SpringBoot+poi实现读取word文件内容 |
您所在的位置:网站首页 › java读取图片文字 › SpringBoot+poi实现读取word文件内容 |
SpringBoot+poi实现读取word文件内容
|
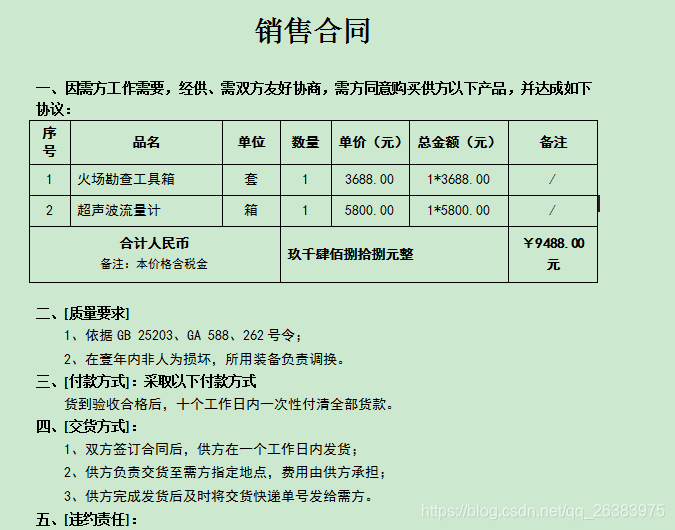
java开发实现读取word 文件内容 目录 一、实现功能二、具体实现1.添加必要依赖2.代码实现2.1 功能1:java读取word文档内容,兼容doc和docx(1)创建controller,编写读取方法:(2)编写页面调用方法(3)测试 2.2 功能2:java读取docx文档的两种方式(1)通过XWPFWordExtractor读取docx文档(2)通过XWPFDocument读取docx文档 2.3 功能3:java读取docx文档内容转HTML(手动编写格式)(1)编写工具类(2)调用工具类的readWordToHtml方法(3)在页面中调用上一步的读取方法(4)启动测试 2.4 功能4:java读取docx文档中表格跨列合并问题的解决方法(1)编写获取单元格的跨列个数(2)组装单元格的跨列属性(3)测试 2.5 功能5:java读取word文档内容(含图片、表格手动编写格式)(1)在WordRead工具类中添加解析方法(文本、图片、表格)(2)调用工具类的readWordImgToHtml方法(3)在页面中调用上一步的读取方法(4)启动测试 三、完整代码 一、实现功能1.java读取word文档内容,兼容doc和docx(不含图片、表格不带格式) 2.java读取docx文档内容的两种方式 3.java读取docx文档内容转HTML(手动编写格式)(后缀名为docx) 4.java读取docx文档内容中表格跨列合并问题的解决方法 5.java读取word文档内容(含图片、表格手动编写格式) 二、具体实现word文件内容: 运行结果: 注:对象说明 XWPFDocument:一个word XWPFParagraph:word中的一个段落 注意:在word中按一次回车就是一个段落 XWPFRun:段落中的文本 注意:段落中一个字可能就是一个XWPFRun对象 XWPFTable:word中的一个表格 注意:表格与段落同级 XWPFTableRow:表格中的一行 XWPFTableCell:行中的一列 2.2 功能2:java读取docx文档的两种方式POI在读docx文件的时候有两种方式: (1)通过XWPFWordExtractor (2)通过XWPFDocument 在XWPFWordExtractor读取信息时其内部还是通过XWPFDocument来获取的。 (1)通过XWPFWordExtractor读取docx文档在使用XWPFWordExtractor读取docx文档的内容时,我们只能获取到其文本,而不能获取到其文本对应的属性值。 使用XWPFWordExtractor来读取docx文档内容的方法如下: /** * 通过XWPFWordExtractor读取word(后缀名为docx的文件) * @return */ public static String readWordDocx1(){ String result =""; String filePath = "e:\\w1.doc"; try { File file = new File(filePath); FileInputStream fs = new FileInputStream(file); XWPFDocument doc = new XWPFDocument(fs); XWPFWordExtractor extractor = new XWPFWordExtractor(doc); String text = extractor.getText();//获取word中的文本内容 extractor.close(); fs.close(); result = text; }catch (Exception e) { e.printStackTrace(); } return result; } (2)通过XWPFDocument读取docx文档在通过XWPFDocument读取docx文档时,我们就可以获取到文本比较精确的属性信息了。比如我们可以获取到某一个XWPFParagraph、XWPFRun或者是某一个XWPFTable,包括它们对应的属性信息。 下面是一个使用XWPFDocument读取docx文档的示例: /** * 通过XWPFDocument读取docx文档 * @throws IOException */ public static String readWord() throws IOException{ XWPFDocument document = new XWPFDocument(new FileInputStream("E:\\w3.docx")); String htmlText=""; try { // 获取word中的所有段落与表格 List elements = document.getBodyElements(); for (IBodyElement element : elements) { // 段落 if (element instanceof XWPFParagraph) { htmlText+=getParagraphText((XWPFParagraph) element); } // 表格 else if (element instanceof XWPFTable) { htmlText+=getTabelText((XWPFTable) element); } } }catch (Exception e) { e.printStackTrace(); }finally{ document.close(); } return htmlText; } /** * 获取段落内容( docx后缀名的Word) * @param paragraph */ private static String getParagraphText(XWPFParagraph paragraph) { // 获取段落中所有内容 List runs = paragraph.getRuns(); if (runs.size() == 0) { //System.out.println("按了回车(新段落)"); return ""; } StringBuffer runText = new StringBuffer(); for (XWPFRun run : runs) { runText.append(run.text()); } // if (runText.length() > 0) { // runText.append(",对齐方式:").append(paragraph.getAlignment().name()); // System.out.println(runText); // } return runText.toString(); } /** * 获取表格内容( docx后缀名的Word) * @param table */ private static String getTabelText(XWPFTable table) { String result=""; //获取表格数据行 List rows = table.getRows(); if(rows.size()>0){ //遍历 for (int i=0;i String cellText=""; // 简单获取内容(简单方式是不能获取字体对齐方式的) // System.out.println(cell.getText()); // 一个单元格可以理解为一个word文档,单元格里也可以加段落与表格 List paragraphs = cell.getParagraphs(); for (XWPFParagraph paragraph : paragraphs) { cellText+=getParagraphText(paragraph); } result+=cellText; } } } return result; } 2.3 功能3:java读取docx文档内容转HTML(手动编写格式)前两个功能的 读取结果,都不带格式,需要手动编写格式,所以有了功能3的实现。 (1)编写工具类 package com.example.filedemo.common.wordUtil; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.IOException; import java.util.List; import org.apache.poi.hwpf.extractor.WordExtractor; import org.apache.poi.xwpf.extractor.XWPFWordExtractor; import org.apache.poi.xwpf.usermodel.IBodyElement; import org.apache.poi.xwpf.usermodel.XWPFDocument; import org.apache.poi.xwpf.usermodel.XWPFParagraph; import org.apache.poi.xwpf.usermodel.XWPFRun; import org.apache.poi.xwpf.usermodel.XWPFTable; import org.apache.poi.xwpf.usermodel.XWPFTableCell; import org.apache.poi.xwpf.usermodel.XWPFTableRow; /** * word读取工具类 * @author Administrator * */ public class WordRead { public static void main(String[] args) { try { String result = readWord(); System.out.println(result); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } /** * 方式一:读取word中的文本内容(段落、表格统计获取)--- doc\docx 都可 */ public static String readWordText(){ String result =""; String filePath = "e:\\w1.doc"; String suffixName = filePath.substring(filePath.lastIndexOf("."));//从最后一个.开始截取。截取fileName的后缀名 try { File file = new File(filePath); FileInputStream fs = new FileInputStream(file); if(suffixName.equalsIgnoreCase(".doc")){//doc StringBuilder result2 = new StringBuilder(); WordExtractor re = new WordExtractor(fs); result2.append(re.getText());//获取word中的文本内容 re.close(); result = result2.toString(); }else{//docx XWPFDocument doc = new XWPFDocument(fs); XWPFWordExtractor extractor = new XWPFWordExtractor(doc); String text = extractor.getText();//获取word中的文本内容 extractor.close(); fs.close(); result = text; } }catch (Exception e) { e.printStackTrace(); } return result; } /** * 方式2:读取word中的文本内容(段落、表格分开处理) docx后缀名的Word * @throws IOException */ public static String readWord() throws IOException{ XWPFDocument document = new XWPFDocument(new FileInputStream("E:\\w3.docx")); String htmlText=""; try { // 获取word中的所有段落与表格 List elements = document.getBodyElements(); for (IBodyElement element : elements) { // 段落 if (element instanceof XWPFParagraph) { htmlText+=getParagraphText((XWPFParagraph) element); } // 表格 else if (element instanceof XWPFTable) { htmlText+=getTabelText((XWPFTable) element); } } }catch (Exception e) { e.printStackTrace(); }finally{ document.close(); } return htmlText; } /** * 方式2:读取word中的文本内容(段落、表格分开处理) docx后缀名的Word * @param filePath 文件路径 * @throws IOException */ public static String readWord2(String filePath) throws IOException{ XWPFDocument document = new XWPFDocument(new FileInputStream(filePath)); String htmlText=""; try { // 获取word中的所有段落与表格 List elements = document.getBodyElements(); for (IBodyElement element : elements) { // 段落 if (element instanceof XWPFParagraph) { htmlText+=getParagraphText((XWPFParagraph) element); } // 表格 else if (element instanceof XWPFTable) { htmlText+=getTabelText((XWPFTable) element); } } }catch (Exception e) { e.printStackTrace(); }finally{ document.close(); } return htmlText; } /** * 方式2:读取word中的文本内容(段落、表格分开处理) docx后缀名的Word * @param fs 文件流 * @throws IOException */ public static String readWord3(FileInputStream fs) throws IOException{ XWPFDocument document = new XWPFDocument(fs); String htmlText=""; try { // 获取word中的所有段落与表格 List elements = document.getBodyElements(); for (IBodyElement element : elements) { // 段落 if (element instanceof XWPFParagraph) { htmlText+=getParagraphText((XWPFParagraph) element); } // 表格 else if (element instanceof XWPFTable) { htmlText+=getTabelText((XWPFTable) element); } } }catch (Exception e) { e.printStackTrace(); }finally{ document.close(); } return htmlText; } /** * 获取段落内容( docx后缀名的Word) * @param paragraph */ private static String getParagraphText(XWPFParagraph paragraph) { // 获取段落中所有内容 List runs = paragraph.getRuns(); if (runs.size() == 0) { //System.out.println("按了回车(新段落)"); return ""; } StringBuffer runText = new StringBuffer(); for (XWPFRun run : runs) { runText.append(run.text()); } // if (runText.length() > 0) { // runText.append(",对齐方式:").append(paragraph.getAlignment().name()); // System.out.println(runText); // } return runText.toString(); } /** * 获取表格内容( docx后缀名的Word) * @param table */ private static String getTabelText(XWPFTable table) { String result=""; //获取表格数据行 List rows = table.getRows(); if(rows.size()>0){ //遍历 for (int i=0;i String cellText=""; // 简单获取内容(简单方式是不能获取字体对齐方式的) // System.out.println(cell.getText()); // 一个单元格可以理解为一个word文档,单元格里也可以加段落与表格 List paragraphs = cell.getParagraphs(); for (XWPFParagraph paragraph : paragraphs) { cellText+=getParagraphText(paragraph); } result+=cellText; } } } return result; } /** * 读取word中的文本内容(段落、表格分开处理)转HTML docx后缀名的Word * @param filePath 文件路径 * @throws IOException */ public static String readWordToHtml(String filePath) throws IOException{ XWPFDocument document = new XWPFDocument(new FileInputStream(filePath)); String htmlText=""; try { // 获取word中的所有段落与表格 List elements = document.getBodyElements(); for (IBodyElement element : elements) { // 段落 if (element instanceof XWPFParagraph) { htmlText+=getParagraphHtmlText((XWPFParagraph) element); } // 表格 else if (element instanceof XWPFTable) { htmlText+=getTabelHtmlText((XWPFTable) element); } } }catch (Exception e) { e.printStackTrace(); }finally{ document.close(); } return htmlText; } /** * 获取段落内容并组装段落HTML * @param paragraph */ private static String getParagraphHtmlText(XWPFParagraph paragraph) { // 获取段落中所有内容 List runs = paragraph.getRuns(); if (runs.size() == 0) { //System.out.println("按了回车(新段落)"); return ""; } StringBuffer runText = new StringBuffer(); for (XWPFRun run : runs) { runText.append(run.text()); } return ""+runText.toString()+" "; } /** * 获取表格内容并组装表格HTML * @param table */ private static String getTabelHtmlText(XWPFTable table) { String result=""; //获取表格数据行 List rows = table.getRows(); if(rows.size()>0){ result+=""; //遍历 for (int i=0;i result+=""; String cellText=""; // 简单获取内容(简单方式是不能获取字体对齐方式的) // System.out.println(cell.getText()); // 一个单元格可以理解为一个word文档,单元格里也可以加段落与表格 List paragraphs = cell.getParagraphs(); for (XWPFParagraph paragraph : paragraphs) { cellText+=""+getParagraphText(paragraph)+" "; } result+=cellText; result+=""; } result+=""; } result+=""; } return result; } /** * 通过XWPFWordExtractor读取word(后缀名为docx的文件) * @return */ public static String readWordDocx1(){ String result =""; String filePath = "e:\\w1.doc"; try { File file = new File(filePath); FileInputStream fs = new FileInputStream(file); XWPFDocument doc = new XWPFDocument(fs); XWPFWordExtractor extractor = new XWPFWordExtractor(doc); String text = extractor.getText();//获取word中的文本内容 extractor.close(); fs.close(); result = text; }catch (Exception e) { e.printStackTrace(); } return result; } /** * 通过XWPFDocument读取word(后缀名为docx的文件) * @return */ public static String readWordDocx2(){ String result =""; String filePath = "e:\\w1.doc"; try { File file = new File(filePath); FileInputStream fs = new FileInputStream(file); XWPFDocument doc = new XWPFDocument(fs); XWPFWordExtractor extractor = new XWPFWordExtractor(doc); String text = extractor.getText();//获取word中的文本内容 extractor.close(); fs.close(); result = text; }catch (Exception e) { e.printStackTrace(); } return result; } } (2)调用工具类的readWordToHtml方法ReadFileController类中添加如下方法: /** * 读取Word中的文本内容转html(docx) */ @RequestMapping(value ="/readWordFile2") public Map readWordFile2(HttpServletRequest request,HttpServletResponse response){ Map result = new HashMap(); //word文件地址放在src/main/webapp/下 //表示到项目的根目录(webapp)下,要是想到目录下的子文件夹,修改"/"即可 String path = request.getSession().getServletContext().getRealPath("/"); String filePath = path+"template/wp.docx"; try { //读取Word中的文本内容包含表格 String wordhtml = WordRead.readWordToHtml(filePath); result.put("content", wordhtml); }catch (Exception e) { e.printStackTrace(); } return result; } (3)在页面中调用上一步的读取方法 二:读取docx文档内容(组装格式) 读取docx文档内容(带格式) //读取Word文档内容(带格式) function doReadFile2(){ $("#wordDiv").hide(); $.ajax({ type:"get", url:"/auth/readFile/readWordFile2", data:{}, dataType:"JSON",//预期服务器返回的数据类型 success:function(res){ console.log(res) $("#wordDiv").show(); var html=""; html+="word内容如下:" html+=""+res.content+""; $("#wordDiv").html(html); } }) } (4)启动测试运行结果: 解决方法: 获取单元格的跨列个数,组装单元格的跨列属性(colspan) (1)编写获取单元格的跨列个数 /** * 获取单元格跨列个数 * @return */ public static BigInteger getCellGridSpanNum(XWPFTableCell cell){ BigInteger gridSpanNum =null; //获取单元格跨列 CTDecimalNumber gridSpanXml = cell.getCTTc().getTcPr().getGridSpan(); if(gridSpanXml!=null){ gridSpanNum = gridSpanXml.getVal(); System.out.println("gridSpanNum:"+gridSpanNum); } return gridSpanNum; } (2)组装单元格的跨列属性
"+getParagraphText(paragraph)+" "; } result+=cellText; result+=""; } result+=""; } result+=""; } return result; } (3)测试运行结果如下: 获取word文档中的所有图片: XWPFDocument document = new XWPFDocument(new FileInputStream("E:\\w3.docx")); //获取word中的所有图片 List picLists= document.getAllPictures(); for(XWPFPictureData pic:picLists){ System.out.println("图片名称:\t" + pic.getFileName()); System.out.println("图片类型:\t" + pic.getPictureType()); byte[] data = pic.getData(); System.out.println(data); //下载图片到w3.docx所在文件夹 String imagePath = "E:\\w3.docx"; FileOutputStream fos = new FileOutputStream(imagePath + pic.getFileName()); fos.write(data); }实现: (1)在WordRead工具类中添加解析方法(文本、图片、表格) /** * 读取word中的文本内容(段落、表格、图片分开处理)转HTML docx后缀名的Word * @param filePath 文件路径 * @throws IOException */ public static String readWordImgToHtml(String filePath) throws IOException{ XWPFDocument document = new XWPFDocument(new FileInputStream(filePath)); String htmlText=""; try { // 获取word中的所有段落与表格 List elements = document.getBodyElements(); for (IBodyElement element : elements) { // 段落 if (element instanceof XWPFParagraph) { htmlText+=getParagraphHtmlText((XWPFParagraph) element); } // 表格 else if (element instanceof XWPFTable) { htmlText+=getTabelHtmlText((XWPFTable) element); } } //获取word中的所有图片 List picLists= document.getAllPictures(); for(XWPFPictureData pic:picLists){ System.out.println("图片名称:\t" + pic.getFileName()); System.out.println("图片类型:\t" + pic.getPictureType()); byte[] data = pic.getData(); System.out.println(data); //字节流图片上传,并返回服务器地址 String imgUrl = getImageUrl(data, pic.getFileName()); System.out.println("图片服务器地址:"+imgUrl); //组装img htmlText+="ReadFileController类中添加如下方法: /** * 读取docx文档内容(文本、图片和表格---手动组装格式) */ @RequestMapping(value ="/readWordFile3") public Map readWordFile3(HttpServletRequest request,HttpServletResponse response){ Map result = new HashMap(); //word文件地址放在src/main/webapp/下 //表示到项目的根目录(webapp)下,要是想到目录下的子文件夹,修改"/"即可 String path = request.getSession().getServletContext().getRealPath("/"); String filePath = path+"template/wp3.docx"; try { //读取Word中的文本内容包含表格 String wordhtml = WordRead.readWordImgToHtml(filePath); result.put("content", wordhtml); }catch (Exception e) { e.printStackTrace(); } return result; } (3)在页面中调用上一步的读取方法 三:读取docx文档内容(文本、图片和表格)(组装格式) 读取docx文档内容(带格式并包含图片) //读取Word文档内容(带格式并包含图片) function doReadFile3(){ $("#wordDiv").hide(); $.ajax({ type:"get", url:"/auth/readFile/readWordFile3", data:{}, dataType:"JSON",//预期服务器返回的数据类型 success:function(res){ console.log(res) $("#wordDiv").show(); var html=""; html+="word内容如下:" html+=""+res.content+""; $("#wordDiv").html(html); } }) } (4)启动测试运行结果: 点击此处进行下载 参考资料: java使用poi读写word中的内容(包含表格内容) XWPF POI word文档操作 java解析docx文档提取文字和图片 java word文件转html (转换后可在线预览) |

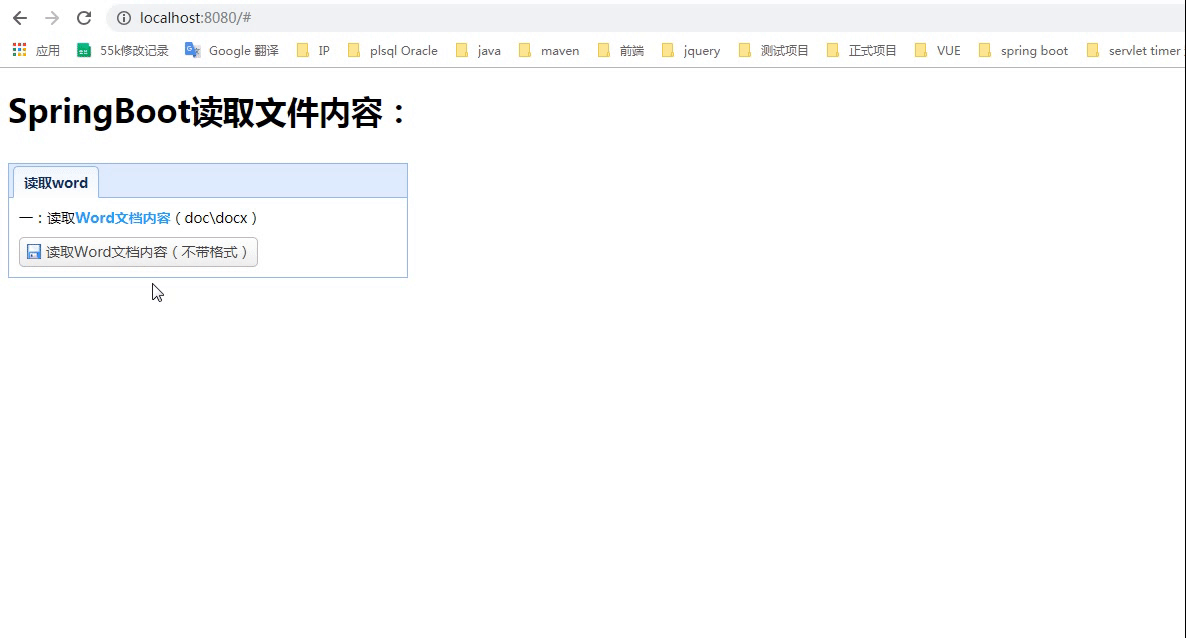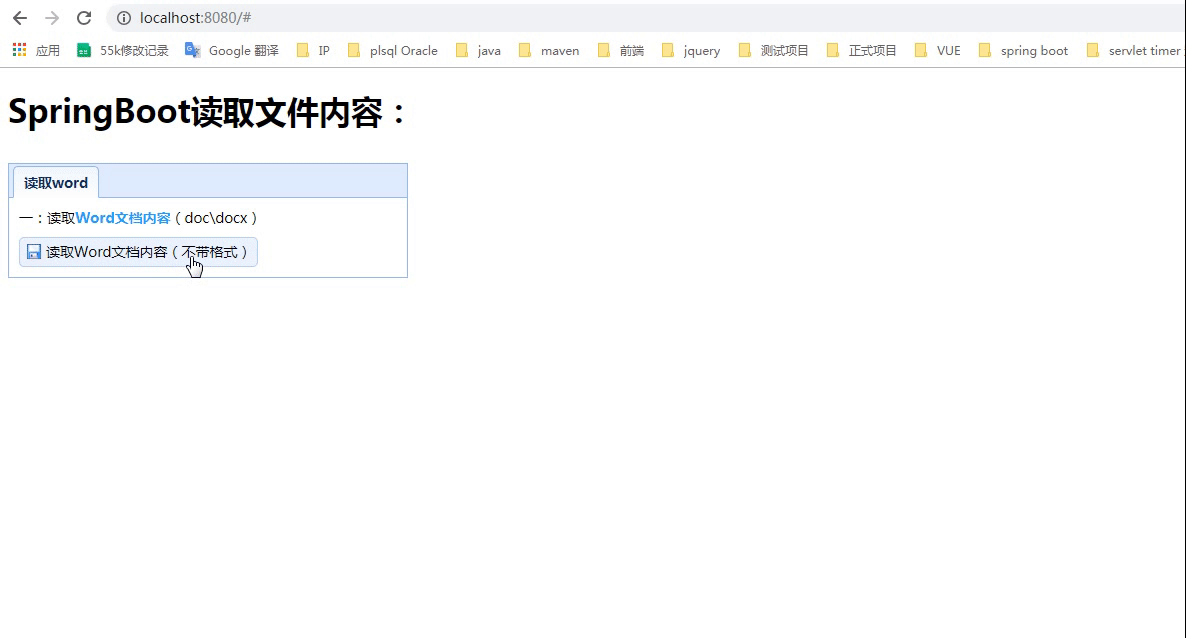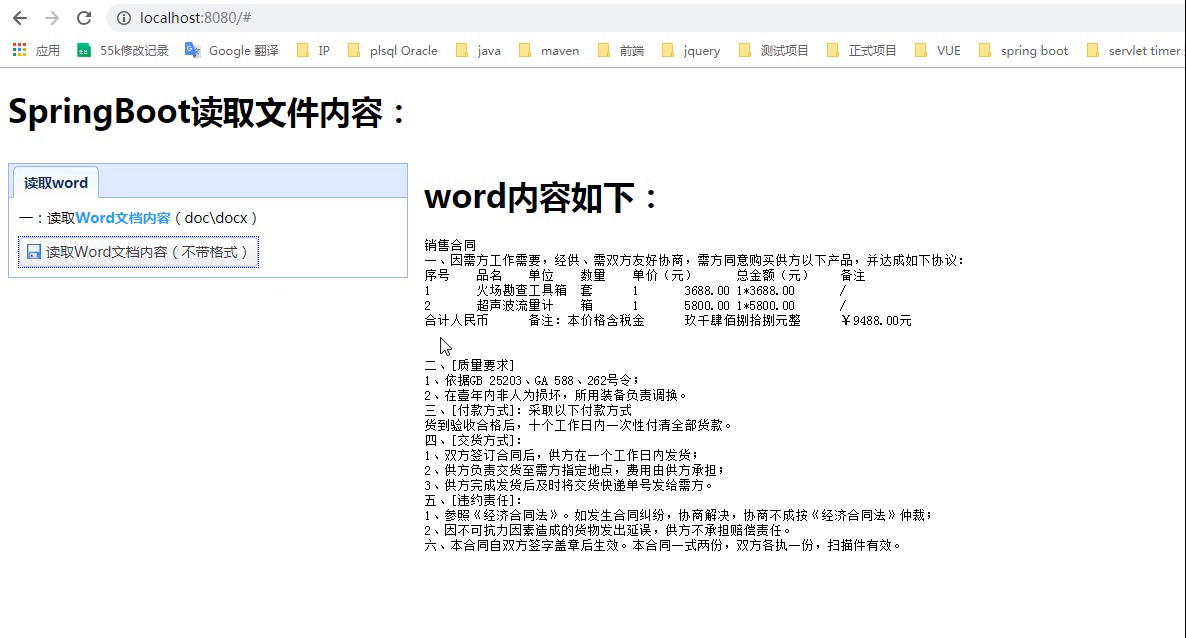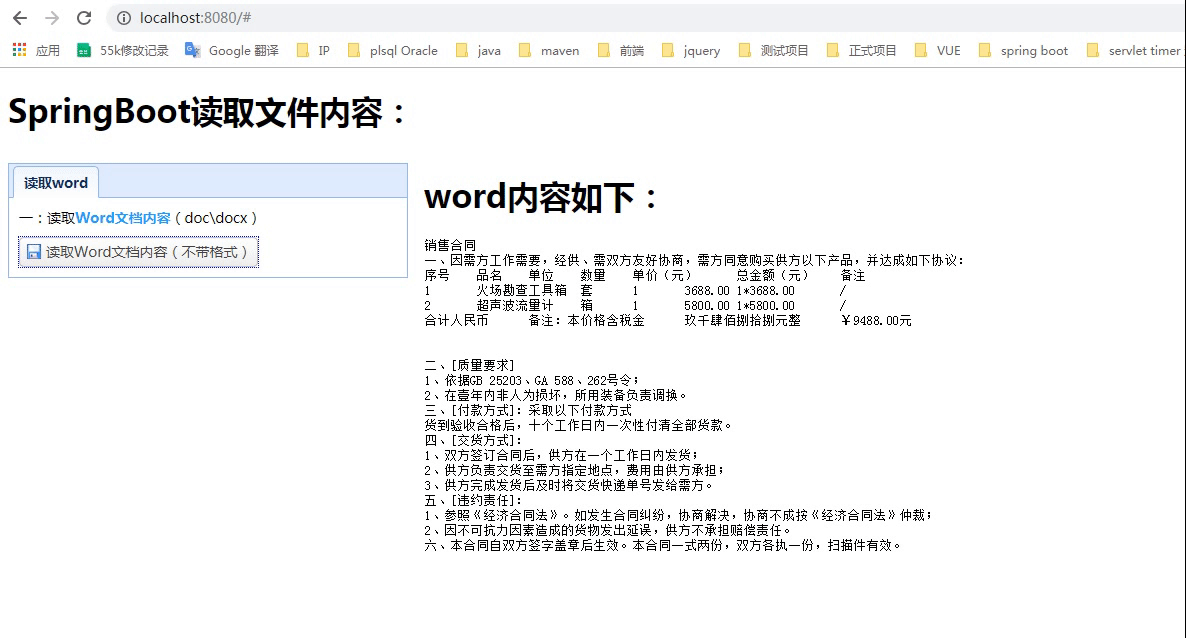
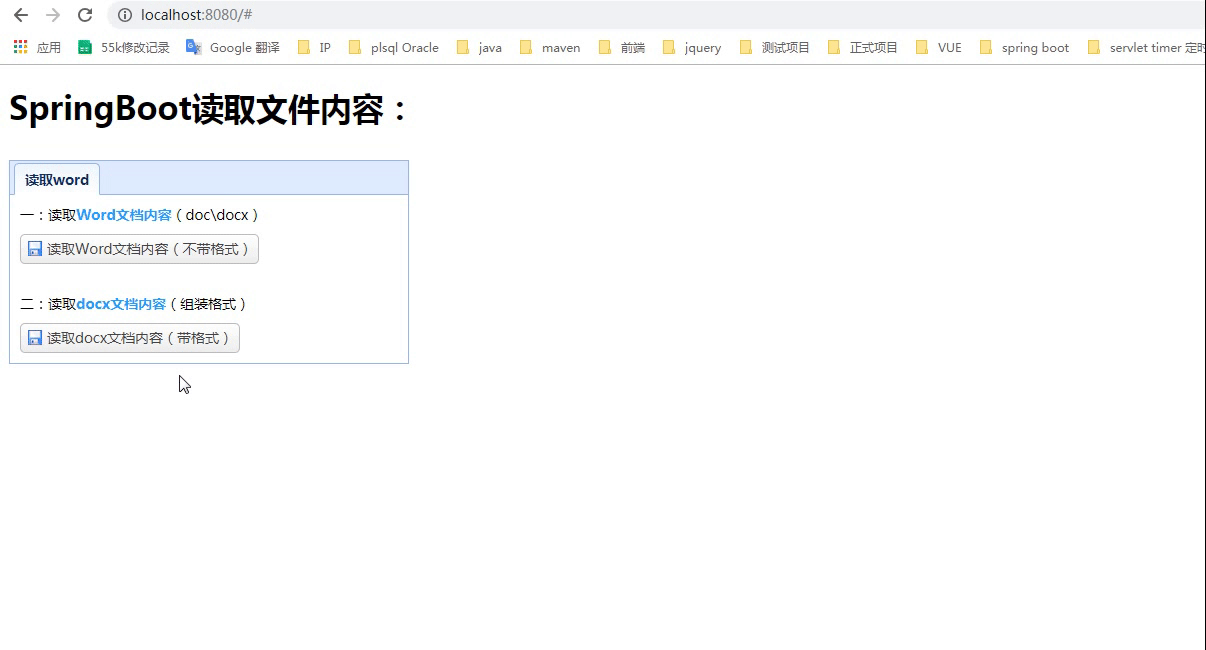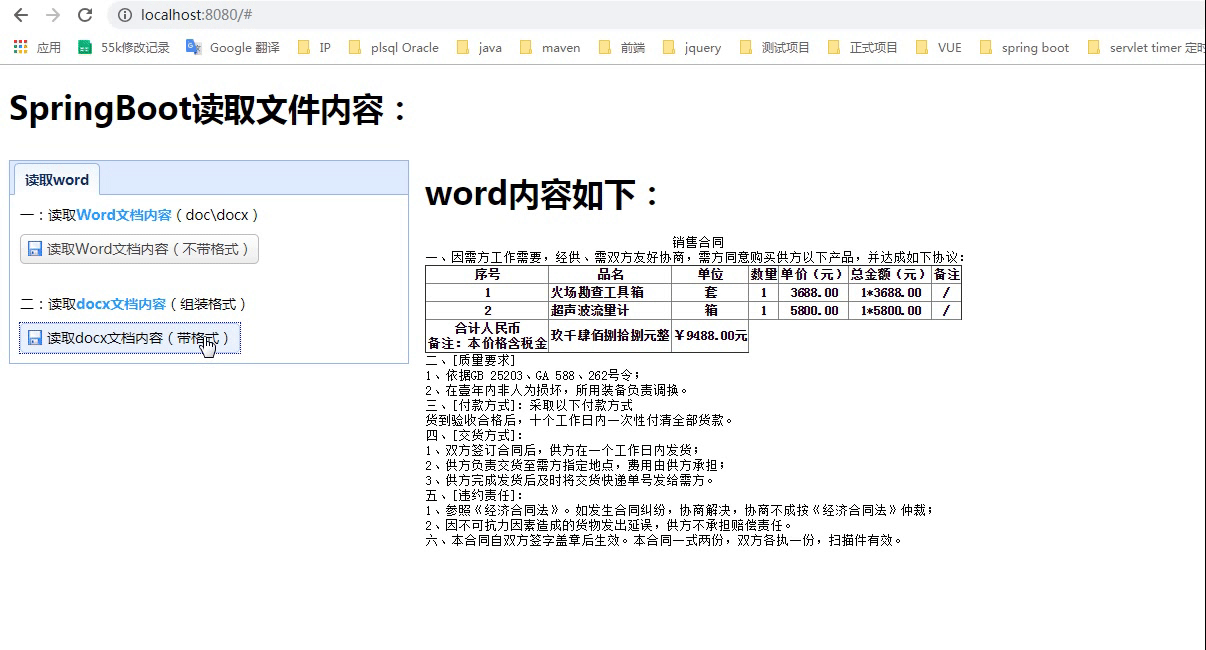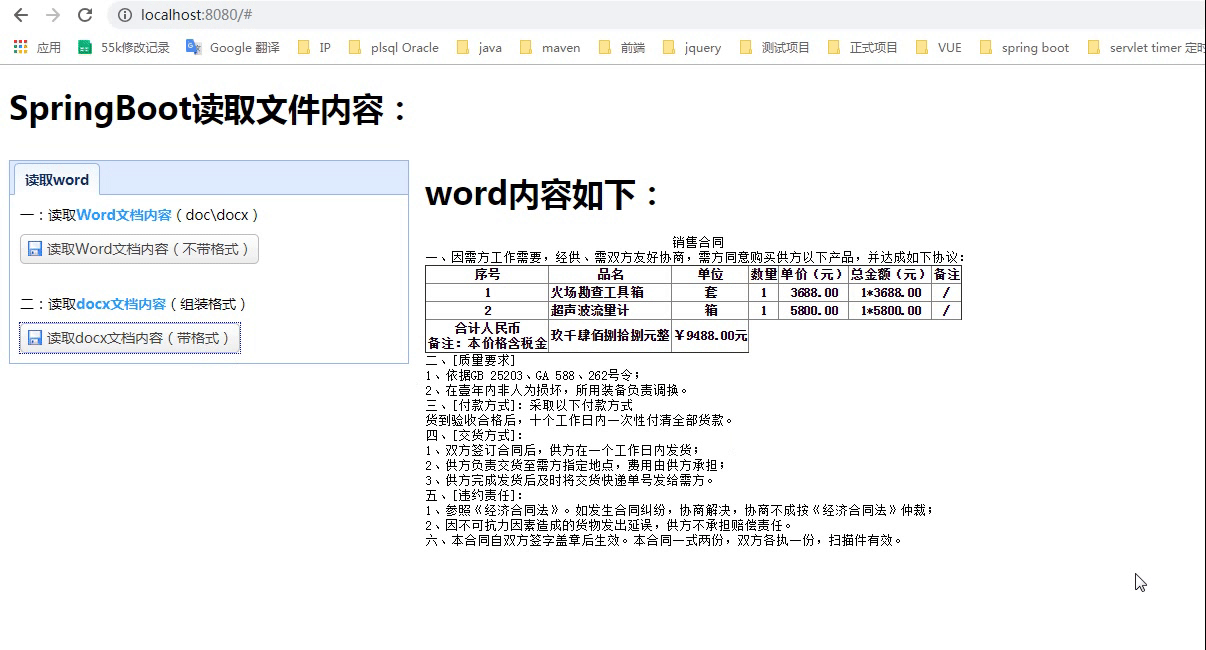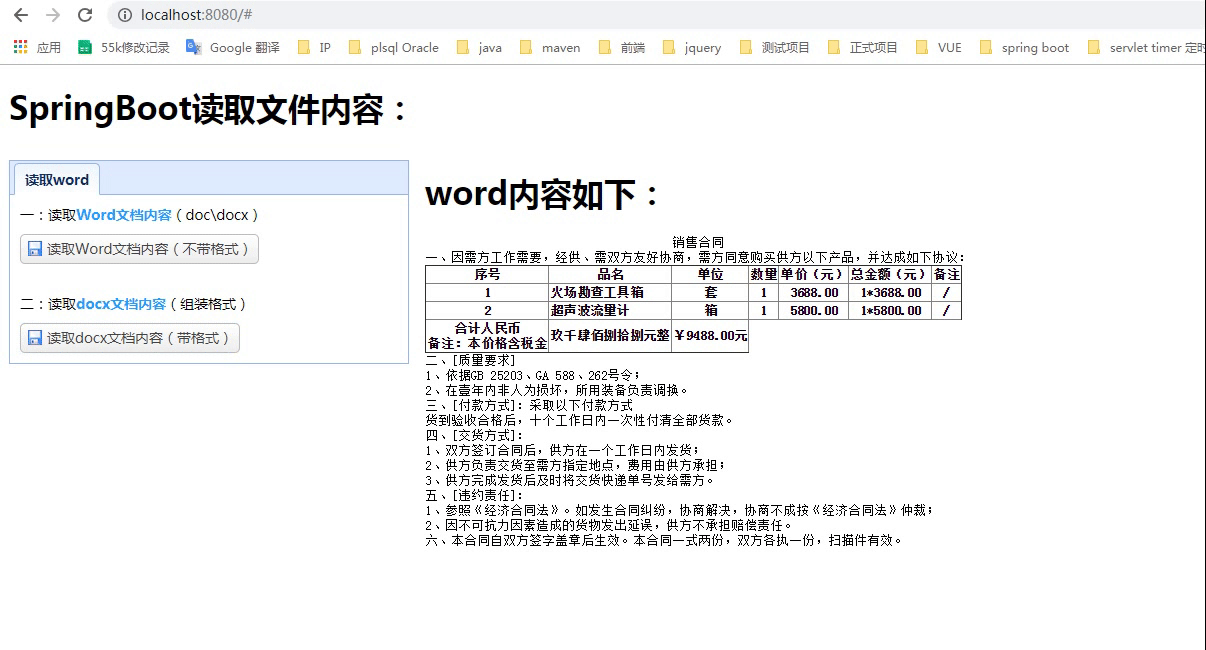 通过运行结果,我们看到表格格式出来了,但是有个待解决的问题,表格跨列合并。
通过运行结果,我们看到表格格式出来了,但是有个待解决的问题,表格跨列合并。 修改getTabelHtmlText方法,代码如下:
修改getTabelHtmlText方法,代码如下:


【本文地址】
今日新闻 |
推荐新闻 |