【Linux】常用的文本处理命令详解 + 实例 [⭐实操常用,建议收藏!!⭐] |
您所在的位置:网站首页 › linux文件常用命令 › 【Linux】常用的文本处理命令详解 + 实例 [⭐实操常用,建议收藏!!⭐] |
【Linux】常用的文本处理命令详解 + 实例 [⭐实操常用,建议收藏!!⭐]
|
👨🎓博主简介 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入! 🐋 希望大家多多支持,我们一起进步!😄 🎉如果文章对你有帮助的话,欢迎 点赞 👍🏻 评论 💬 收藏 ⭐️ 加关注+💗 常用的文本处理命令目录 1、rename 批量修改文件名rename 介绍:rename 格式:rename 实例: 2、dirname 去除文件名中的非目录部分(取路径的目录部分)dirname 介绍:dirname 格式:dirname 实例: 3、basename 显示文件路径名的基本文件名(取路径中的文件名)basename 介绍:basename 格式:basename 实例: 4、cut 按列提取文件内容(切割文本内容)cut 介绍:cut 格式:cut 实例: 5、sort 对文件内容进行排序sort 介绍:sort 格式:sort 实例: 6、uniq 去除文件中的重复内容行(去重 相邻 的重复行)uniq 介绍:uniq 格式:uniq 实例: 7、tee 读取标准输入的数据(双重重定向)tee 介绍:tee 格式:tee 实例: 8、tr 字符转换工具(字符串替换)tr 介绍:tr 格式:tr 实例: 9、join 连接两个文件-->以某列为主,相同合并两个文件(不相同的话先排序)join 介绍:join 格式:join 实例: 10、paste 合并两个文件-->合并文件的列,把每个文件以列队列的方式合并显示paste 介绍:paste 格式:paste 实例: 11、split 分割文件内容split 介绍:split 格式:split 实例: 12、diff / vimdiff [多]文本比较diff / vimdiff 介绍:diff / vimdiff 格式:diff / vimdiff 实例: 13、xagrs 给其他命令传参数的过滤器xagrs 介绍:xagrs 格式:xagrs 实例: 14、rev 将文件中的每行内容反序输出(以列为单位)rev 介绍:rev 格式:rev 实例: 15、shuf 产生随机的排列(指定输出内容,随机输出没有顺序)shuf 介绍:shuf 格式:shuf 实例: 16、Shell脚本的调式方法一:set 方式脚本 外 使用调式脚本 内 使用调式 方法二:bashdb 第三方调试工具bashdb的安装bashdb的使用 1、rename 批量修改文件名首先:批量创建文件(20个) touch test-{1..20}.txt
rename命令的功能是用于批量修改文件名称。与mv命令一次只能修改一个文件名不同,rename命令能够基于正则表达式对文件名进行批量修改,但要求是把匹配规则准确地描述给系统。 rename命令的参数有三项:其一是当前文件名中要被修改的字符,其二是其要被修改为的新字符,其三是要被执行的对象文件列表。初次可能有点难理解,动手尝试下吧~ rename 格式: rename 原字符 新字符 文件名 rename 实例:实例1:修改名为 test-18.txt 为 cs-18.txt 单个修改还是推荐mv命令; rename test-18.txt cs-18.txt test-18.txt
实例2:将所有test开头的文件全部修改为abc开头的 rename test abc test*
实例3:将所有的txt后缀改为cfg rename txt cfg *
实例4:将所有的a都改为A rename a A *
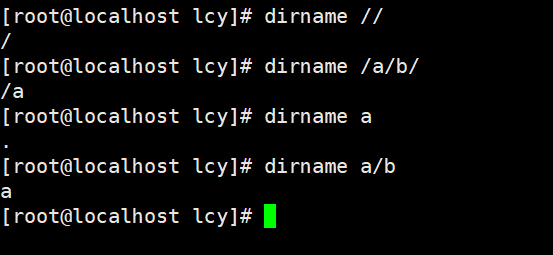
dirname命令去除文件名中的非目录部分,仅显示与目录有关的内容。dirname命令读取指定路径名保留最后一个/及其后面的字符,删除其他部分,并写结果到标准输出。如果最后一个/后无字符,dirname命令使用倒数第二个/,并忽略其后的所有字符。dirname 和 basename 通常在 shell 内部命令替换使用,以指定一个与指定输入文件名略有差异的输出文件名。 dirname 格式: dirname [参数] dirname 实例:实例1:去除 // 的非目录部分结果为 / : dirname // #结果为 /实例2:去除 /a/b/ 的非目录部分结果为 /a : dirname /a/b/ #结果为 /a实例3:去除 a 的非目录部分结果为 : dirname a #结果为 .实例4:去除 a/b 的非目录部分结果为路径名 a : dirname a/b #结果为 a
basename命令主要用于显示文件路径名剔除目录部分后的显示文件名。如何指定了后缀参数suffix,同时也删除文件的扩展名。其中,name是文件的路径名,suffix是文件名的后缀。 basename 格式: basename [参数] basename 实例:显示文件路径名/usr/bin/lcy的基本文件名lcy: basename /usr/bin/lcy #结果为 lcy
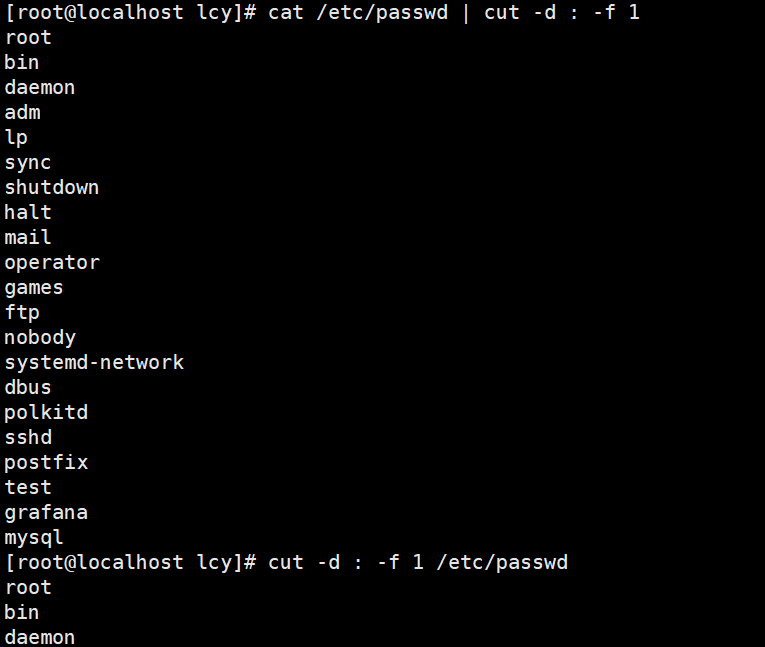
cut命令的功能是用于按列提取文件内容。常用的grep命令仅能对关键词进行按行提取过滤,而cut命令则是可以根据指定的关键词信息,针对特定的列内容进行过滤。 cut 格式: cut [参数] 文件名 cat 文件名 | cut [参数]常用参数: 参数解析-d指定分隔符-f指定取第几段,与-d一起使用-b按字节进行切割(一般是英文)-c按字符进行切割(一般是中文) cut 实例:实例1:以冒号为间隔符,仅提取指定文件中第一列的内容: cat /etc/passwd | cut -d : -f 1 cut -d : -f 1 /etc/passwd
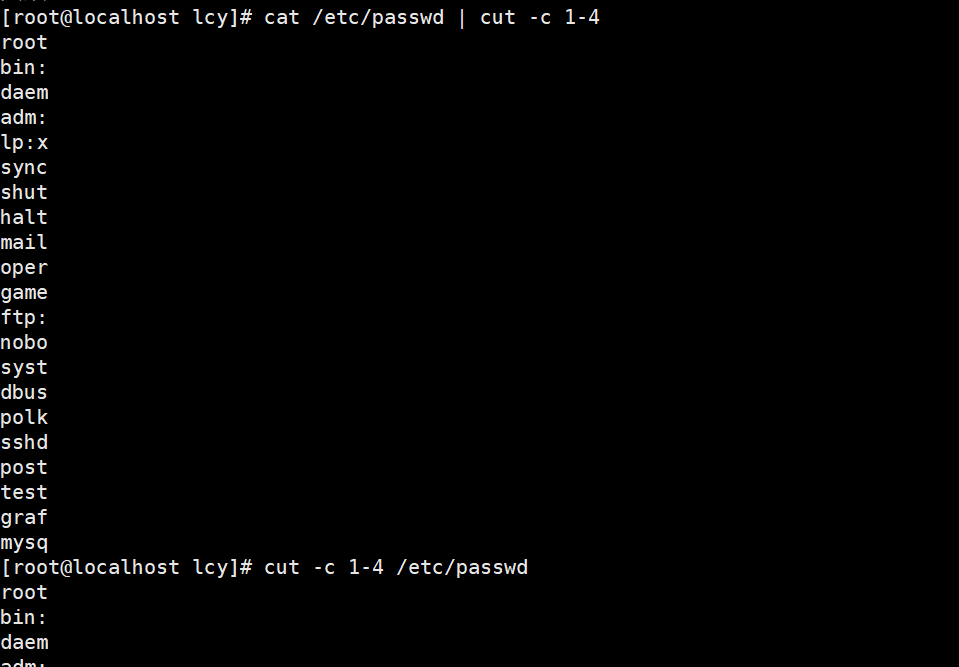
实例2:仅提取指定文件中每行的前4个字符: cat /etc/passwd | cut -c 1-4 cut -c 1-4 /etc/passwd
实例3:以空格为单位切割只要成功、失败两个字
实例4:切割passwd中只有root四个字 head -1 /etc/passwd | cut -d ":" -f 1
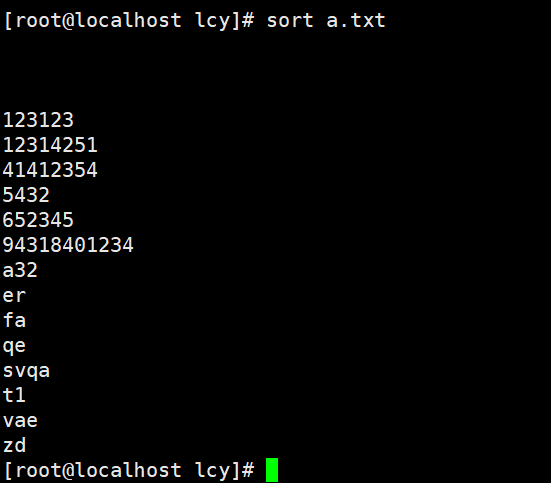
sort命令的功能是对文件内容进行排序。有时文本中的内容顺序不正确,一行行的手动修改实在太麻烦了。此时使用sort命令就再合适不过了,它能够对文本内容进行再次排序。 sort 格式: sort [参数] 文件名 cat 文件名 | sort [参数]常用参数: 参数解析-n(number)以数字为单位进行排序-r降序排-t指定分隔符,默认是空格-k以某段进行排序-b忽略每行前面出现的字符-c检查文件是否已经按照顺序排序-d除字母、数字及空格字符外,忽略其他字符-f将小写字母视为大写字母-h以更易读的格式输出信息(以人类可读的方式)-i除040至176之间的ASCII字符外,忽略其他字符-m将几个排序号的文件进行合并-M将前面3个字母依照月份的缩写进行排序-o将排序后的结果写入指定文件-R依据随机哈希值进行排序-T设置临时目录-z使用0字节结尾, 而不是换行 sort 实例:实例1:整体文件内容排序(优先空格–>数字–>字母–>中文) 不加任何参数默认只给首字母排序 sort a.txt cat a.txt | sort
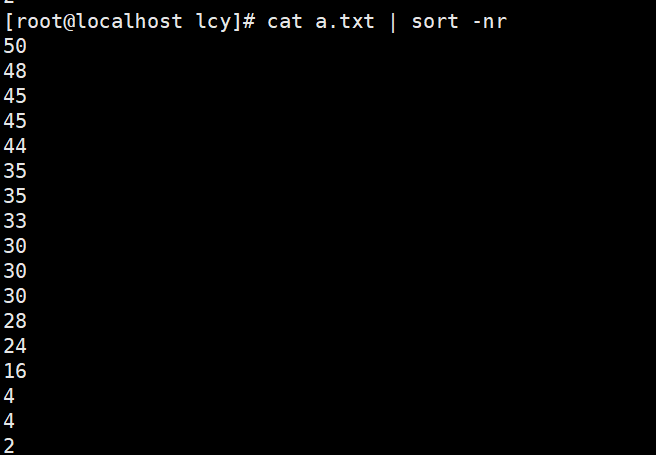
实例2:文本中数字从大到小排序(降序) sort -nr a.txt cat a.txt | sort -nr
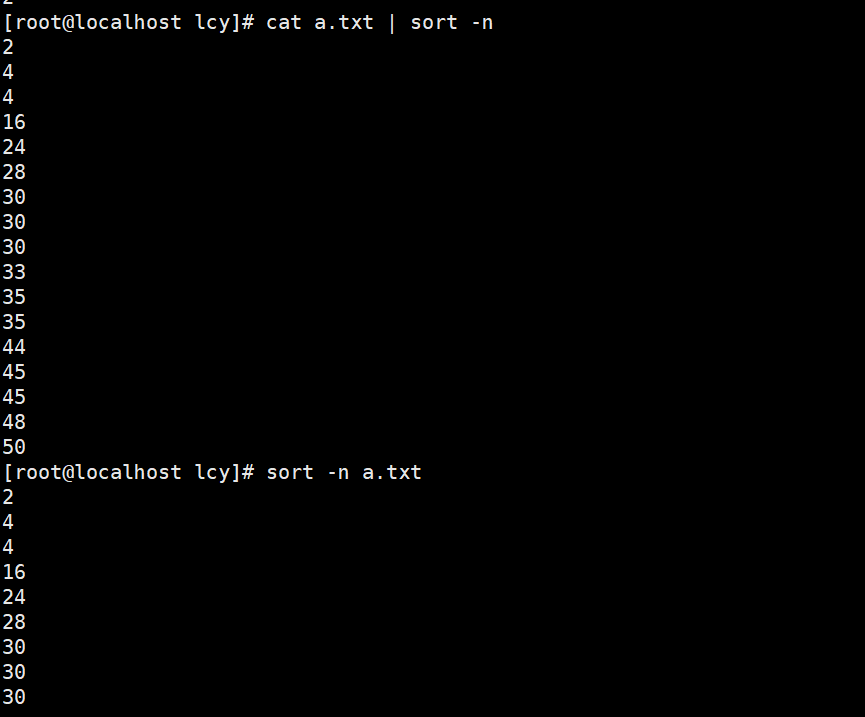
实例3:文本中数字从小到大排序(升序) sort -n a.txt cat a.txt | sort -n
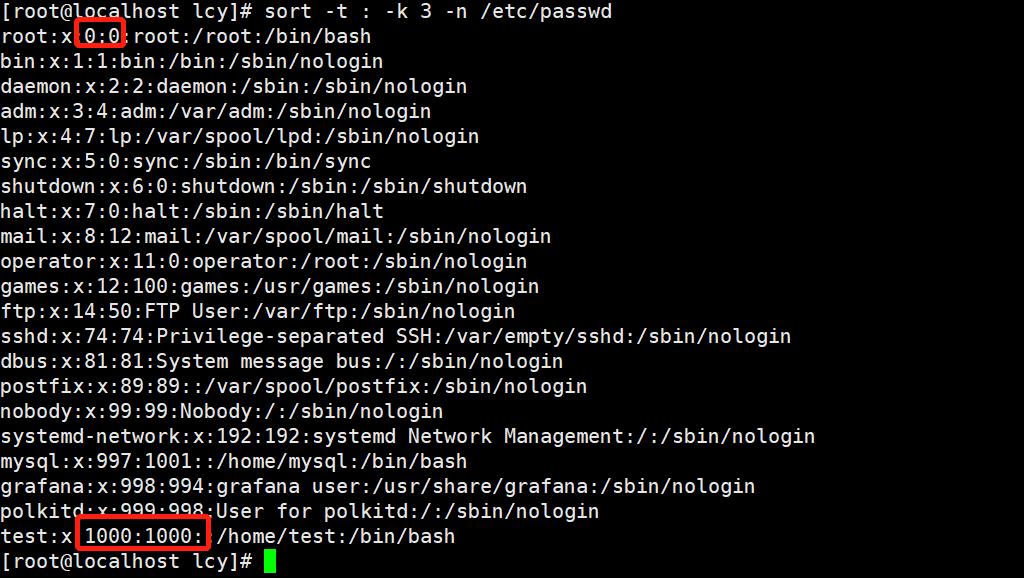
实例4:以冒号(:)为间隔符,对指定的文件内容按照数字大小对第3列进行排序(降序) sort -t : -k 3 -n /etc/passwd
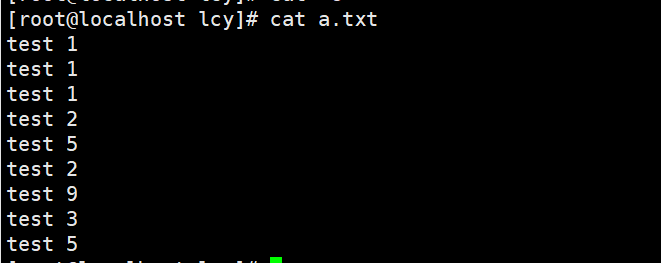
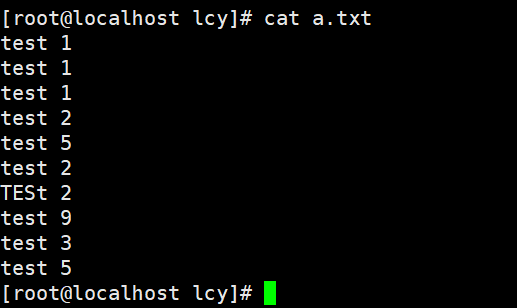
uniq命令来自英文单词unique的缩写,中文译为独特的、唯一的,其功能是用于去除文件中的重复内容行。uniq命令能够去除掉文件中相邻的重复内容行,如果两端相同内容中间夹杂了其他文本行,则需要先使用sort命令进行排序后再去重复,这样保留下来的内容就都是唯一的了。 uniq 格式: uniq [参数] 文件名 cat 文件名 | uniq [参数]常用参数 参数解析-c统计,显示每行在文本中重复出现的次数-d设置每个重复纪录只出现一次-u仅显示没有重复的纪录-D显示所有相邻的重复行-f跳过对前N个列的比较-i忽略大小写-s跳过对前N个字符的比较-w仅对前N个字符进行比较-z设置终止符(默认为换行符) uniq 实例:文本原文
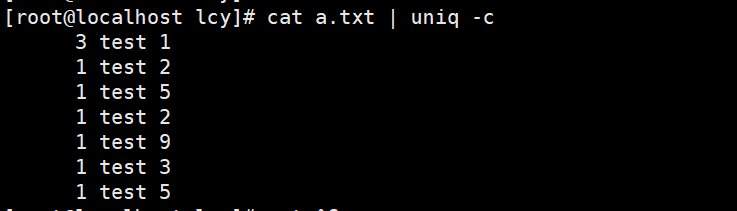
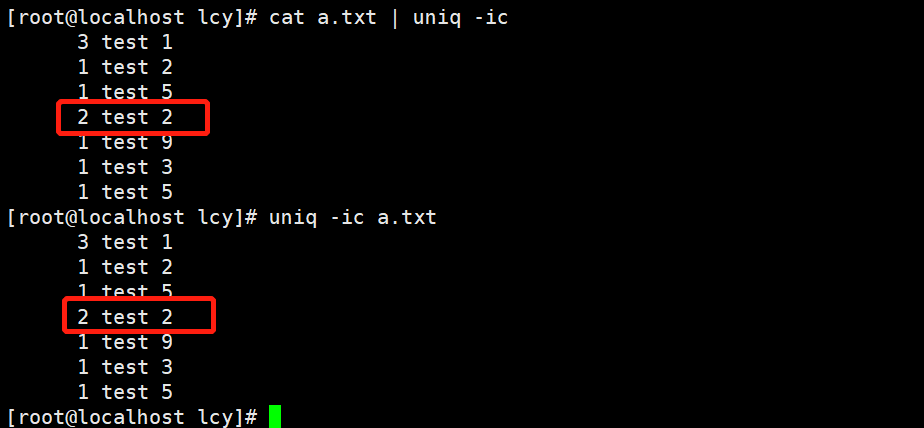
实例1:去除相邻的重复行,并显示重复次数 uniq -c a.txt cat a.txt | uniq -c前面的3、1代表的是统计的 相邻 重复行次数。
可以看到有几个也是一样的,但是没有进行统计,那是因为他们不是相邻的行,这时候我们可以结合sort命令排序来进行统计; cat a.txt | sort -n | uniq -c
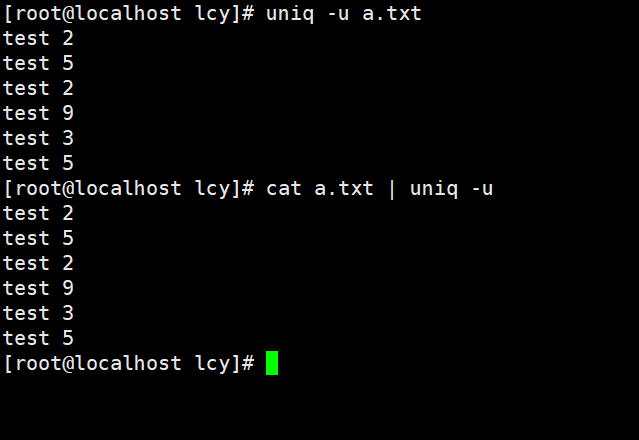
实例2:只统计没有重复的相邻的行的数据 uniq -u a.txt cat a.txt | uniq -u
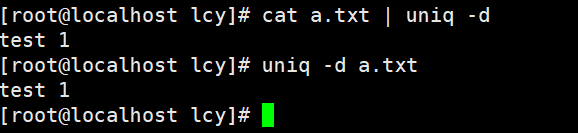
实例3:只统计重复的相邻的行的数据 cat a.txt | uniq -d uniq -d a.txt
实例4:忽略大小写去除相邻相邻的重复行,并显示重复次数 初始数据:
默认覆盖到文件中 tee 介绍:tee命令的功能是用于读取标准输入的数据,将其内容转交到标准输出设备中,同时保存成文件,并在页面上显示出来。 tee 格式: tee [参数] 文件名 cat 文件名 | tee [参数]常用参数 参数解析-a追加-i忽略中断信号-p诊断写入非管道的错误 tee 实例:实例1:执行uptime指定的命令,并将其执行结果即输出到屏幕,又写入到文件中 uptime | tee cs.txt
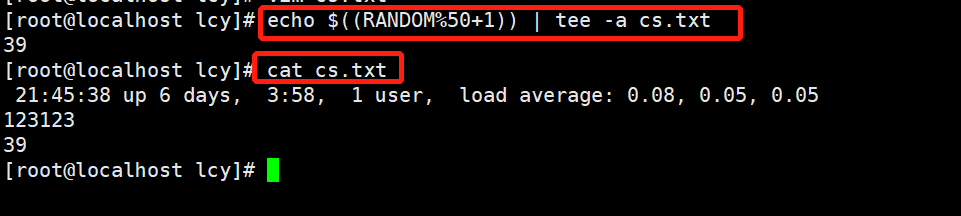
实例2:将要输入的结果即输出到屏幕上,又追加到cs.txt中 echo "123123" | tee -a cs.txt
实例3:随机输出1-50之间的随机数,将结果输出到屏幕上,并追加到cs.txt文件中 echo $((RANDOM%50+1)) | tee -a cs.txt
tr命令来自英文单词“transform”的缩写,中文译为“转换”,其功能是用于字符转换。tr命令是一款批量字符转换、压缩、删除的文本工具,但仅能从标准输入中读取文本内容,需要与管道符或输入重定向操作符搭配使用。 tr 格式: tr [参数] 原字符串 替换的字符串 ehco "字符串"|tr "原字符串" "替换的字符串"常用参数 参数解析-c排除某个字符替换其他字符-d删除指定的字符串-s去除相邻重复的字符-t将字符串1截断为字符串2的长度 tr 实例:实例1:直接展示输出abc,将abc替换为大写的ABC echo "abc" | tr "abc" "ABC"
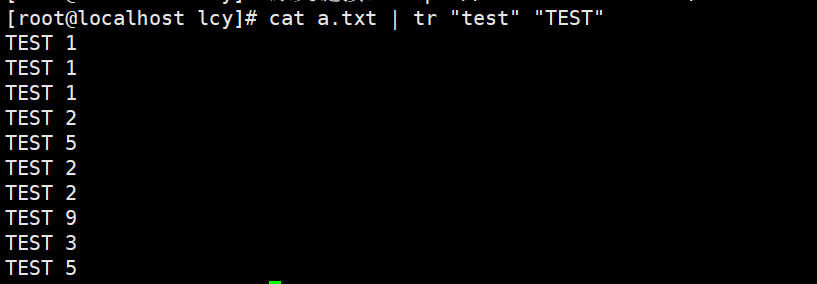
实例2:将文本中的小写的test全部变为大写的TEST 这个转换并没有起到修改的作用,因此看着是都转换了,但文本中还是小写的。 cat a.txt | tr "test" "TEST"
实例3:输出一长串字符串,只删除a-z的字母,其他都留着 echo "aaaaaaaaabbbbbbbbbbbbbbbbbb1c2c3cc" | tr -d "a-z" echo "aaaaaaaaabbbbbbbbbbbbbbbbbb1c2c3cc" | tr -d [a-z]
实例4:去除相邻的相同字符,只保留一个 echo "aaaaaaaabbbbbbbccccccc" | tr -s "a-z" echo "aaaaaaaabbbbbbbccccccc" | tr -s [a-z]
实例5:只保留字符abc,其余字符都替换成逗号 echo "aaaaaaaaabbbbbbbbbbbbbbbbbb1c2c3cc" | tr -c "abc" ","
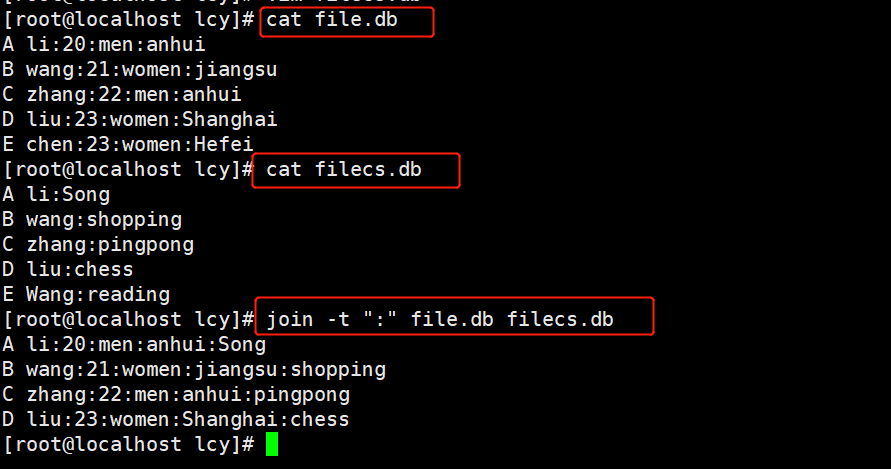
实例6:将所有的a-z的小写,全部替换为大写 cat a.txt | tr [a-z] [A-Z] tr [a-z] [A-Z] 以某列为主,相同合并两个文件(不相同的话先排序) join 介绍:join的连接操作简言之就是将两个具有相同域的纪录给挑选出来,再将这些纪录所有的域放到一行。 注意:join在对两个文件进行连接时,两个文件必须都是按照连接域排好序的,按其他域排序是无效的。 join 格式: join [参数] [文件1] [文件2]常用参数 参数解析-a1或-a2除了显示共同域的纪录之外,-a1显示第一个文件没有共同域的纪录,-a2显示第二个文件中没有共同域的纪录-i忽略大小写-o设置结果显示的格式-t改变域的分隔符-v1或-v2不显示共同域的纪录之外,-v1显示第一个文件没有共同域的纪录,-v2显示第二个文件中没有共同域的纪录-1或-2-1用来设置文件1连接的域,-2用来设置文件2连接的域 join 实例:实例1:将两个文件的具有共同域的记录连接在一起 [root@localhost lcy]# cat file.db A li:20:men:anhui B wang:21:women:jiangsu C zhang:22:men:anhui D liu:23:women:Shanghai E chen:23:women:Hefei [root@localhost lcy]# cat filecs.db A li:Song B wang:shopping C zhang:pingpong D liu:chess E Wang:reading [root@localhost lcy]# join -t ":" file.db filecs.db A li:20:men:anhui:Song B wang:21:women:jiangsu:shopping C zhang:22:men:anhui:pingpong D liu:23:women:Shanghai:chess
实例2:-a1还显示第一个文件中没有共同域的纪录,-a2则显示第二个 文本内容:
实例3:设置指定格式的域来显示出来(将具有共同纪录的域按照姓名+性别+爱好的格式显示出来) [root@localhost lcy]# join -t ":" -o 1.1 1.3 2.2 file.db filecs.db A li:men:Song B wang:women:shopping C zhang:men:pingpong D liu:women:chess 10、paste 合并两个文件–>合并文件的列,把每个文件以列队列的方式合并显示 paste 介绍:paste命令来自英文单词“粘贴”,其功能是用于合并两个文件。paste命令能够将两个文件以列对列的方式进行合并,相当于是把两个不同的文件内容粘贴到了一起,形成新的文件,如需先将内容合并成一行,再以行粘贴的方式合并,可以用-s参数搞定。 paste 格式: paste [参数] 文件名1 文件名2常用参数 参数解析-d设置自定义间隔符【指定连接符】-s将每个文件粘贴成一行【将文件多行变成一行输出】- -从标准输入中读取数据 paste 实例:实例1:将2行字符串修改为1行,在第一行后面添加=用于连接第二行 文本初始内容:
|


















【本文地址】
今日新闻 |
推荐新闻 |