【目标检测】英雄联盟能用YOLOv5实时目标检测了 支持onnx推理 |
您所在的位置:网站首页 › labelme标签 › 【目标检测】英雄联盟能用YOLOv5实时目标检测了 支持onnx推理 |
【目标检测】英雄联盟能用YOLOv5实时目标检测了 支持onnx推理
|
目录 一、项目介绍 二、项目结构 三、准备数据 1.数据标注 2.数据转换格式 四、执行训练 1.anchors文件 2.标签文件 3.预训练模型 4.训练数据 5.修改配置 6.执行训练 五、执行预测 1.检测图片 2.检测视频 3.heatmap 五、转换onnx 1.导出onnx文件 2.检测图片 3.检测视频
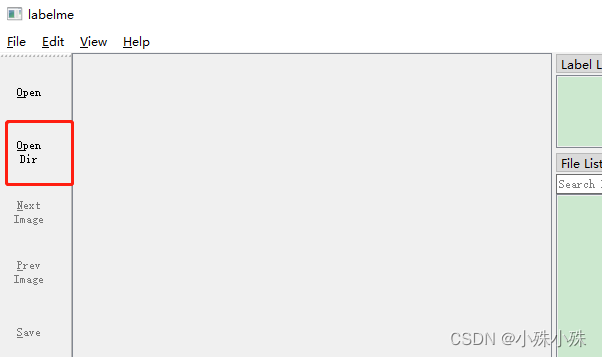
dcmyolo(dreams create miracles),中文:大聪明目标检测工具包。该项目基于pytorch搭建,构建的目的是提供一个拥有更好性能的 YOLO版本 ,同时拥有丰富的中文教程和源码细节解读,提供算法工具箱,给出不同体量模型的实验数据,为算法落地带来便利。项目本着方便开发者的目的,开箱即用,推理阶段直接将dcmyolo目录考到项目中,实例化一个类,然后调用即可。 很多教程都是基于coco和voc数据集,我也会提供基于coco数据集的预训练模型。为了增加趣味性,下面我将以检测英雄联盟中的英雄、小兵和塔为案例,仔细介绍dcmyolo的使用方法。 项目链接: https://github.com/oaifaye/dcmyolo 数据链接: https://pan.baidu.com/s/1P7dYyd5B8ofBXaQEnzYO_g 提取码:faye 测试视频: https://pan.baidu.com/s/127KmDvrXNEYXBYHHRWeizw 提取码:faye 预训练模型: https://pan.baidu.com/s/1a7uPLqBByAOgHSZfYebHaQ 提取码:faye 标注工具: https://pan.baidu.com/s/1YDrpr1SJOxL5-wpo1nlLfw 提取码:faye 效果演示: 英雄联盟能用YOLOv5实时目标检测了_英雄联盟 二、项目结构dcmyolo 项目主目录 + data 存放训练和测试的数据 - dcmyolo 实现该项目所有核心功能,移植的时候直接考这个目录就可以 - model 模型构建相关 + backbone 各种backbone,现在只有CSPdarknet,以后会继续丰富 yolo_body.py 构建模型的类,实例化后进行使用 + model_data 存放模型文件 + utils 工具类 labelme2voc.py 将labelme的json文件转换成voc格式 voc2annotation_txt.py 将VOC格式转换成项目需要的格式 make_anchors.py 生成数据集的anchors文件 train_dcmyolo.py 执行训练 export.py 导出onnx等格式的文件 predict_dcmyolo.py 推理demo predict_onnx.py pth转换onnx,onnx执行推理的demo 三、准备数据我们需要制作train.txt、val.txt、test.txt三个文件,格式如下: data/wangzhe/JPEGImages/1.jpg 910,504,1035,633,0 1759,113,1920,383,2 data/wangzhe/JPEGImages/10.jpg 805,189,1060,570,0 1,649,273,935,2 1636,70,1823,182,2 data/wangzhe/JPEGImages/100.jpg 896,258,1254,550,3 data/wangzhe/JPEGImages/101.jpg 869,416,1059,591,0 277,295,464,407,4 1024,311,1369,640,3文件中一个图片一行,一行中每段信息用空格隔开,第一段是图片存放的路径,这里我们就放在项目中的data/wangzhe/JPEGImages目录;其余的段表示框的位置和所属类别,每段中用有逗号分成5个部分,分别表示左上x,左上y,右下x,右下y,所属类别的index。 如果只有图片,没有标注,我们需要执行下面的数据标注和数据格式转换步骤,过程很简单,就是体力活。 如果使用开源数据集,我们需要自己动手把数据集的标注文件转换成如上格式,不需要下面的步骤。 如果使用我整理好的英雄联盟手游数据,下载数据后直接在项目的data目录解压缩,直接就能用,也不需要下面的步骤。 1.数据标注这一步骤用于制作自己的数据集,标注工具我们使用labelme,标注之后使用脚本将标注文件转换成voc格式,然后再从voc转换成我们需要的格式,labelme下载链接在上面,解压缩之后使用方法如下: (1)双击main.exe打开labelme
(2)选择要标注的图片目录,这里我准备了100多张英雄联盟的截图,比如放在项目中的data/wangzhe_org/目录。
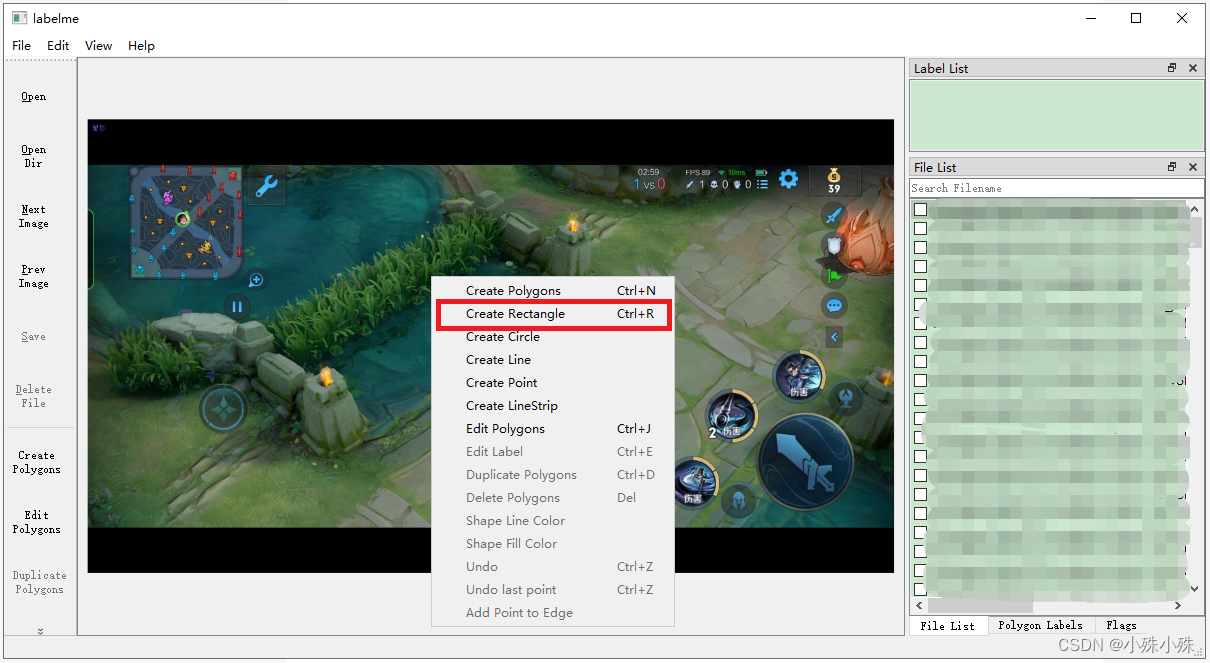
(3)该文件夹下所有的图片会列在右侧,选一张图片,右键图片区域选择矩形框
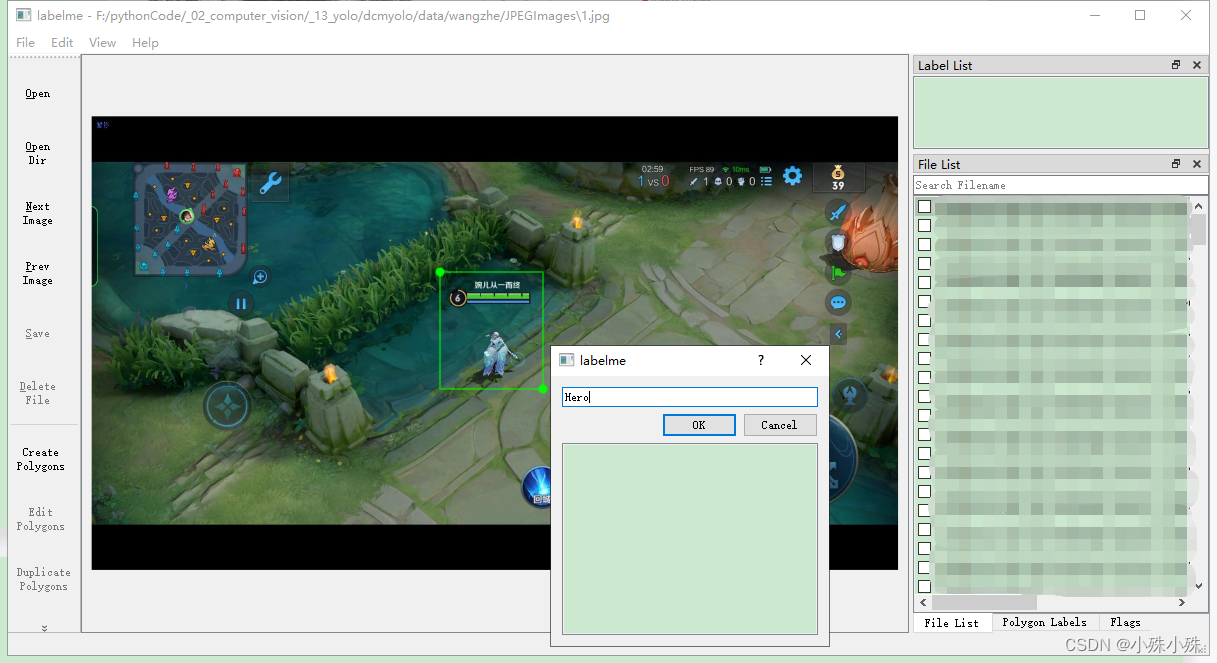
(4)用矩形框选一个目标(英雄),填入类别名称,点击OK完成一个目标的标注。注意:一定要从左上到右下进行框选;同一张图片有多少目标标注多少目标,不要遗漏;同一类别的名称必须一样,不同类别的名称不能相同;类别名称使用英文(大小写敏感),不要有标点。
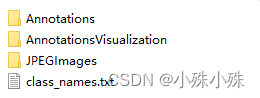
(5)标注完一张图片,选择下一个图片时会提示保存json文件,保存到默认目录即可,不要改目录。 2.数据转换格式我们已经得到了labelme生成的json格式的标准文件,我们需要先将它先转换成VOC格式,再转换成我们需要的格式。 (1)转换成VOC格式 执行项目中的labelme2voc.py文件,实例如下: ''' data/wangzhe_org/: 存放原图片和labelme生成的json文件的目录 data/wangzhe/: 目标目录 labels: 存放所有列表标签的文件,英雄联盟的数据集标签文件已经放在项目的dcmyolo/model_data/wangzhe_classes.txt文件中 ''' python labelme2voc.py data/wangzhe_org/ data/wangzhe/ --labels dcmyolo/model_data/wangzhe_classes.txt其中dcmyolo/model_data/wangzhe_classes.txt文件,共3种标签文件内容如下: Hero Solider TowerVOC格式有如下4个文件 ,Annotations存放标签文件、AnnotationsVisualization存放用框标注好的图片,方便我们检查、JPEGImages存放图片、class_names.txt存放所有类别的标签,我们接下来只使用Annotations和JPEGImages:
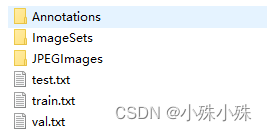
(2)转换项目需要的格式 执行项目中的voc2annotation_txt.py文件,实例如下: ''' classes_path: 存放标签种类的文件 data_dir: 存数据的目录,写到Annotations上一级 trainval_percent: 用于指定(训练集+验证集)与测试集的比例,默认情况下 9:1 train_percent: 用于指定(训练集+验证集)中训练集与验证集的比例,默认情况下 9:1 ''' python voc2annotation_txt.py --classes_path dcmyolo/model_data/wangzhe_classes.txt --data_dir data/wangzhe/ --trainval_percent 0.95 --train_percent 0.95至此我们生成了项目需要的标签文件,可以训练了。 四、执行训练所有数据文件、配置文件的文件名和目录都可以自定义,下面我将按照我的习惯存放这些文件。 1.anchors文件文件放在dcmyolo/model_data/wangzhe_classes.txt 原版的yolov5中提到的一个改进是不需要手动生成anchors,其实是在训练之前掉了一下生成anchors的方法,我更习惯手动生成anchors,也不麻烦。 anchors的作用我将在下一篇讲原理的时候提到,现在我们只管生成就好了,使用make_anchors.py生成: ''' txt_path: 标注文件txt anchors_path: anchors文件txt clusters: 聚类的数目,一般情况下是9 input_size: 模型中图像的输入尺寸 ''' python make_anchors.py --txt_path data/wangzhe/train.txt --anchors_path dcmyolo/model_data/wangzhe_anchors.txt --clusters 9 --input_size 640生成后的文件wangzhe_anchors.txt长这样: 25,44,30,58,37,64,50,68,42,91,55,104,71,113,62,141,91,256 2.标签文件文件放在dcmyolo/model_data/wangzhe_classes.txt,内容就是标签三个类别,每行一个类别: Hero Solider Tower 3.预训练模型下载预训练模型后,解压缩放在dcmyolo/model_data/。 预训练模型有两种,backbone和yolov5,backbone只是在imagenet上预训练的分类模型,yolov5是在coco数据集训练的yolov5模型。如果既加载backbone又加载yolov5的预训练模型,backbone参数将被覆盖。yolov5预训练模型包含一些backbone没有的卷积层,如果fine-tuning建议使用yolov5的预训练模型,收敛更快。 4.训练数据将上面的数据集解压缩,放到data目录即可。 如果是自己标注的数据,核心的三个文件train.txt、val.txt、test.txt放到data/wangzhe/目录,同时要保证这三个文件中的图片路径是对的就可以了,目录结构如下,其中ImageSets目录是临时目录,训练用不到,可以没有。
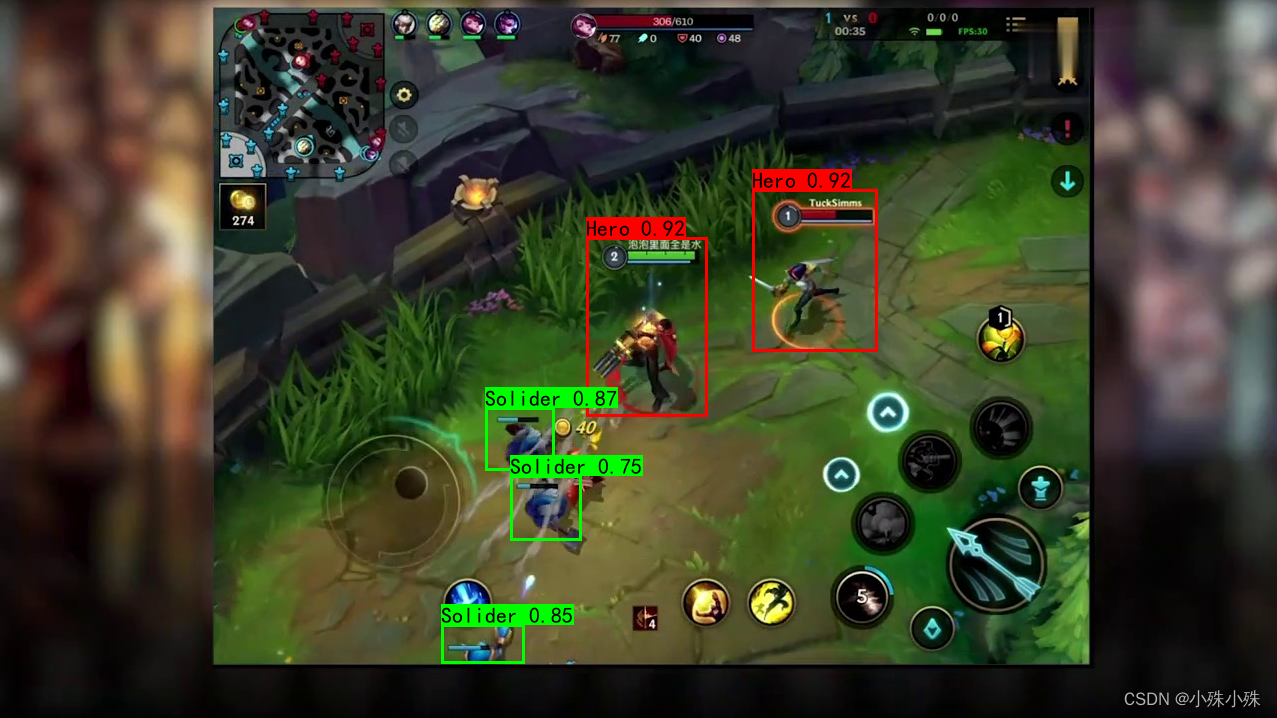
所有参数定义及注释如下,为了省地方去掉了前面的parser.add_argument: ('--classes_path', type=str, default='dcmyolo/model_data/coco_classes.txt', help="类别标签文件路径") ('--anchors_path', type=str, default='dcmyolo/model_data/coco_anchors.txt', help="anchors文件路径") ('--train_annotation_path', type=str, default='data/coco/train.txt', help="存放训练集图片路径和标签的txt") ('--val_annotation_path', type=str, default='data/coco/val.txt', help="存放验证图片路径和标签的txt") ('--phi', type=str, default='s', help="所使用的YoloV5的版本。n、s、m、l、x") # ---------------------------------------------------------------------# # --backbone_model_dir参数 # 如果有backbone的预训练模型,可以backbone预训练模型目录,当model_path不存在的时候不加载整个模型的权值。 # 只写到模型文件的上一级目录即可,文件名会根据phi自动计算(前提是从百度网盘下载的模型文件名没改) # ---------------------------------------------------------------------# ('--backbone_model_dir', type=str, default='dcmyolo/model_data/', help="backbone的预训练模型,写到上一级目录即可") ('--model_path', type=str, default='dcmyolo/model_data/pretrained.pth', help="yolov5预训练模型的路径") ('--save_period', type=int, default=10, help="多少个epoch保存一次权值") ('--save_dir', type=str, default='logs_wangzhe', help="权值与日志文件保存的文件夹") ('--input_shape', nargs='+', type=int, default=[640, 640], help="输入的shape大小,一定要是32的倍数") ('--use_fp16', action='store_true', help="是否使用混合精度训练") #------------------------------------------------------------------# # mosaic 马赛克数据增强。 # mosaic_prob 每个step有多少概率使用mosaic数据增强,默认50%。 # # mixup 是否使用mixup数据增强,仅在mosaic=True时有效。 # 只会对mosaic增强后的图片进行mixup的处理。 # mixup_prob 有多少概率在mosaic后使用mixup数据增强,默认50%。 # 总的mixup概率为mosaic_prob * mixup_prob。 # # special_aug_ratio 参考YoloX,由于Mosaic生成的训练图片,远远脱离自然图片的真实分布。 # 当mosaic=True时,本代码会在special_aug_ratio范围内开启mosaic。 # 默认为前70%个epoch,100个世代会开启70个世代。 #------------------------------------------------------------------# ('--use_mosaic', action='store_true', help="是否使用马赛克数据增强") ('--mosaic_prob', type=float, default=0.5, help="每个step有多少概率使用mosaic数据增强") ('--use_mixup', action='store_true', help="是否使用mixup数据增强,仅在mosaic=True时有效") ('--mixup_prob', type=float, default=0.5, help="有多少概率在mosaic后使用mixup数据增强") ('--special_aug_ratio', type=float, default=0.7, help="当mosaic=True时,会在该范围内开启mosaic") ('--epoch', type=int, default=100, help="总迭代次数") ('--batch_size', type=int, default=128, help="每批次取多少张图片") ('--label_smoothing', type=float, default=0, help="是否开启标签平滑") ('--init_lr', type=float, default=1e-2, help="初始学习率") ('--min_lr', type=float, default=1e-4, help="最小学习率") ('--optimizer_type', type=str, default="sgd", help="使用到的优化器种类,可选的有adam、sgd") ('--momentum', type=float, default=0.937, help="优化器内部使用到的momentum参数") ('--weight_decay', type=float, default=5e-4, help="权值衰减,可防止过拟合") ('--lr_decay_type', type=str, default="step", help="使用到的学习率下降方式,可选的有step、cos") ('--eval_flag', action='store_true', help="是否在训练时进行评估,评估对象为验证集") ('--eval_period', type=int, default=10, help="代表多少个epoch评估一次") ('--num_workers', type=int, default=4, help="多少个线程读取数据")示例脚本train_dcmyolo.sh: for i in $(ps -ax |grep train_dcmyolo |awk '{print $1}') do id=`echo $i |awk -F"/" '{print $1}'` kill -9 $id done nohup python -u train_dcmyolo.py \ --classes_path dcmyolo/model_data/wangzhe_classes.txt \ --anchors_path dcmyolo/model_data/coco_anchors.txt \ --train_annotation_path data/wangzhe/train.txt \ --val_annotation_path data/wangzhe/val.txt \ --save_dir logs_wangzhe \ --phi s \ --backbone_model_dir dcmyolo/model_data \ --model_path dcmyolo/model_data/yolov5_s.pth \ --input_shape 640 640 \ --batch_size 4 \ --epoch 1000 \ --save_period 100 \ > log_train_dcmyolo.log & tail -f log_train_dcmyolo.log 6.执行训练执行下面的脚本执行训练,训练结果会放在logs_wangzhe目录下。 ./train_dcmyolo.sh 五、执行预测推理和预测的方法都在predict_dcmyolo.py中,可以执行检测图片、检测视频和热图,所有参数定义如下,同样为了省地方,去掉了parser.add_argument: ('--operation_type', type=str, default='', help="操作类型export_onnx / predict_image / predict_video") ('--model_path', type=str, default='', help="pth模型的路径") ('--classes_path', type=str, default='', help="分类标签文件") ('--anchors_path', type=str, default='', help="anchors文件") ('--onnx_path', type=str, default='', help="onnx保存路径") ('--video_path', type=str, default='', help="视频时才会用到,视频的路径") ('--video_save_path', type=str, default='', help="视频时才会用到,视频检测之后的保存路径") ('--phi', type=str, default='', help="所使用的YoloV5的版本。n、s、m、l、x") ('--no_simplify', action='store_false', help="不使用onnxsim简化模型") ('--input_shape', nargs='+', type=int, default=[640, 640], help="输入的shape大小,一定要是32的倍数") ('--append_nms', action='store_true', help="添加nms") ('--iou_threshold', type=float, default=0.3, help="两个bbox的iou超过这个值会被认为是同一物体") ('--score_threshold', type=float, default=0.5, help="检测物体的概率小于这个值将会被舍弃") 1.检测图片检测图片,示例脚本如下: python predict_dcmyolo.py --operation_type predict_image --model_path dcmyolo/model_data/wangzhe_best_weights.pth --classes_path dcmyolo/model_data/wangzhe_classes.txt --anchors_path dcmyolo/model_data/coco_anchors.txt在控制台中输入一个图片路径,检测结果会显示出来:
测试视频可以从上方链接下载,示例脚本如下,检测结果会放在指定的输出位置: python predict_dcmyolo.py --operation_type predict_video --model_path dcmyolo/model_data/wangzhe_best_weights.pth --classes_path dcmyolo/model_data/wangzhe_classes.txt --anchors_path dcmyolo/model_data/coco_anchors.txt --video_path data/video/wangzhe1.mp4 --video_save_path_path data/video/wangzhe1_out.mp4 3.heatmap示例脚本如下: python predict_dcmyolo.py --operation_type heatmap --model_path dcmyolo/model_data/wangzhe_best_weights.pth --classes_path dcmyolo/model_data/wangzhe_classes.txt --anchors_path dcmyolo/model_data/coco_anchors.txt --heatmap_save_path data/heatmap.jpg与检测图片类似的,在控制台中输入一个图片路径,然后heatmap会显示出来。可以很明显的看到激活区域,证明模型确实很好的检测到了目标。
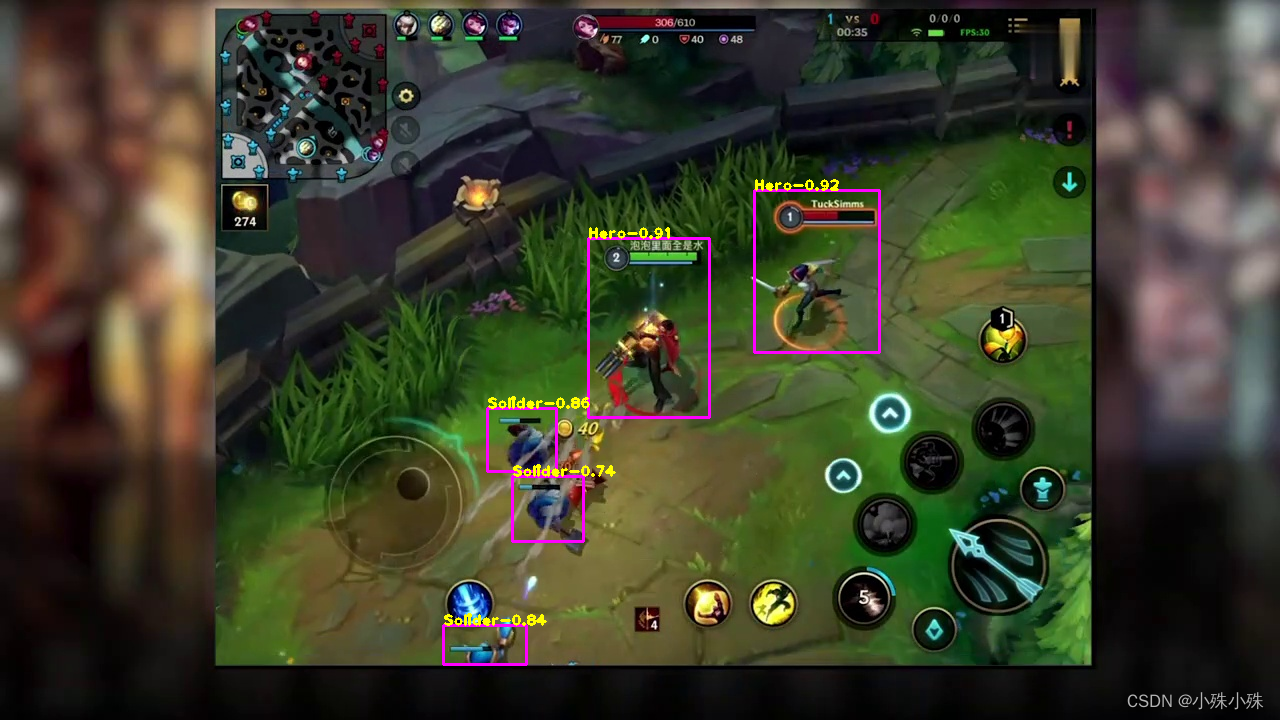
导出onnx格式的模型,有利于模型加速,方便模型部署。所有onnx相关的方法放在predict_onnx.py中。可以执行导出onnx文件、检测图片和检测视频,所有参数定义如下,同样为了省地方,去掉了parser.add_argument: ('--operation_type', type=str, default='', help="操作类型export_onnx / predict_image / predict_video") ('--model_path', type=str, default='', help="pth模型的路径") ('--classes_path', type=str, default='', help="分类标签文件") ('--anchors_path', type=str, default='', help="anchors文件") ('--onnx_path', type=str, default='', help="onnx保存路径") ('--video_path', type=str, default='', help="视频时才会用到,视频的路径") ('--video_save_path', type=str, default='', help="视频时才会用到,视频检测之后的保存路径") ('--phi', type=str, default='', help="所使用的YoloV5的版本。n、s、m、l、x") ('--no_simplify', action='store_false', help="不使用onnxsim简化模型") ('--input_shape', nargs='+', type=int, default=[640, 640], help="输入的shape大小,一定要是32的倍数") ('--append_nms', action='store_true', help="添加nms") ('--iou_threshold', type=float, default=0.3, help="两个bbox的iou超过这个值会被认为是同一物体") ('--score_threshold', type=float, default=0.5, help="检测物体的概率小于这个值将会被舍弃") 1.导出onnx文件导出的onnx建议包含nms,这样onnx输出的结果直接就能用,不需要程序再做后处理。添加 --append_nms参数就能联通nms导出了,onnx结果回报存在指定的输出路径。示例脚本如下: python predict_onnx.py --operation_type export_onnx --model_path dcmyolo/model_data/wangzhe_best_weights.pth --classes_path dcmyolo/model_data/wangzhe_classes.txt --anchors_path dcmyolo/model_data/coco_anchors.txt --onnx_path dcmyolo/model_data/wangzhe_best_weights.onnx --append_nms 2.检测图片使用onnx模型检测图片,示例脚本如下: python predict_onnx.py --operation_type predict_image --onnx_path dcmyolo/model_data/wangzhe_best_weights.onnx --classes_path dcmyolo/model_data/wangzhe_classes.txt在控制台中输入一个图片路径,检测结果会显示出来,可以看到onnx和pytorch的结果是一致的。
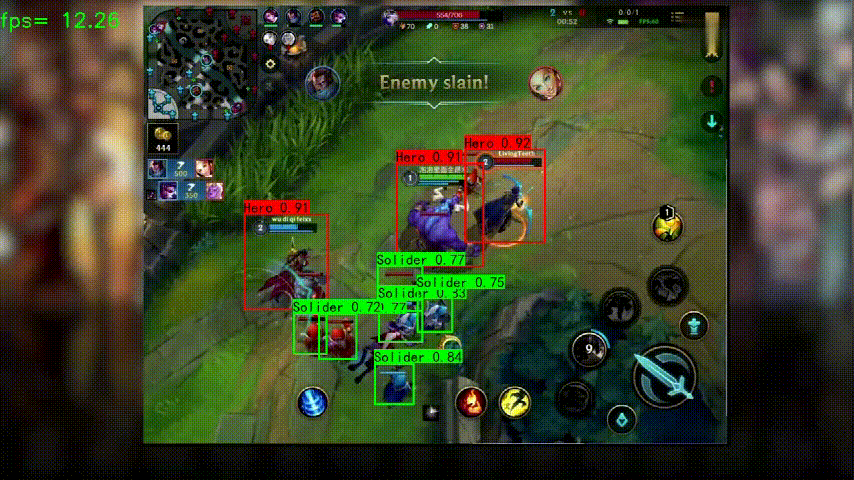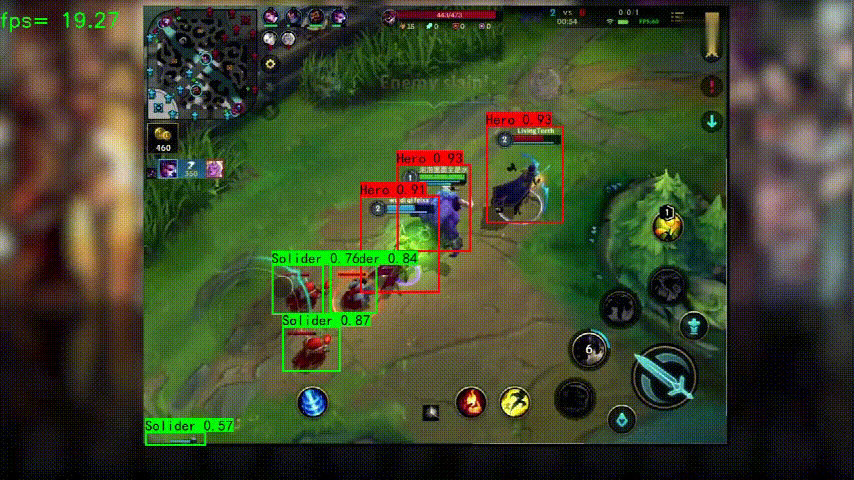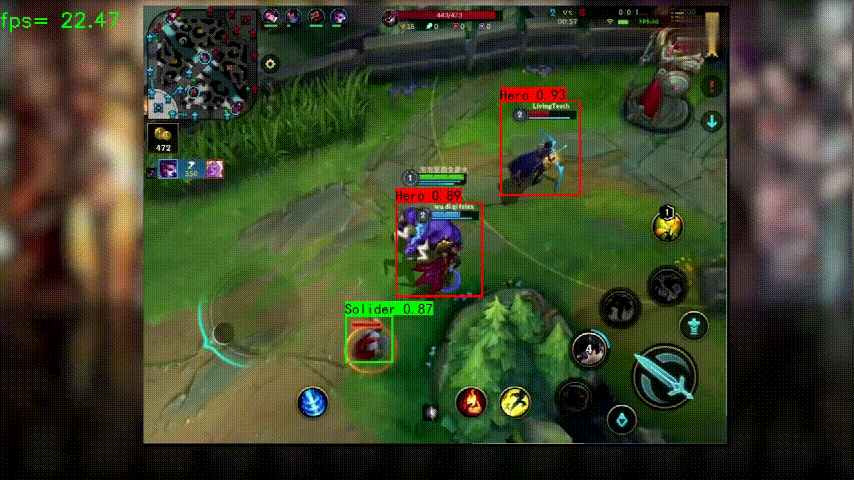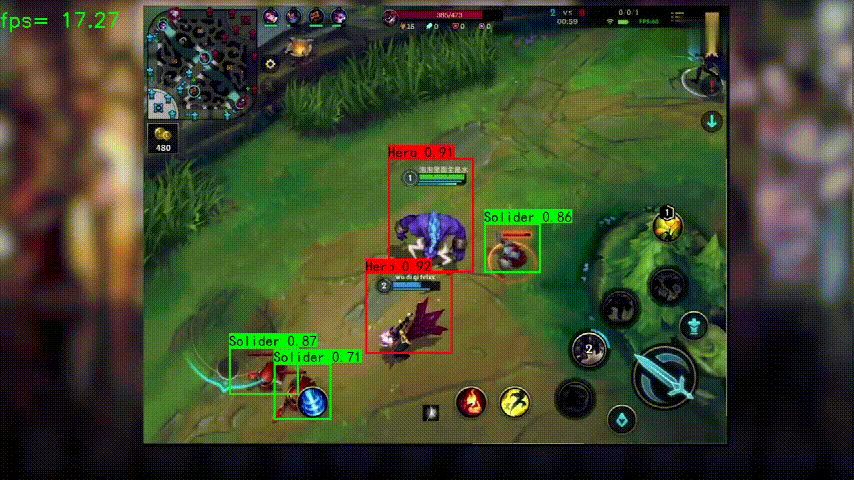
测试视频可以从上方链接下载,示例脚本如下,检测结果会放在指定的输出位置: python predict_onnx.py --operation_type predict_video --onnx_path dcmyolo/model_data/wangzhe_best_weights.onnx --classes_path dcmyolo/model_data/wangzhe_classes.txt --video_path data/video/wangzhe1.mp4 --video_save_path data/video/wangzhe1_out1.mp4
YOLOv5实时检测英雄联盟的功能就简单介绍到这里,下一篇我会介绍YOLOv5的实现原理,dcmyolo项目也会持续维护,会有越来越多的功能加入进来,敬请期待。 转载自CSDN-专业IT技术社区 版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。 原文链接:https://blog.csdn.net/xian0710830114/article/details/128011209 |


【本文地址】
今日新闻 |
推荐新闻 |