使用LabVIEW共享变量 |
您所在的位置:网站首页 › labview缓冲区在哪 › 使用LabVIEW共享变量 |
使用LabVIEW共享变量
|
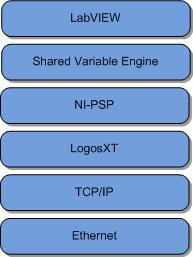
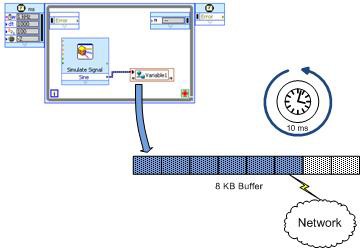
利用网络发布共享变量,您可以在以太网网络上读写共享变量。网络应用的处理完全通过网络发布变量完成。 除了使数据可在网络外使用,网络发布共享变量中还增加了许多单进程共享变量所不具备的功能。由于这些增加的功能,网络发布共享变量的内部实现要比单进程共享变量要复杂得多。后面几节将讨论这方面的内容,并给出利用网络发布共享变量来获得卓越性能的一些建议。 NI-PSP NI发布-订阅协议(NI-PSP)是专为传输网络共享变量而优化的网络协议。 NI-PSP的最底层协议是TCP/IP,已重点针对桌面系统和NI RT终端的性能进行了全面的调整(参见以下基准测试性能比较)。 LogosXT的工作原理 图7显示的是网络共享变量的软件栈。 由于此处所述的工作原理专门针对LogosXT堆栈级别,因此理解这一点很重要。 LogosXT是软件栈中负责优化共享变量吞吐量的层。 图7.共享变量网络堆栈 图8显示的是LogosXT传输算法的主要组成部分。 本质上,它非常简单。 其中两个最重要的组成部分是: 8 KB传输缓冲区10 ms定时器线程图8.LogosXT的主要组成部分。 当缓冲区满了或者10 ms过去之后,缓冲区的数据将传输出去 这些数字是在经过彻底分析各种数据包大小和时间后得出的,旨在优化数据吞吐量。 算法如下: 如果在10 ms定时器触发之前传输缓冲区容量已满(8 KB),则缓冲区中的数据会立即通过与启动写入操作相同的线程发送到TCP。 对于共享变量,该线程将是共享变量引擎线程。如果10 ms过去了,缓冲区还没有填满,那么数据将通过定时器的线程发送出去。重要说明:两个不同端点之间的所有连接共有一个传输缓冲区。 也就是说,代表两台不同机器之间的连接的所有变量将共享一个缓冲区。 但不要将此传输缓冲区与共享变量的缓冲属性混淆。 这个传输缓冲区是一个非常底层的缓冲区,它将变量多路复用到一个TCP连接中,从而优化了网络吞吐量。 由于网络堆栈这一层的功能会对LabVIEW程序框图上的代码产生负面作用,因此理解该功能很重要。 从吞吐量的角度来看,在单个发送操作中发送尽可能多的数据显然效率更高,因而该算法会等待10 ms。 从时间和数据包大小的角度来看,每个网络操作都有固定的开销。 如果我们发送许多小数据包(N个数据包),这些数据包总共包含B字节,那么我们需要支付N次网络开销。 然而,如果我们发送一个包含B字节的大数据包,那么我们只需支付一次固定开销,这样整体吞吐量要高得多。 如果需要以尽可能高的吞吐量与终端流式传输数据,则此算法非常适用。 另一个方面,如果不需要经常发送小数据包,例如向终端发送命令以执行某些操作(如断开继电器[1个字节的布尔数据]),但希望命令能尽快到达终端,则需要优化延迟。 如果对于应用来说,优化延迟更为重要,则需要使用“刷新共享变量数据”函数。 该VI将强制LogosXT中的传输缓冲区通过共享变量引擎和网络进行刷新。 这将极大降低延迟。 注意: 在LabVIEW 8.5中,不存在强制LogosXT刷新其缓冲区的情况,也不存在“刷新共享变量数据”函数。 由于程序会先等待传输缓冲区被填满,然后再按10 ms的定时频率将缓冲区接收到的数据发送出去,因此系统基本上至少会有10 ms的延迟。 但如上所述,将一台机器连接到另一台机器的所有共享变量均共享同一个传输缓冲区,因此如果调用“刷新共享变量数据”,将会影响系统上的许多其他共享变量。 而如果有其他依赖于高吞吐量的变量,调用“刷新共享变量数据”则会对其产生不利影响(图9)。
图9.刷新共享变量数据
部署与托管 网络发布共享变量必须部署到网络上托管该变量值的共享变量引擎(SVE)中。当写入一个共享变量节点时,LabVIEW会将这个新值发送给部署和托管该变量的SVE。SVE处理循环将发布该值,使得订阅者可以得到更新值。图10显示的就是这一过程。从客户端/服务器的角度来看,SVE是共享变量的服务器,所有对其的引用(不论是对变量进行写入还是读取操作)都是客户端。SVE客户端是每个共享变量节点实现中的一部分,在本文中,客户端和订阅者这两个术语是可互换的。 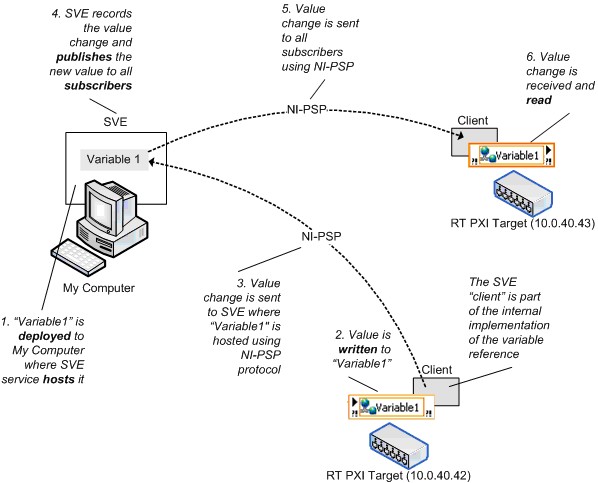
图10.共享变量引擎以及网络共享变量值的变化 网络发布变量和LabVIEW Real-Time 实时FIFO可以通过网络发布共享变量来启用,但与启用实时FIFO的单进程共享变量相比,启用FIFO的网络发布共享变量有一个重要的行为差异。上面说过,在单进程共享变量中,所有写入和读出操作共享一个单一的实时FIFO;但网络发布共享变量并非如此。无论是单元素和多元素情况下,网络发布共享变量的每一个读取线程都有各自的实时FIFO,如下所示。 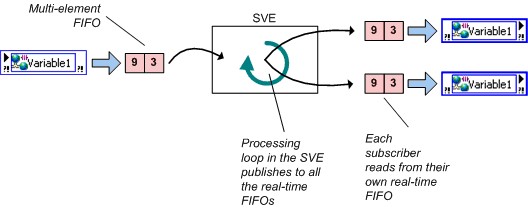
图11.已启用实时FIFO的网络发布变量 网络缓冲 对于网络发布共享变量,您可以使用缓冲功能。在共享变量属性(Shared Variable Properties)对话框中,可以配置缓冲,如图12所示。 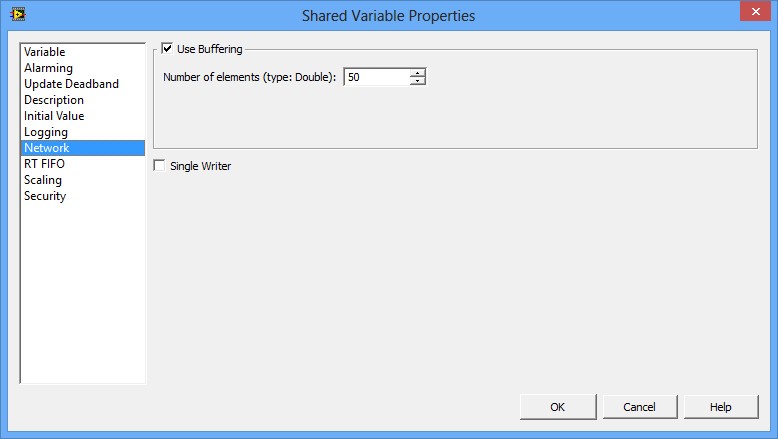
图12.在网络发布共享变量中启用缓冲功能 启用缓冲功能后,您能以数据类型的单位指定缓冲区的大小,在本例中,该数据类型为双精度。 缓冲功能可以解决对于变量读取/写入速度的临时波动问题。读取线程偶尔比写入线程慢的情况可能会导致一些更新数据的丢失。如果应用可以容忍偶尔的数据丢失,则较慢的读取速率并不会影响应用,此时就不需要启用缓冲功能。但是,如果读取线程必须获得每个更新数据,请启用缓冲功能。您可以在共享变量属性(Shared Variable Properties)对话框中的变量(Variable)页面设定缓冲区大小,这样就可以确定在旧数据被覆盖之前,应用可以保存多少更新数据。 在上述对话框中配置网络缓冲区时,您实际上是配置了两个不同缓冲区的大小。 服务器端缓冲区,即图13中标有共享变量引擎(SVE)的方框中的缓冲区,这是自动创建的,并被配置为与客户端缓冲区同样的大小,稍后再详细介绍该缓冲区。 客户端缓冲区就是在启用共享变量缓冲区时逻辑上认为的缓冲区。 客户端缓冲区(如图13右边所示)是负责维持先前值队列的缓冲区。 正是这一缓冲区避免了共享变量受到循环速度或网络流量波动的影响。 与启用实时FIFO的单进程变量(所有写入线程和读取线程共享相同的实时FIFO)不同,网络发布共享变量的每个读取线程都有自己的缓冲区,因此读取线程不会相互影响。 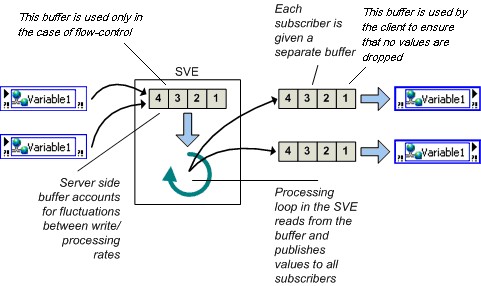
图13.缓冲 缓冲功能只适用于变量读取/写入速度存在临时波动的情况。如果程序运行的时间不确定,而读取线程速率总是低于写入线程速率,则不管将缓冲区设置为多大,最终都会出现数据丢失的情况。由于缓冲功能会为每个订阅者分配一个缓冲区,为避免不必要的内存占用,请仅在必要时使用缓冲功能。 网络和实时缓冲 如果同时启用网络缓冲和实时FIFO,则共享变量的执行中将同时包含一个网络缓冲区和一个实时FIFO。前面讲过,启用实时FIFO后,将为每个读取线程和写入线程创建新的实时FIFO,使得多个写入线程和读出线程之间不会彼此阻塞。 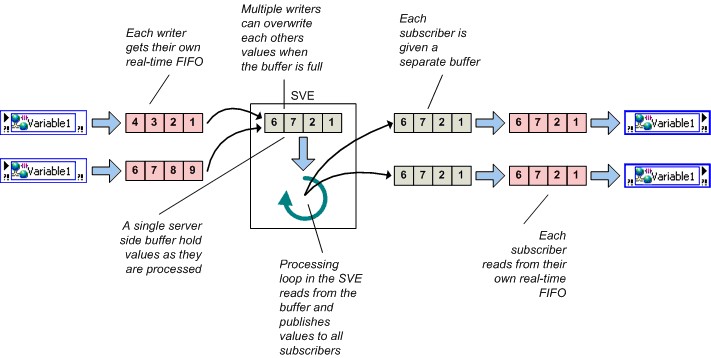
图14.网络缓冲和实时FIFO 虽然这两个缓冲区的大小可以独立设置,但在大多数情况下,NI建议将其设为同样的大小。如果启用实时FIFO,LabVIEW将为每个读取线程和写入线程创建新的实时FIFO。因此,多个写入线程和读出线程之间不会彼此阻塞。 缓冲区生命周期 LabVIEW在初始写入或读取操作时创建网络和实时FIFO缓冲区,具体取决于缓冲区的位置。 服务器端缓冲区在写入线程初始写入共享变量时创建。客户端缓冲区在建立订阅时创建。当包含共享变量节点的VI开始执行时,即会触发这些行为。 如果写入线程在特定读取线程订阅共享变量之前将数据写入共享变量,则该订阅者将无法得到这些初始数据值。 注意: 在LabVIEW 8.6之前,首次执行共享变量读取或写入节点时会创建缓冲区。 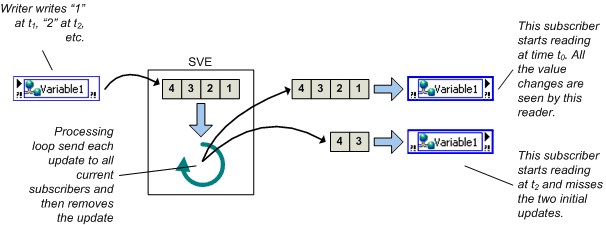
图15.缓冲区生命周期 缓冲区溢出/下溢 网络发布共享变量会报告网络缓冲区的溢出和下溢情况。不管是哪个版本,实时FIFO都会通过返回错误来指示溢出/下溢情况。 注意: 旧版LabVIEW不会报告网络缓冲区的溢出/下溢情况。 在LabVIEW 8.0或8.0.1,可以用下列两种方式检查网络缓冲下溢。由于共享变量时间标识的分辨率为1 ms,当以低于1 kHz的速率更新共享变量时,可以将变量的时间标识与后续读取操作的时间标识进行比较来检测缓冲区下溢。或者读取线程可以使用与数据绑定的序列号来报告缓冲区溢出/下溢。但如果数据类型是数组,则在实时优先级循环内不能对共享变量使用第二种方法,因为如果簇中的某个元素是数组,则启用实时FIFO的共享变量不支持自定义控件(簇)数据类型。 共享变量生命周期 如前所述,所有共享变量都是项目库的一部分。SVE将会注册项目库和库中包含的共享变量(当LabVIEW需要调用其中某个变量时)。默认情况下,只要运行引用任意所包含共享变量的VI时,SVE即会部署并发布共享变量库。由于SVE将部署包含该共享变量的整个库,因此无论所运行的VI是否引用库中的全部共享变量,SVE都将发布库中所有的共享变量。您随时可以手动部署任意项目库,只需要右键单击项目浏览器窗口的库即可。 停止VI或重启托管该变量的机器并不影响共享变量在网络上的可用性。如果需要删除网络上的共享变量,则必须明确地在项目浏览器窗口中解除该变量所属库的部署。也可选择工具(Tools) » 分布式系统管理器(Distributed System Manager)来解除共享变量或整个变量项目库的部署。 注意: 旧版LabVIEW使用变量管理器(工具[Tools] » 共享变量[Shared Variable] » 变量管理器[Variable Manager])而不是分布式系统管理器来管理共享变量的部署。 前面板数据绑定 另一个仅适用于网络发布共享变量的功能是前面板数据绑定。在项目浏览器窗口中,将共享变量拖拽到VI前面板,即可创建共享变量的绑定控件。当控件启用数据绑定时,改变控件的值将改变与其绑定的共享变量的值。在VI运行时,如果成功连接到SVE,则在VI的前面板对象旁边会出现一个绿色标记,如图16所示。 
图16.将前面板控件绑定到共享变量 通过属性(Properties)对话框中的数据绑定(Data Binding)页面,可实现和改变任意输入控件和显示控件的绑定。当使用LabVIEW Real-Time模块或LabVIEW DSC模块时,选择工具(Tools) » 共享变量(Shared Variable) » 前面板批量绑定配置(Front Panel Binding Mass Configuration),即可显示前面板批量绑定配置(Front Panel Binding Mass Configuration)对话框,然后创建一个将多个输入控件和显示控件绑定到共享变量的操作界面。 针对在LabVIEW Real-Time系统上运行的应用程序,NI不建议使用前面板数据绑定功能,因为前面板可能不存在。 编程访问 如上所述,您可以使用LabVIEW项目来交互式地创建、配置和部署共享变量,还可以使用程序框图上的共享变量节点或前面板的数据绑定来读写共享变量。LabVIEW 2009及之后版本还提供对于以上功能的编程访问。 在需要创建大量共享变量的应用中,可使用VI服务器,通过编程方式来建立项目库和共享变量。此外,LabVIEW DSC模块提供了一套全面的VI,让您能够通过编程方式来创建和编辑共享变量和项目库以及管理SVE。以编程方式创建共享变量库只能在Windows系统上实现,但通过编程来部署这些新库可在Windows或LabVIEW Real-Time系统上完成。 在需要动态更改VI读写的共享变量或需要读写大量变量的应用程序中,可使用编程共享变量API。您可以通过编程方式创建URL,然后动态更改共享变量。 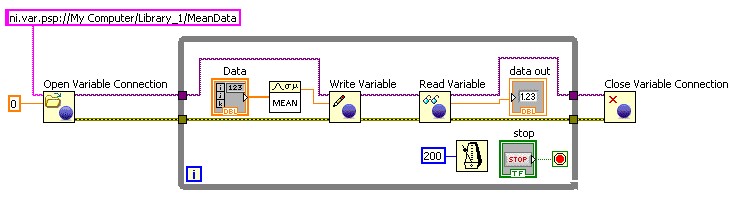
图17.使用编程共享变量API来读写共享变量 此外,由于NI LabWindows/CVI 8.1和NI Measurement Studio 8.1引入了网络变量库,您可以在ANSI C、Visual Basic .NET或者Visual C#环境下读写共享变量。 |
【本文地址】
今日新闻 |
推荐新闻 |