EDTER:基于transform的边缘检测 |
您所在的位置:网站首页 › layernorm的作用 › EDTER:基于transform的边缘检测 |
EDTER:基于transform的边缘检测
|
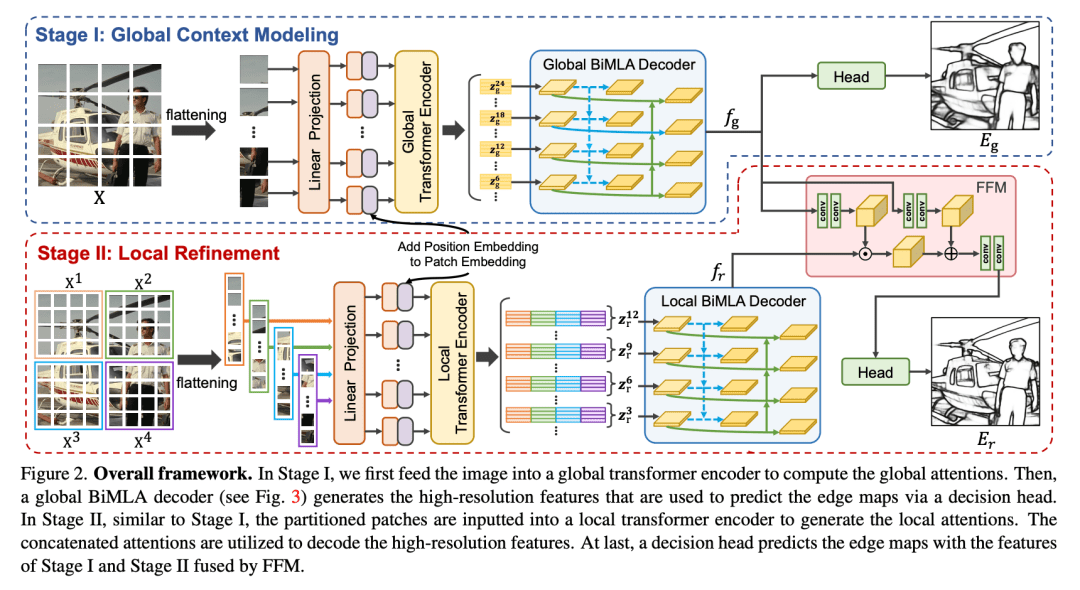
https://github.com/MengyangPu/EDTER Related Work 边缘检测作为计算机视觉的一项基本任务,多年来得到了广泛的研究。下面重点介绍与该论文相关的一些工作。 Edge Detection: 早期的边缘检测器,如Sobel、Canny主要是对图像进行梯度分析,提取边缘。这些方法提供了基本的底层cues,广泛应用于计算机视觉领域。基于Learning-based的方法整合不同的低层特征训练分类器得到边界和边缘,这些方法基于手工制作的特征,限制了检测语义边界和有意义的边缘的能力。DeepEdge、HED、RCF、BDCN、PiDiNet(主要阐述了前人做的工作,见原文)。 transformer: DETR、ViT、SETR,这些工作证明了transformer在获取远程依赖关系和全局上下文信息的有效性。 阐述该论文的创新点:第一个将transformer应用于边缘检测。 通过一个两阶段框架来学习全局和局部图像上下文信息。 融合了全局和局部cues。 Edge Detection with Transformer Overview EDTER分两阶段提取整幅图像的上下文信息和fine-grained cues。阶段1中,将图像分割成coarse-grained patches并且run一个全局transformer编码器来获取long-range的上下文信息。然后,develop BiMLA解码器生成高分辨率的representations用于边缘检测。阶段2中,首先通过不重叠的滑动窗口将整个图像分割成多个fine-grained patches序列,然后一个局部transformer作用于每个序列来提取short-range局部 cues。然后将局部cues输入到局部BiMLA解码器获取像素级特征图。最后通过FFM融合两个阶段的信息然后输入到决策头进行最终的边缘预测。
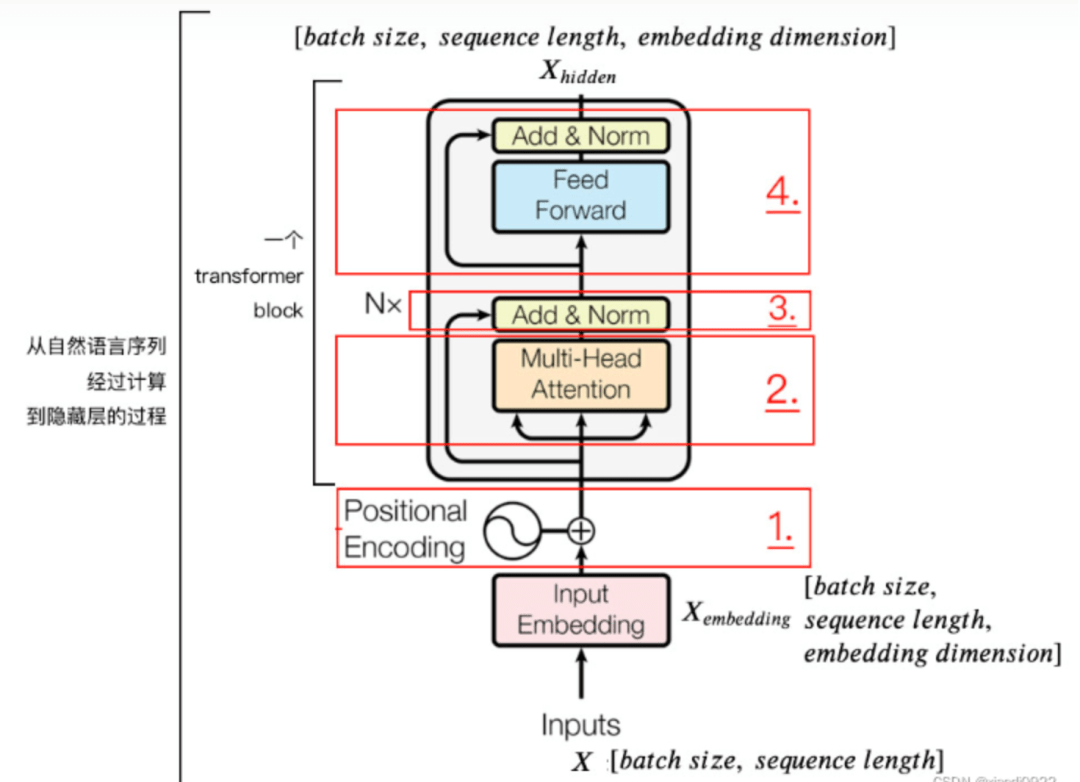
Review Vision Transformer 本文采用的transformer encoders遵循ViT。 Image Partition:ViT的第一步是将2D图像X(H×W×3)转换为1D的图像patches序列。也就是将X分割成尺寸为P×P的flattened image patches,产生H/P×W/P的vision tokens。然后,通过learnable linear projection将序列投影到一个隐藏的embedding space。为了保留位置信息,在patch embeddings中加入标准的可学习的1D position embeddings。最后,将组合好的embedding输入到transformer encoder。 Transformer Encoder:标准的transformer encoder 是由L个transformer blocks组成。每个块有多头自注意力 操作(MSA)、一个多层感知机(MLP)、和两个Layernorm,此外,每个块应用一个残差连接。MSA并行执行M自注意力并输出他们的concat结果。
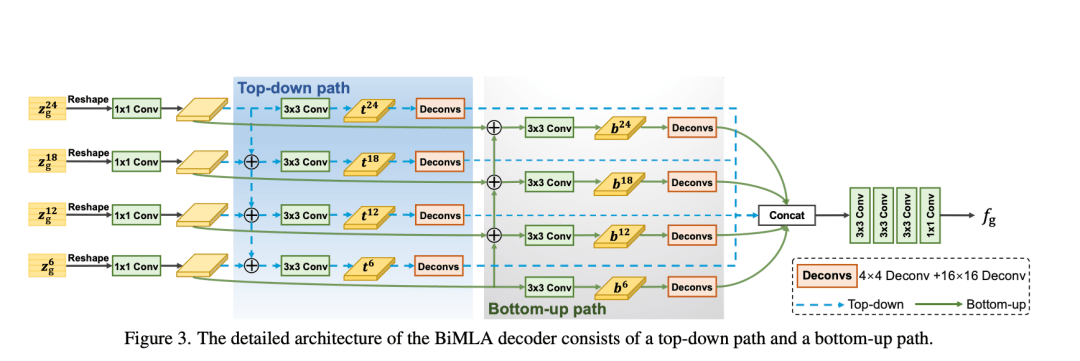
Stage I: Global Context Modeling 在第一个阶段,通过全局tranformer encoder Ge和全局解码器Gd来提取coarse-grained patches全局上下文特征。 首先,将输入图像分成一系列尺寸为16×16的 coarse-grained patches,然后生成embedding (Zg0)作为编码器的输入。下一步全局tranformer encoder 作用于embedding(Zg0)计算全局的注意力。得到全局上下文特征Zg序列被全局解码器Gd上采样到高分辨率特征进行合并。 BiMLA Decoder: 生成边缘感知的像素级表示对于精确的边缘检测至关重要。受多级特征融合的影响,提出了双向多级聚合解码器(BiMLA)
BiMLA包括一个自顶向下和自底向上的路径来增强信息的流通在transformer encoder。首先,将Lg个transformer blocks分成四组,从每组的最后一个block中拿出embedding features(Zg6,Zg12,Zg18,Zg24) 作为输入。然后将他们reshape成3D特征图(H/16×W/16×C)。对于自顶向下的路径,分配相同的设计(一个1×1卷积和3×3卷积层)作用于reshaped feature得到四个输出features(t6,t12,t18,t24),遵循SETR-MLA的方法。同样地,自底向上的路径从最底层逐步到顶层,分配3×3卷积层到多级特征上,最后产生另外四个输出features(b6,b12,b18,b24)。每个聚合特征通过一个反卷积block,包含4×4和16×16两个反卷积层。每个反卷积之后加入BN和ReLU。双路径来的八个特征图进行concat操作得到一个tensor。BIMLA使用额外的卷积层来平滑features,包括三层3×3卷积层和一个1×1卷积层+BN+ReLU。
Stage II: Local Refinement 因为16×16的patches不利于提取 thin edges,将像素作为tokens是一种直接的方法,但是,这将导致计算负担很大,在实际应用中不可行。作者的解决方法是用一个不重叠的滑动窗口进行采样,然后计算采样区域中的attentions。由于窗口中的patches的数量是固定的,计算复杂度和图像大小成线性关系。 采用H/2×W/2的滑动窗口,将输入图像分成{X1,X2,X3,X4}的序列。对于每个窗口,分割成8*8的fine-grained patches,通过局部tranformer编码器Re,计算attentions。然后,将所有窗口的attentions进行concat得到Zr={Zr1,···,ZrLr}。为了进一步节省计算资源,将Lr=12,也就意味着局部tranformer编码器由12个transformer blocks组成。与全局BiMLA类似,选择{Zr3,Zr6,Zr9,Zr12}输入到局部BiMLA Rd生成局部高分辨率特征。
Feature Fusion Module:通过一个特征融合模块整合了来自于两个levels的上下文cues,并利用局部决策头来预测边缘。FFM将全局上下文作为先验知识并对局部上下文进行modulates(调节),生成包含全局上下文和细粒度局部细节的融合特征。FFM由空间特征transform block和两个3×3卷积层组成,然后进行BN和ReLU。前者用于调节,后者用于平滑。然后将融合特征输入局部决策头Rh,预测出边缘图Er。 Network Training 训练方法:首先优化阶段1生成的全局特征,然后对参数进行修正并训练阶段2生成边缘图。 损失函数的设计:
Training Stage I:通过最小化每个边缘图和ground truth之间的损失优化阶段1。
Training Stage II:阶段1训练完之后,确定其参数然后进入阶段2。
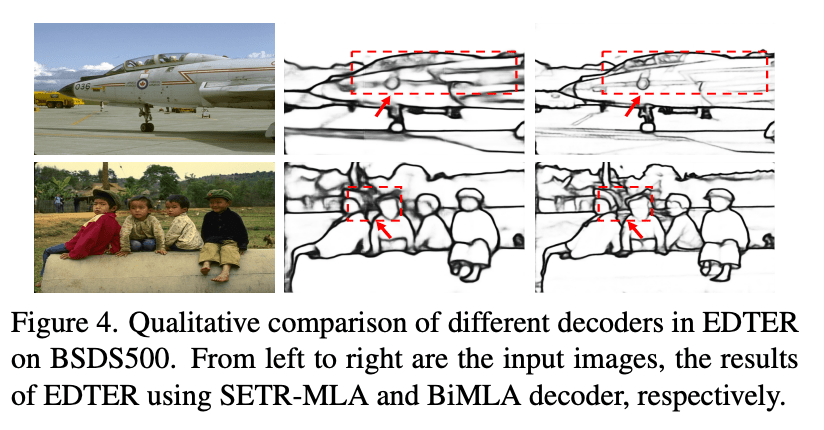
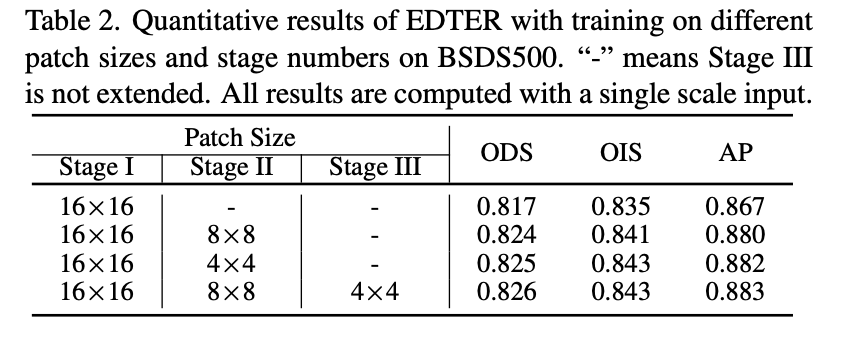
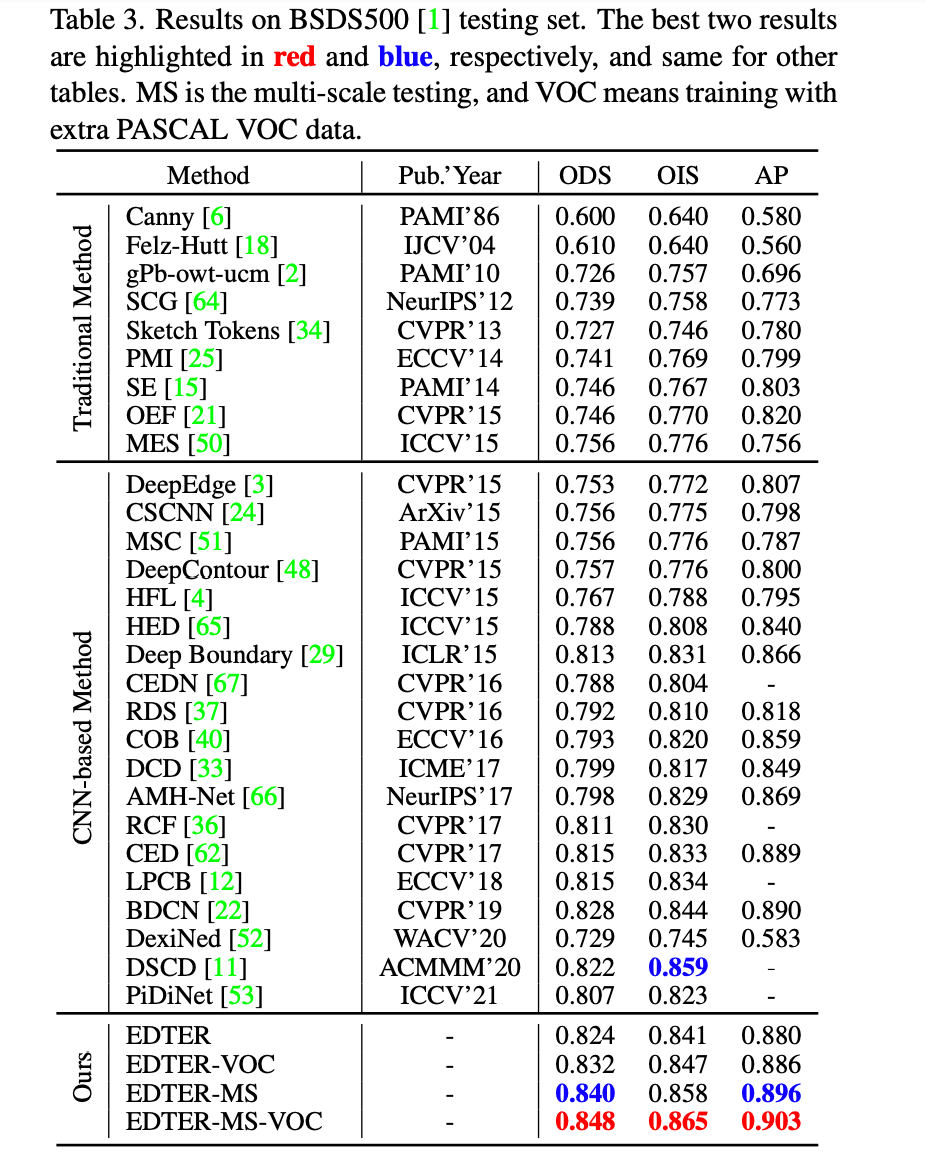
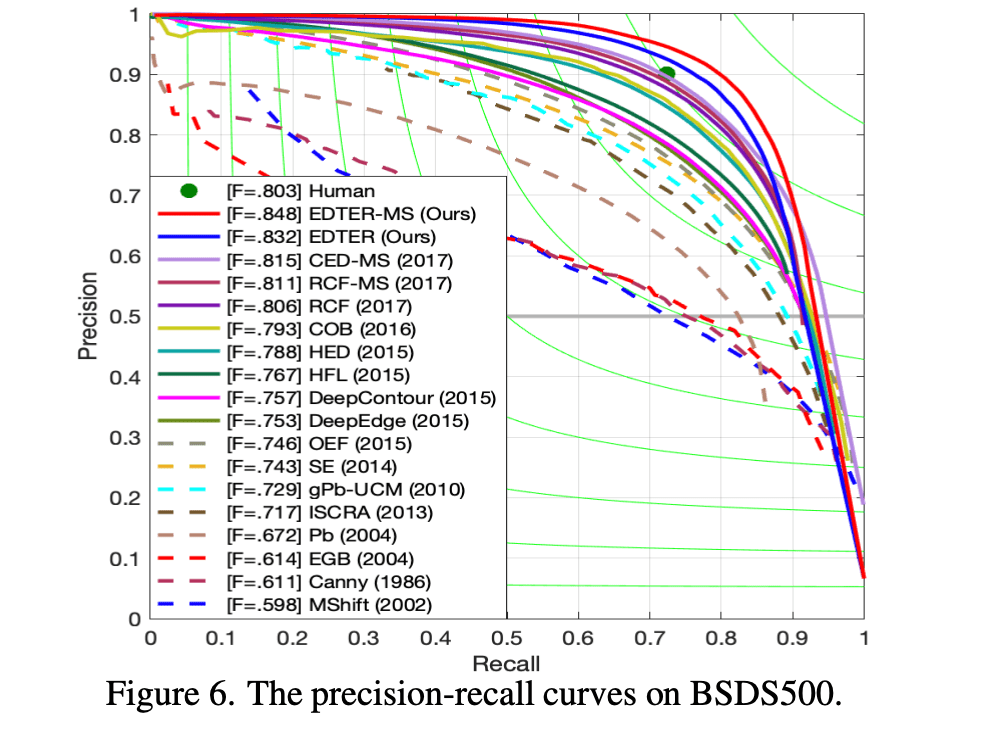
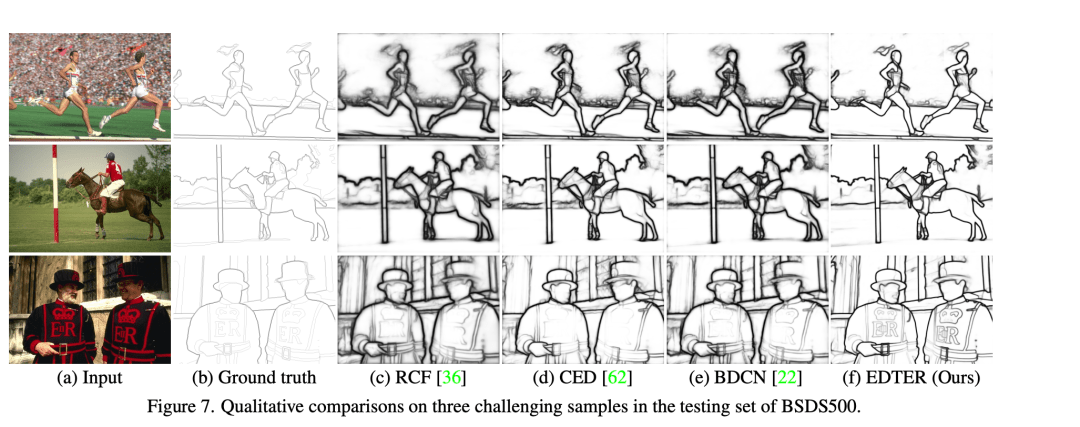
5 实验结果 主要以图片的形式展示
机器学习算法AI大数据技术 搜索公众号添加: datanlp 阅读过本文的人还看了以下文章: TensorFlow 2.0深度学习案例实战 基于40万表格数据集TableBank,用MaskRCNN做表格检测 《基于深度学习的自然语言处理》中/英PDF Deep Learning 中文版初版-周志华团队 【全套视频课】最全的目标检测算法系列讲解,通俗易懂! 《美团机器学习实践》_美团算法团队.pdf 《深度学习入门:基于Python的理论与实现》高清中文PDF+源码 《深度学习:基于Keras的Python实践》PDF和代码 特征提取与图像处理(第二版).pdf python就业班学习视频,从入门到实战项目 2019最新《PyTorch自然语言处理》英、中文版PDF+源码 《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码 《深度学习之pytorch》pdf+附书源码 PyTorch深度学习快速实战入门《pytorch-handbook》 【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》 《Python数据分析与挖掘实战》PDF+完整源码 汽车行业完整知识图谱项目实战视频(全23课) 李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材 笔记、代码清晰易懂!李航《统计学习方法》最新资源全套! 《神经网络与深度学习》最新2018版中英PDF+源码 将机器学习模型部署为REST API yolo3 检测出图像中的不规则汉字 同样是机器学习算法工程师,你的面试为什么过不了? 前海征信大数据算法:风险概率预测 【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类 特征工程(一) 特征工程(二) :文本数据的展开、过滤和分块 特征工程(三):特征缩放,从词袋到 TF-IDF 特征工程(四): 类别特征 特征工程(五): PCA 降维 特征工程(六): 非线性特征提取和模型堆叠 特征工程(七):图像特征提取和深度学习 如何利用全新的决策树集成级联结构gcForest做特征工程并打分? Machine Learning Yearning 中文翻译稿 蚂蚁金服2018秋招-算法工程师(共四面)通过 全球AI挑战-场景分类的比赛源码(多模型融合) 斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏) 中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程 不断更新资源 深度学习、机器学习、数据分析、python 搜索公众号添加: datayx 返回搜狐,查看更多 |








【本文地址】
今日新闻 |
推荐新闻 |