kafka |
您所在的位置:网站首页 › kafka消费者配置参数 › kafka |
kafka
|
Kafka是一种分布式的流式数据平台,广泛应用于实时流数据处理和消息系统。它可以让处理数据的应用程序能够处理高流量的数据流,同时提供可靠性和可扩展性。 【多易教育】-Kafka文档 1.基本概念 1.1什么是kafka Kafka 最初是由 LinkedIn 即领英公司基于 Scala 和 Java 语言开发的分布式消息发布-订阅系统,现已捐献给Apache 软件基金会。其具有高吞吐、低延迟的特性,许多大数据实时流式处理系统比如 Storm、Spark、Flink等都能很好地与之集成。 总的来讲,Kafka 通常具有 3 重角色: 存储系统:通常消息队列会把消息持久化到磁盘,防止消息丢失,保证消息可靠性。Kafka 的消息持久化机制和多副本机制使其能够作为通用数据存储系统来使用。 消息系统:Kafka 和传统的消息队列比如 RabbitMQ、RocketMQ、ActiveMQ 类似,支持流量削峰、服务解耦、异步通信等核心功能。 ==》 先进先出 ==》 只针对分区,不是全局的 流处理平台:Kafka 不仅能够与大多数流式计算框架完美整合,并且自身也提供了一个完整的流式处理库,即 Kafka Streaming。Kafka Streaming 提供了类似 Flink 中的窗口、聚合、变换、连接等功能。一句话概括:Kafka 是一个分布式的基于发布/订阅模式的消息中间件,在业界主要应用于大数据实时流式计算领域,起解耦合和削峰填谷的作用。
1.2kafka的特点 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, 由多个consumer group 对partition进行consume操作。 可扩展性:kafka集群支持热扩展 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失 容错性:允许集群中有节点失败(若副本数量为n,则允许n-1个节点失败) 高并发:支持数千个客户端同时读写Kafka在各种应用场景中,起到的作用可以归纳为这么几个术语:削峰填谷,解耦! 在大数据流式计算领域中,kafka主要作为计算系统的前置缓存和输出结果缓存; 2.安装部署 2.1安装zookeeper集群 上传安装包 移动到指定文件夹Plain Text mv zookeeper-3.4.6.tar.gz /opt/apps/ 解压Plain Texttar -zxvf zookeeper-3.4.6.tar.gz 修改配置文件Plain Text(1)进入到conf目录下cd /opt/apps/zookeeper-3.4.6/conf(2)修改配置文件名称mv zoo_sample.cfg zoo.cfg(3)编辑配置文件vi zoo.cfgdataDir=/opt/apps/data/zkdata server.1=linux01:2888:3888 server.2=linux01:2888:3888 server.3=linux01:2888:3888 创建数据目录Plain Textmkdir -p /opt/apps/data/zkdata 在各个节点的数据存储目录中,生成一个myid文件,内容为它的idPlain Textecho 1 > /opt/apps/data/zkdata/myidecho 2 > /opt/apps/data/zkdata/myidecho 3 > /opt/apps/data/zkdata/myid 分发安装包Plain Text# 使用for循环分发for i in {2..3}; do scp -r zookeeper-3.4.6 linux0$i:$PWD; done 配置环境变量Plain Textvi /etc/profile#ZOOKEEPER_HOMEexport ZOOKEEPER_HOME=/opt/apps/zookeeper-3.4.6export PATH=$PATH:$ZOOKEEPER_HOME/bin source /etc/profile# 注意:还需要分发环境变量 启停集群Plain Textbin/zkServer.sh start # zk服务启动bin/zkServer.sh status # zk查看服务状态bin/zkServer.sh stop # zk停止服务 一键启停脚本(1)启动脚本 Plain Text#!/bin/bashfor i in 1 2 3dossh linux0${i} "source /etc/profile;/opt/apps/zookeeper-3.4.6/bin/zkServer.sh start"done (2)停止脚本 Plain Text#!/bin/bashfor i in 1 2 3dossh linux0${i} "source /etc/profile;/opt/apps/zookeeper-3.4.6/bin/zkServer.sh stop"done 2.2安装kafka集群 上传安装包 解压Plain Texttar -zxvf kafka_2.11-2.2.2.tgz tar -C /opt/apps/ 修改配置文件Plain Text(1)进入配置文件目录[root@linux01 apps]# cd kafka_2.12-2.3.1/config (2)编辑配置文件vi server.properties #为依次增长的:0、1、2、3、4,集群中唯一 idbroker.id=0 #数据存储的⽬录 log.dirs=/opt/data/kafkadata#底层存储的数据(日志)留存时长(默认7天)log.retention.hours=168#底层存储的数据(日志)留存量(默认1G) log.retention.bytes=1073741824 #指定zk集群地址zookeeper.connect=linux01:2181,linux02:2181,linux03:2181 分发安装包Plain Textfor i in {2..3} doscp -r kafka_2.11-2.2.2 linux0$i:$PWDdone 安装包分发后,记得修改config/server.properties中的 配置参数: broker.id 环境变量Plain Textvi /etc/profileexport KAFKA_HOME=/opt/apps/kafka_2.11-2.2.2export PATH=$PATH:$KAFKA_HOME/bin source /etc/profile# 注意:还需要分发环境变量 启停集群(在各个节点上启动)Plain Textbin/kafka-server-start.sh -daemon /opt/apps/kafka_2.11-2.2.2/config/server.properties # 停止集群bin/kafka-server-stop.sh 一键启停脚本:Plain Text#!/bin/bash case $1 in "start"){ for i in linux01 linux02 linux03 do echo ---------- kafka $i 启动 ------------ ssh $i "source /etc/profile; /opt/app/kafka2.4.1/bin/kafka-server-start.sh -daemon /opt/app/kafka2.4.1/config/server.properties" done };; "stop"){ for i in linux01 linux02 linux03 do echo ---------- kafka $i 停止 ------------ ssh $i "source /etc/profile; /opt/app/kafka2.4.1/bin/kafka-server-stop.sh " done };; esac 2.3Kafka运维监控:Kafka-Eagle(了解) kafka自身并没有集成监控管理系统,因此对kafka的监控管理比较不便,好在有大量的第三方监控管理系统来使用,常见的有: Kafka Eagle KafkaOffsetMonitor Kafka Manager(雅虎开源的Kafka集群管理器) Kafka Web Console 还有JMX接口自开发监控管理系统
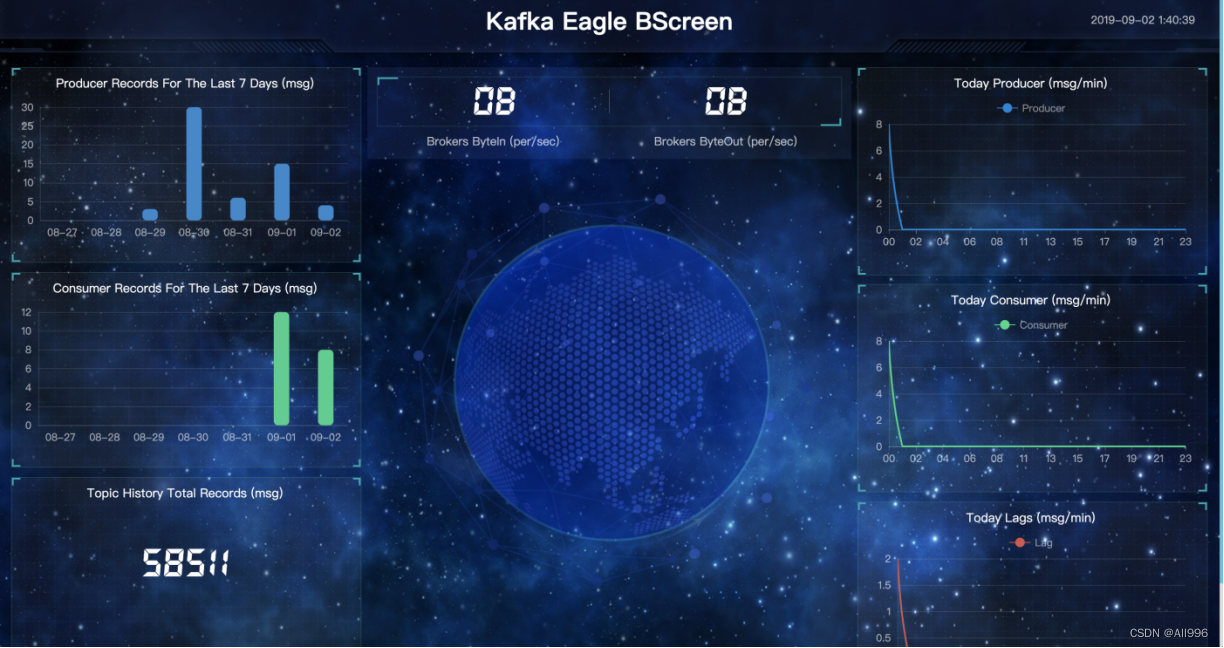
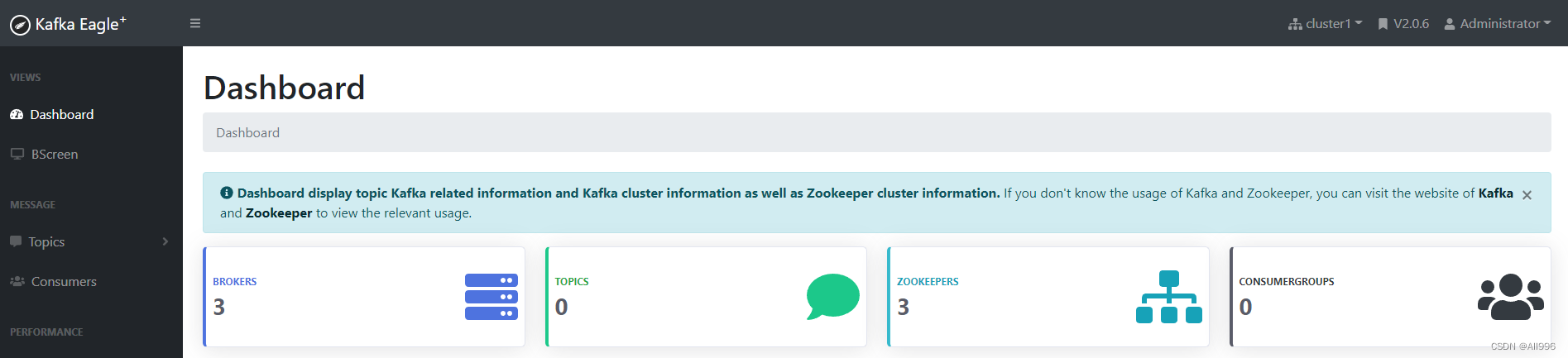
2.3.1Kafka-Eagle安装 安装包下载地址: http://download.kafka-eagle.org/ 官方文档地址:Preface - Kafka Eagle 上传,解压 配置环境变量:JAVA_HOME 和KE_HOMEPlain Textvi /etc/profile -- 之前配过了就不用再配了export JAVA_HOME=/opt/apps/jdk1.8.3_9u19export PATH=$PATH:$JAVA_HOME/binexport KE_HOME=/opt/apps/efak-web-2.1.0export PATH=$PATH:$KE_HOME/bin 配置KafkaEaglePlain Textcd ${KE_HOME}/confvi system-config.properties修改如下内容:####################################### multi zookeeper & kafka cluster list# Settings prefixed with 'kafka.eagle.' will be deprecated, use 'efak.' instead######################################efak.zk.cluster.alias=cluster1cluster1.zk.list=linux01:2181,linux02:2181,linux03:2181####################################### broker size online list######################################cluster1.efak.broker.size=3####################################### kafka sqlite jdbc driver address######################################efak.driver=org.sqlite.JDBCefak.url=jdbc:sqlite:/opt/data/kafka-eagle/db/ke.dbefak.username=rootefak.password=www.kafka-eagle.org####################################### kafka mysql jdbc driver address#######################################efak.driver=com.mysql.cj.jdbc.Driver#efak.url=jdbc:mysql://linux01:3306/ke?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull#efak.username=root#efak.password=123456 如上,数据库选择的是sqlite,需要手动创建所配置的db文件存放目录:/opt/data/kafka-eagle/db/ 如果使用MySQL 提前在mysql中创建指定的数据库 mysql> CREATE DATABASE IF NOT EXISTS ke DEFAULT CHARSET utf8 COLLATE utf8_general_ci; 配置kafka服务端的JMX端口【选配】Plaintext在kafka的启动脚本: kafka-server-start.sh 中添加如下命令:if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then export JMX_PORT="9999" export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"fi 这个加在文件的最后面 改完后,将文件同步给所有节点 然后重启kafka集群 配置KE_HOME 环境变量 启动KafkaEaglePlain Textcd ${KE_HOME}/binchmod +x ke.sh ./ke.sh start 访问web界面http://192.168.232.3:8048 账号密码:Account:admin ,Password:123456
3.基本操作 3.1概述 Kafka 中提供了许多命令行工具(位于$KAFKA HOME/bin 目录下)用于管理集群的变更。 kafka-console-consumer.sh 用于消费消息 kafka-console-producer.sh 用于生产消息 z`kafka-topics.sh 用于管理主题 kafka-server-stop.sh 用于关闭Kafka服务 kafka-server-start.sh 用于启动Kafka服务 kafka-configs.sh 用于配置管理 kafka-consumer-perf-test.sh 用于测试消费性能 kafka-producer-perf-test.sh 用于测试生产性能 kafka-dump-log.sh 用于查看数据日志内容 kafka-preferred-replica-election.sh 用于优先副本的选举 kafka-reassign-partitions.sh 用于分区重分.000000000000 配 3.2topic管理操作:kafka-topics 3.2.1查看topic列表 Shellkafka-topics.sh --bootstrap-server linux01:9092,linux02:9092,linux03:9092 --list Shell[root@linux01 bin]# ./kafka-topics.sh --list --zookeeper linux01:2181 __consumer_offsets gmall2022_db_c gmall_event_bak gmall_start_bak test001 topic_log 3.2.2查看topic状态信息 Shell[root@linux01 bin]# ./kafka-topics.sh --describe --zookeeper linux01:2181 --topic test Topic: test PartitionCount: 3 ReplicationFactor: 3 Configs: Topic: test Partition: 0 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1 Topic: test Partition: 1 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2 Topic: test Partition: 2 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
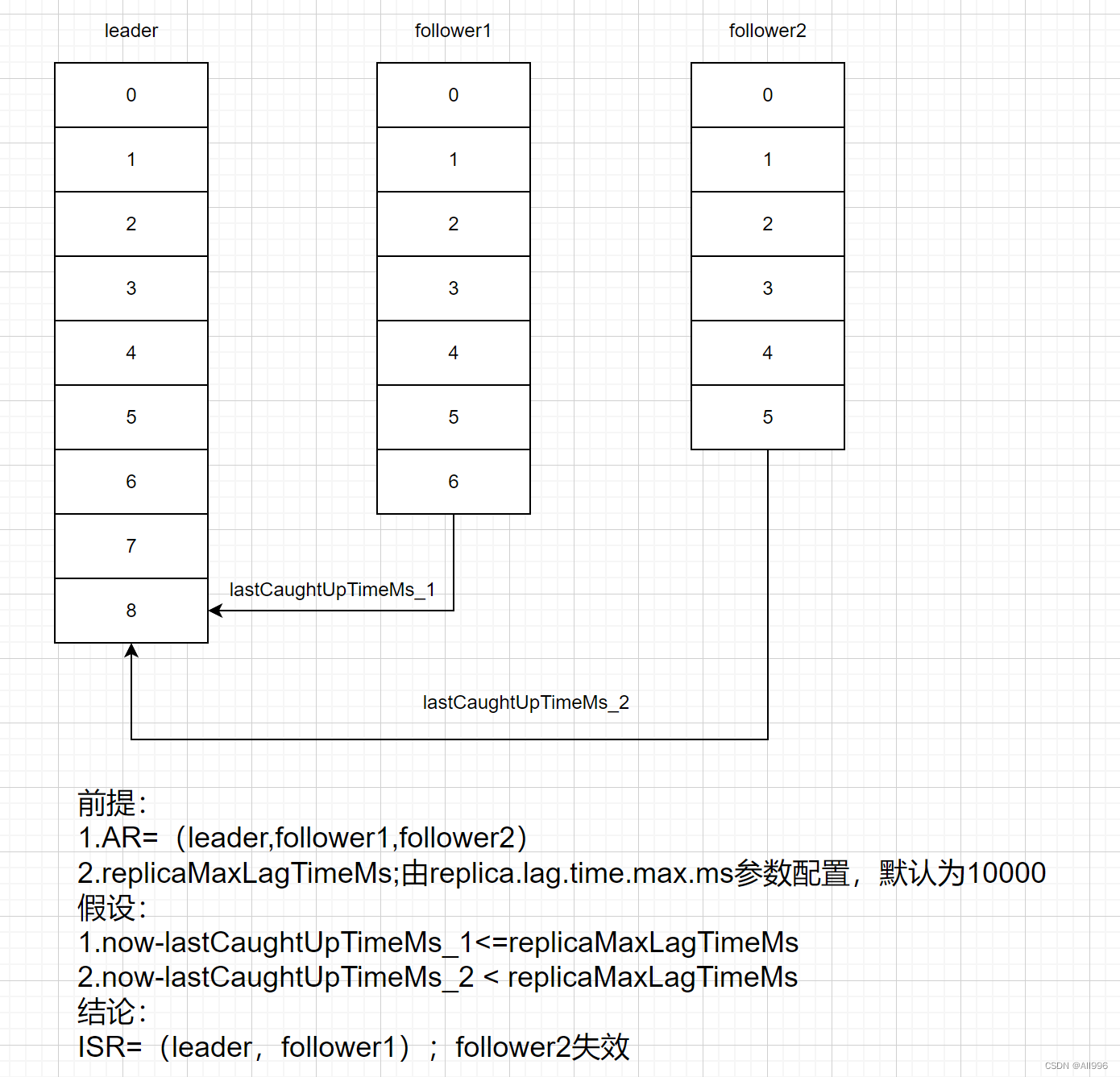
从上面的结果中可以看出 topic的分区数量,以及每个分区的副本数量,以及每个副本所在的broker节点,以及每个分区的leader副本所在broker节点,以及每个分区的ISR副本列表; ISR: in sync replica ,同步副同步本(当然也包含leader自身,replica.lag.time.max.ms =30000) OSR:out of sync replicas 失去同步的副本(该副本上次请求leader同步数据距现在的时间间隔超出配置阈值) ISR同步副本列表ISR概念:(同步副本)。每个分区的leader会维护一个ISR列表,ISR列表里面就是follower副本的Borker编号,只有跟得上Leader的 follower副本才能加入到 ISR里面,这个是通过replica.lag.time.max.ms =30000(默认值)参数配置的,只有ISR里的成员才有被选为 leader 的可能。
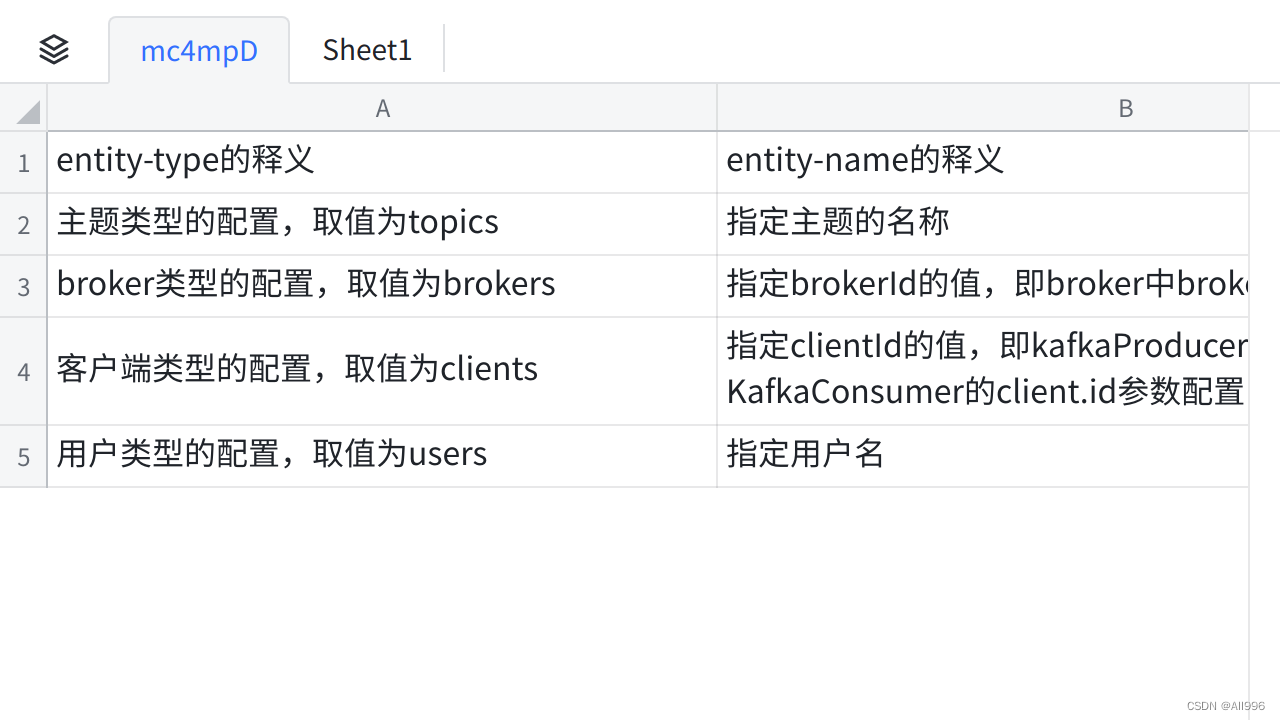
踢出ISR和重新加入ISR的条件: 踢出ISR的条件: 由replica.lag.time.max.ms =30000决定,如上图; 重新加入ISR的条件: OSR副本的LEO(log end offset)追上leader的LEO;3.2.3创建topic --bootstrap-server --zookeeper一样的效果 ,新版本建议使用 --bootstrap-server Shellkafka-topics.sh --bootstrap-server linux01:9092,linux02:9092,linux03:9092 --create --topic test01 --partitions 3 --replication-factor 3 参数解释: --replication-factor 副本数量--partitions 分区数量--topic topic名称 本方式,副本的存储位置是系统自动决定的; 手动指定分配方案:分区数,副本数,存储位置 TypeScriptkafka-topics.sh --create --topic tpc-1 --zookeeper linux01:2181 --replica-assignment 0:1:3,1:2:6该topic,将有如下partition:(2个分区 3个副本) partition0 ,所在节点: broker0、broker1、broker3 partition1 ,所在节点: broker1、broker2、broker6[root@linux01 logs]# kafka-topics.sh --describe --topic tpc-1 --zookeeper linux01:2181 Topic: tpc-1 PartitionCount: 2 ReplicationFactor: 3 Configs: Topic: tpc-1 Partition: 0 Leader: 0 Replicas: 0,1,3 Isr: 0,1 Topic: tpc-1 Partition: 1 Leader: 1 Replicas: 1,2,6 Isr: 1,2 3.2.4删除topic TypeScriptbin/kafka-topics.sh --zookeeper linux01:2181 --delete --topic test删除topic,server.properties中需要一个参数处于启用状态: delete.topic.enable = true(默认是true) 使用 kafka-topics .sh 脚本删除主题的行为本质上只是在 ZooKeeper 中的 /admin/delete_topics 路径下建一个与待删除主题同名的节点,以标记该主题为待删除的状态。然后由 Kafka控制器异步完成。 3.2.5增加分区数 Shellkafka-topics.sh --zookeeper doit01:2181 --alter --topic doitedu-tpc2 --partitions 3 Kafka只支持增加分区,不支持减少分区 原因是:减少分区,代价太大(数据的转移,日志段拼接合并) 如果真的需要实现此功能,则完全可以重新创建一个分区数较小的主题,然后将现有主题中的消息按照既定的逻辑复制过去; 3.2.6动态配置topic参数(不常用) 通过管理命令,可以为已创建的topic增加、修改、删除topic level参数 添加/修改 指定topic的配置参数:Shellkafka-topics.sh --zookeeper linux01:2181 --alter --topic tpc2 --config compression.type=gzip # --config compression.type=gzip 修改或添加参数配置# --add-config compression.type=gzip 添加参数配置# --delete-config compression.type 删除配置参数 topic配置参数文档地址: https://kafka.apache.org/documentation/#topicconfigs 3.3生产者:kafka-console-producer Shell[root@linux01 logs]# kafka-console-producer.sh --broker-list linux01:9092 --topic test01 >a >b >c >hello >hi >hadoop >hive 顺序轮询(老版本) 顺序分配,消息是均匀的分配给每个 partition,即每个分区存储一次消息,轮询策略是 Kafka Producer 提供的默认策略,如果你不使用指定的轮询策略的话,Kafka 默认会使用顺序轮训策略的方式。 随机分配 实现随机分配的代码只需要两行,如下 JavaList partitions = cluster.partitionsForTopic(topic); return ThreadLocalRandom.current().nextInt(partitions.size()); 3.4消费者:kafka-console-consumer 消费者在消费的时候,需要指定要订阅的主题,还可以指定消费的起始偏移量 起始偏移量的指定策略有3中: earliest 起始点 latest 最新 指定的offset( 分区号:偏移量) ==》 必须的告诉他是哪个topic 的哪个分区的哪个offset 从之前所记录的偏移量开始消费在命令行中,可以指定从什么地方开始消费 加上参数 --from-beginning 指定从最前面开始消费 如果不加--from-beginning 就需要分情况讨论了,如果之前记录过消费的位置,那么就从之前消费的位置开始消费,如果说之前没有记录过之前消费的偏移量,那么就从最新的位置开始消费kafka的topic中的消息,是有序号的(序号叫消息偏移量),而且消息的偏移量是在各个partition中独立维护的,在各个分区内,都是从0开始递增编号! (1)消费消息 Shell[root@linux01 logs]# kafka-console-consumer.sh --bootstrap-server linux01:9092 --topic test01 --from-beginning hive hello hadoop Plaintext-- 指定从最前面开始消费 [root@linux01 bin]# kafka-console-consumer.sh --bootstrap-server linux01:9092 --topic doitedu01 --from-beginninghadoop list hello kafka --不指定他消费的位置的时候,就是从最新的地方开始消费 [root@linux01 bin]# kafka-console-consumer.sh --bootstrap-server linux01:9092 --topic doitedu01 (2)指定要消费的分区,和要消费的起始offset Shell-- 从指定的offset(需要指定偏移量和分区号) [root@linux01 bin]# kafka-console-consumer.sh --bootstrap-server linux01:9092 --topic doitedu01 --offset 2 --partition 0 yy abc 3333 2222 (3)消费组 消费组是kafka为了提高消费并行度的一种机制! 在kafka的底层逻辑中,任何一个消费者都有自己所属的组(如果没有指定,系统会自己给你分配一个组id) 组和组之间,没有任何关系,大家都可以消费到目标topic的所有数据 但是组内的各个消费者,就只能读到自己所分配到的partitions KAFKA中的消费组,可以动态增减消费者,而且消费组中的消费者数量发生任意变动,都会重新分配分区消费任务(消费者组在均衡策略)如何让多个消费者组成一个组: 就是让这些消费者的groupId相同即可! 3.5消费位移的记录 kafka的消费者,可以记录自己所消费到的消息偏移量,记录的这个偏移量就叫(消费位移); 记录这个消费到的位置,作用就在于消费者重启后可以接续上一次消费到位置来继续往后面消费; 消费位移,是组内共享的!!!消费位置记录在一个内置的topic中 ,默认是5s提交一次位移更新。 参数:auto.commit.interval.ms 默认是5s记录一次 Shell-- 可以使用特定的工具类 解析内置记录偏移量的topic kafka-console-consumer.sh --bootstrap-server linux01:9092 --from-beginning --topic __consumer_offsets --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" 通过指定formatter工具类,来对__consumer_offsets主题中的数据进行解析; Shell[g01,doitedu01,0]::OffsetAndMetadata(offset=14, leaderEpoch=Optional[0], metadata=, commitTimestamp=1659889851318, expireTimestamp=None) [g01,doitedu01,2]::OffsetAndMetadata(offset=17, leaderEpoch=Optional[0], metadata=, commitTimestamp=1659889856319, expireTimestamp=None) [g01,doitedu01,1]::OffsetAndMetadata(offset=13, leaderEpoch=Optional[0], metadata=, commitTimestamp=1659889856319, expireTimestamp=None) [g01,doitedu01,0]::OffsetAndMetadata(offset=14, leaderEpoch=Optional[0], metadata=, commitTimestamp=1659889856319, expireTimestamp=None) 如果需要获取某个特定 consumer-group的消费偏移量信息,则需要计算该消费组的偏移量记录所在分区: Math.abs(groupID.hashCode()) % numPartitions(50) 根据组id的hash取值%50 确定具体是将这个组具体每个分区消费到了哪里 __consumer_offsets的分区数为:50 3.6配置管理 kafka-config kafka-configs.sh 脚本是专门用来进行动态参数配置操作的,这里的操作是运行状态修改原有的配置,如此可以达到动态变更的目的;一般情况下不会进行动态修改 。 动态配置的参数,会被存储在zookeeper上,因而是持久生效的 可用参数的查阅地址: https://kafka.apache.org/documentation/#configuration kafka-configs.sh 脚本包含:变更alter、查看describe 这两种指令类型; kafka-configs. sh 支持主题、 broker 、用户和客户端这4个类型的配置。 kafka-configs.sh 脚本使用 entity-type 参数来指定操作配置的类型,并且使 entity-name参数来指定操作配置的名称。 比如查看topic的配置可以按如下方式执行: Shellkafka-configs.sh --zookeeper linux01:2181 --describe --entity-type topics --entity-name doitedu01 比如查看broker的动态配置可以按如下方式执行: Shellkafka-configs.sh --describe --entity-type brokers --entity-name 0 --zookeeper linux01:2181 entity-type和entity-name的对应关系
点击图片可查看完整电子表格 示例:添加topic级别参数 Shellkafka-configs.sh --zookeeper linux01:2181 --alter --entity-type topics --entity-name doitedu01 --add-config cleanup.policy=compact,max.message.bytes=10000 示例:添加broker参数 Shellkafka-configs.sh --entity-type brokers --entity-name 0 --alter --add-config log.flush.interval.ms=1000 --bootstrap-server linux01:9092,linux02:9092,linux03:9092 动态配置topic参数 通过管理命令,可以为已创建的topic增加、修改、删除topic level参数 添加/修改 指定topic的配置参数: Shellkafka-topics.sh --topic doitedu01 --alter --config compression.type=gzip --zookeeper linux01:2181 如果利用 kafka-configs.sh 脚本来对topic、producer、consumer、broker等进行参数动态 添加、修改配置参数 Shellkafka-configs.sh --zookeeper linux01:2181 --entity-type topics --entity-name doitedu01 --alter --add-config compression.type=gzip 删除配置参数 Shellkafka-configs.sh --zookeeper linux01:2181 --entity-type topics --entity-name doitedu01 --alter --delete-config compression.type
|



【本文地址】
今日新闻 |
推荐新闻 |