机器学习:k |
您所在的位置:网站首页 › knn手写识别 › 机器学习:k |
机器学习:k
|
目录 一、实战背景 二、sklearn 1、sklearn的简介 2、sklearn安装 3.sklearn实现k-近邻算法简介 三、使用sklearn实现手写数字识别 1、提供的数据是32x32的二进制图像,将其转化为1x1024的向量。编写代码如下: 2.调用sklearn.neighbors.KNeighborsClassifier实现手写数字识别 3.main函数实现 4.测试结果 四、自己用Python写k-近邻算法分类器实现 1.代码如下: 2.测试结果如下: 一、实战背景这里的手写数字数据经过图形处理,被处理成了相同颜色和大小,宽高为32x32,采用文本的格式存储图像,数字的文本格式如下图:
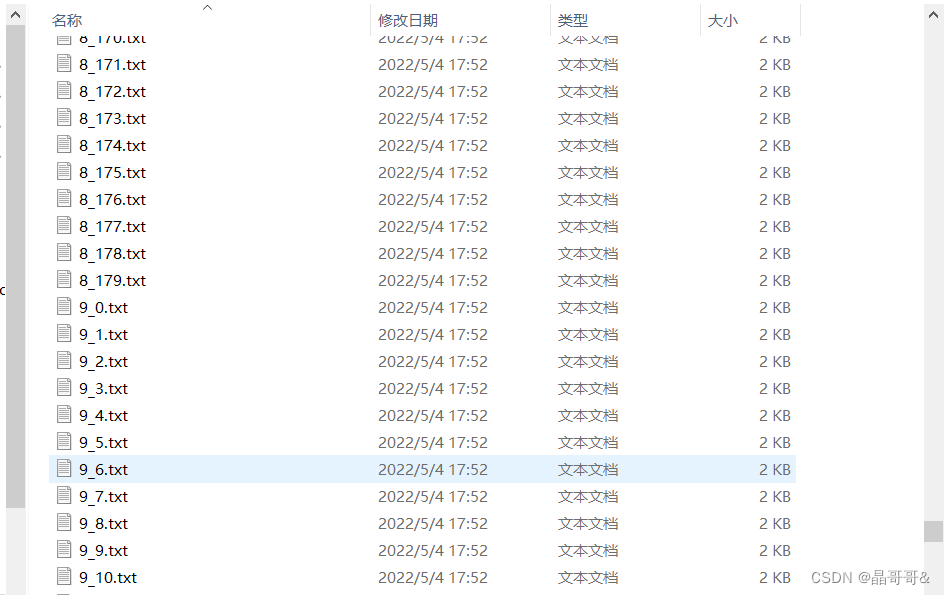
这些文本格式的数据文件的命名也有特点,格式为:数字的值_该数字的样本序号,如下图所示:
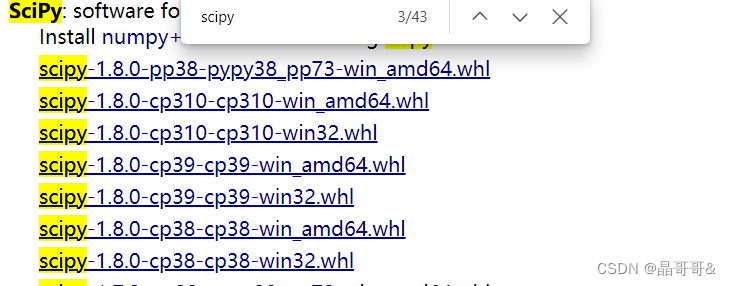
数据集的下载地址:数据集下载 对于处理好的文本,这里采用python提供的第三方库Sklearn构建手写数字系统,当然也可以用上一小节(机器学习:K-近邻算法(二)约会网站配对效果_晶哥哥&的博客-CSDN博客)的方法设计K-近邻算法分类器。 二、sklearn 1、sklearn的简介参考:手写数字识别中的sklearn简介 2、sklearn安装在安装sklearn之前需要安装两个库,即numpy+mkl和scipy,这里不建议用pip安装,第三方库的下载地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/ 在网页中找到对应的版本的numpy+mkl和scipy,Ctrl+F可以出现搜索框搜索这两个库,如下图所示
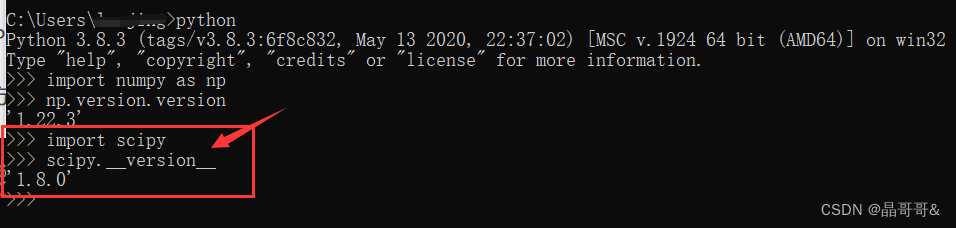
分析这里边的数字代表什么,例如 (1)1.22.3代表你python中numpy库的版本号 (2)cp38代表你python的版本号为3.8.x (3)amd64代表你电脑的位数为64 根据自己的电脑和安装的Python选择,如何查看python版本号和numpy库的版本号,看下面: 先打开cmd,然后按照下方输入
scipy中的数字理解和上边一样,这里介绍scipy的版本查看: 接着上面的cmd往下输入
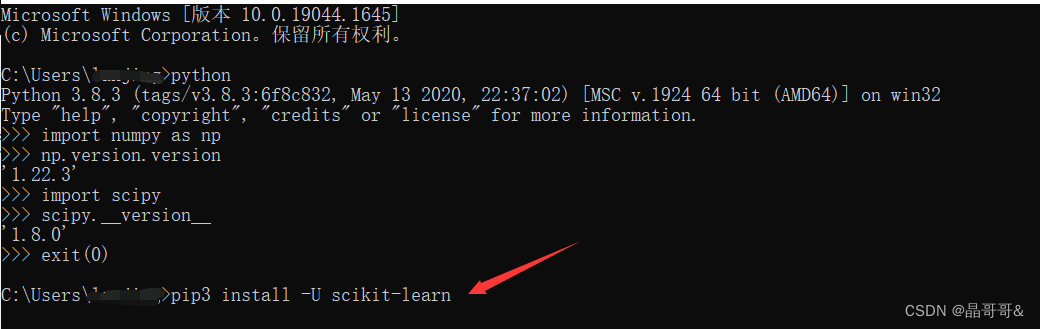
这两个.whl文件下载完成后,输入下面箭头所指的命令下载安装sklearn,这里注意,要先退出python环境,输入:exit(0),然后再输入箭头所指的命令
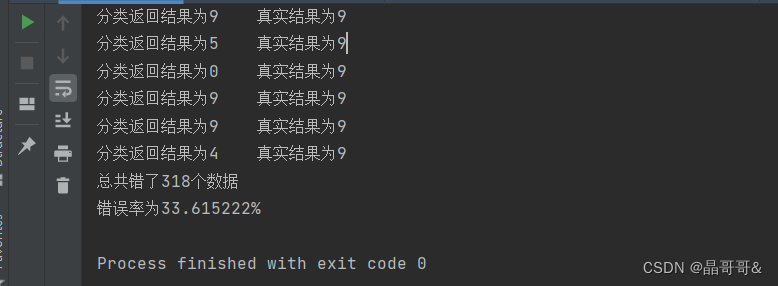
官网英文文档:英文文档 里面有sklearn.neighbors.KNeighborsClassifier参数介绍,方法介绍,可以参考这个大佬的文章介绍:参数中文介绍 三、使用sklearn实现手写数字识别 1、提供的数据是32x32的二进制图像,将其转化为1x1024的向量。编写代码如下: import numpy as np def img2vector(filename): #初始化1x1024向量 returnVect=np.zeros((1,1024)) #打开文件 file=open(filename) #将数据的每一行一次存放到向量中 for i in range(32): #读取一行数据 lineStr=file.readline() for j in range(32): returnVect[0,32*i+j]=int(lineStr[j]) #返回转换后的1x1024向量 return returnVect 2.调用sklearn.neighbors.KNeighborsClassifier实现手写数字识别编写代码如下: from sklearn.neighbor import KNeighborsClassifier as KNN from os import listdir import numpy as np def handwriteClassTest(): #获得训练集的类别labels hwLabels=[] #获取trainingDigits目录下的文件名 trainingFileList=listdir('trainingDigits') #得到文件的个数 m=len(trainingFileList) #初始化训练集矩阵 trainingMat=np.zeros((m,1024)) #从文件中解析出训练集的类别 for i in range(m): #获得文件的名字 fileNameStr=trainingFileList[i] #获得分类的数字 classNumber=int(fileNameStr.split('_')[0]) #将类别添加到类别Labels中 hwLabels.append(classNumber) #将每一个文件的数据存放到训练集中 trainingFileList[i,:]=img2vector('trainingDigits/%s'%(fileNameStr)) #构建KNN分类器,调用 neigh=KNN(n_neighbors=5,algorithm='auto') #拟合模型 neigh.fit(trainingMat,hwLabels) #获取测试集下文件 testFlieList=listdir('testDigits') #获取测试集的文件个数 mTest=len(testFileList) #错误计数器 errorCount=0.0 #从文件中获取测试集类别 for i in range(mTest): #获取文件的名字 fileNameStr=testFileList[i] #获取类别 classNumber=int(fileNameStr.split('_'[0])) #获得测试集向量1x1024 vectorUnderTest=img2vector('testDigits/%s'%(fileNameStr)) #获得预测结果 classfierResult=neigh.predict(vectorUnderTest) print('分类返回结果为%d\t真实结果为%d'%(classfierResult,classNumber)) if classfierResult!=classNumber: errorCount+=1.0 print('总共错了%d个数据,错误率为%f%%'%(errorCount,errorCount/mTest*100)) 3.main函数实现 if __name__=='__main__': handwriteClassTest() 4.测试结果
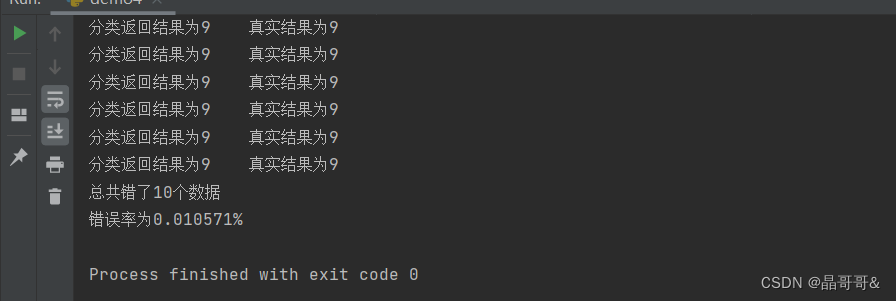
四、自己用Python写k-近邻算法分类器实现 1.代码如下: import numpy as np import operator from os import listdir ''' 函数说明:KNN算法分类器,做距离计算找出前k个距离最小的结果中最小距离分类 参数: inX---用于分类的数据,测试集 dataSet---用于训练的数据,训练集 labels--分类标签 k---KNN算法参数,选择距离最小的k个点 ''' def classify0(inX,dataSet,labels,k): #获取训练集的行数 dataSetsize=dataSet.shape[0] #矩阵相减 diffMat=np.tile(inX,(dataSetsize,1))-dataSet #平方 sqDiffMat=diffMat**2 #平方后的数据相加 sqDistances=sqDiffMat.sum(1) #开平方,得到距离 distances=sqDistances**0.5 #获取distances中元素从小到大后索引值 sortedDistIndices=distances.argsort() #初始化记录类别数的字典 classCount={} #计算前k个距离的类别个数 for i in range(k): #取出前k个元素的类别 voteIlabel=labels[sortedDistIndices[i]] #计算类别次数 classCount[voteIlabes]=classCount.get(voteIlabel,0)+1 #按照值降序排列 sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) #返回次数最多的类别 return sortedClassCount[0][0] ''' 函数说明:将32x32的二进制图像转化为1x1024向量 参数:filename----文件名 ''' def img2vector(filename): #初始化1x1024向量 returnVect=np.zeros((1,1024)) #打开文件 file=open(filename) #按行读取 for i in range(32): #读取一行 lineStr=file.readline() #将每一行数据一次存放到returnVect for j in range(32): returnVect[0,i*32+j]=int(lineStr[j]) #返回转换后的1x1024向量 return returnVect ''' 函数说明:手写数字分类测试 ''' def handwriteClassTest(): #初始化训练集labels hwLabels=[] #获取训练集文件下的文件 trainingFileList=listdir('trainingDigits') #获得文件个数 m=len(trainingFileList) #初始化训练集矩阵 trainingMat=np.zeros((m,1024)) #从文件中解析类别 for i in range(m): #获得文件名字 fileNameStr=trainingFileList[i] #获得分类的数字 classNumber=int(filenNameStr.split('_')[0]) #将获得类别添加 hwLabels.append(classNumber) #将文件的数据存储到训练集矩阵 trainingMat[i,:]=img2vector('trainingDigits/%s'%(fileNameStr)) #获得测试集文件下的文件名 testFileList=listdir('testDigits') #测试集数据的数量 mTest=len(testFileList) #错误计数 errorCount=0.0 #从文件中解析测试集的类别并进行分类 for i in range(mTest): #获得文件名 fileNameStr=testFileList[i] #获得类别数字 classNumber=int(fileNameStr.split('_')[0]) #获得测试的1x1024向量,用于训练 vectorUnderTest=img2vector('testDigits/%s'%(fileNameStr)) #获得预测结果 classifierReult=classify0(vectorUnderTest,trainingMat,hwLabels,3) print('分类返回结果%d/t真实分类结果%d'%(classifierReult,classNumber)) if classifierReult!=classNumber: errorCount+=1.0 print('总共错了%d个数据\n错误率为%f%%'%(errorCount,errorCount/mTest*100)) ''' 函数说明:main函数 ''' if __name__=='__main__': handwriteClassTest() 2.测试结果如下:
ps: k-近邻算法结束。 K-近邻算法理解遗留问题,它的缺点:无法给出数据的内在含义。不理解数据的内在含义 批注:我学习的博主Jack Cui,网址:Jack Cui | 关注人工智能及互联网的个人网站 (cuijiahua.com) 我就是看他的学习记录学习的,详细学习内容可进入他的网站学习。我写文章主要目的是为了再次熟悉代码和记录不会的知识点。 |

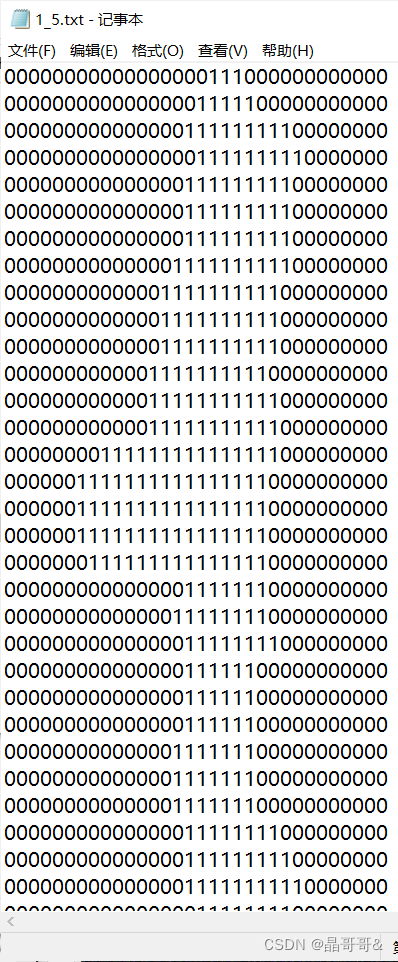


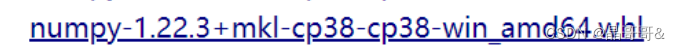

【本文地址】
今日新闻 |
推荐新闻 |