【论文阅读】Connecting the Dots: Document |
您所在的位置:网站首页 › labuladong插件没有思路 › 【论文阅读】Connecting the Dots: Document |
【论文阅读】Connecting the Dots: Document
|
论文地址:https://www.aclweb.org/anthology/D19-1498/ 代码地址:https://github.com/fenchri/edge-oriented-graph Background这篇paper也是解决document-level relation extraction问题,提出的模型基于以下几个发现:1. 之前很多的graph based model都是基于node的,然而作者发现entity 之间的relation,可以通过节点之间路径来形成唯一的edge representation,从而更好地得到表达;2.每一个target entity的mentions对于entity之间的relation是非常重要的。这篇paper提出的EoG模型很好地解决了这两个问题。 Abstract However, entity relations can be better expressed through unique edge representations formed as paths between nodes. We thus propose an edge-oriented graph neural model for document-level relation extraction. The model utilises different types of nodes and edges to create a document-level graph. An inference mechanism on the graph edges enables to learn intra- and inter-sentence relations using multi-instance learning internally. 1 Introduce a relation between two entities depends on different contexts. It could thus be better expressed with an edge connection that is unique for the pair. A straightforward way to address this is to create graph-based models that rely on edge representations rather focusing on node representations, which are shared between multiple entity pairs.两个实体之间的关系取决于不同的上下文。因此,它可以更好地表示为一个独特的边缘连接对。解决这个问题的一个简单方法是创建基于图的模型,该模型依赖于边表示,而不是关注节点表示,这些表示在多个实体对之间共享。 In this work, we tackle document-level, intraand inter-sentence RE using MIL with a graphbased neural model. Our objective is to infer the relation between two entities by exploiting other interactions in the document. We construct a doc- ument graph with heterogeneous types of nodes and edges to better capture different dependencies between nodes. In the proposed graph, a node corresponds to either entities, mentions, or sentences, instead of words. To achieve our objective, we design the model to be edge-oriented in a sense that it learns edge representations (between the graph nodes) rather than node representations. An iterative algorithm over the graph edges is used to model dependencies between the nodes in the form of edge representations. The intra- and inter-sentence entity relations are predicted by employing these edges. Our contributions can be summarised as follows为了实现我们的目标,我们设计了一个面向边的模型,从某种意义上说,它学习边表示(在图节点之间)而不是节点表示。利用图边上的迭代算法,以边表示的形式建立节点间的依赖关系。利用这些边预测句内和句间的实体关系。我们的贡献总结如下: 1.提出了一种新的面向边缘图的文档级关系抽取神经网络模型。该模型与现有的图模型不同,它侧重于构造唯一的节点和边,将信息编码为边表示,而不是节点表示。 2.该模型不依赖于语法依赖工具,可以在人工注释的文档级化学疾病交互数据集上实现最先进的性能。 3.对模型组件的分析表明,文档级图可以有效地编码文档级依赖关系。此外,我们还发现句间关联有助于句内关系的检测。 2 Proposed Model We build our model as a significant extension of our previously proposed sentence-level model (Christopoulou et al., 2018) for documentlevel RE.这两个模型之间最关键的区别是引入并构建了部分连接的文档图,而不是完全连接的句子级图。此外,文档图由异构类型的节点和边组成,而句子级图只包含实体节点和其中的单个边类型。此外,提出的方法利用多实例学习时,提及级注释可用。
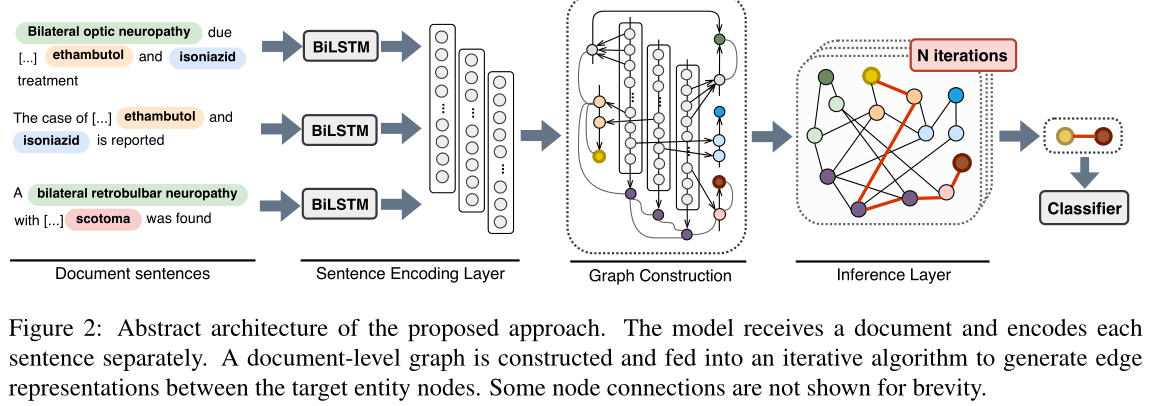
EoG模型分为四部分:sentence encdoing layer、graph construction、inference layer、classification layer。 2.1 Task Setting task definition:给定标注好的document(entity与mentions),目标是抽取出所有entity pair的relation。 2.2 Sentence Encoding Layer sentence encoding layer:doucment中的每一个sentence的word都被编码为一个vector,实际上,这样得到的是4维的张量[batch_size,nums_seqs,seq_length,embedding_dim],然后将其输送到BILSTM中进行编码,得到contxtual representation。 2.3 Graph Layer graph costruction:graph construction分为两部分:node construction与edge construction。 node construction:在EoG模型中,有三种node:mention node($n_m$)、entity node($n_e$)、sentence node($n_s$)。mention node是所有entity的mentions的集合。每一个mention node的representation是此mention的所有word embedding的平均;entity node是所有entity的集合,每一个entity node的representation是该entity所有的mentions的平均;sentence node是所有sentence的集合,每一个sentence node是该sentence中所有word embedding的平均。除此之外,我们为了区别不同类型的node,还给每一个node的representation上concat对应类型的node embedding。所以最终的表示: $n_m=[avg_{w_i∈m}(w_i);t_m]$ $n_e=[avg_{m_i∈e}(m_i);t_e]$ $n_s=[avg_{w_i∈s}(w_i);t_s]$ edge construction:有五种edge:mention-mention(MM)、mention-entity(ME)、mention-sentence(MS)、entity-sentence(ES)、sentence-sentence(SS)。MM edge,我们是连接两个在同一个sentence的两个mention,并且其表示我们是concat这两个mention本身的representation+context+两个mention的距离。Co-occurrence of mentions in a sentence might be a weak indication of an interaction.For this reason,因此 we create mentionto-mention edges only if the corresponding mentions reside in the same sentence.具体公式: $x_{MM}=[n_{m_i};n_{m_j};c_{m_j,m_j};d_{m_i,m_j}]$ $x_{MM}$表示的是对于mention pair $(m_i,m_j)$的MM edge,当i=1,j=2时,$x_{MM}=[n_{m_1};n_{m_2};c_{m_1,m_2};d_{m_1,m_2}]$,其中$c_{m_1,m_2}$的计算如下: $\alpha_{k,i}=n_{m_k}^Tw_i$ $a_{k,i}=\frac{exp(\alpha_{k,i})}{\sum_{j\in[1,n],j\notin m_k}exp(\alpha_{k,j})}$ $a_i=(a_{1,i}+a_{2,i})/2$ $c_{m_1,m_2}=H^Ta$ $k={1,2}$ where $n_{m_k}$ is a mention node representation, $w_i$ is a sentence word representation, $a_i$ is the attention weight of word $i$ for mention pair $m_1$, $m_2$,$H ∈ R^{w×d}$ is a sentence word representations matrix, $a ∈ R^w$ is the attention weights vector for the pair and $c_{m_1,m_2}$ is the final context representation for the mention pair.其中,$a_i$表示sentence的第$i$个word对此mention pair的重要性程度,也就是attention weight。 ME edge,我们连接所有的mention与其对应的entity,$x_{ME}=[n_m;n_e]$; MS edge,将mention与此mention所在的sentence node进行连接,$x_{MS}=[n_m,n_s]$ ; ES edge,如果一个sentence中至少存在一个entity的mention,那么我们将setence node与entity node进行连接,$x_{ES}=[n_e;n_s]$; SS edge:将所有的sentence node进行连接,以获得non-local information,$x_{SS}=[n_{s_i};n_{s_j};d_{s_i,s_j}]$,其中$d_{s_i,s_j}$表示两个sentence的距离vector。We connect all sentence nodes in the graph. We consider $SS_{direct}$ as direct, ordered edges直接有序边 (distance equal to 1) and $SS_{indirect}$ as indirect, non-ordered edges间接非有序边 (distance > 1) between $S$ nodes, respectively. In our setting, $SS$ denotes the combination of $SS_{direct}$ and $SS_{indirect}$. 当然了,我们最终的目的是提取出entity pair的relation,所以我们对所有的edge representation都做一个线性变换,从而让其唯独一致。即:公式(2)$e_z^{(1)}=W_zx_z$,$z∈[MM,ME,MS,ES,SS]$。where $e_z^{(1)}$ is an edge representation of length 1, $W_z∈ R^{d_z×d}$ corresponds to a learned matrix. 2.4 Inference Layer 我们使用一个迭代算法来生成图中不同节点之间的边,以及更新现有的边。我们仅使用第2.3.2节中描述的边初始化图,这意味着不存在直接实体到实体(EE)边。我们只能通过表示节点之间的路径来生成EE边表示。这意味着实体可以通过最小长度等于3的边路径进行关联。【Length 2 for an intra-sentence pair (E-S-E) or length 3 for an inter-sentence pair (E-S-S-E)】 inference layer:由于我们没有直接的EEedge,所以我们需要得到entity之间的唯一路径的表示,来产生EE edge的representation。这里使用了two-step inference mechanism来实现这一点。 the first step:利用中间节点k在两个节点i和j之间产生一条路径,如下: $f(e_{ik}^{(l)},e_{kj}^{(l)})=\sigma(e_{ik}^{(l)}\bigodot (We_{kj}^{(l)}))$ where $σ$ is the sigmoid non-linear function, $W ∈ R^{d_z×d_z}$ is a learned parameter matrix, $⊙$ refers to element-wise multiplication, $l$ is the length of the edge and $e_{ik}$ corresponds to the representation of the edge between nodes $i$ and $k$. The second step:将原始的(short)edge(如果有的话)与所有新产生的(longer)edge进行聚合,如下: $e_{ij}^{(2l)}=\beta e_{ij}^{(l)}+(1−\beta)\sum_{k≠i,j}f(e_{ik}^{(l)},e^{(l)}_{kj})$ 其中$β∈[0,1]$是控制较短边表示贡献的标量。通常,对于较短的边,β较大,因为我们期望通过两个节点之间的最短路径更好地表达两个节点之间的关系(Xu et al.,2015) 重复上述两步N次,我们就可以得到比较充分混合的EE edge。这两个步骤重复有限次N。迭代次数与边缘表示的最终长度相关。当初始边长度$l$等于1时,第一次迭代得到的边长度最多为2。第二次迭代的结果是边的长度达到4。同样,经过N次迭代后,边的长度将达到2N。实际上,这一步就是为了解决logical reasoning。 2.5 Classification Layer classification layer:这里使用softmax进行分类,因为实验所使用的两个数据集其实都是每一个entity pair都只有一个relation。具体公式: $y=softmax(W_ce_{EE}+b_c)$ where $W_c∈ R^{r×d_z}$ and $b_c∈ R^r$ are learned parameters of the classification layer and $r$ is the number of relation categories. 3 Experimental Settings Pytorch ,Adam 3.1 Data and Task Settings 数据集:CDR (BioCreative V) ,GDA (DisGeNet) 。论文 abstract 作为 document CDR:它由1500份PubMed摘要组成,分为三个大小相等的集合,用于培训、开发和测试。数据集是用化学和疾病概念之间的二元相互作用手工标注的。对于这个数据集,我们使用了PubMed预先训练的单词嵌入 GDA:包含30192篇MEDLINE摘要,分为29192篇训练文章和1000篇测试文章。该数据集在文档水平上用基因和疾病概念之间的二元相互作用进行注释,使用远程监控。概念之间的关联是通过将DisGeNet(Pi~nero et al.,2016)平台与PubMed3摘要相结合而产生的。我们进一步将培训集分成80/20的百分比,作为培训集和开发集。对于GDA数据集,我们使用了随机初始化的单词embedding。 3.2 Model Settings EoG是我们的主模型,有边{MM, ME, MS, ES, SS}。EoG (Full)设置是指图完全连接的模型,图节点之间都是连接的,包括E个节点。为此,我们为EE边缘增加了一层线性层,如式(2)所示。EoG (NoInf)设置为无推理模型,忽略迭代推理算法(第2.4节)。实体节点嵌入的连接被用来表示目标对。在这种情况下,我们还为EE边缘使用了额外的EE线性层。最后,EoG (Sent)设置指的是一个训练句子而不是文档的模型。对于每个实体层次对entity-level pair,我们使用最大假设将不同句子中提及层次对mention-level pair的预测合并:如果至少有一个提及层次mention-level pair 预测表明了一种关系,那么我们就预测实体对是相关的,类似于Gu et al.(2017)。除非另有说明,所有的设置包括节点类型嵌入,MM边的上下文嵌入和MM和SS边的距离嵌入。 4 Results
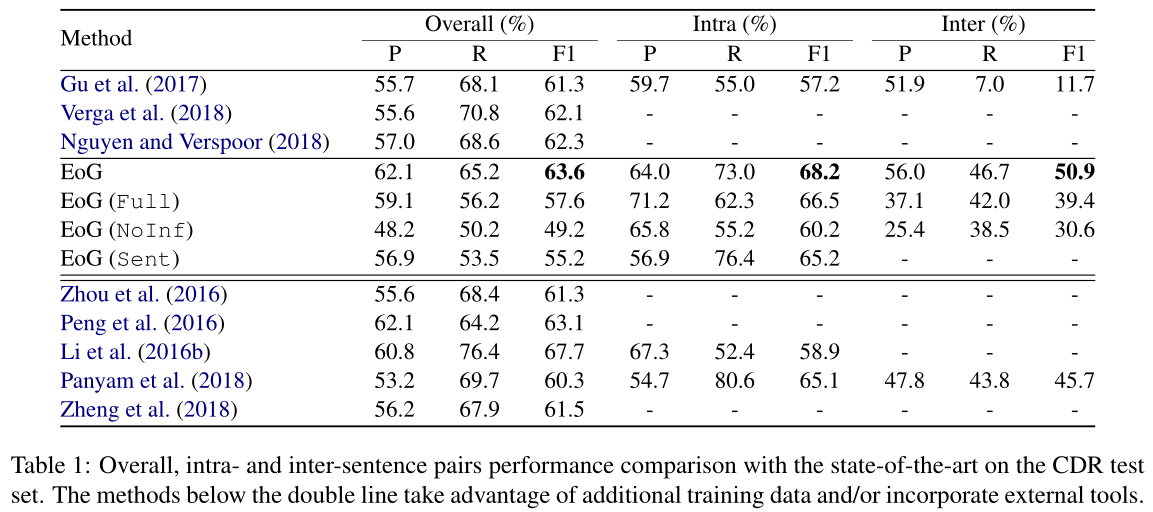
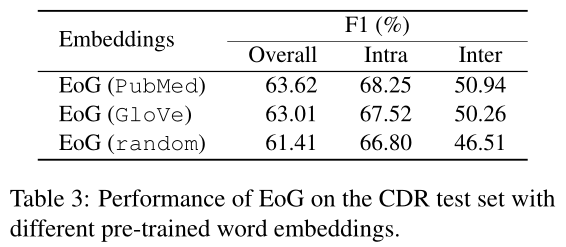
表1描述了我们提出的模型在CDR测试集上的性能,并与最先进的模型进行了比较。我们直接将我们的模型与不包含外部知识的模型进行比较。V erga et al.(2018)和Nguyen and V erspoor(2018)认为每个文档只有一对,而Gu et al.(2017)则为句内和句间对开发了单独的模型。可以观察到,该模型的总体性能比现有的CDR数据集高出1.3个百分点。我们还展示了利用语法依赖工具的方法。Li et al(2016b)使用与其他未标记训练数据的联合训练。我们的模型在句内和句间对上的表现明显更好,即使与大多数具有外部知识的模型相比,除了Li et al (2016b). 5 Analysis & Discussion 我们首先分析了使用不同预训练词嵌入的主模型(EoG)的性能。表3显示了特定领域(PubMed)(Chiu等人,2016)、通用领域(GloVe)(Pennington等人,2014)和随机初始化(随机)单词嵌入之间的性能差异。正如所观察到的,我们提出的模型与域内和域外预先训练的单词嵌入一致。随机嵌入的低性能是由于数据集太小,导致嵌入质量较低。
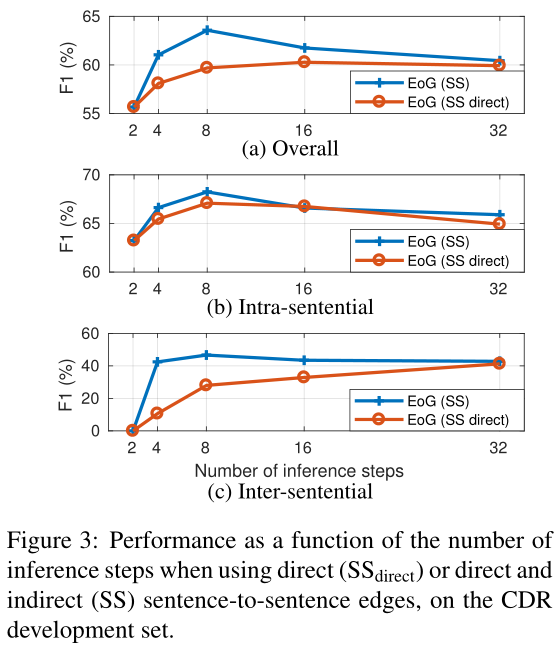
为了进一步分析,我们选择了CDR数据集,因为它是手动注释的。为了更好地分析我们模型的行为,我们分析了direct and indirect sentence-to-sentence edges的影响作为推理步骤的功能function of the inference steps。图3a、3b和3c分别说明了两个图在整体、句内和句间对中的性能。
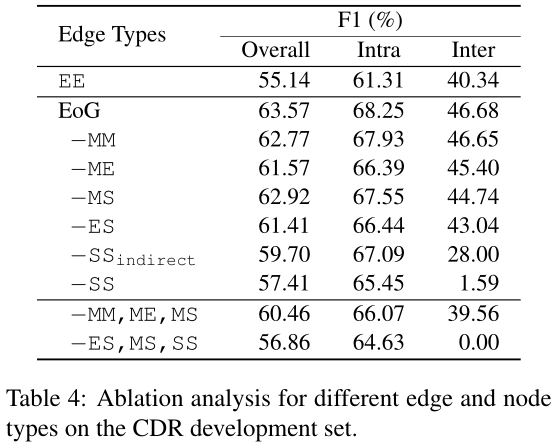
第一个观察结果是,对于推理步骤$l=8$,仅使用直接边direct edges将总体性能降低了4%。这种下降主要影响句间对inter-sentential,其中18%的点下降是观察到的。事实上,有序边ordered($SS_{direct}$)需要更长的推理时间才能更好地执行,而其他间接边($SS$)需要更少的步骤。与$SS_{direct}$Edge相比,$SS$ Edge在所有推理步骤中在句间对inter-sentence pairs 检测方面的优越性,表示在叙述中,一些中间信息并不重要。间接边indirect edges在句内对(l≤16)中的表现略好于直接边的观察结果与表1的结果一致,表1表明句间信息可以作为句内对的补充证据。 我们还对图的边和节点进行了烧蚀分析ablation analysis,如表4所示。EE边的使用只会导致对之间的性能较差。去除MM和ME边不会显著影响性能,因为ES边可以代替它们的影响。完全删除与M个节点的连接会导致较低的句间性能。这种行为指出了某些局部依赖在识别跨句关系中的重要性。
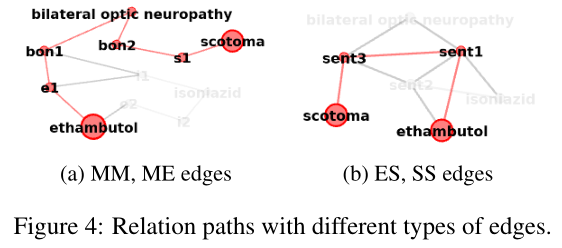
删除ES边会降低所有对的性能,因为EE边的编码变得更加困难,【Length 3 (E-M-M-E) for intra- and length 5 (E-M-S-S-M-E) for inter-sentence pairs.】我们进一步观察到,没有句子到句子连接的句子间对的识别非常差。这与该模型在没有连接到S节点的情况下无法识别任何句间对是相辅相成的。在这种情况下,我们只能通过MM和ME边识别句子中的成对词,如图4a所示。在CDR数据集中,78%的句子间成对词至少有一个参数在文档中只提到一次。这些对的识别,没有S节点,需要很长的推理路径【Minimum inference length 6 (E-M-M-E-M-M-E)】如图4b所示,S节点的引入产生了一条长度为一半的路径,我们希望它能更好地表示这种关系。较长的推理表示比较短的推理表示弱得多。这表明推理机制在识别非常复杂的关联方面能力有限。【从结果可以看到,去掉SS对结果影响巨大,这说明对于document-level RE,提取inter-sentence之间的交互信息是非常重要的,另外,MM似乎对结果影响最小,但是我认为MM对于entity pair的relation identification是非常重要的,只是EoG里面构造的方式不对,在之后的GAIN模型里面,可以看到MM对结果提升巨大,当然构建方式不一样。】
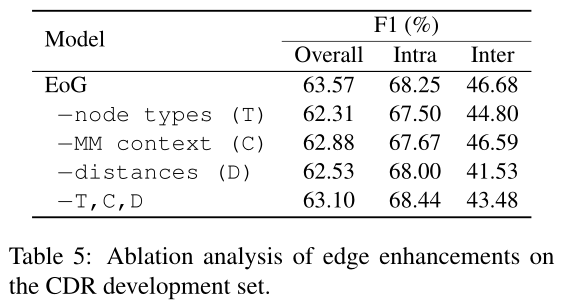
然后我们研究了表5中图边的附加增强。一般来说,句内对不受这些设置的影响。然而,对于句间对,删除节点类型嵌入和距离嵌入会导致分数下降2%和5%。这些结果表明,文档中不同元素之间的相互作用,以及句子和提及之间的距离,在句间对推理中起着重要的作用。删除所有这些设置的效果并不比删除其中一个差,这可能表示模型过拟合。我们计划进一步调查这一点,作为未来工作的一部分。
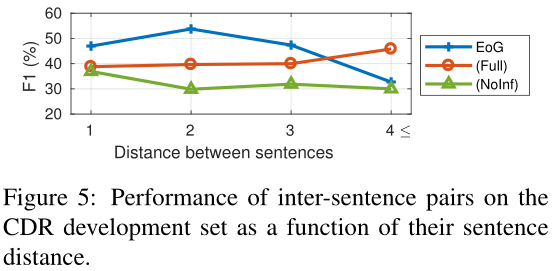
我们根据句子水平的距离来检验不同模型在句间对上的性能。图5说明了对于长距离对,EoG的性能较低,这表明很难预测它们,并且可能需要其他潜在的文档级信息(EoG(Full))
可以看到,当entity pair之间相差4句上内时,EoG(Full)结果明显要好,这说明原始的EoG忽略了一些重要节点之间的交互信息,那么能不能让模型自动选择哪些节点要交互,哪些节点不要交互呢?(在LSR就是这么做的)
最后还做了一些bad case的分析,有三种:使用and相连接的entity,model无法找到她们之间的relation;缺少coreference;3.不完全的实体链接。个人觉得EoG模型是一个非常好的开端,提供了很多思路,值得细细品读。 7 Conclusion 提出了一种基于多实例学习的面向边的图神经网络文档级关系抽取模型。该模型构造了一个具有不同类型节点和边的文档级图,同时对图边上的句内和句间对进行迭代建模。据我们所知,这是第一种利用面向边的模型进行文档级RE的方法。对句内和句间数据的分析表明,本文提出的部分连通文档图结构能够有效地编码文档元素之间的依赖关系。此外,我们推断文档级别的信息有助于识别句内对,从而获得更高的精度和分数。作为未来的工作,我们计划改进推理机制,并可能在文档图结构中加入额外的信息。我们希望这项研究能启发社区进一步研究边缘导向模型在RE和其他相关任务中的应用。 思考: 为什么用边的表示建图?作者说,传统用词作为节点,构建异质图,这样不好。因为这样在图里,只要是同样的一对节点,之间的边也是相同的。而在自然语言里,即使是相同的两个实体,在不同上下文中关系可能也不一样,所以最好是 express relation with an edge connection that is unique for the pair.某位博主的理解:作者的意思就是图不能很好地表示上下文,因为图里的点就只是关键的词,比如 entity 和 mention,因此尽管图里也有邻居的结构,也能表示一些 context 信息,但是原来文本中的其它“废话”还是被浪费了。所以,作者在构建 sentence node、mention-mention edge 的时候,都是把一大段原文信息引入了。 node representation 都直接用 word embedding 平均得到。这怎么会靠谱呢?看到有人说可以用 mask-based or structure-aware representation learning,我也不是太理解。 句子之间的联系,对于句子内的关系抽取也有帮助!
参考: 论文笔记:https://ivenwang.com/2020/12/20/eog-doc-re/ 论文笔记:https://codewithzichao.github.io/2020/10/24/NLP-RE-Integrate-GNN-into-Document-level-RE-task/#more
|

【本文地址】
今日新闻 |
推荐新闻 |