Json格式的数据集标签转化为有效的txt格式(data |
您所在的位置:网站首页 › json文件转换成数据表 › Json格式的数据集标签转化为有效的txt格式(data |
Json格式的数据集标签转化为有效的txt格式(data
|
Json格式的数据集标签转化为有效的txt格式(data_coco)
学习前言分析json格式标签转化为有效的txt格式实现效果
学习前言 在参加许多目标检测比赛时,为了能够获得合理的评价结果,官方往往是将已经打好标签的数据集事先划分好训练集与测试集,将训练集和测试集的标签分别存放在json文件。以百度飞桨平台第17届全国大学生智能汽车竞赛百度创意组数据集为例,我们将学习如何将json格式的数据集标签转化为有效的txt文件。 分析json格式标签 了解json文件格式,详细请参考这篇博客:Json文件格式详解 开始分析Json文件之前,先让我们了解一下官方给出的数据集: 以测试集为例,train.json中存储的数据类型为字典:有三个键分别为:‘images’, ‘annotations’,‘categories’,详细内容如下: {‘images’: [{‘file_name’: ‘013856.jpg’, ‘height’: 1080, ‘width’: 1920, ‘id’: 13856}, {‘file_name’: ‘06933.jpg’, ‘height’: 720, ‘width’: 1280, ‘id’: 6933}…{‘file_name’: ‘015349.jpg’, ‘height’: 1080, ‘width’: 1920, ‘id’: 15349}], ‘annotations’: [{‘image_id’: 13856, ‘id’: 0, ‘category_id’: 2, ‘bbox’: [541, 517, 79, 102], ‘area’: 8058, ‘iscrowd’: 0, ‘segmentation’: []},{‘image_id’: 13856, ‘id’: 1, ‘category_id’: 2, ‘bbox’: [827, 514, 54, 88], ‘area’: 4752, ‘iscrowd’: 0, ‘segmentation’: []}… {‘image_id’: 15349, ‘id’: 113950, ‘category_id’: 1, ‘bbox’: [341, 573, 83, 90], ‘area’: 7470, ‘iscrowd’: 0, ‘segmentation’: []}],‘categories’: [{‘id’: 1, ‘name’: ‘Motor Vehicle’}, {‘id’: 2, ‘name’: ‘Non_motorized Vehicle’}, {‘id’: 3, ‘name’: ‘Pedestrian’}, {‘id’: 4, ‘name’: ‘Traffic Light-Red Light’}, {‘id’: 5, ‘name’: ‘Traffic Light-Yellow Light’}, {‘id’: 6, ‘name’: ‘Traffic Light-Green Light’}, {‘id’: 7, ‘name’: ‘Traffic Light-Off’}] 'images’对应的值是一个列表,其中有2000个元素,每一个元素都是一个字典,字典中键的含义分别为:‘file_name’:图像名称及格式;‘height’:图像高度;‘width’:图像宽度;‘id’:图像名称对应的序号。 同理,'annotations’对应的内容如下:‘image_id’:图像名称对应的序号,与’images’中的’id’是同一个值;‘id’:标签的总个数,从1开始计时;‘category_id’: 标签对应的类别编号; ‘bbox’:标注框的像素坐标;‘area’: 标注框的面积;‘iscrowd’:一张图像上是否为单个标注对象;‘segmentation’:表示polygon格式,只要iscrowd=1那么segmentation就是RLE格式。 'categories’对应的内容如下:‘id’:类别编号; ‘name’:类别标签 。 转化为有效的txt格式 经过上述分析,我们便可以根据’images’中的’id’创建对应的txt文件;根据’images’中的’id’与’annotations’中的’image_id’的对应关系,将对应的’bbox’和’category_id’写入对应的txt文件中;根据’categories’中的’id’和’name’将标签和标签编号单独写入另一个txt文件中。 实现上述目的的代码如下: # 处理同一个数据集下多个json文件时,仅运行一次class_txt即可 import json import os "存储标签与预测框到txt文件中" def json_txt(json_path, txt_path): "json_path: 需要处理的json文件的路径" "txt_path: 将json文件处理后txt文件存放的文件夹名" # 生成存放json文件的路径 if not os.path.exists(txt_path): os.mkdir(txt_path) # 读取json文件 with open(json_path, 'r') as f: dict = json.load(f) # 得到images和annotations信息 images_value = dict.get("images") # 得到某个键下对应的值 annotations_value = dict.get("annotations") # 得到某个键下对应的值 # 使用images下的图像名的id创建txt文件 list=[] # 将文件名存储在list中 for i in images_value: open(txt_path + str(i.get("id")) + '.txt', 'w') list.append(i.get("id")) # 将id对应图片的bbox写入txt文件中 for i in list: for j in annotations_value: if j.get("image_id") == i: # bbox标签归一化处理 num = sum(j.get('bbox')) new_list = [round(m / num, 6) for m in j.get('bbox')] # 保留六位小数 with open(txt_path + str(i) + '.txt', 'a') as file1: # 写入txt文件中 print(j.get("category_id"), new_list[0], new_list[1], new_list[2], new_list[3], file=file1) "将id对应的标签存储在class.txt中" def class_txt(json_path, class_txt_path): "json_path: 需要处理的json文件的路径" "txt_path: 将json文件处理后存放所需的txt文件名" # 生成存放json文件的路径 with open(json_path, 'r') as f: dict = json.load(f) # 得到categories下对应的信息 categories_value = dict.get("categories") # 得到某个键下对应的值 # 将每个类别id与类别写入txt文件中 with open(class_txt_path, 'a') as file0: for i in categories_value: print(i.get("id"), i.get('name'), file=file0) json_txt("train.json", "train_annotations/") # class_txt("eval.json", "id_categories.txt")需要注意的是:由于在eval.json和train.json中都有’categories’,且内容相同,故在生成标签和标签编号txt文件时,运行一次class_txt()函数即可。 实现效果 生成的文件: |

 其中,eval文件夹有2000张测试集图片,train文件夹有14000张训练集图片。
其中,eval文件夹有2000张测试集图片,train文件夹有14000张训练集图片。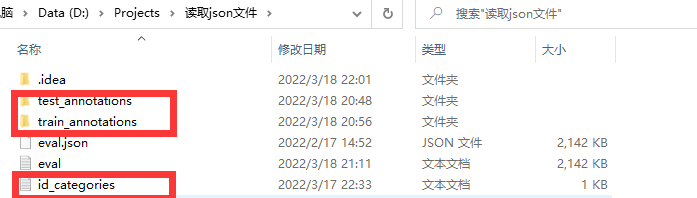 有效的txt文件:
有效的txt文件: 

【本文地址】
今日新闻 |
推荐新闻 |