Kafka入门实战教程(10):不再依赖ZooKeeper的KRaft |
您所在的位置:网站首页 › kafka和zookeeper需要分开部署吗 › Kafka入门实战教程(10):不再依赖ZooKeeper的KRaft |
Kafka入门实战教程(10):不再依赖ZooKeeper的KRaft
|
1 新的KRaft架构模式
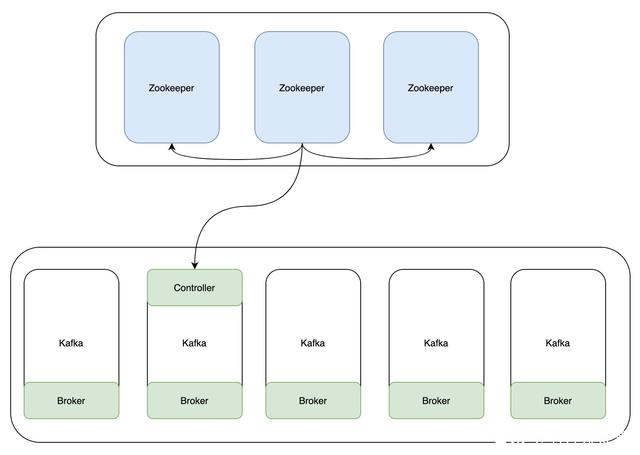
在Kafka 2.8之前,Kafka重度依赖于Zookeeper集群做元数据管理和集群的高可用(即所谓的共识服务)。
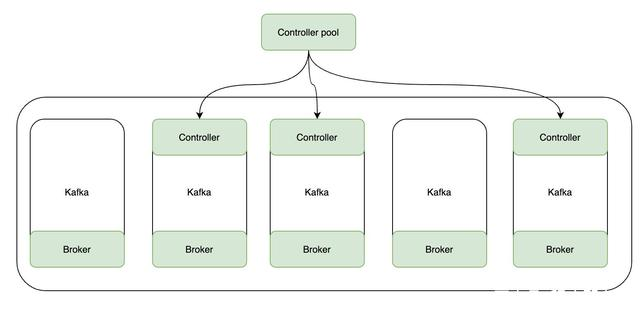
在Kafka 2.8之后,引入了基于Raft协议的KRaft模式,支持取消对Zookeeper的依赖。在此模式下,一部分Kafka Broker被指定为Controller,另一部分则为Broker。这些Controller的作用就是以前由Zookeeper提供的共识服务,并且所有的元数据都将存储在Kafka主题中并在内部进行管理。
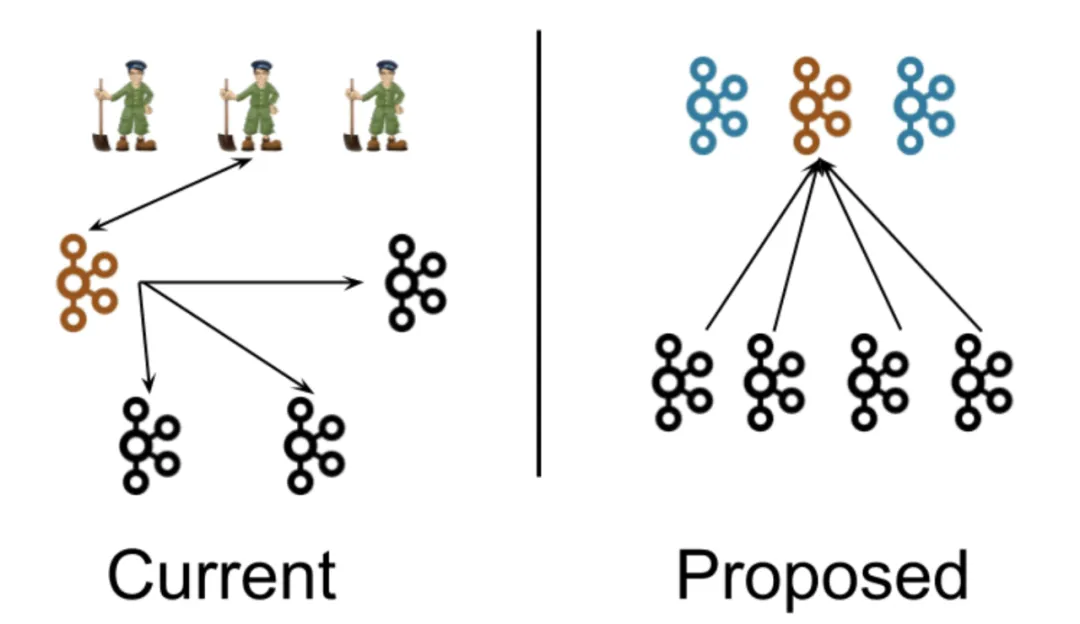
总体而言,使用KRaft的好处如下: Kafka不用再依赖外部框架,能够做到独立运行。类似于Redis的Sentinel,它的本质仍然是一个Kafka实例。 Controller管理集群时,不再需要从Zookeeper中先读取数据,因此集群的性能得到一定的提升。 由于不再依赖Zookeeper,Kafka集群扩展时不用再受到Zookeeper读写能力的限制。 Controller不再动态选举,而是由配置文件规定。这样可以有针对性的加强Controller节点的配置,而不是像以前一样对随机Controller节点的高负载束手无策。
本次我们采用物理宿主机部署,本集群三个Kafka实例均在一台主机上。 下载Kafka安装包
从Apache Kafka官方社区下载最新版3.2.0的安装包(.tgz),然后将其拷贝到服务器上并解压。这里我使用一台Linux主机,启动三个Kafka实例,分别绑定9092,19092,29092端口来模拟三台服务器的集群效果。由于只有三个实例,因此它们既是Controller节点,也是Broker节点。 修改KRaft必要配置和基于Zookeeper的模式不同,KRaft模式下的配置需要进入Kraft目录,找到server.properties文件: cd config/kraft依次修改每个服务器下的kraft目录下的server.properties文件: (1)kafka01 process.roles=broker,controller node.id=1 controller.quorum.voters=1@kafka01:9093,2@kafka02:19093,3@kafka03:29093 listeners=PLAINTEXT://:9092,CONTROLLER://:9093 advertised.listeners=PLAINTEXT://kakfa01:9092 log.dirs=/usr/local/modules/kakfa01/logs(2)kafka02 process.roles=broker,controller node.id=2 controller.quorum.voters=1@kafka01:9093,2@kafka02:19093,3@kafka03:29093 listeners=PLAINTEXT://:19092,CONTROLLER://:19093 advertised.listeners=PLAINTEXT://kakfa02:19092 log.dirs=/usr/local/modules/kakfa02/logs(3)kafka03 process.roles=broker,controller node.id=2 controller.quorum.voters=1@kafka01:9093,2@kafka02:19093,3@kafka03:29093 listeners=PLAINTEXT://:29092,CONTROLLER://:29093 advertised.listeners=PLAINTEXT://kakfa03:29092 log.dirs=/usr/local/modules/kakfa03/logs 初始化集群数据目录(1)生成存储目录唯一ID(UUID) bin/kafka-storage.sh random-uuid uTTIHcpoQSeiGlItgLau0A(2)用这个唯一ID格式化Kafka存储目录 # kafka01 /usr/local/modules/kafka01/bin/kafka-storage.sh format -t uTTIHcpoQSeiGlItgLau0A -c /usr/local/modules/kafka01/config/kraft/server.properties # kafka02 /usr/local/modules/kafka02/bin/kafka-storage.sh format -t uTTIHcpoQSeiGlItgLau0A -c /usr/local/modules/kafka02/config/kraft/server.properties # kafka03 /usr/local/modules/kafka03/bin/kafka-storage.sh format -t uTTIHcpoQSeiGlItgLau0A -c /usr/local/modules/kafka03/config/kraft/server.properties(3)启动Kafka KRaft集群节点服务 # kafka01 /usr/local/modules/kafka01/bin/kafka-server-start.sh -daemon /usr/local/modules/kafka01/config/kraft/server.properties # kakfa02 /usr/local/modules/kafka02/bin/kafka-server-start.sh -daemon /usr/local/modules/kafka02/config/kraft/server.properties # kafka03 /usr/local/modules/kafka03/bin/kafka-server-start.sh -daemon /usr/local/modules/kafka03/config/kraft/server.properties(4)验证Kafka集群节点服务 # jps 1207 Kafka 2137 Jps 2013 Kafka 1614 Kafka 快速测试生产消费(1)创建测试topic kafka01/bin/kafka-topics.sh --create --bootstrap-server kafka01:9092,kafka02:19092,kafka03:29092 --replication-factor 2 --partitions 3 --topic test Created topic test.(2)模拟Producer kafka01/bin/kafka-console-producer.sh --broker-list kafka01:9092,kafka02:19092,kafka03:29092 --topic test >hello >world >edison >zhou(3)模拟Consumer kafka02/bin/kafka-console-consumer.sh --bootstrap-server kafka01:9092,kafka02:19092,kafka03:29092 --from-beginning --topic test hello world edison zhou可以看到,已经可以正常的生产和消费数据。 3 总结本文总结了Kafka KRaft模式的基本概念和优点,介绍了Kafka KRaft模式的部署过程。基于KRaft模式,我们不再需要依赖Zookeeper进行元数据管理和共识服务,在技术选型时不再需要引入额外的组件,对于Kafka来说,实在是个好消息。 至此,Kafka学习征途系列已经有了11篇推文,目前已经走到了结尾,总结这个系列既是我对自己学习的总结,也是系统地梳理所学知识,相信它对我有帮助,也一定对你有所帮助! 参考资料极客时间,胡夕《Kafka核心技术与实战》 B站,尚硅谷《Kafka 3.x入门到精通教程》
作者:周旭龙 出处:https://edisonchou.cnblogs.com 本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。 |

【本文地址】
今日新闻 |
推荐新闻 |