Java cpu 监控 分析 |
您所在的位置:网站首页 › java监控系统进程 › Java cpu 监控 分析 |
Java cpu 监控 分析
|
Abstract
在这篇文章中我们会综合性的介绍如何监控JVM cpu, thread 级别cpu, 以及如何通过JFR技术来分析JVM的CPU 问题. 如何获取CPU 这里我们会先介绍如何在进程内部获取JVM的CPU. 这里我们主要采用JVM 自带的JMX来实现对自己的监控. 获取整个系统的JVM cpu可以通过调用mbean中的getProcessCpuTime方法来得到中的cputime. 简单点来说就是: (cputime2 - cputime1)/1000000/elapseTimeInMs/processorCount 完整代码如下: package cpu; import com.sun.management.OperatingSystemMXBean; import java.lang.management.ManagementFactory; import java.util.concurrent.Executors; import java.util.concurrent.ScheduledExecutorService; import java.util.concurrent.ThreadFactory; import java.util.concurrent.TimeUnit; import java.util.concurrent.atomic.AtomicInteger; public class CpuTest { public static void main(String[] args) { final AtomicInteger seq = new AtomicInteger(0); ScheduledExecutorService es = Executors.newScheduledThreadPool(20, new ThreadFactory() { @Override public Thread newThread(Runnable r) { Thread th = new Thread(r); th.setName("consumingthreads-" + seq.incrementAndGet()); return th; } }); for (int i = 0; i < 200; i++) { es.scheduleAtFixedRate(new ConsumingCpuTask(), 0, 10, TimeUnit.MILLISECONDS); } // not terminate the es // another thread to print host cpu ScheduledExecutorService printer = Executors.newSingleThreadScheduledExecutor(new ThreadFactory() { @Override public Thread newThread(Runnable r) { Thread th = new Thread(r); th.setName("printer"); return th; } }); // print every 10 seconds printer.scheduleAtFixedRate(new PrintCurrentProcessCpuTask(), 0, 10, TimeUnit.SECONDS); } static final int PROCESSOR_COUNT = Runtime.getRuntime().availableProcessors(); // notice here is com.sun.management.OperatingSystemMXBean and it's not java.lang.management.OperatingSystemMXBean static final OperatingSystemMXBean bean = (OperatingSystemMXBean) ManagementFactory.getOperatingSystemMXBean(); /** * get process cpu in nanoseconds */ static double getProcessCpuTime() { return bean.getProcessCpuTime(); } /** * A task to simulate consuming cpu */ static class ConsumingCpuTask implements Runnable { @Override public void run() { AtomicInteger integer = new AtomicInteger(0); for (int i = 0; i < 10000; i++) { integer.incrementAndGet(); } } } static class PrintCurrentProcessCpuTask implements Runnable { double cpuTime = 0; long collectTime = 0; @Override public void run() { if (cpuTime == 0) { cpuTime = getProcessCpuTime(); collectTime = System.currentTimeMillis(); } else { double newCpuTime = getProcessCpuTime(); long newCollectTime = System.currentTimeMillis(); double cpu = (newCpuTime - cpuTime) / (newCollectTime - collectTime) / 1000_000 / PROCESSOR_COUNT; cpuTime = newCpuTime; collectTime = newCollectTime; System.out.println(String.format("Process cpu is: %.2f %%", cpu * 100)); } } } }当你运行这个代码就可以看到定时打出的cpu指标,比如在我的机器上是17%左右(本身有16核):
而这个值跟系统显示也是一致的(mac端的Activity Monitor/top命令):
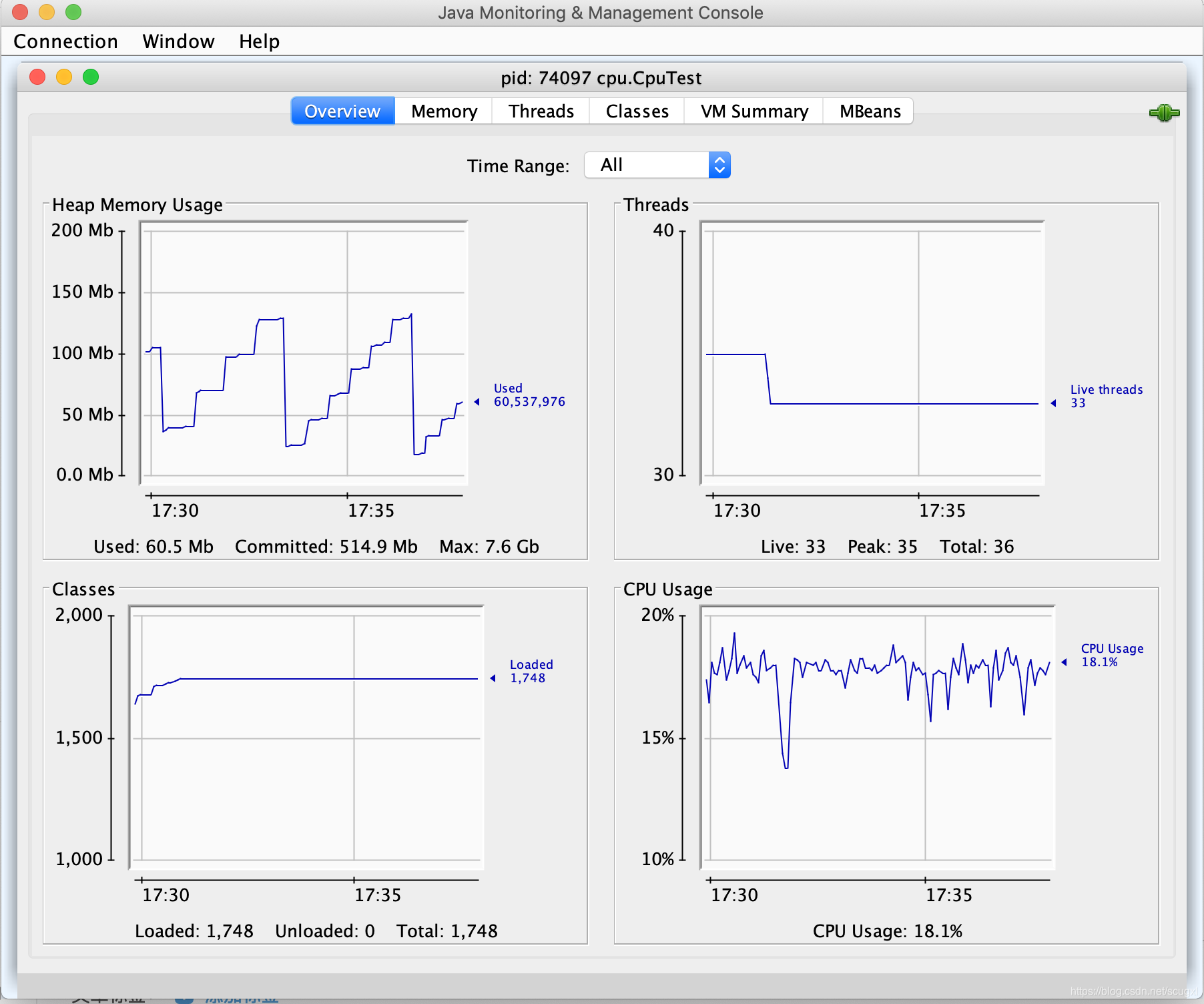
或者用Java自带的Jconsole 可以看(是JDK自带的工具, 在bin目录),运行jconsole
选择关注的进程:
获取系统中各个线程的CPU 这里我们会展示如何获取系统中各个线程的CPU 这个也很好统计. 获取线程的cpu主要通过ThreadMXBean获取: // it's com.sun.management.ThreadMXBean static ThreadMXBean threadMXBean = (ThreadMXBean) ManagementFactory.getThreadMXBean(); static class PrintThreadCpuTask implements Runnable { // not consider thread safe here Map threadId2CpuTime = null; Map threadId2Name = null; private long collectTime = 0; @Override public void run() { if (threadId2CpuTime == null) { threadId2CpuTime = new HashMap(); threadId2Name = new HashMap(); long threads[] = threadMXBean.getAllThreadIds(); long cpuTimes[] = threadMXBean.getThreadCpuTime(threads); for (int i = 0; i < threads.length; i++) { threadId2CpuTime.put(threads[i], cpuTimes[i]); // get the thread name // maybe null, if not exists any more ThreadInfo info = threadMXBean.getThreadInfo(threads[i]); if (info != null) { threadId2Name.put(threads[i], info.getThreadName()); } } collectTime = System.currentTimeMillis(); } else { long threads[] = threadMXBean.getAllThreadIds(); long cpuTimes[] = threadMXBean.getThreadCpuTime(threads); Map newthreadId2CpuTime = new HashMap(); for (int i = 0; i < threads.length; i++) { newthreadId2CpuTime.put(threads[i], cpuTimes[i]); } long newCollectTime = System.currentTimeMillis(); threadId2CpuTime.entrySet().forEach(en -> { long threadId = en.getKey(); Long time = en.getValue(); Long newTime = newthreadId2CpuTime.get(threadId); if (newTime != null) { double cpu = (newTime - time) * 1.0d / (newCollectTime - collectTime) / 1000000L / PROCESSOR_COUNT; System.out.println(String.format("\t\tThread %s cpu is: %.2f %%", threadId2Name.get(threadId), cpu * 100)); } threadId2CpuTime.put(threadId, newTime); }); } } }输出如下:
JFR(Java flying recorder), 是java内置的一个性能数据采集器. 可以详细的获取JVM内部的状态和事件. JFR分析示例通过如下的命令激活JFR: java -XX:+UnlockCommercialFeatures -XX:+FlightRecorder cpu.CpuTest运行后通过内置的JCMD就可以进行采集等操作(JCMD 还有其他命令比如JFR.check 等.)
这个文件可以通过JMC(Java mission control)打开, 直接运行jmc即可 (也在jdk/bin下面): 在这里面就可以看到热点方法:
JFR本身还支持很多事件的采集包括GC/IO等. Reference:https://docs.oracle.com/javacomponents/jmc-5-4/jfr-runtime-guide/about.htm 一个实际例子在产品环境中发现的一个问题, 客户会周期的执行一些snmp数据采集任务集合A, 然后每隔一段时间又会执行另外的任务集合B(此时A也在同步执行), 发现此时B执行时, CPU比较高, 这是正常的因为任务B本身比较耗CPU, 但是发现任务B完成后, CPU依然很高, 并没有下降的趋势. CPU图形如下:
1. 分析了任务A的成功率并没有变化. 2. 我们对比了前后的线程是否有增减, 找到了一个Windows selector 但是一查CPU 也没有明显的变化(~3%). 3. 最后我们用前面的脚本查询了前后两次的所有线程的CPU 发现了, snmp相关的线程cpu每个都从1.5% 增加到了 7%. 59 lm-collector-snmp-transport--4-1=1.61 60 lm-collector-snmp-transport--4-2=1.48 61 lm-collector-snmp-transport--4-3=1.56 62 lm-collector-snmp-transport--4-4=1.80 64 lm-collector-snmp-transport--4-5=1.64 65 snmp-selector=1.22 66 lm-collector-snmp-transport--4-6=1.41 67 lm-collector-snmp-transport--4-7=1.46 68 lm-collector-snmp-transport--4-10=1.77 69 lm-collector-snmp-transport--4-9=1.51 70 lm-collector-snmp-transport--4-8=1.884. 然后突然想起来了 好像我们底层是共享的snmp 发送线程, 然后又因为有流控. 所以总共10组线程会每隔10ms 做一个host的发送任务. 但是在任务B中我们新加进来了很多任务(每个host新加了一个任务,然后在这10个线程中),相当于以前有900个host, 我们的线程组就会: 每10ms 执行900 次任务了, 然后B任务执行时, 又加了900个任务进来就是每10ms执行1800个任务. 这个对ScheduleExecutorService来说可能是个不小的性能问题. 5. 验证猜想. 我们dump 2次JFR也发现了: B任务执行前:
B任务执行后:
注意这个Context Switch count 被Double了, 还有ScheduledThreadPool中的siftDown方法也被调用更加频繁了. 这个我本来最开始发现这个每个snmp线程的samplecount变多了, 但是感觉没有多很多, 就没去管. 实际上发现有还是多了很多的. 解决办法嘛, 还在思考之中~~~~ 博客代码:https://github.com/gaoxingliang/goodutils/blob/master/src/cpu/CpuTest.java |









【本文地址】