ZooKeeper与Kafka介绍 |
您所在的位置:网站首页 › kafka和zookeeper版本 › ZooKeeper与Kafka介绍 |
ZooKeeper与Kafka介绍
|
ZooKeeper介绍
官网:http://zookeeper.apache.org/ ZooKeeper是一个分布式协调服务,它的主要作用是为分布式系统提供一致性服务,提供的功能包括:配置维护、命名服务、分布式同步、组服务等。Kafka的运行依赖ZooKeeper。 ZooKeeper最早起源于雅虎研究院的一个研究小组。在当时,研究人员发现,在雅虎内部很多大型系统基本都需要依赖一个类似的系统来进行分布式协调,但是这些系统往往都存在分布式单点问题。所以,雅虎的开发人员就试图开发一个通用的无单点问题的分布式协调框架,以便让开发人员将精力集中在处理业务逻辑上。 关于ZooKeeper这个项目的名字,其实也有一段趣闻。在立项初期,考虑到之前内部很多项目都是使用动物的名字来命名的(例如著名的Pig项目),雅虎的工程师希望给这个项目也取一个动物的名字。时任研究院的首席科学家RaghuRamakrishnan开玩笑地说:“在这样下去,我们这儿就变成动物园了!”此话一出,大家纷纷表示就叫动物园管理员吧 一一 因为各个以动物命名的分布式组件放在一起,雅虎的整个分布式系统看上去就像一个大型的动物园了,而ZooKeeper正好要用来进行分布式环境的协调。于是,ZooKeeper的名字也就由此诞生了。 ZooKeeper的数据结构类似于Linux的文件系统,是一种树形的结构。如下: / / \ / \ Lang Service / \ / \ / \ / \ JAVA PHP Nginx Tomcat如果已经搭建了ZooKeeper服务,可以进入到ZooKeeper命令行终端,然后执行ls /看到下面的目录结构 /usr/local/zookeeper/bin/zkCli.sh -server test1:2181 #进入到Zookeeper的命令行终端下面,执行:ls /树是由节点所组成,ZooKeeper的数据存储也同样是基于节点,这种节点叫做Znode。 /Lang/PHP是一个节点,/Service/Tomcat也是一个节点,这样就可以让每一个Znode拥有唯一的路径。每一个Znode里包含了数据、子节点引用、访问权限等。
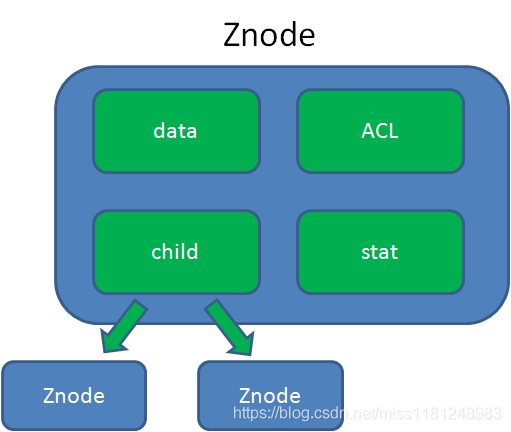
如上图,data即Znode里面的数据;ACL为权限规则,它规定了哪些用户或哪些IP才有权限访问此Znode;stat记录了Znode相关的元数据,比如事务ID、版本号、时间戳、大小;child为当前节点的子节点引用,类似于二叉树的左孩子右孩子。ZooKeeper有个限制,就是每个Znode的数据大小不会超过1M。 get /node_name getAcl /node_name 节点类型 持久节点(persistent):所谓持久节点,是指在节点创建后,就一直存在,直到有删除操作来主动清除这个节点——不会因为创建该节点的客户端会话失效而消失。 create /node 'persistent node' 持久顺序节点(persistent_sequential,节点会自动加上编号):这类节点的基本特性和上面的节点类型是一致的。额外的特性是,在ZK中,每个父节点会为他的第一级子节点维护一份时序,会记录每个子节点创建的先后顺序。基于这个特性,在创建子节点的时候,可以设置这个属性,那么在创建节点过程中,ZK会自动为给定节点名加上一个数字后缀,作为新的节点名。这个数字后缀的范围是整型的最大值。 在创建节点的时候只需要传入节点 “/test_”,这样之后,zookeeper自动会在“test_”后面补充数字。 create -s /s_node 'persistent sequential' 临时节点(ephemeral):和持久节点不同,临时节点的生命周期会和客户端会话绑定,即如果客户端会话失效(不是连接端口),那么这个节点就会自动被清除掉。另外,在临时节点下面无法创建子节点。 create -e /e_node 'ephemeral' 临时顺序节点(ephemeral_sequential):此节点是属于临时节点,不过带有顺序,客户端会话结束节点就消失。 create -e -s /e_s_node 'ephemeral sequential' ZooKeeper集群的角色ZooKeeper提供服务时,是需要通过集群来实现,ZooKeeper集群中有一个leader,多个follower角色,其中leader提供写服务,follower提供读服务。 LeaderLeader是整个ZooKeeper集群工作机制中的核心 。Leader作为整个ZooKeeper集群的主节点,负责响应所有对ZooKeeper状态变更的请求。其主要工作包括下面两个方面: 1)事务请求的唯一调度和处理,保障集群处理事务的顺序性 2)集群内各服务器的调度者Leader选举是ZooKeeper最重要的技术之一,也是保障分布式数据一致性的关键所在。以三台机器为例,在服务器集群初始化阶段,当有一台服务器Server1启动时候是无法完成选举的,当第二台机器Server2启动后两台机器能互相通信,每台机器都试图找到一个Leader,于是便进入了Leader选举流程。 每个server发出一个投票,投票的最基本元素是SID(服务器id)和ZXID(事物id)–> 接受来自各个服务器的投票 --> 处理投票,优先检查ZXID(数据越新ZXID越大),ZXID比较大的作为leader,ZXID一样的情况下比较SID --> 统计投票,这里有个过半的概念,大于集群机器数量的一半,即大于或等于(n/2+1)。这里是三台,所以大于等于2即为达到“过半”的要求 --> 改变服务器状态,一旦确定了leader,服务器就会更改自己的状态,且一般不会再发生变化。 FollowerFollower即跟随者,他的逻辑比较简单。除了响应本服务器上的读请求外,还要处理Leader的提议,并在Leader提交该提议时在本地也进行提交。另外需要注意的是,Leader和Follower构成ZooKeeper集群的法定人数,也就是说,只有他们才参与新Leader的选举、响应Leader的提议。 Observer服务器充当一个观察者的角色。如果ZooKeeper集群的读取负载很高,或者客户端多到跨机房,可以设置一些Observer服务器,以提高读取的吞吐量。Observer和Follower比较相似,只有一些小区别:首先Observer不属于法定人数,即不参加选举也不响应提议,也不参与写操作的“过半写成功”策略;其次是Observer不需要将事务持久化到磁盘,一旦Observer被重启,需要从Leader重新同步整个命名空间。 Kafka介绍Kafka是一款性能非常好的并且支持分布式的消息队列中间件。由于它的高吞吐特性,Kafka通常使用在大数据领域,如日志收集平台。其实Kafka是一个流处理平台,这个概念不太好理解,之所以叫做流,是因为它在工作中就像是一个可以支撑高吞吐量的管道,数据像水一样流进去,然后另外一端再去读取这些数据。我们就可以把Kafka看作是一种特殊的消息队列中间件。 Kafka与传统消息系统相比,有以下不同: 它被设计为一个分布式系统,易于向外扩展; 它同时为发布和订阅提供高吞吐量; 它支持多订阅者,当失败时能自动平衡消费者; 它将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。在Kafka中有几个关键角色和概念。 Producer消息生产者,是消息的产生源头,负责生成消息并发送给Kafka。 Consumer消息消费者,是消息的使用方,负责消费Kafka服务器上的消息。 Topic主题,由用户自定义,并配置在Kafka服务器,用于建立生产者和消费者之间的订阅关系,生产者将消息发送到指定的Topic,然后消费者再从该Topic下去取消息。 Partition消息分区,一个Topic下面会有多个Partition,每个Partition都是一个有序队列,Partition中的每条消息都会被分配一个有序的id。 Broker这个其实就是Kafka服务器了,无论是单台Kafka还是集群,被统一叫做Broker,有的资料上把它翻译为代理或经纪人。 Group消费者分组,将同一类的消费者归类到一个组里。在Kafka中,多个消费者共同消费一个Topic下的消息,每个消费者消费其中的部分消息,这些消费者就组成了一个分组,拥有同一个组名。 Kafka和ZooKeeper了解了ZooKeeper和Kafka后,再来看看Zookeeper在Kafka集群中到底担任了一个什么样的角色? 简单讲,ZooKeeper用于分布式系统的协调,Kafka使用ZooKeeper也是基于相同的原因。ZooKeeper主要用来协调Kafka的各个broker,不仅可以实现broker的负载均衡,而且当增加了broker或者某个broker故障了,ZooKeeper将会通知生产者和消费者,这样可以保证整个系统正常运转。 Broker注册Broker在ZooKeeper中保存为一个临时节点,节点的路径是/brokers/ids/[brokerid],每个节点会保存对应broker的IP以及端口等信息。 /usr/local/zookeeper/bin/zkCli.sh -server test1:2181 #进入到Zookeeper的命令行终端下面,执行:ls /brokers/ids Topic注册在Kafka中,一个topic会被分成多个区并被分到多个broker上,分区的信息以及broker的分布情况都保存在ZooKeeper中,根节点路径为/brokers/topics,每个topic都会在topics下建立独立的子节点,每个topic节点下都会包含分区以及broker的对应信息。 /usr/local/zookeeper/bin/zkCli.sh -server test1:2181 #进入到Zookeeper的命令行终端下面,执行:ls /brokers/topics 生产者负载均衡当Broker启动时,会注册该Broker的信息,以及可订阅的topic信息。生产者通过注册在Broker以及Topic上的watcher动态的感知Broker以及Topic的分区情况,从而将Topic的分区动态的分配到broker上. 消费者Kafka有消费者分组的概念,每个分组中可以包含多个消费者,每条消息只会发给分组中的一个消费者,且每个分组之间是相互独立互不影响的。 消费者与分区的对应关系对于每个消费者分组,Kafka都会为其分配一个全局唯一的Group ID,分组内的所有消费者会共享该ID, Kafka还会为每个消费者分配一个consumer ID,通常采用hostname:uuid的形式。 在kafka的设计中规定,对于topic的每个分区,最多只能被一个消费者进行消费,也就是消费者与分区的关系是一对多的关系。消费者与分区的关系也被存储在ZooKeeper中节点的路劲为 /consumers/[group_id]/owners/[topic]/[broker_id-partition_id],该节点的内容就是消费者的Consumer ID。 消费者负载均衡消费者服务启动时,会创建一个属于消费者节点的临时节点,节点的路径为/consumers/[group_id]/ids/[consumer_id],该节点的内容是该消费者订阅的Topic信息。每个消费者会对/consumers/[group_id]/ids节点注册Watcher监听器,一旦消费者的数量增加或减少就会触发消费者的负载均衡。消费者还会对/brokers/ids/[brokerid]节点进行监听,如果发现服务器的Broker服务器列表发生变化,也会进行消费者的负载均衡。 消费者的offset在Kafka的消费者API分为两种: (1) High Level Api:由ZooKeeper维护消费者的offset (2) Low Level Api:自己的代码实现对offset的维护 由于自己维护offset往往比较复杂,所以多数情况下都是使用High Level的API,offset在ZooKeeper中的节点路径为/consumers/[group_id]/offsets/[topic]/[broker_id-part_id],该节点的值就是对应的offset。 Kafka工作流程1)生产者定期向主题发送消息。 2)Kafka broker将所有消息存储在为该特定主题配置的分区中。它确保消息在分区之间平等共享。如果生产者发送两个消息,并且有两个分区,则Kafka将在第一个分区中存储一个消息,在第二个分区中存储第二个消息。 3)消费者订阅一个特定的主题。 4)一旦消费者订阅了一个主题,Kafka将向消费者提供该主题的当前偏移量,并将偏移量保存在ZooKeeper中。 5)消费者将定期请求Kafka新消息。 6)一旦Kafka收到来自生产者的消息,它会将这些消息转发给消费者。 7)消费者将收到消息并处理它。 8)一旦消息被处理,消费者将向Kafka broker发送确认。 9)一旦Kafka收到确认,它会将偏移量更改为新值,并在ZooKeeper中进行更新。由于ZooKeeper中保留了偏移量,因此即使在服务器出现故障时,消费者也可以正确读取下一条消息。 更多资料参考: 原来这才是kafka |
【本文地址】
今日新闻 |
推荐新闻 |