Kettle表输入表输出提升50倍的秘诀! |
您所在的位置:网站首页 › kettle优化参数 › Kettle表输入表输出提升50倍的秘诀! |
Kettle表输入表输出提升50倍的秘诀!
|
点击上方“阿拉奇学Java”,选择“置顶或者星标” 优质文章第一时间送达!
最近工作需要,需要从Oracle导数据到Mysql,并且需要进行适当的清洗,转换。数据量在5亿条左右,硬件环境为Winserver 2008R2 64位 ,64G,48核,1T hdd,kettle是8.2,从Oracle(11G,linux服务器,局域网连接)抽到mysql(5.7,本机,win server)。优化前的速度是读1000r/s(Oracle)左右,写1000r/s左右。优化后的速度是读8Wr/s(Oracle)左右,写4Wr/s左右。因为表的字段大小和类型以及是否有索引都有关系,所以总体来说,提升了20-50倍左右。 mysql 优化mysql此处只是为了迁移数据用,实际上用csv,或者clickhouse也行。但是担心csv在处理日期时可能有问题,而clickhouse不能在win下跑,而条件所限,没有多余的linux资源,而mysql第三方开源框架(不管是导入hdfs),还是作为clickhouse的外表,还是数据展示(supserset,metabase等),还是迁移到tidb,都很方便。所以最终决定用mysql。 Note:此处的mysql只做临时数据迁移用,所以可以随便重启跟修改mysqld参数。如果是跟业务混用时,需要咨询dba,确保不会影响其他业务。 mysql 安装及配置优化 下载64位 zip mysql 解压 mysql-5.7.26-winx64.zip 到目录,比如 D:\mysql-5.7.26-winx64 创建D:\mysql-5.7.26-winx64\my.ini [mysqld] port=3306 basedir=D:\mysql-5.7.26-winx64\ datadir=D:\mysql-5.7.26-winx64\data net_buffer_length=5242880 max_allowed_packet=104857600 bulk_insert_buffer_size=104857600 max_connections = 1000 innodb_flush_log_at_trx_commit = 2 # 本场景下测试MyISAM比InnoDB 提升1倍左右 default-storage-engine=MyISAM general_log = 1 general_log_file=D:\mysql-5.7.26-winx64\logs\mysql.log innodb_buffer_pool_size = 36G innodb_log_files_in_group=2 innodb_log_file_size = 500M innodb_log_buffer_size = 50M sync_binlog=1 innodb_lock_wait_timeout = 50 innodb_thread_concurrency = 16 key_buffer_size=82M read_buffer_size=64K read_rnd_buffer_size=256K sort_buffer_size=256K myisam_max_sort_file_size=100G myisam_sort_buffer_size=100M transaction_isolation=READ-COMMITTED 安装 启动mysql服务 Kettle优化 启动参数优化 本机内存较大,为了防止OOM,所以调大内存参数,创建环境变量 PENTAHO_DI_JAVA_OPTIONS = -Xms20480m -Xmx30720m -XX:MaxPermSize=1024m 起始20G,最大30G。 表输入和表输出开启多线程 表输入如果开启多线程的话,会导致数据重复。比如 select * from test ,起3个线程,就会查3遍,最后的数据就是3份。肯定不行,没达到优化的目的。 因为source是oracle,利用oracle的特性: rownum 和函数: mod ,以及kettle的参数: Internal.Step.Unique.Count,Internal.Step.Unique.Number select * from (SELECT test.*,rownum rn FROM test ) where mod(rn,${Internal.Step.Unique.Count}) = ${Internal.Step.Unique.Number}解释一下 rownum 是oracle系统顺序分配为从查询返回的行的编号,返回的第一行分配的是1,第二行是2,意味着,如果排序字段或者数据有变化的话,rownum也会变(也就是跟物理数据没有对应关系,如果要对应关系的话,应该用rowid,但是rowid不是数字,而是类似 AAAR3sAAEAAAACXAAA 的编码),所以需要对rownum进行固化,所以将 SELECT test.*,rownum rn FROM test 作为子查询。 mod 是oracle的取模运算函数,比如, mod(5,3) 意即 5%3=2 ,就是 5/3=1...2 中的2,也就是如果能获取到总线程数,以及当前线程数,取模,就可以对结果集进行拆分了。mod(行号,总线程数)=当前线程序号。 kettle 内置函数 ${Internal.Step.Unique.Count} 和 ${Internal.Step.Unique.Number} 分别代表线程总数和当前线程序号 而表输出就无所谓了,开多少线程,kettle都会求总数然后平摊的。 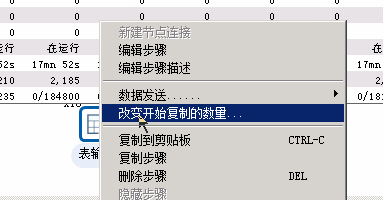
右键选择表输入或者表输出,选择 改变开始复制的数量... 注意,不是一味的调大就一定能提升效率,要进行测试的。表输入时,注意勾选替换变量 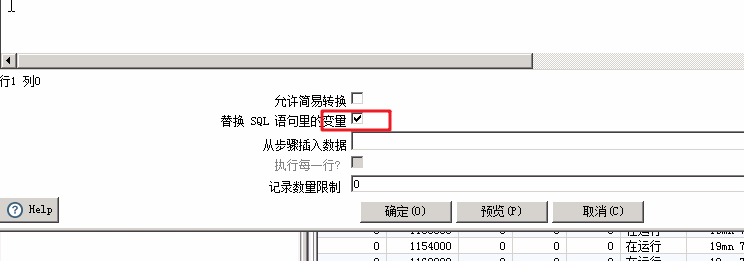
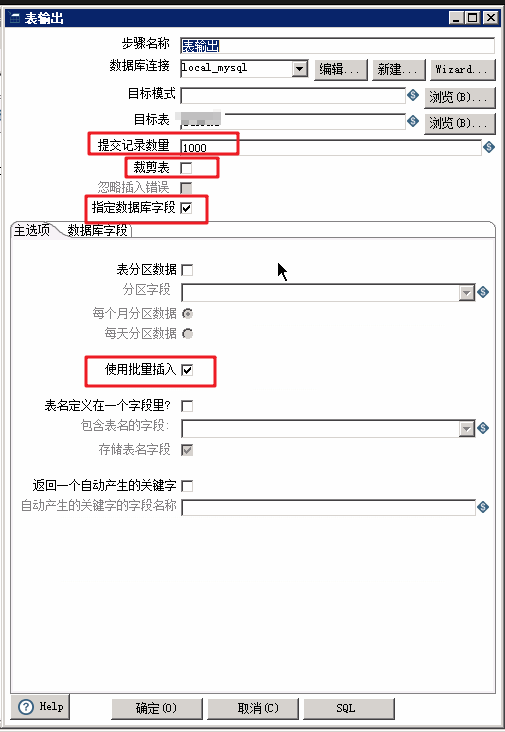 修改提交数量(默认100,但是不是越大越好)
去掉裁剪表,因为是多线程,你肯定不希望,A线程刚插入的,B给删掉。
必须要指定数据库字段,因为表输入的时候,会多一个行号字段。会导致插入失败。当然如果你在创建表时,多加了行号字段,当做自增id的话,那就不需要这一步了。
开启批量插入。
修改提交数量(默认100,但是不是越大越好)
去掉裁剪表,因为是多线程,你肯定不希望,A线程刚插入的,B给删掉。
必须要指定数据库字段,因为表输入的时候,会多一个行号字段。会导致插入失败。当然如果你在创建表时,多加了行号字段,当做自增id的话,那就不需要这一步了。
开启批量插入。
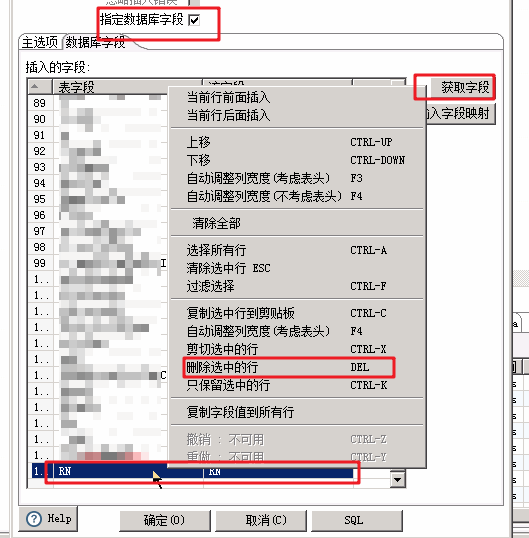
Note: 通过开启多线程,速度能提升5倍以上。 开启线程池及优化jdbc参数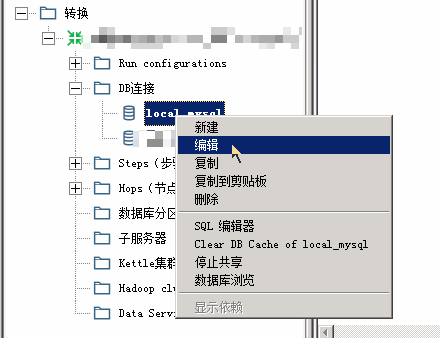
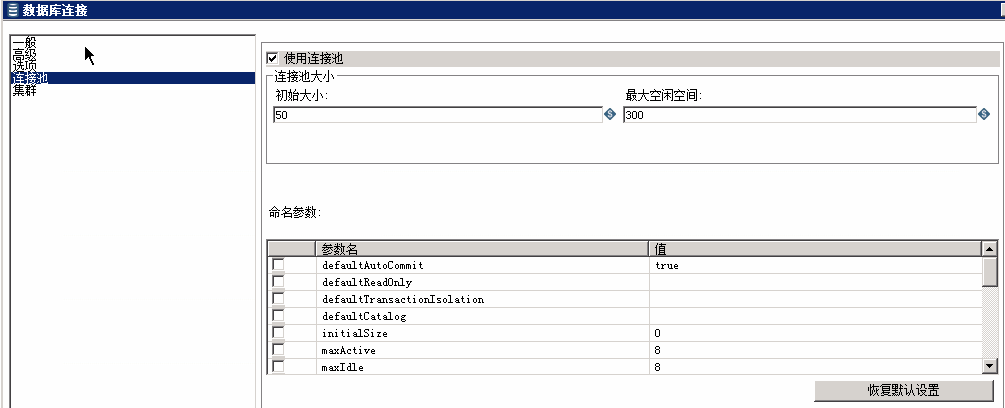
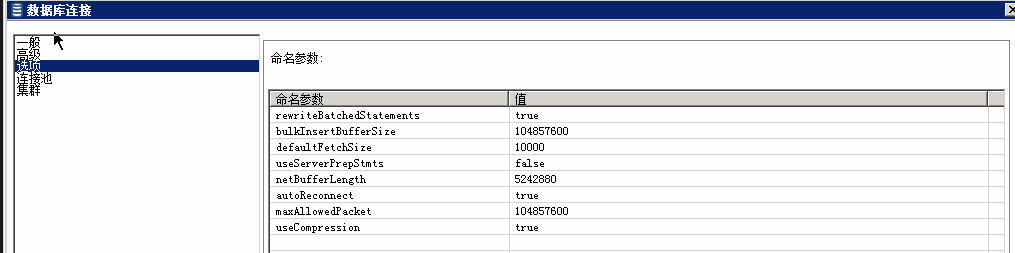 运行观察结果
运行观察结果
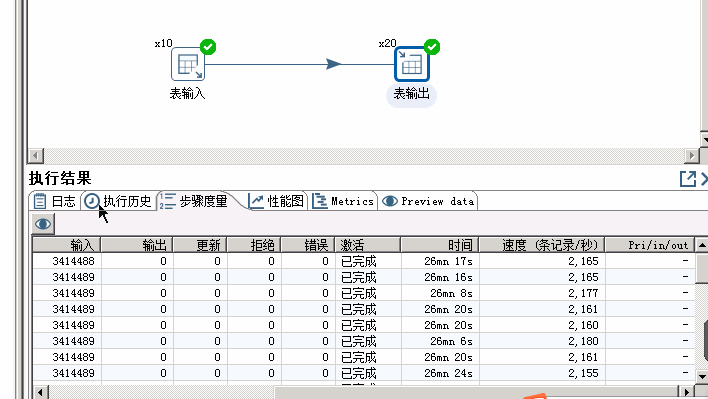
注意调整不同的参数(线程数,提交数),观察速度。 其余提升空间换ssd 继续优化mysql参数 换引擎,比如,tokudb 换抽取工具,比如streamsets,datax 换数据库,比如 clickhouse,tidb,Cassandra kettle集群 链接:https://juejin.im/post/5d0087f9f265da1bd6059cc1 看到这里啦,说明你对这篇文章感兴趣,帮忙转发一下或者点击文章右下角在看。感谢啦!关注公众号,回复「 进群 」即可进入无广告技术交流群。同时送上250本电子书+学习视频作为见面礼! 有你想看的 精彩
|
 推荐阅读 |
推荐阅读 | 

【本文地址】
今日新闻 |
推荐新闻 |