是原子的:–>只有一行汇编代码的情况)**即使是多处理器平台,访问内存的总线周期也有先后,一个处理器上的交换指令执行时,另一个处理器的交换指令只能等待总线周期关于lock和unlock的伪代码:
当线程申请锁时,需要执行以下步骤: (假设当前mutex的初始值为1,al是一个寄存器) 先将al寄存器中的值清0 该动作可以被多个线程同时执行,因为每个线程都有自己的一组寄存器(保存上下文信息),执行该动作本质上是将自己的al寄存器清0 然后交换al寄存器和mutex中的值 ,(xchgb是体系结构提供的交换指令,该指令可以完成寄存器和内存单元之间数据的交换)最后判断al寄存器中的值是否大于0 若大于0则申请锁成功,此时就可以进入临界区访问对应的临界资源否则申请锁失败需要被挂起等待,直到锁被释放后再次竞争申请锁例如:此时内存中mutex的值为1,线程申请锁时先将al寄存器中的值清0,然后将al寄存器中的值与内存中mutex的值进行交换 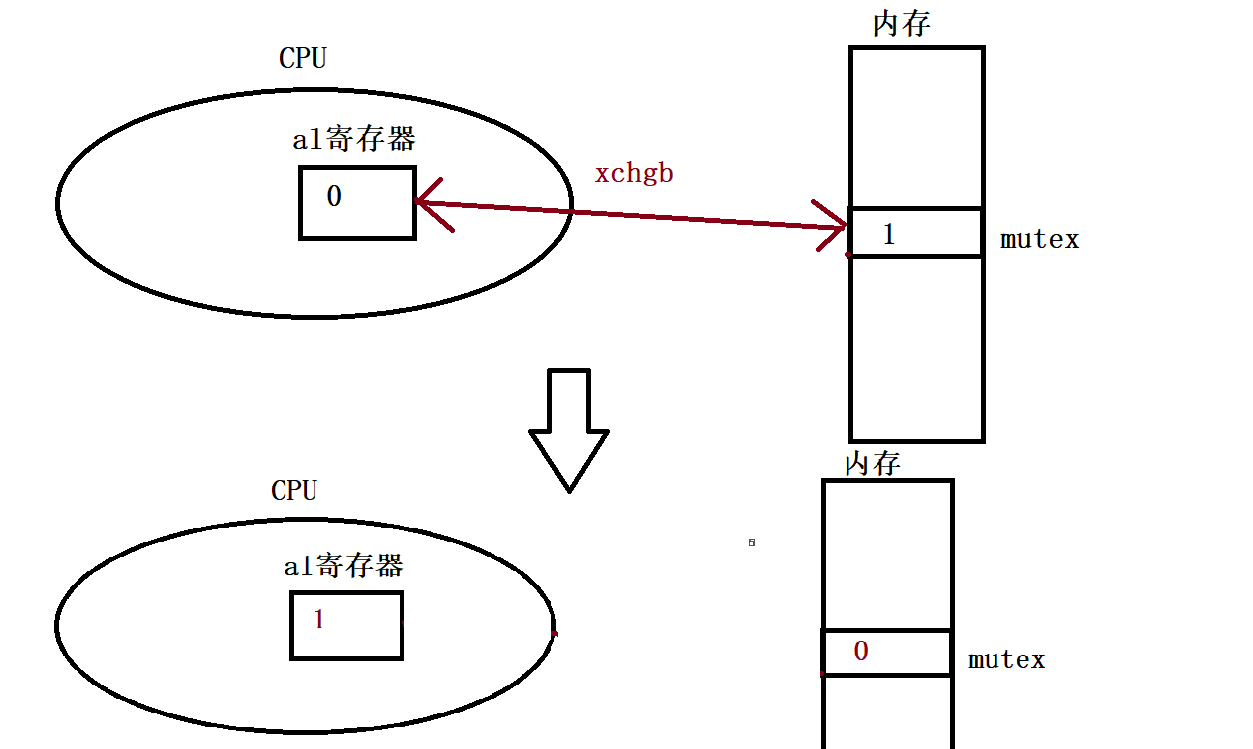
交换完成后检测该线程的al寄存器中的值为1,则该线程申请锁成功,可以进入临界区对临界资源进行访问 后面的线程若是再申请锁,与内存中的mutex交换得到的值就是0了,此时该线程申请锁失败,要被挂起等待,直到锁被释放后再次竞争申请锁 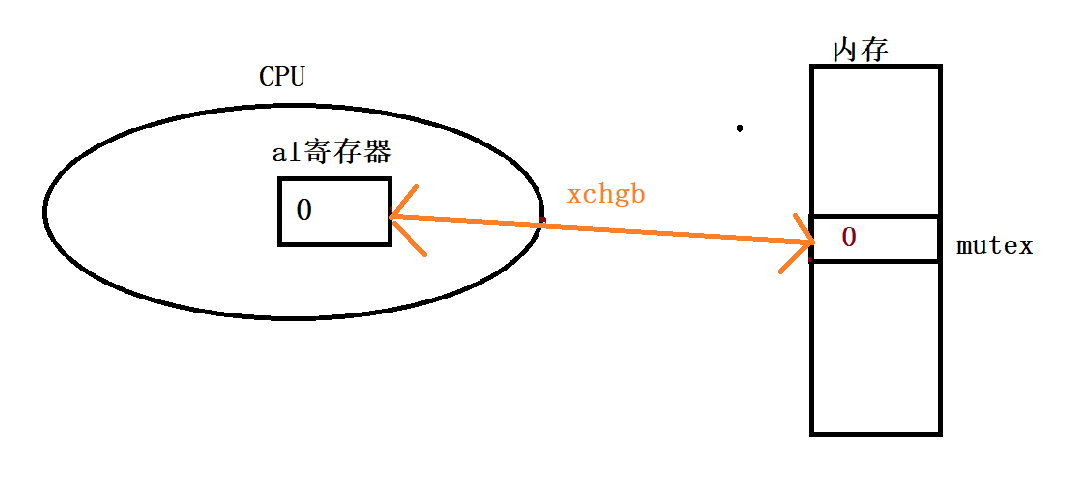
当线程释放锁的时候: 将内存中的mutex置回1 使得下一个申请锁的线程在执行交换指令后能够得到1,形象地说就是“将锁的钥匙放回去” 唤醒等待mutex的线程 唤醒这些因为申请锁失败而被挂起的线程,让它们继续竞争申请锁 注意事项: 在申请锁时本质上就是哪一个线程先执行了交换指令,那么该线程就申请锁成功,因为此时该线程的al寄存器中的值就是1了 而交换指令就只是一条汇编指令->是原子的,一个线程要么执行了交换指令,要么没有执行交换指令,所以申请锁的过程是原子的 在线程释放锁时没有将当前线程al寄存器中的值清0,这不会造成影响 因为每次线程在申请锁时都会先将自己al寄存器中的值清0,再执行交换指令 **CPU内的寄存器不是被所有的线程共享的,**每个线程都有自己的一组寄存器 但内存中的数据是各个线程共享的申请锁实际就是,把内存中的mutex通过交换指令,原子性的交换到自己的al寄存器中 |


【本文地址】
今日新闻 |
推荐新闻 |