西瓜书第3章学习笔记 |
您所在的位置:网站首页 › lda的两种求解方法 › 西瓜书第3章学习笔记 |
西瓜书第3章学习笔记
|
第三章 线性模型
3.1基本形式
线性模型就是要学得一个形如 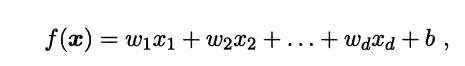
的函数,其中x表示某确定属性上的取值,ω为权值,向量形式如下: 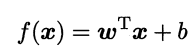
要做的就是求出ω和b。 类比西瓜问题: 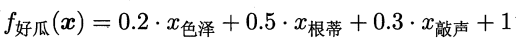
可以理解为,决定一个瓜是否为好瓜的因素包括色泽,根蒂,敲声。 3.2线性回归线性回归的目的就是学得一个形如 首先考虑单变量的情形,即假设西瓜的好坏只由单一因素决定(例如西瓜大小)。 确定ω和b这两个参数的首要原则应该是使得预测值
求解ω和b使E最小化的过程称为线性回归模型的最小二乘“参数估计”,我们将E分别对ω和b求偏导,并令其为零,即可求出最优解: 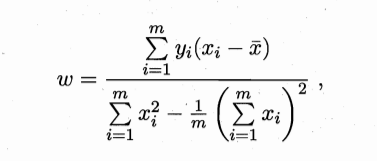
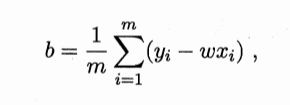
其中 将单变量的情形进行推广,决定西瓜好坏的因素有多维,并用矩阵来表示如下: 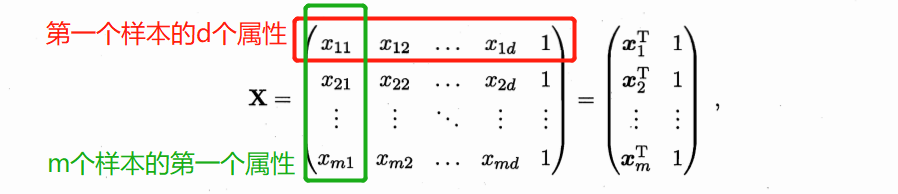
注:最后一列都为1是因为b的系数为1. 类似的,有均方误差的表达式如下: 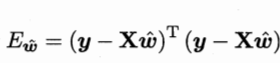
再对ω求偏导: 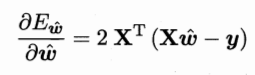 3.2.3对数线性回归
3.2.3对数线性回归
在前面的线性回归中使用的模型都是 前两小节讨论的都是回归问题,当面对分类问题时,只需要将分类问题的真实标记y和回归模型的预测值联系起来。 考虑二分类问题,其真实标记y的取值为0或1,而线性回归模型产生的预测值是一个连续值 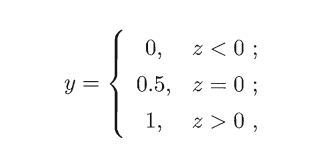
显然,阶跃函数不具有可微的性质,因此便使用其替代——对数几率函数: 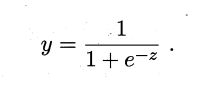
两种函数的图像如下: 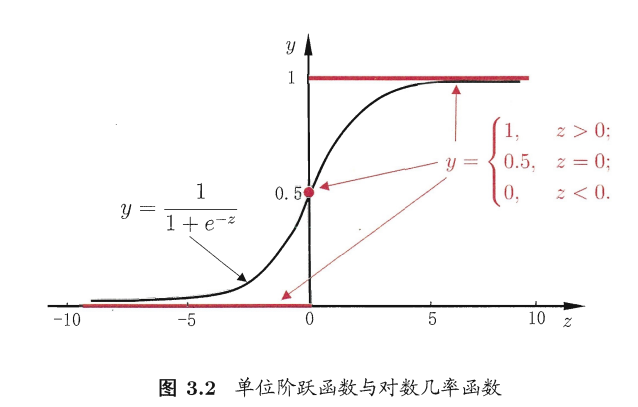
可以看出对数几率函数也是一种Sigmoid函数。 将 
若将y视为正例,则1-y为反例,二者的比值称为几率,反映了x作为正例的相对可能性。 把上述式子中的y看做后验概率p(y=1丨x),则该式子可以写为: 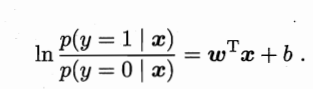
也就是把随机变量y取值为0和1的概率分别建模为了: 
为了便于讨论,令β=(ω;b), 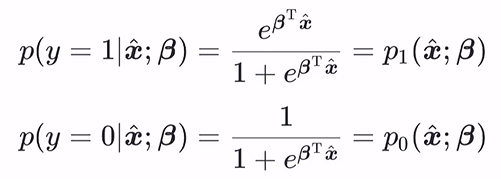
可以简写为下面式子,方便进行极大似然估计: 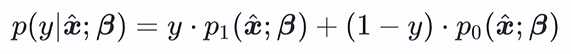
注:上式中,分别代入y=0和y=1就可以分别得到上面两个式子。 接下来写出似然函数和对数似然函数: 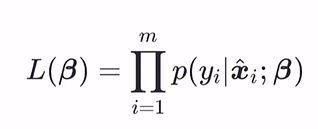
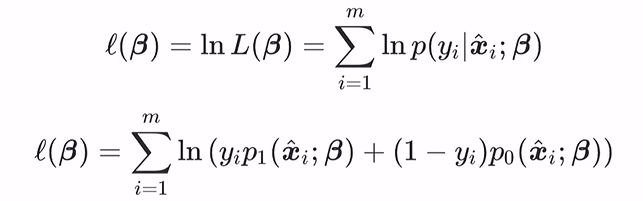
再把p0和p1分别代入得到 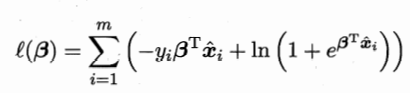
上式已经是关于β的高阶可导连续函数,使用梯度下降法即可得到近似值。 3.4线性判别分析(LDA)LDA的想法是将所有的样本点投影到一条直线上,使得相似的样本点尽可能地靠近,不同的样本点尽可能远离,由于最早由Fisher提出,也叫“Fisher判别分析”,图示如下: 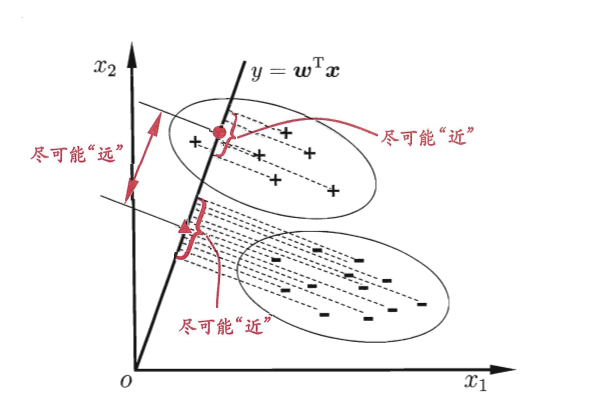
欲使异类样本尽可能远离,可以让类中心的距离最大化,根据此原理得出损失函数: 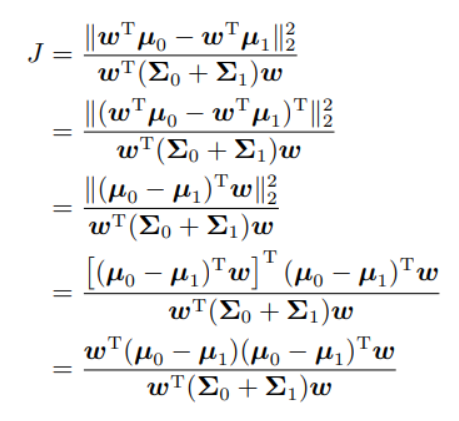
|
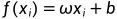 的线性模型用以得出预测值。
的线性模型用以得出预测值。 与实际值
与实际值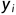 间的误差较小,即让均方误差最小化(将均方误差最小化来求解模型的方法称为“最小二乘法”)。均方误差的定义如下:
间的误差较小,即让均方误差最小化(将均方误差最小化来求解模型的方法称为“最小二乘法”)。均方误差的定义如下: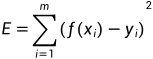
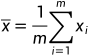 为x的均值。
为x的均值。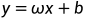 ,如果将模型修改为
,如果将模型修改为 ,就变为了对数线性回归,其形式上仍是线性回归,但是本质上求的是y和x的非线性关系。
,就变为了对数线性回归,其形式上仍是线性回归,但是本质上求的是y和x的非线性关系。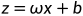 ,于是我们需要将连续值z转化为0/1值,用到阶跃函数:
,于是我们需要将连续值z转化为0/1值,用到阶跃函数: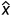 =(x;1),上述式子就可以写成:
=(x;1),上述式子就可以写成:【本文地址】