Kafka Consumer位移(Offset)提交 |
您所在的位置:网站首页 › kafka消费者启动卡死 › Kafka Consumer位移(Offset)提交 |
Kafka Consumer位移(Offset)提交
|
本文目录
1.Consumer 位移(offset)1.2 位移(offset)的作用
2. 位移(offset)提交导致的问题2.1 消息丢失2.2 消息重复消费
3 Consumer位移提交方式3.1 自动提交3.2 手动同步提交3.4 手动异步提交3.5 同步异步组合提交
4 位移管理
1.Consumer 位移(offset)
消费者提交位移(offset),是消费者往一个名为_consumer_offset的特殊主题发送消息,消息中包含每个分区的位移量。它记录了 Consumer 要消费的下一条消息的位移。切记是下一条消息的位移,而不是目前最新消费消息的位移。 举个例子简单说明一下位移提交。假设一个分区中有 20 条消息,位移分别是 0 到 19。某个 Consumer 应用已消费了 10 条消息,此时Consumer 的当前的位移为20,指下一条消息(也就是第20条消息)的位移。 通过如下命令可以查某个消费组中消费者目前的偏移量 ./kafka-consumer-groups.sh --describe --bootstrap-server 192.168.235.132:9092 --group consumer.demo
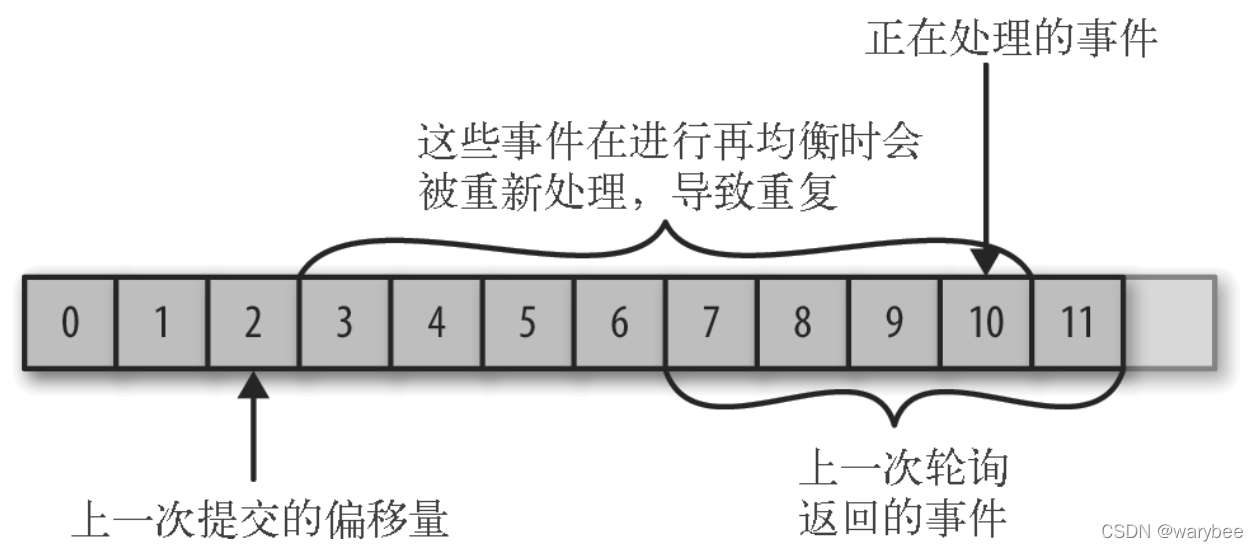
参数介绍: CURRENT-OFFSET:当前Consumer 的当前的位移值 LOG-END-OFFSET:消息最大偏移量 LAG:消息堆积的条数 1.2 位移(offset)的作用如果消费者一直运行,位移量的提交并不会产生任何影响。但是如果有消费者发生崩溃,或者有新的消费者加入消费者群组的时候,会触发 Kafka 的再均衡。这使得 Kafka 完成再均衡之后,每个消费者可能被会分到新分区中。为了能够继续之前的工作,消费者就需要读取每一个分区的最后一次提交的位移量,然后从位移量指定的地方继续处理。就好像书签一样,需要书签你才可以快速找到你上次读书的位置。 2. 位移(offset)提交导致的问题 2.1 消息丢失如果提交的偏移量大于客户端处理的最后一个消息的偏移量,那么处于两个偏移量之间的消息将会丢失。
如果提交的位移(offset)量小于消费者实际处理的最后一个消息的位移(offset)量,处于两个位移(offset)之间的消息会被重复处理。
鉴于位移提交甚至是位移管理对 Consumer 端的巨大影响, KafkaConsumer API,提供了多种提交位移的方式。 3 Consumer位移提交方式 从用户的角度来说,位移提交分为自动提交和手动提交;从 Consumer 端的角度来说,位移提交分为同步提交和异步提交。 3.1 自动提交自动提交是KafkaConsumer API中的默认提交方式。 自动提交,需要配置两个参数: enable.auto.commit=true 的时候代表自动提交位移。auto.commit.interval.ms=50000 auto.commit.interval.ms默认值是5s,即kafka每隔5s会帮你自动提交一次位移。自动位移提交的动作是在 poll()方法的逻辑里完成的,在每次真正向服务端发起拉取请求之前会检查是否可以进行位移提交,如果可以,那么就会提交上一次轮询的位移。假如消费数据量特别大,可以设置的短一点。 //设置自动提交enable.auto.commit=true,(enable.auto.commit默认为就是true) configs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true); //配置自动提交间隔 configs.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,3000);完整消费者代码: public static void main(String[] args) { Map configs = new HashMap(); // 设置连接Kafka的初始连接用到的服务器地址 // 如果是集群,则可以通过此初始连接发现集群中的其他broker configs.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "http://192.168.235.132:9092"); //KEY反序列化类 configs.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.IntegerDeserializer"); //value反序列化类 configs.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer"); configs.put(ConsumerConfig.GROUP_ID_CONFIG, "consumer.demo"); configs.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest"); //设置自动提交enable.auto.commit=true,(enable.auto.commit默认为就是true) configs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true); //配置自动提交间隔 configs.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,3000); //创建消费者对象 KafkaConsumer consumer = new KafkaConsumer(configs); List topics = new ArrayList(); topics.add("test_topic_1"); //消费者订阅主题 consumer.subscribe(topics); while (true){ //批量拉取主题消息,每3秒拉取一次 ConsumerRecords records = consumer.poll(3000); //变量消息 for (ConsumerRecord record : records) { System.out.println(record.value()); } consumer.commitAsync(); } //关闭消费者 } 3.2 手动同步提交手动提交,则是指你要自己提交位移,Kafka Consumer 压根不管。 开启手动提交,把enable.auto.commit=false,用commitSync()提交由poll方法返回的最新偏移量。该方法为同步操作,等待直到 offset 被成功提交才返回。 //设置手动提交 configs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false); //创建消费者对象 KafkaConsumer consumer = new KafkaConsumer(configs); List topics = new ArrayList(); topics.add("test_topic_1"); //消费者订阅主题 consumer.subscribe(topics); while (true){ //批量拉取主题消息,每3秒拉取一次 ConsumerRecords records = consumer.poll(3000); //变量消息 for (ConsumerRecord record : records) { System.out.println(record.value()); } //consumer.commitSync(); //设置间隔多久提交一次 consumer.commitSync(Duration.ofSeconds(2)); }手动同步提交会 调用 commitSync方法 时,Consumer 处于阻塞状态,直到 Broker 返回结果,这样就会限制应用程序的吞吐量。虽然可以通过降低提交频率来提升吞吐量,但一旦发生再均衡,会增加重复消息的数量。 3.4 手动异步提交异步提交使用 commitAsync();方法。 //设置手动提交 configs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false); //创建消费者对象 KafkaConsumer consumer = new KafkaConsumer(configs); List topics = new ArrayList(); topics.add("test_topic_1"); //消费者订阅主题 consumer.subscribe(topics); while (true){ //批量拉取主题消息,每3秒拉取一次 ConsumerRecords records = consumer.poll(3000); //变量消息 for (ConsumerRecord record : records) { System.out.println(record.value()); } // consumer.commitAsync(); }异步提交回调函数 consumer.commitAsync(new OffsetCommitCallback() { @Override public void onComplete(Map offsets, Exception exception) { } }); 3.5 同步异步组合提交如果提交失败发生在关闭消费者或者再均衡前的最后一次提交,那么就要确保提交能够成功。这个时候就需要使用同步异步组合提交。 //设置自动提交enable.auto.commit=true,(enable.auto.commit默认为就是true) configs.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,true); //配置自动提交间隔 configs.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,3000); //创建消费者对象 KafkaConsumer consumer = new KafkaConsumer(configs); List topics = new ArrayList(); topics.add("test_topic_1"); //消费者订阅主题 consumer.subscribe(topics); try { while (true){ //批量拉取主题消息,每3秒拉取一次 ConsumerRecords records = consumer.poll(3000); //变量消息 for (ConsumerRecord record : records) { System.out.println(record.value()); } //异步提交 consumer.commitAsync(); } }catch (Exception exception){ handle(exception); // 处理异常 }finally { consumer.commitSync(); // 最后一次提交使用同步阻塞式提交 consumer.close(); } 4 位移管理Kafka中,消费者根据消息的位移顺序消费消息。 消费者的位移由消费者管理,可以存储于zookeeper中,也可以存储于Kafka主题 __consumer_offsets中。 Kafka Clients提供了消费者API,让消费者可以管理自己的位移。 public void assign(Collection partitions)给当前消费者手动分配一系列主题分区。 手动分配分区不支持增量分配,如果先前有分配分区,则该操作会覆盖之前的分配。 如果给出的主题分区是空的,则等价于调用unsubscribe方法。 手动分配主题分区的方法不使用消费组管理功能。当消费组成员变了,或者集群或主题的 元数据改变了,不会触发分区分配的再平衡。 手动分区分配assign(Collection)不能和自动分区分配subscribe(Collection, ConsumerRebalanceListener)一起使用。 如果启用了自动提交偏移量,则在新的分区分配替换旧的分区分配之前,会对旧的分区分 配中的消费偏移量进行异步提交。 public Set assignment() 获取给当前消费者分配的分区集合。如果订阅是通过调用assign方法直接分配主题分区, 则返回相同的集合。如果使用了主题订阅,该方法返回当前分配给该消费者的主题分区集 合。如果分区订阅还没开始进行分区分配,或者正在重新分配分区,则会返回none。 public Map> listTopics() 获取对用户授权的所有主题分区元数据。该方法会对服务器发起远程调用。 public List partitionsFor(String topic) 获取指定主题的分区元数据。如果当前消费者没有关于该主题的元数据,就会对服务器发 起远程调用。 public Map beginningOffsets(Collection partitions) 对于给定的主题分区,列出它们第一个消息的偏移量。 注意,如果指定的分区不存在,该方法可能会永远阻塞。 该方法不改变分区的当前消费者偏移量。 public void seekToEnd(Collection partitions) 将偏移量移动到每个给定分区的最后一个。 该方法延迟执行,只有当调用过poll方法或position方法之后才可以使用。 如果没有指定分区,则将当前消费者分配的所有分区的消费者偏移量移动到最后。 如果设置了隔离级别为:isolation.level=read_committed,则会将分区的消费偏移量移动 到最后一个稳定的偏移量,即下一个要消费的消息现在还是未提交状态的事务消息。 public void seek(TopicPartition partition, long offset) 将给定主题分区的消费偏移量移动到指定的偏移量,即当前消费者下一条要消费的消息偏 移量。 若该方法多次调用,则最后一次的覆盖前面的。 如果在消费中间随意使用,可能会丢失数据。 public long position(TopicPartition partition) 检查指定主题分区的消费偏移量 public void seekToBeginning(Collection partitions) 将给定每个分区的消费者偏移量移动到它们的起始偏移量。该方法懒执行,只有当调用过 poll方法或position方法之后才会执行。如果没有提供分区,则将所有分配给当前消费者的 分区消费偏移量移动到起始偏移量。 参考文章: https://segmentfault.com/a/1190000022949840https://www.cnblogs.com/fnlingnzb-learner/p/13429705.html |


【本文地址】
今日新闻 |
推荐新闻 |