kafka分区策略 |
您所在的位置:网站首页 › kafka指定分区生产 › kafka分区策略 |
kafka分区策略
|
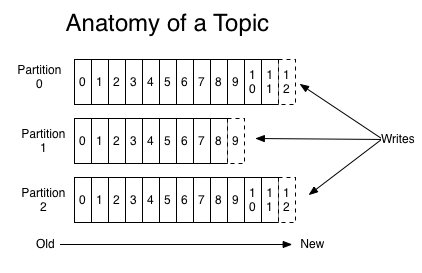
为什么分区? kafka有topic的概念,它是承载真实数据的逻辑容器,而在主题之下还分为若干个分区,也就是说kafka的消息组织方式实际上是三级结构:主题-分区-消息。主题下的每条消息只会保存在某个分区中,而不会在多个分区中被保存多份。
其实分区的作用就是提供负载均衡的能力,不同的分区能够被放置在不同节点的机器上,而数据的读写操作也都是针对分区这个粒度进行的,这样每个节点的机器都能够独立地执行各自分区的读写请求处理。并且,我们还可以通过添加新的节点机器来增加整体系统的吞吐量。 分区策略 所谓的分区策略是决定生产者将消息发送到哪个分区的算法。 如果要自定义分区策略,你需要显示地配置生产者端的参数partitioner.class。 package kafka; import org.apache.kafka.clients.producer.KafkaProducer; import java.util.Properties; public class KafkaProduce { public void kafkaProducer() throws Exception { Properties pro = new Properties(); ......// 其他配置 pro.put("partitioner.class", "kafka.KafkaPartitioner"); KafkaProducer config = new KafkaProducer(pro); } }轮询策略 也称Round-robin策略,即顺序分配。比如一个topic下有3个分区,那么第一条消息被发送到分区0,第二条被发送到分区1,第三条被发送到分区2,以此类推。当生产第四条消息时又会重新开始。
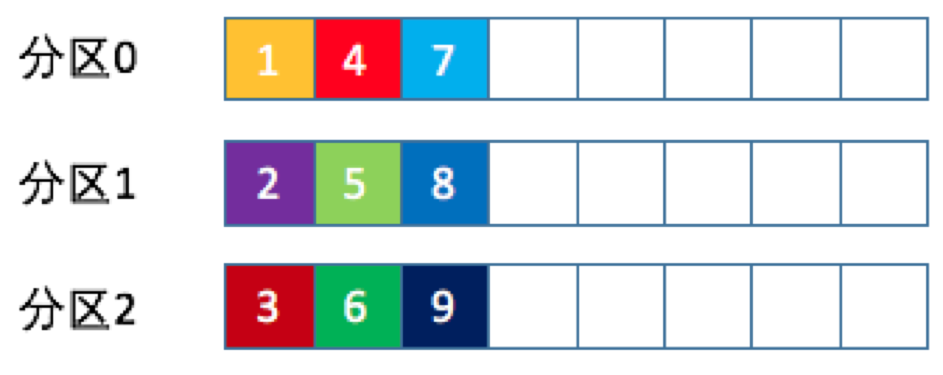
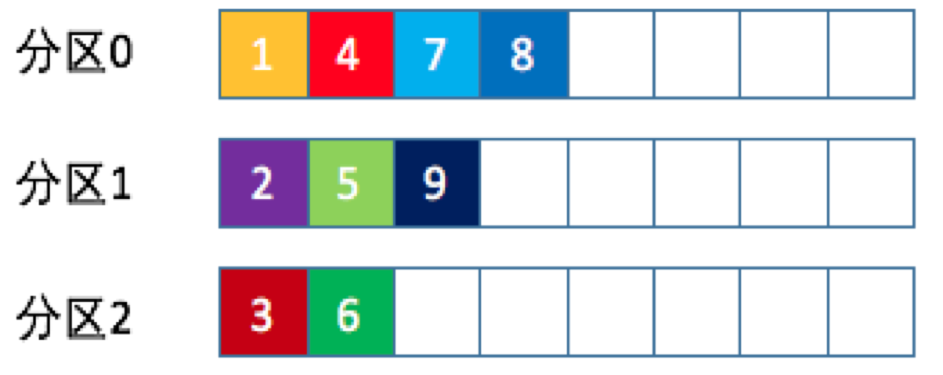
这就是所谓的轮询策略。轮询策略是kafka java生产者API默认提供的分区策略。轮询策略有非常优秀的负载均衡表现,它总是能保证消息最大限度地被平均分配到所有分区上,故默认情况下它是最合理的分区策略,也是平时最常用的分区策略之一。 随机策略 也称Randomness策略。所谓随机就是我们随意地将消息放置在任意一个分区上,如下图
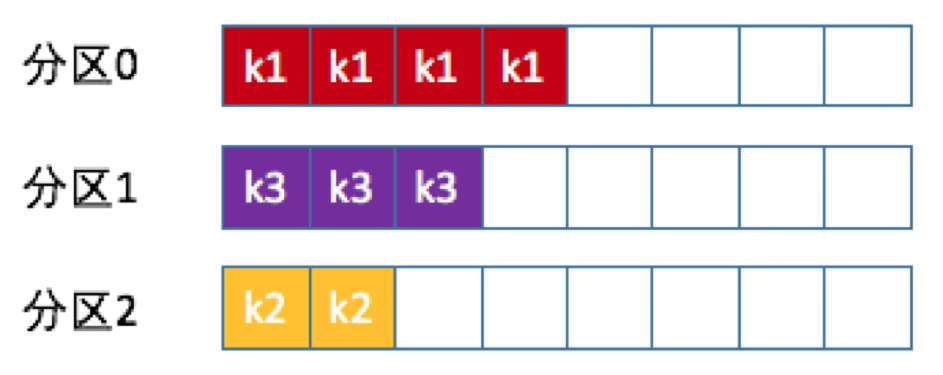
实现方法: package kafka; import org.apache.kafka.clients.producer.Partitioner; import org.apache.kafka.common.Cluster; import org.apache.kafka.common.PartitionInfo; import java.util.List; import java.util.Map; public class KafkaPartitioner implements Partitioner { @Override public int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) { List partitions = cluster.partitionsForTopic(s); // 随机策略 return ThreadLocalRandom.current().nextInt(partitions.size()); } @Override public void close() { } @Override public void configure(Map map) { } }本质上看随机策略也是力求将数据均匀地打撒到各个分区,但从实际表现来看,它要逊于轮询策略,所以如果追求数据的均匀分布,还是使用轮询策略比较好。 按key保存策略 kafka允许为每条消息定义消息键,简称为key。一旦消息被定义了key,那么你就可以保证同一个key的所有消息都进入到相同的分区里面,由于每个分区下的消息处理都是有顺序的,如下图所示
实际上kafka默认分区策略实际上同时实现了两种策略:如果指定了key那么默认按key保存策略;如果没有指定key,则使用轮询策略。 切记分区是实现负载均衡以及高吞吐量的关键,故在生产者这一端就要仔细盘算合适的分区策略,避免造成消息数据的“倾斜”,使得某些分区成为性能瓶颈,这样极易引发下游数据消费的性能下降。 |
【本文地址】
今日新闻 |
推荐新闻 |