Kubernetes 节点调度原理及调度策略 |
您所在的位置:网站首页 › k8s反亲和性 › Kubernetes 节点调度原理及调度策略 |
Kubernetes 节点调度原理及调度策略
|
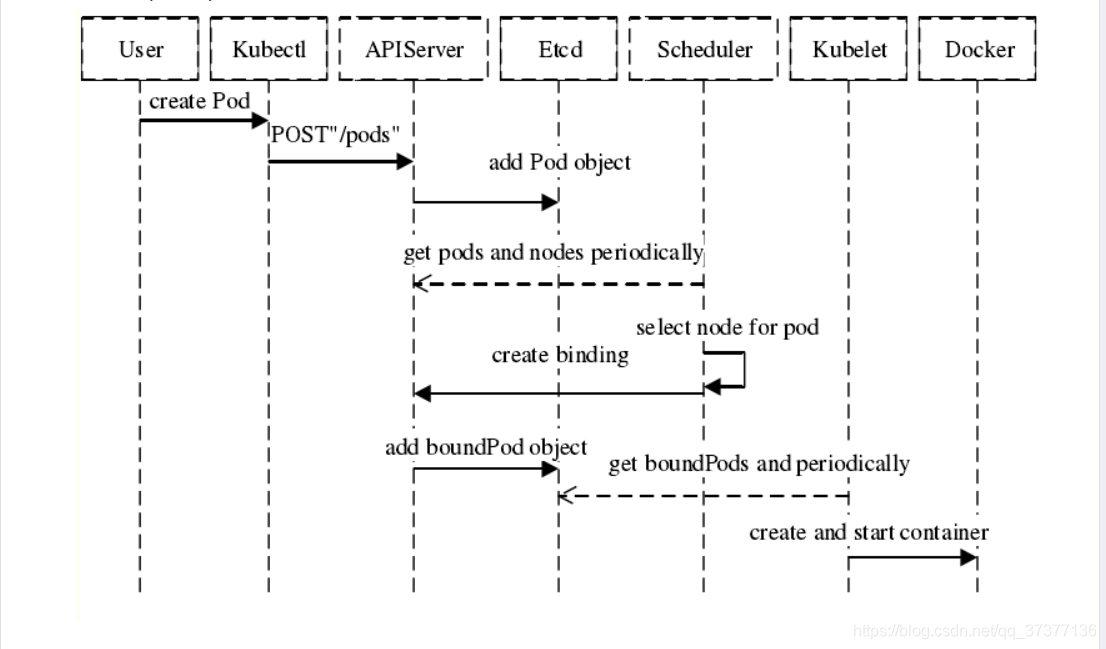
Kubernetes 调度器官方文档 Kubernetes Pod 分配给节点 kubernetes 保留所有标签和注释 其他博主博客 k8s调度器scheduler 简介对每一个新创建的 Pod 或者是未被调度的 Pod,kube-scheduler 会选择一个最优的 Node 去运行这个 Pod。然而,Pod 内的每一个容器对资源都有不同的需求,而且 Pod 本身也有不同的资源需求。因此,Pod 在被调度到 Node 上之前,根据这些特定的资源调度需求,需要对集群中的 Node 进行一次过滤。 在一个集群中,满足一个 Pod 调度请求的所有 Node 称之为 _可调度节点。如果没有任何一个 Node 能满足 Pod 的资源请求,那么这个 Pod 将一直停留在未调度状态直到调度器能够找到合适的 Node。 调度器先在集群中找到一个 Pod 的所有可调度节点,然后根据一系列函数对这些可调度节点打分,然后选出其中得分最高的 Node 来运行 Pod。之后,调度器将这个调度决定通知给 kube-apiserver,这个过程叫做绑定。 在做调度决定时需要考虑的因素包括:单独和整体的资源请求、硬件/软件/策略限制、亲和以及反亲和要求、数据局域性、负载间的干扰等等 k8s调度器scheduler 调度步骤1、过滤(过滤策略):过滤阶段会将所有满足 Pod 调度需求的 Node 选出来,将不满足的节点过滤掉 2、优先(优先策略):根据优先级选出最佳节点 3、节点择优:kube-scheduler 会将 Pod 调度到得分最高的 Node 上。如果存在多个得分最高的 Node,kube-scheduler 会从中随机选取一个节点
**pod调度过程 ** k8s 资源不足时的处理方式 名称注解SelectorSpreadPriority尽量将归属于同一个Service 、StatefulSet 或ReplicaSet 的 Pod 资源分散到不同的 Node上InterPodAffinityPriority遍历 Pod 对象的亲和性,并将那些能够匹配到给定 Node 的条目的权重相加,结果值越大的 Node 得分越高LeastRequestedPriority空闲资源比例越高的 Node 得分越高。换句话说,Node 上的 Pod 越多,并且资源被占用的越多,那么这个Node 的得分就会越少MostRequestedPriority空闲资源比例越低的 Node 得分越高。这个调度策略将会把你所有的工作负载(Pod)调度到尽量少的 Node 上RequestedToCapacityRatioPriority为 Node 上每个资源占用比例设定得分值,为 Node 上每个资源占用比例设定得分值,给资源打分函数在打分时使用。BalancedResourceAllocation优选那些使得资源利用率更为均衡的节点。NodePreferAvoidPodsPriority这个策略将根据 Node 的注解信息中是否含有 scheduler.alpha.kubernetes.io/preferAvoidPods 来 计算其优先级。使用这个策略可以将两个不同 Pod 运行在不同的 Node 上。NodeAffinityPriority基于 Pod 属性中 PreferredDuringSchedulingIgnoredDuringExecution来进行 Node 亲和性调度。TaintTolerationPriority基于 Pod 中对每个 Node 上污点容忍程度进行优先级评估,这个策略能够调整待选 Node 的排名。ImageLocalityPriorityNode 上已经拥有Pod需要的容器镜像的Node 会有较高的优先级ServiceSpreadingPriority这个调度策略的主要目的是确保将归属于同一个 Service 的 Pod 调度到不同的 Node 上。如果 Node 上 没有归属于同一个 Service 的 Pod,这个策略更倾向于将 Pod 调度到这类 Node 上。最终的目的:即使在一个 Node 宕机之后 Service 也具有很强容灾能力CalculateAntiAffinityPriorityMap这个策略主要是用来实现pod反亲和EqualPriorityMap将所有的 Node 设置成相同的权重为 1 一、节点定向调度 名称属性Inlable在某个列表中NotInlable不在某个列表中Exists某个lable存在DoesNotExist某个lable不存在Gtlable大于某个列表中Ltlable小于某个列表中 nodeSelector方式1、创建目录 mkdir -p /root/kubernetes/nodedirectional2、查看node节点的标签 kubectl get nodes --show-labels
4、创建deployment无状态的pod kubectl create deployment node-directional --image=nginx --dry-run=client -o yaml > nodeselector.yaml apiVersion: apps/v1 kind: Deployment metadata: labels: app: node-directional name: node-directional spec: replicas: 1 selector: matchLabels: app: node-directional template: metadata: labels: app: node-directional spec: containers: - image: nginx name: nginx nodeSelector: nodeselector: dev5、生成定向调度pod(多次查看是否调度在k8s-node1 ,node的节点) kubectl delete pod --all && kubectl apply -f nodeselector.yaml && kubectl get pod -o wide
1、创建定向调度pod(多次查看是否调度在k8s-node2,node的节点) vim nodename.yaml apiVersion: apps/v1 kind: Deployment metadata: labels: app: nodename-directional name: nodename-directional spec: replicas: 1 selector: matchLabels: app: nodename-directional template: metadata: labels: app: nodename-directional spec: containers: - image: nginx name: nginx nodeName: k8s-node2 kubectl apply -f nodename.yaml查看分配的节点 kubectl get pod -o wide
硬亲和: 强制满足条件 软亲和: 不满足时,选择得分最高的 Node 注意:节点标签改变而不再符合此节点亲和性规则时,不会将Pod从该节点移出,仅对新建的Pod对象生效 硬亲和:1、创建硬亲和目录 mkdir -p /root/kubernetes/affinity/node/required2、创建硬亲和pod vim required-nodeaffinity.yaml apiVersion: v1 kind: Pod metadata: name: required-nodeaffinity spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: # 定义硬亲和性 nodeSelectorTerms: - matchExpressions: #集合选择器 - key: kubernetes.io/hostname operator: In values: - k8s-node2 containers: - name: nginx image: nginx:latest3、生成pod(调度到k8s-node2节点) kubectl delete po --all && kubectl apply -f required-nodeaffinity.yaml && kubectl get pod -o wide
4、测试调度再其他节点(node3没有此节点) vim required-notnodeaffinity.yaml apiVersion: v1 kind: Pod metadata: name: required-notnodeaffinity spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: # 定义硬亲和性 nodeSelectorTerms: - matchExpressions: #集合选择器 - key: kubernetes.io/hostname operator: In values: - k8s-node3 containers: - name: nginx image: nginx:latest kubectl apply -f required-notnodeaffinity.yaml5、查看生成pod(处于Pending状态) kubectl get pod required-notnodeaffinity
1、创建硬亲和目录 mkdir -p /root/kubernetes/affinity/node/preferred2、创建软亲和pod vim preferred-nodeaffinity.yaml apiVersion: v1 kind: Pod metadata: name: preferred-nodeaffinity spec: affinity: nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: # 定义软亲和性 - weight: 1 preference: matchExpressions: #集合选择器 - key: kubernetes.io/hostname operator: In values: - k8s-node3 #没有node3节点 containers: - name: preferred-nodeaffinity image: nginx:latest3、生成pod(调度到k8s-node1/k8s-node2节点) kubectl delete po --all && kubectl apply -f preferred-nodeaffinity.yaml && kubectl get pod -o wide
1、将节点node1添加标签 kubectl label nodes k8s-node1 preferred-required=nodeaffinity
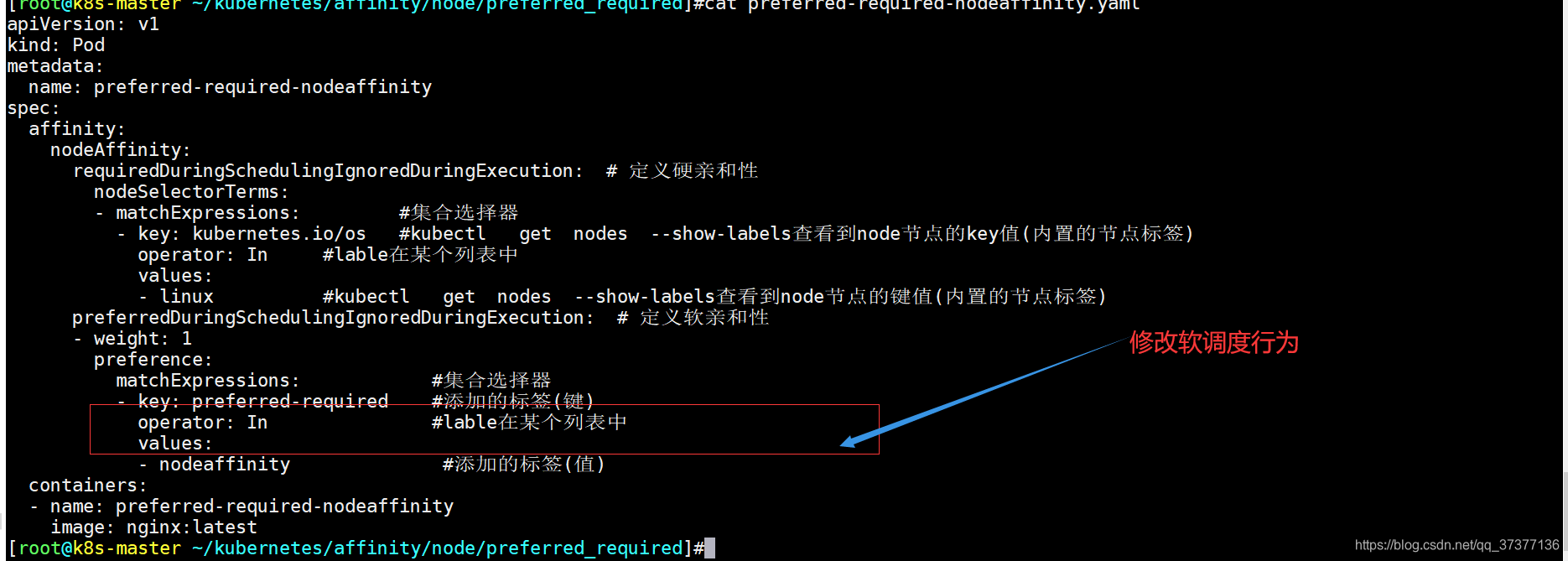
2、创建硬亲和目录 mkdir -p /root/kubernetes/affinity/node/preferred_required3、创建软硬亲和pod(调度在node2) vim preferred-required-nodeaffinity.yaml apiVersion: v1 kind: Pod metadata: name: preferred-required-nodeaffinity spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: # 定义硬亲和性 nodeSelectorTerms: - matchExpressions: #集合选择器 - key: kubernetes.io/os #kubectl get nodes --show-labels查看到node节点的key值(内置的节点标签) operator: In #lable在某个列表中 values: - linux #kubectl get nodes --show-labels查看到node节点的键值(内置的节点标签) preferredDuringSchedulingIgnoredDuringExecution: # 定义软亲和性 - weight: 1 preference: matchExpressions: #集合选择器 - key: preferred-required #添加的标签(键) operator: NotIn #lable不在某个列表中 values: - nodeaffinity #添加的标签(值) containers: - name: preferred-required-nodeaffinity image: nginx:latest3、生成pod(调度到k8s-node2) kubectl delete po --all && kubectl apply -f preferred-required-nodeaffinity.yaml && kubectl get pod -o wide
硬亲和为每个节点内置标签kubernetes.io/os=linux(节点都满足),软亲和之前打好的标签(lable不在某个列表中),不会调度node1节点和master(自带污点),接下剩下调度在node2节点。 4、创建软硬亲和pod(调度在node1) vim preferred-required-nodeaffinity.yaml apiVersion: v1 kind: Pod metadata: name: preferred-required-nodeaffinity spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: # 定义硬亲和性 nodeSelectorTerms: - matchExpressions: #集合选择器 - key: kubernetes.io/os #kubectl get nodes --show-labels查看到node节点的key值(内置的节点标签) operator: In #lable在某个列表中 values: - linux #kubectl get nodes --show-labels查看到node节点的键值(内置的节点标签) preferredDuringSchedulingIgnoredDuringExecution: # 定义软亲和性 - weight: 1 preference: matchExpressions: #集合选择器 - key: preferred-required #添加的标签(键) operator: In #lable在某个列表中 values: - nodeaffinity #添加的标签(值) containers: - name: preferred-required-nodeaffinity image: nginx:latest
5、生成pod(调度到k8s-node1) kubectl delete po --all && kubectl apply -f preferred-required-nodeaffinity.yaml && kubectl get pod -o wide
全部调度在node1节点上 |

 3、k8s-node1节点添加新的标签
3、k8s-node1节点添加新的标签




 node的硬亲和必须满足条件,不满足处于等待符合条件的节点
node的硬亲和必须满足条件,不满足处于等待符合条件的节点 node的软亲和如果不存在就寻找其他性能比较好的节点,调度到该节点运行应用
node的软亲和如果不存在就寻找其他性能比较好的节点,调度到该节点运行应用


【本文地址】