如何爬取js动态生成的页面数据 |
您所在的位置:网站首页 › js提取网页数据 › 如何爬取js动态生成的页面数据 |
如何爬取js动态生成的页面数据
|
一、目标网页及要求
目标网页:
https://www.xuexi.cn/f997e76a890b0e5a053c57b19f468436/018d244441062d8916dd472a4c6a0a0b.html
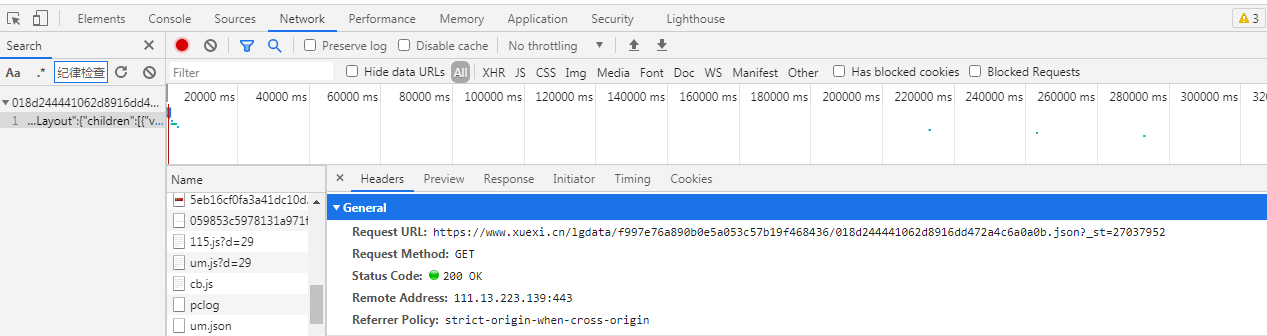
以Chrome浏览器为例,通过F12打开抓包工具,按F5刷新下页面,ctr+F进行全局搜索页面中的内容,发现该页面内容是通过ajax动态获取的 Method:GET url:https://www.xuexi.cn/lgdata/f997e76a890b0e5a053c57b19f468436/018d244441062d8916dd472a4c6a0a0b.json?_st=27037952
将响应内容通过新窗口打开(安装过JSONView插件),可以很直观的查看Json数据结构
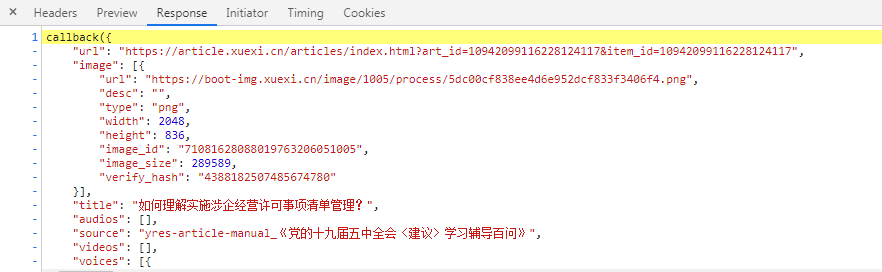
通过分析发现,详情页链接都在title下的link中,并且分为:带请求参数id和不带请求参数两种形式 3、详情页分析接下来分别对这两种形式的详情页链接进行访问,继续按照目标主页页面的分析步骤,发现数据是通过js动态加载的 携带请求参数id:详情页url :https://www.xuexi.cn/lgpage/detail/index.html?id=10942099116228124117&item_id=10942099116228124117 数据来源js:https://boot-source.xuexi.cn/data/app/10942099116228124117.js?callback=callback&_st=1622280445799 其它详情页数据来源js都是这种格式 规律如下: 通过详情页url提取id,然后_st参数是16开头的13位数字,没错,就是时间戳*1000后的整数部分,这样我们就能通过详情页url来找到其数据来源js的url 提取数据: 首先通过正则提取出dict数据,然后通过jsonpath规则提取出目标数据 标题:‘$..title’ 内容:'$..content',之后通过xpath提取p或者span标签中的内容 来源:'$..show_source' 出版时间:'$..publishi_time'
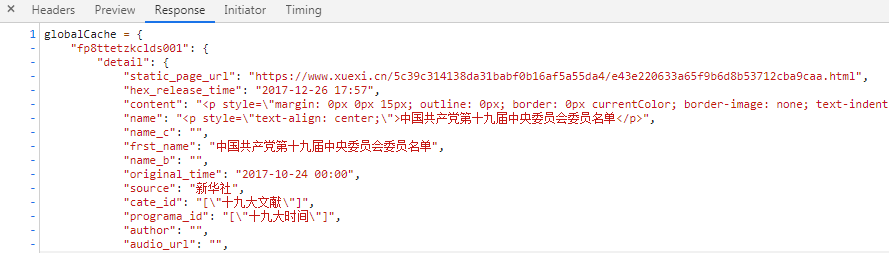
详情页url :https://www.xuexi.cn/5c39c314138da31babf0b16af5a55da4/e43e220633a65f9b6d8b53712cba9caa.html 数据来源js:https://www.xuexi.cn/5c39c314138da31babf0b16af5a55da4/datae43e220633a65f9b6d8b53712cba9caa.js 其它详情页都是以e43e220633a65f9b6d8b53712cba9caa.html结尾,js页都是以datae43e220633a65f9b6d8b53712cba9caa.js结尾 规律如下: 将详情页url中的e43e220633a65f9b6d8b53712cba9caa.html替换成datae43e220633a65f9b6d8b53712cba9caa.js即可 提取数据: 首先通过正则提取出dict数据,然后通过jsonpath规则提取出目标数据 标题:'$.fp8ttetzkclds001..frst_name' 内容:'$.fp8ttetzkclds001.detail.content',之后通过xpath提取p或者span标签中的内容 来源:'$.fp8ttetzkclds001..source' 出版时间:'$.fp8ttetzkclds001..original_time'
|



【本文地址】
今日新闻 |
推荐新闻 |