深入理解NLP中LayerNorm的原理以及LN的代码详解 |
您所在的位置:网站首页 › layernorm参数作用 › 深入理解NLP中LayerNorm的原理以及LN的代码详解 |
深入理解NLP中LayerNorm的原理以及LN的代码详解
|
深入理解NLP中LayerNorm的原理以及LN的代码详解
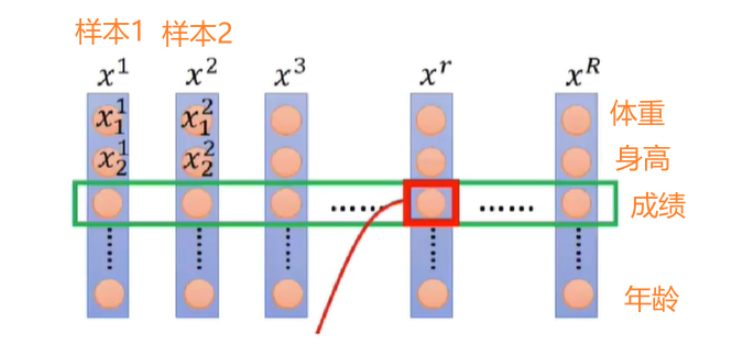
在介绍LayerNorm之前,我们先来思考一下,为什么NLP中要引入LayerNorm? 如果你学过一点深度学习,那么应该多多少少听过BatchNorm这个东西。BN简单来说就是对一批样本按照每个特征维度进行归一化。BN具体细节请看我的另一篇博客:深入理解BatchNorm的原理 以下图为例演示下BatchNorm的过程,我们会对R个样本的“成绩”这个特征维度做归一化。 但在NLP领域,每个样本通常是一个句子,而句子中包含若干个单词。这时如果使用BN去做过归一化通常效果会很差。
那有没有更好的归一化方法呢? 有的,我们今天就来看一看NLP中常用的归一化操作:LayerNorm LayerNorm原理在NLP中,大多数情况下大家都是用LN(LayerNorm)而不是BN(BatchNorm)。最直接的原因是BN在NLP中效果很差,所以一般不用。 |

【本文地址】