实验二 K |
您所在的位置:网站首页 › k近邻的应用 › 实验二 K |
实验二 K
|
K-近邻算法及应用
所在班级
机器学习
实验要求
作业要求
学习目标
理解K-近邻算法原理,能实现算法K近邻算法;
学号
3180701310
【实验目的】
理解K-近邻算法原理,能实现算法K近邻算法; 掌握常见的距离度量方法; 掌握K近邻树实现算法; 针对特定应用场景及数据,能应用K近邻解决实际问题。 【实验内容】实现曼哈顿距离、欧氏距离、闵式距离算法,并测试算法正确性。 实现K近邻树算法; 针对iris数据集,应用sklearn的K近邻算法进行类别预测。 针对iris数据集,编制程序使用K近邻树进行类别预测。 【实验报告要求】对照实验内容,撰写实验过程、算法及测试结果; 代码规范化:命名规则、注释; 分析核心算法的复杂度; 查阅文献,讨论K近邻的优缺点; 举例说明K近邻的应用场景。 【实验运行结果】 【实验代码及其注释】 一、距离度量利用python代码遍历三个点中,与1点距离最近的点 # 导入所需要的包 import math from itertools import combinations # 当p=1时,就是曼哈顿距离; # 当p=2时,就是欧氏距离; # 当p=inf时,就是闵式距离。 # 函数主要用于距离测算 def L(x, y, p=2): # x1 = [1, 1], x2 = [5,1] if len(x) == len(y) and len(x) > 1: sum = 0 for i in range(len(x)): sum += math.pow(abs(x[i] - y[i]), p) return math.pow(sum, 1/p) else: return 0 # 输入样例,该列来源于课本 x1 = [1, 1] x2 = [5, 1] x3 = [4, 4] # 计算x1与x2和x3之间的距离 for i in range(1, 5): # i从1到4 r = { '1-{}'.format(c):L(x1, c, p=i) for c in [x2, x3]} # 创建一个字典 print(min(zip(r.values(), r.keys()))) # 当p=i时选出x2和我x3中距离x1最近的点输出:
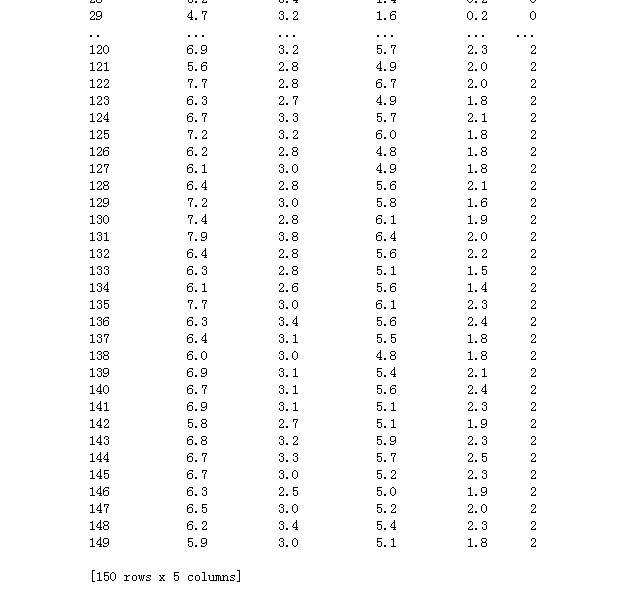
python实现,遍历所有数据点,找出n个距离最近的点的分类情况,少数服从多数(不使用直接的python中现有的K-近邻算法包) # 导包 import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from collections import Counter # data 输入数据 iris = load_iris() # 获取python中鸢尾花Iris数据集 df = pd.DataFrame(iris.data, columns=iris.feature_names) # 将数据集使用DataFrame建表 df['label'] = iris.target # 将表的最后一列作为目标列 df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label'] # 定义表中每一列 # data = np.array(df.iloc[:100, [0, 1, -1]]) df # 将建好的表显示在屏幕上查看输出:
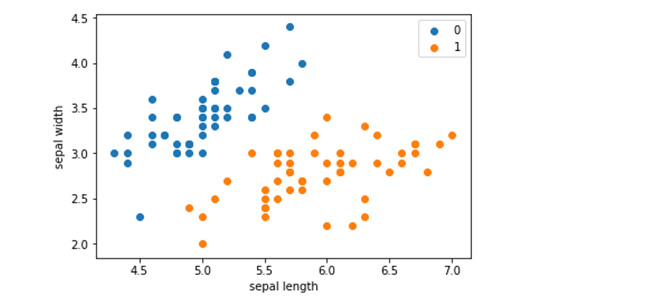
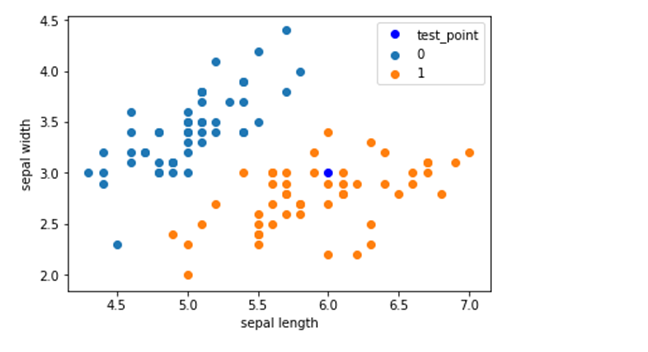
注释: train_test_split()是分离器函数,用于将数组或矩阵划分为训练集和测试集, 函数样式为:X_train, X_test, y_train, y_test = train_test_split(train_data, train_target, test_size, random_state,shuffle) train_data:待划分的样本数据 train_target:待划分的对应样本数据的样本标签 test_size: 1)浮点数,在0 ~ 1之间,表示样本占比(test_size = 0.3,则样本数据中有30%的数据作为测试数据,记入X_test,其余70%数据记入X_train, 同时适用于样本标签); 2)整数,表示样本数据中有多少数据记入X_test中,其余数据记入X_train) data = np.array(df.iloc[:100, [0, 1, -1]]) # iloc函数:通过行号来取行数据,读取数据前100行的第0,1列和最后一列 # X为data数据集中去除最后一列所形成的新数据集 # y为data数据集中最后一列数据所形成的新数据集 X, y = data[:,:-1], data[:,-1] # 选取训练集,和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2) # 建立一个类KNN,用于k-近邻的计算 class KNN: #初始化 def __init__(self, X_train, y_train, n_neighbors=3, p=2): # 初始化数据,neighbor表示邻近点,p为欧氏距离 self.n = n_neighbors self.p = p self.X_train = X_train self.y_train = y_train def predict(self, X): # X为测试集 knn_list = [] for i in range(self.n): # 遍历邻近点 dist = np.linalg.norm(X - self.X_train[i], ord=self.p) # 计算训练集和测试集之间的距离 knn_list.append((dist, self.y_train[i])) # 在列表末尾添加一个元素 for i in range(self.n, len(self.X_train)): # 3-20 max_index = knn_list.index(max(knn_list, key=lambda x: x[0])) # 找出列表中距离最大的点 dist = np.linalg.norm(X - self.X_train[i], ord=self.p) # 计算训练集和测试集之间的距离 if knn_list[max_index][0] > dist: # 若当前数据的距离大于之前得出的距离,就将数值替换 knn_list[max_index] = (dist, self.y_train[i]) # 统计 knn = [k[-1] for k in knn_list] count_pairs = Counter(knn) # 统计标签的个数 max_count = sorted(count_pairs, key=lambda x:x)[-1] # 将标签升序排列 return max_count # 计算测试算法的正确率 def score(self, X_test, y_test): right_count = 0 n = 10 for X, y in zip(X_test, y_test): label = self.predict(X) if label == y: right_count += 1 return right_count / len(X_test)11、 clf = KNN(X_train, y_train) # 调用KNN算法进行计算12、 clf.score(X_test, y_test) # 计算正确率输出:
输出:
输出:
sklearn.neighbors.KNeighborsClassifier n_neighbors: 临近点个数 p: 距离度量 algorithm: 近邻算法,可选{'auto', 'ball_tree', 'kd_tree', 'brute'} weights: 确定近邻的权重 15、 # 导包 from sklearn.neighbors import KNeighborsClassifier # 调用 clf_sk = KNeighborsClassifier() clf_sk.fit(X_train, y_train)输出:
输出:
|






【本文地址】