SpringBoot整合WebMagic实现爬虫(简单整合含gitee源码) |
您所在的位置:网站首页 › java爬虫webmagic › SpringBoot整合WebMagic实现爬虫(简单整合含gitee源码) |
SpringBoot整合WebMagic实现爬虫(简单整合含gitee源码)
|
SpringBoot整合WebMagic
前言
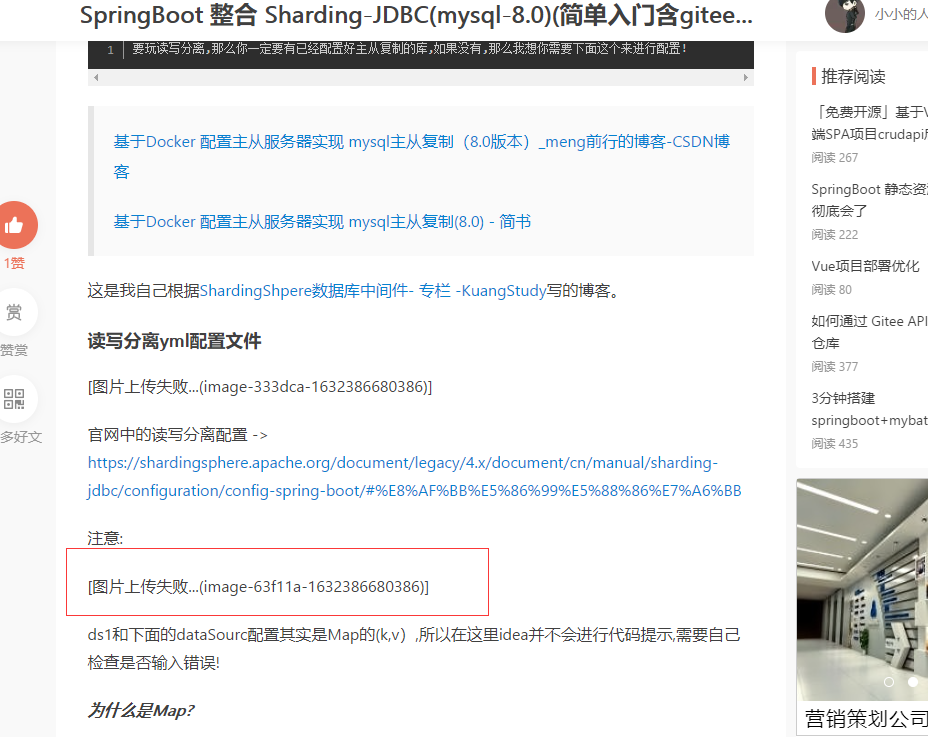
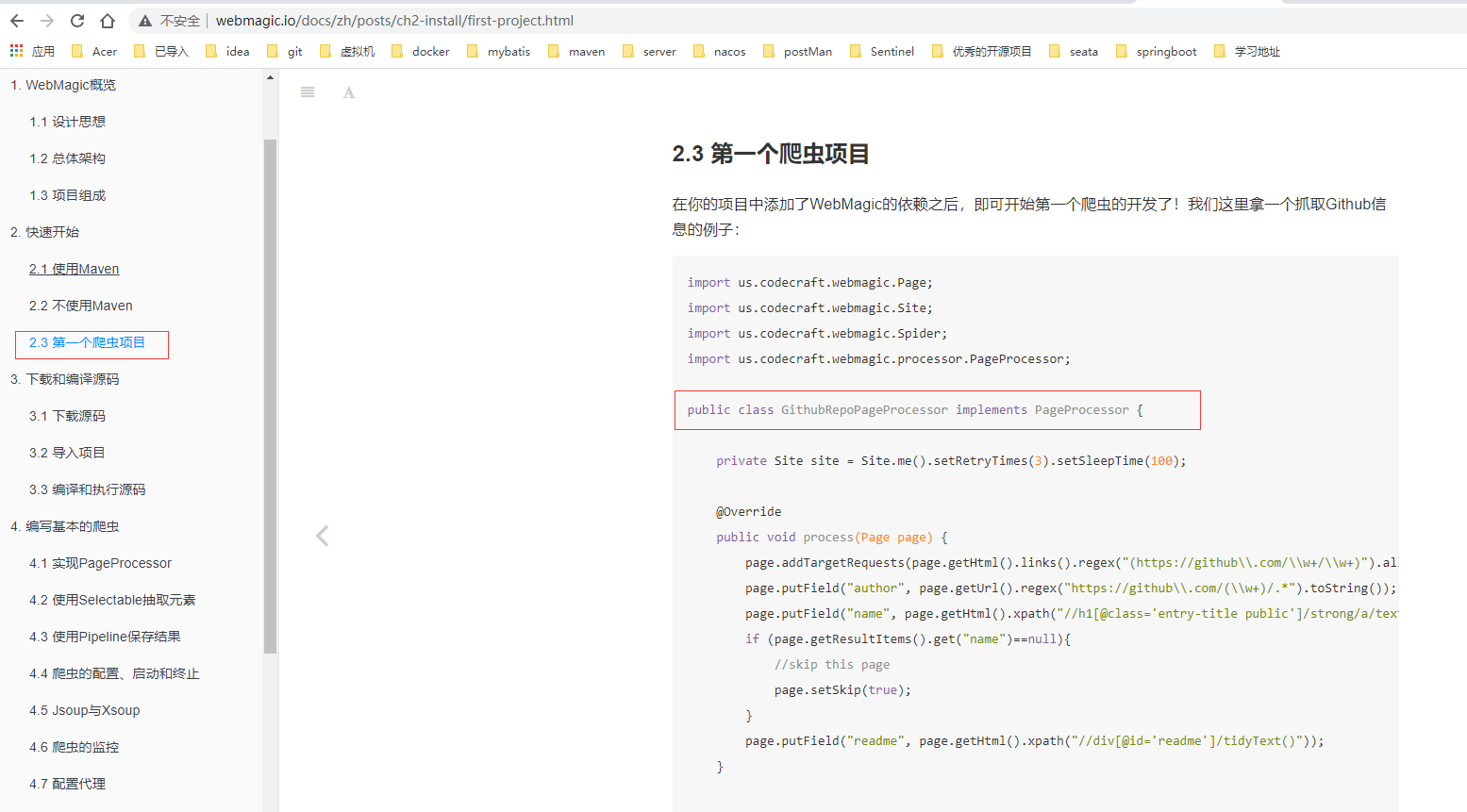
为什么我要整合WebMagic ? WebMagic是一个简单灵活的Java爬虫框架。基于WebMagic,你可以快速开发出一个高效、易维护的爬虫。 因为部分网站它不支持外链图片上传,而我已经把我的图片资源上传了,所以我需要把所有的资源进行获取整合再在部分网站重新上传; 举个🌰: 红框里的就是上传失败的。 很无奈,人家不支持外链地址,那没有办法,自己重新上传吧! 所以我通过WebMagic进行爬取我放置在其他网站的博客再进行上传。 如下🌰: 爬取后获得的资源: jdk - version - 1.8 maven - version - 3.8.1 SpringBoot - version - 2.2.2.RELEASE Swagger - version - 2.7.0 remark - version - 1.0.0 webmagic - version - 0.7.3 其他 参考pom 项目地址gitee地址: https://gitee.com/zjydzyjs/spring-boot-use-case-collection/tree/master/webmagic 前置知识 WebMagic 需自主学习 webmagic官网 webmagic详情文档 这里说一下我的感慨,webmagic的作者是真厉害,他再官方上也说了,该框架是他自己业余开发,这个精神值得佩服,在此感谢作者(Yihua Huang); 假设你已经学习了该项目,可以继续学习了。 WebMagic 简单测试 文档中的第一个用例: 你可以再idea中进行搜索(快速按两次 shift),输入GithubRepoPageProcessor类就可以发现这个作者已经写好的用例了,我们可以测试一下。 package us.codecraft.webmagic.processor.example; import us.codecraft.webmagic.Page; import us.codecraft.webmagic.Site; import us.codecraft.webmagic.Spider; import us.codecraft.webmagic.processor.PageProcessor; public class GithubRepoPageProcessor implements PageProcessor { private Site site = Site.me().setRetryTimes(3).setSleepTime(1000).setTimeOut(10000); public GithubRepoPageProcessor() { } public void process(Page page) { page.addTargetRequests(page.getHtml().links().regex("(https://github\\.com/[\\w\\-]+/[\\w\\-]+)").all()); page.addTargetRequests(page.getHtml().links().regex("(https://github\\.com/[\\w\\-])").all()); page.putField("author", page.getUrl().regex("https://github\\.com/(\\w+)/.*").toString()); page.putField("name", page.getHtml().xpath("//h1[@class='public']/strong/a/text()").toString()); if (page.getResultItems().get("name") == null) { page.setSkip(true); } page.putField("readme", page.getHtml().xpath("//div[@id='readme']/tidyText()")); } public Site getSite() { return this.site; } public static void main(String[] args) { Spider.create(new GithubRepoPageProcessor()).addUrl(new String[]{"https://github.com/code4craft"}).thread(5).run(); } }你直接通过通过以下用例进行调用就可以测试了,在类{@link com.blacktea.webmagic.demo.WebMagicTest}里, @Test void testDemo1(){ Spider.create(new GithubRepoPageProcessor()) .addUrl(new String[]{"https://github.com/code4craft"}) .thread(5).run(); }运行得到错误内容: 10:34:13.307 [main] DEBUG us.codecraft.webmagic.scheduler.QueueScheduler - push to queue https://github.com/code4craft 10:34:13.730 [main] INFO us.codecraft.webmagic.Spider - Spider github.com started! 10:34:13.762 [pool-1-thread-1] DEBUG org.apache.http.client.protocol.RequestAddCookies - CookieSpec selected: standard 10:34:13.766 [pool-1-thread-1] DEBUG org.apache.http.client.protocol.RequestAuthCache - Auth cache not set in the context 10:34:13.766 [pool-1-thread-1] DEBUG org.apache.http.impl.conn.PoolingHttpClientConnectionManager - Connection request: [route: {s}->https://github.com:443][total kept alive: 0; route allocated: 0 of 100; total allocated: 0 of 5] 10:34:13.774 [pool-1-thread-1] DEBUG org.apache.http.impl.conn.PoolingHttpClientConnectionManager - Connection leased: [id: 0][route: {s}->https://github.com:443][total kept alive: 0; route allocated: 1 of 100; total allocated: 1 of 5] 10:34:13.775 [pool-1-thread-1] DEBUG org.apache.http.impl.execchain.MainClientExec - Opening connection {s}->https://github.com:443 10:34:13.778 [pool-1-thread-1] DEBUG org.apache.http.impl.conn.DefaultHttpClientConnectionOperator - Connecting to github.com/140.82.112.4:443 10:34:13.778 [pool-1-thread-1] DEBUG org.apache.http.conn.ssl.SSLConnectionSocketFactory - Connecting socket to github.com/140.82.112.4:443 with timeout 10000 10:34:14.052 [pool-1-thread-1] DEBUG org.apache.http.conn.ssl.SSLConnectionSocketFactory - Enabled protocols: [TLSv1] 10:34:14.052 [pool-1-thread-1] DEBUG org.apache.http.conn.ssl.SSLConnectionSocketFactory - Enabled cipher suites:[TLS_ECDHE_ECDSA_WITH_AES_256_CBC_SHA, TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA, TLS_RSA_WITH_AES_256_CBC_SHA, TLS_ECDH_ECDSA_WITH_AES_256_CBC_SHA, TLS_ECDH_RSA_WITH_AES_256_CBC_SHA, TLS_DHE_RSA_WITH_AES_256_CBC_SHA, TLS_DHE_DSS_WITH_AES_256_CBC_SHA, TLS_ECDHE_ECDSA_WITH_AES_128_CBC_SHA, TLS_ECDHE_RSA_WITH_AES_128_CBC_SHA, TLS_RSA_WITH_AES_128_CBC_SHA, TLS_ECDH_ECDSA_WITH_AES_128_CBC_SHA, TLS_ECDH_RSA_WITH_AES_128_CBC_SHA, TLS_DHE_RSA_WITH_AES_128_CBC_SHA, TLS_DHE_DSS_WITH_AES_128_CBC_SHA, TLS_EMPTY_RENEGOTIATION_INFO_SCSV] 10:34:14.052 [pool-1-thread-1] DEBUG org.apache.http.conn.ssl.SSLConnectionSocketFactory - Starting handshake 10:34:14.314 [pool-1-thread-1] DEBUG org.apache.http.impl.conn.DefaultManagedHttpClientConnection - http-outgoing-0: Shutdown connection 10:34:14.314 [pool-1-thread-1] DEBUG org.apache.http.impl.execchain.MainClientExec - Connection discarded 10:34:14.314 [pool-1-thread-1] DEBUG org.apache.http.impl.conn.PoolingHttpClientConnectionManager - Connection released: [id: 0][route: {s}->https://github.com:443][total kept alive: 0; route allocated: 0 of 100; total allocated: 0 of 5] 10:34:14.316 [pool-1-thread-1] WARN us.codecraft.webmagic.downloader.HttpClientDownloader - download page https://github.com/code4craft error javax.net.ssl.SSLHandshakeException: Received fatal alert: protocol_version at sun.security.ssl.Alert.createSSLException(Alert.java:131) at sun.security.ssl.Alert.createSSLException(Alert.java:117) at sun.security.ssl.TransportContext.fatal(TransportContext.java:340) at sun.security.ssl.Alert$AlertConsumer.consume(Alert.java:293) at sun.security.ssl.TransportContext.dispatch(TransportContext.java:186) at sun.security.ssl.SSLTransport.decode(SSLTransport.java:154) at sun.security.ssl.SSLSocketImpl.decode(SSLSocketImpl.java:1279) at sun.security.ssl.SSLSocketImpl.readHandshakeRecord(SSLSocketImpl.java:1188) at sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:401) at sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:373) at org.apache.http.conn.ssl.SSLConnectionSocketFactory.createLayeredSocket(SSLConnectionSocketFactory.java:436) at org.apache.http.conn.ssl.SSLConnectionSocketFactory.connectSocket(SSLConnectionSocketFactory.java:384) at org.apache.http.impl.conn.DefaultHttpClientConnectionOperator.connect(DefaultHttpClientConnectionOperator.java:142) at org.apache.http.impl.conn.PoolingHttpClientConnectionManager.connect(PoolingHttpClientConnectionManager.java:374) at org.apache.http.impl.execchain.MainClientExec.establishRoute(MainClientExec.java:393) at org.apache.http.impl.execchain.MainClientExec.execute(MainClientExec.java:236) at org.apache.http.impl.execchain.ProtocolExec.execute(ProtocolExec.java:186) at org.apache.http.impl.execchain.RetryExec.execute(RetryExec.java:89) at org.apache.http.impl.execchain.RedirectExec.execute(RedirectExec.java:110) at org.apache.http.impl.client.InternalHttpClient.doExecute(InternalHttpClient.java:185) at org.apache.http.impl.client.CloseableHttpClient.execute(CloseableHttpClient.java:83) at us.codecraft.webmagic.downloader.HttpClientDownloader.download(HttpClientDownloader.java:85) at us.codecraft.webmagic.Spider.processRequest(Spider.java:404) at us.codecraft.webmagic.Spider.access$000(Spider.java:61) at us.codecraft.webmagic.Spider$1.run(Spider.java:320) at us.codecraft.webmagic.thread.CountableThreadPool$1.run(CountableThreadPool.java:74) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) 10:34:15.324 [main] INFO us.codecraft.webmagic.Spider - Spider github.com closed! 1 pages downloaded.那第一个例子就出现这个问题,那得解决呀,是吧? 于是我就在github的issues找到了该问题!
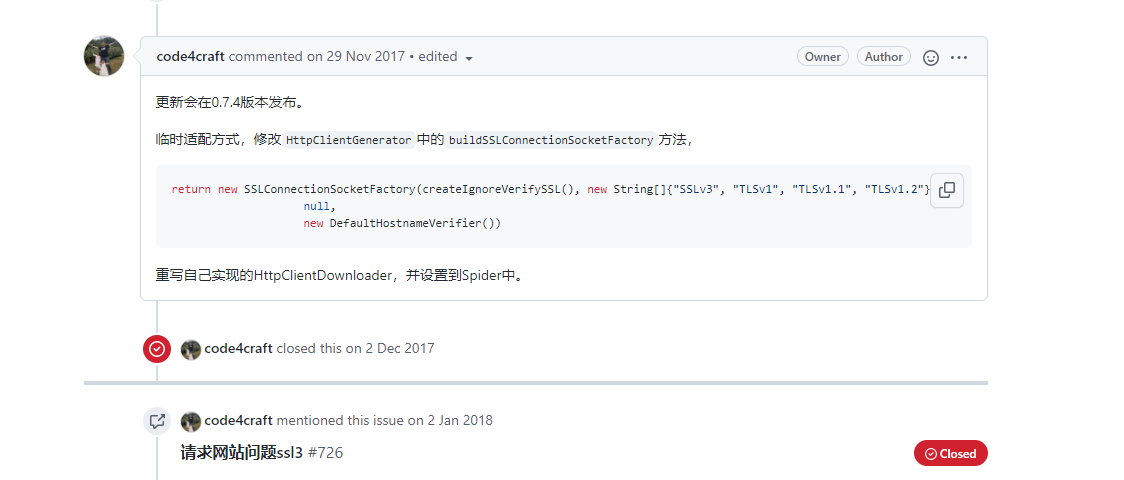
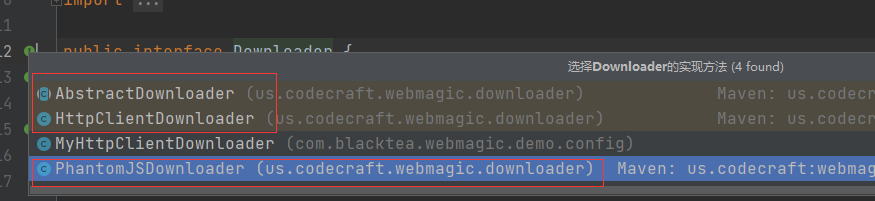
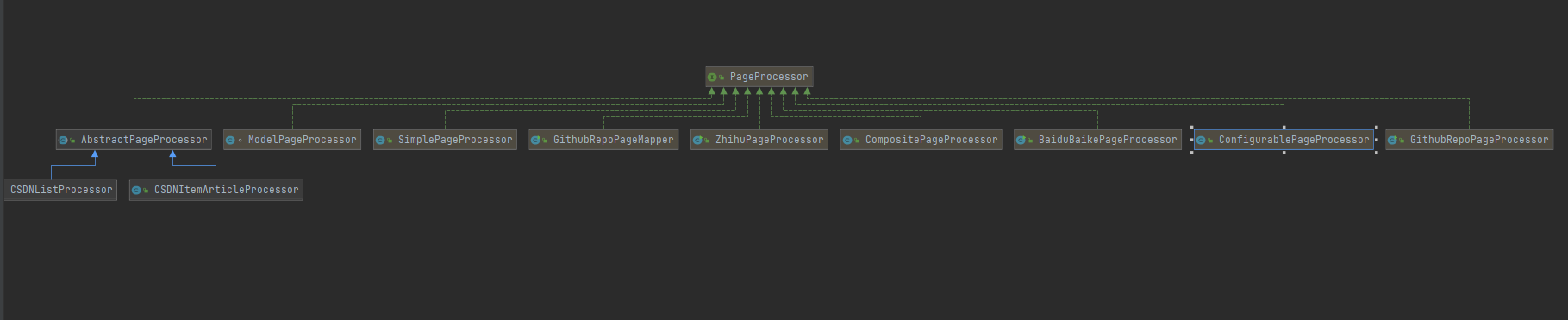
作者说是会在0.7.4中解决,你可能会说那我们换版本就好了,抱歉,作者可能是工作太忙了,所以0.7.4迟迟不出,那没办法,那咱们就自己改吧。 手动解决 protocol_version bug 先找到作者说的HttpClientGenerator类中的方法buildSSLConnectionSocketFactory, private SSLConnectionSocketFactory buildSSLConnectionSocketFactory() { try { return new SSLConnectionSocketFactory(this.createIgnoreVerifySSL()); } catch (KeyManagementException var2) { this.logger.error("ssl connection fail", var2); } catch (NoSuchAlgorithmException var3) { this.logger.error("ssl connection fail", var3); } return SSLConnectionSocketFactory.getSocketFactory(); }将里面的内容改造就行,不过因为是源码,如果你不想重新打包的话,就需要自己去重写引用HttpClientGenerator 如何知道在那里使用上HttpClientGenerator的? 官网说了,WebMagic的结构分为Downloader、PageProcessor、Scheduler、Pipeline四大组件, 那我们怎么知道这四大组件是怎么相互关联的呢? 可以从之前的那个GithubRepoPageProcessor类的执行方法中获得 Spider.create(new GithubRepoPageProcessor()) .addUrl(new String[]{"https://github.com/code4craft"}) .thread(5) .run(); 从上可以知道,执行一个爬取任务,需要通过Spider去启动,那我们查看一下 package us.codecraft.webmagic; ...... public class Spider implements Runnable, Task { protected Downloader downloader; protected List pipelines = new ArrayList(); protected PageProcessor pageProcessor; protected List startRequests; protected Site site; protected String uuid; protected Scheduler scheduler = new QueueScheduler(); protected Logger logger = LoggerFactory.getLogger(this.getClass()); protected CountableThreadPool threadPool; protected ExecutorService executorService; protected int threadNum = 1; protected AtomicInteger stat = new AtomicInteger(0); protected boolean exitWhenComplete = true; protected static final int STAT_INIT = 0; protected static final int STAT_RUNNING = 1; protected static final int STAT_STOPPED = 2; protected boolean spawnUrl = true; protected boolean destroyWhenExit = true; private ReentrantLock newUrlLock = new ReentrantLock(); private Condition newUrlCondition; private List spiderListeners; private final AtomicLong pageCount; private Date startTime; private int emptySleepTime; ...... 省略 /** @deprecated */ public Spider downloader(Downloader downloader) { return this.setDownloader(downloader); } public Spider setDownloader(Downloader downloader) { this.checkIfRunning(); this.downloader = downloader; return this; } public void run() { this.checkRunningStat(); this.initComponent(); this.logger.info("Spider {} started!", this.getUUID()); ...... this.logger.info("Spider {} closed! {} pages downloaded.", this.getUUID(), this.pageCount.get()); } protected void initComponent() { if (this.downloader == null) { // 在这里也看到了默认使用 HttpClientDownloader this.downloader = new HttpClientDownloader(); } if (this.pipelines.isEmpty()) { this.pipelines.add(new ConsolePipeline()); } this.downloader.setThread(this.threadNum); if (this.threadPool == null || this.threadPool.isShutdown()) { if (this.executorService != null && !this.executorService.isShutdown()) { this.threadPool = new CountableThreadPool(this.threadNum, this.executorService); } else { this.threadPool = new CountableThreadPool(this.threadNum); } } if (this.startRequests != null) { Iterator var1 = this.startRequests.iterator(); while(var1.hasNext()) { Request request = (Request)var1.next(); this.addRequest(request); } this.startRequests.clear(); } this.startTime = new Date(); } }从上面可以发现四个都有,我们点击进Downloader类 可以发现 三个实现类(红框内容,my那个是我自己实现的)! 然后你点进HttpClientDownloader类 package us.codecraft.webmagic.downloader; ...... @ThreadSafe public class HttpClientDownloader extends AbstractDownloader { private Logger logger = LoggerFactory.getLogger(this.getClass()); private final Map httpClients = new HashMap(); // 在这里就发现使用HttpClientGenerator private HttpClientGenerator httpClientGenerator = new HttpClientGenerator(); private HttpUriRequestConverter httpUriRequestConverter = new HttpUriRequestConverter(); private ProxyProvider proxyProvider; private boolean responseHeader = true; ......省略 }从以上我们知道了Spider类中有属性Download接口,该接口有实现类HttpClientDownloader,当你在执行Spider.run()时,run()会执行initComponent(),如果你没有设置Spider的download属性,就会自动的选择HttpClientDownloader作为实现类,而HttpClientDownloader中又使用了HttpClientGenerator作为参数,那我们既然要改HttpClientGenerator类中的方法buildSSLConnectionSocketFactory(),那就得重写HttpClientGenerator和Download 实现,得到**MyHttpClientGenerator和MyHttpClientDownloader**。 怎么使用新得Download实现?1.再在使用Spider得时候setDownloader(MyHttpClientDownloader),这样就可以了。 Spider.create(pageProcessor) .setDownloader(new MyHttpClientDownloader());2.或者增加一个类用于继承Spider类,重写initComponent()方法中得 protected void initComponent() { if (this.downloader == null) { // 修改这里为 this.downloader = new MyHttpClientDownloader(); this.downloader = new HttpClientDownloader(); } if (this.pipelines.isEmpty()) { this.pipelines.add(new ConsolePipeline()); } this.downloader.setThread(this.threadNum); if (this.threadPool == null || this.threadPool.isShutdown()) { if (this.executorService != null && !this.executorService.isShutdown()) { this.threadPool = new CountableThreadPool(this.threadNum, this.executorService); } else { this.threadPool = new CountableThreadPool(this.threadNum); } } if (this.startRequests != null) { Iterator var1 = this.startRequests.iterator(); while(var1.hasNext()) { Request request = (Request)var1.next(); this.addRequest(request); } this.startRequests.clear(); } this.startTime = new Date(); }再次执行testDemo1() @Test void testDemo1(){ // 出现错误 -> javax.net.ssl.SSLHandshakeException: Received fatal alert: protocol_version // Spider.create(new GithubRepoPageProcessor()) // .addUrl(new String[]{"https://github.com/code4craft"}) // .thread(5).run(); //使用MyHttpClientDownloader解决 protocol_version,但是可能出现github请求超时,这个与github访问有关系,我访问不了 Spider.create(new GithubRepoPageProcessor()) .addUrl(new String[]{"https://github.com/code4craft"}) .setDownloader(new MyHttpClientDownloader()) .thread(5).run(); } 官网其他用例 package us.codecraft.webmagic.processor; import us.codecraft.webmagic.Page; import us.codecraft.webmagic.Site; public interface PageProcessor { void process(Page var1); Site getSite(); }你可以通过查找PageProcessor接口得实现,得到官网用例,
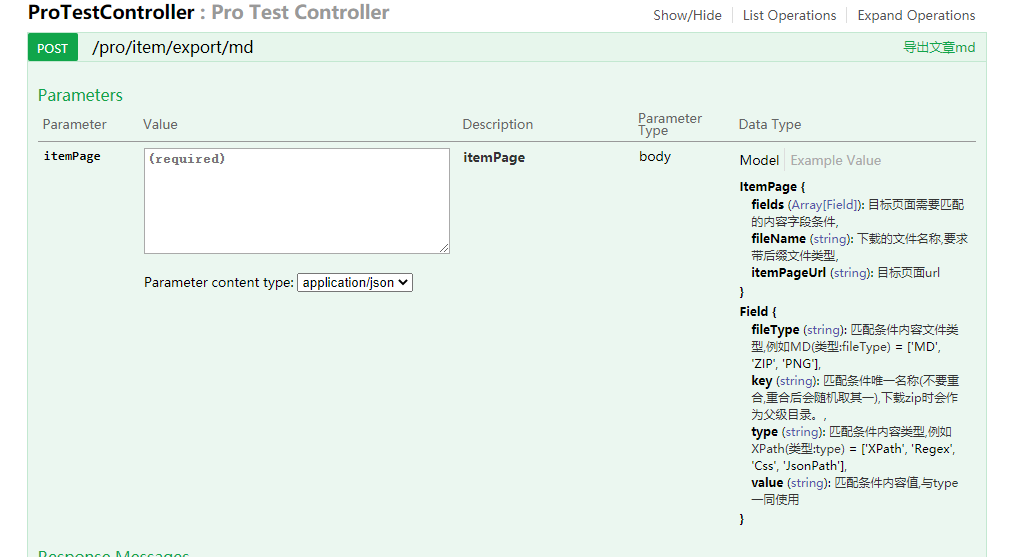
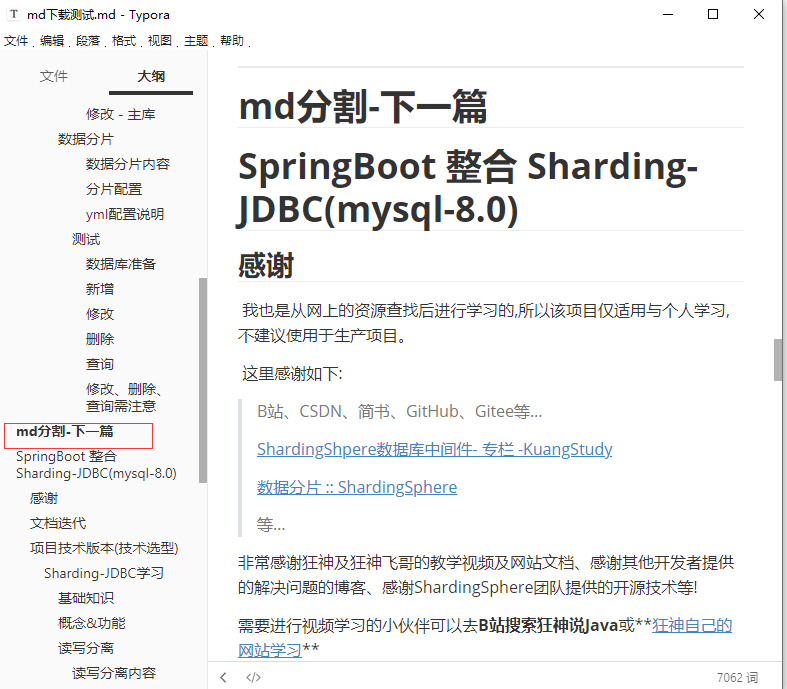
当前版本通过webmagic实现三个接口,可实现三个通用功能。 接口请求报文 名称必填类型说明fileNametrueString表示下载后得文件名称(要求带文件类型后缀);itemPageUrlfalseString目标页面地址;(该项与helpUrl、targetUrl是分开的,只有进行文章详情爬取的时候才需要itemPageUrl)helpUrlfalseString提供需要目标地址的页面url,例如CSDN的列表页;targetUrlfalseString找寻目标地址的匹配url,暂时仅支持 regx 匹配;fieldstrueList匹配规则集合,长度必须大于0keytrueString (Field.key)fields[index].key属性,用于标记该条规则得别名,在导出zip时,会自动将该key作为一级或二级(item一级,list二级)目录名称作为zip内文件分区valuetrueString (Field.value)fields[index].value属性,用于在页面中进行匹配得内容typetrueString (Field.type)fields[index].type属性,与Field.value进行组合使用,当前支持 [‘XPath’, ‘Regex’, ‘Css’, ‘JsonPath’],是对webmagi{@link us.codecraft.webmagic.model.annotation.Type}得复用,源码下得matchVal()方法fileTypetrueString (Field.fileType)fields[index].fileType属性,是对进行匹配后得到结果数据按照类型进行处理,源码下得getDataMap()方法 zip分区说明 为了区分匹配后获取的资源与避免文件名称重复导致文件被覆盖,我这里做了目录分区 1. 当你用itemPageUrl 时,文件结构为 xxx.zip/key/fileType; 2. 当你用`helpUrl and targetUrl`时,文件结构为第几个页面/key/fileType; 匹配结果调试WebMagicUtil.getSelectableValue() private static Object getSelectableValue(Field field,Page page, boolean all){ Selectable selectable = WebMagicUtil.matchVal(field, page); log.debug("当前field.key={},匹配的结果为:{}",field.getKey(),JSON.toJSONString(selectable.all())); if (Validator.isNotNull(selectable)){ // selectable get()/all(),看导出单个具体文件(md),还是压缩文件(zip) if (all){ return selectable.all(); }else { return selectable.get(); } } return null; }该方法会打印出符合的匹配结果的,默认打印全部结果。 1. 通用详情页导出md 1.1 swagger下载md文件使用swagger-ui进行md文件下载,地址 -> http://localhost:8000/pro/item/export/md post,application/json 多个key我会把多个key匹配到的内容一起写入到一个md,只要匹配到符合的内容在一个以上就会进行 额外拼接 “# md分割-下一篇\n\n”,再拼接下一篇。 1.3 效果
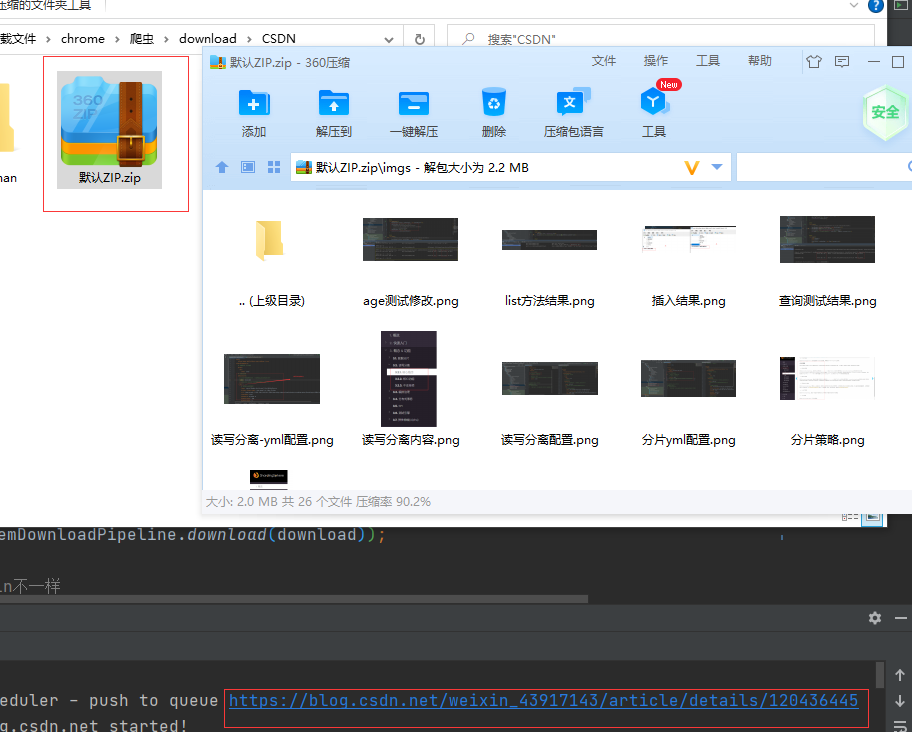
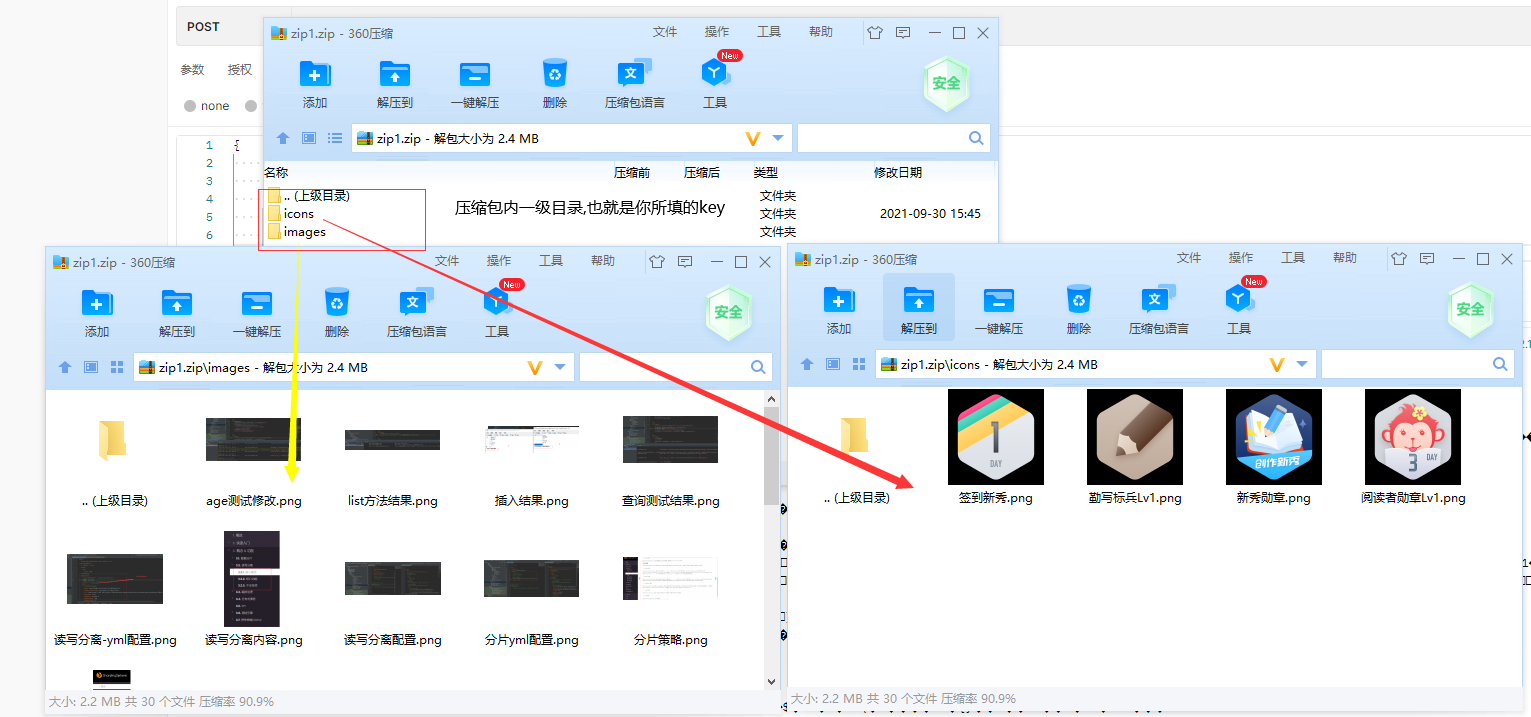
因为我这里爬取的匹配结果为2,所以我就会再拼接一条 “# md分割-下一篇\n\n”。 注意: 这里不是因为 fields.szie = 2,所以才导出2个的,是因为你所配置的规则匹配后的内容结果为2。 有可能你配置的规则没有匹配到内容 或者 配置 一个规则却可以出现多个拼接 多个拼接(多个根据WebMagicUtil.csdnProcess()的all参数决定)也是有可能的! all 为 false,即为符合当前这条field规则的最多只取一条,也就是一个匹配结果[0]拼接index=0, true,取出所有,也就是一个匹配结果[size],循环多个拼接。 2. 通用详情页导出zip ###### 2.1 swagger下载zip 使用swagger-ui进行zip文件下载,地址 -> http://localhost:8000/pro/item/export/zip post,application/json 2.2 jsonCSDN示例 { "fileName":"img下载测试.zip", "itemPageUrl":"https://blog.csdn.net/weixin_43917143/article/details/120436445", "fields":[ {"key":"images","value":"//*[@id=\"article_content\"]//*//img","type":"XPath","fileType":"PNG"}, {"key":"icons","value":"//div[@class=\"mouse-box\"]//img","type":"XPath","fileType":"PNG"} ] }这里建议使用postman进行测试,postman可以将最终结果文件流保存为zip文件 2.3 效果
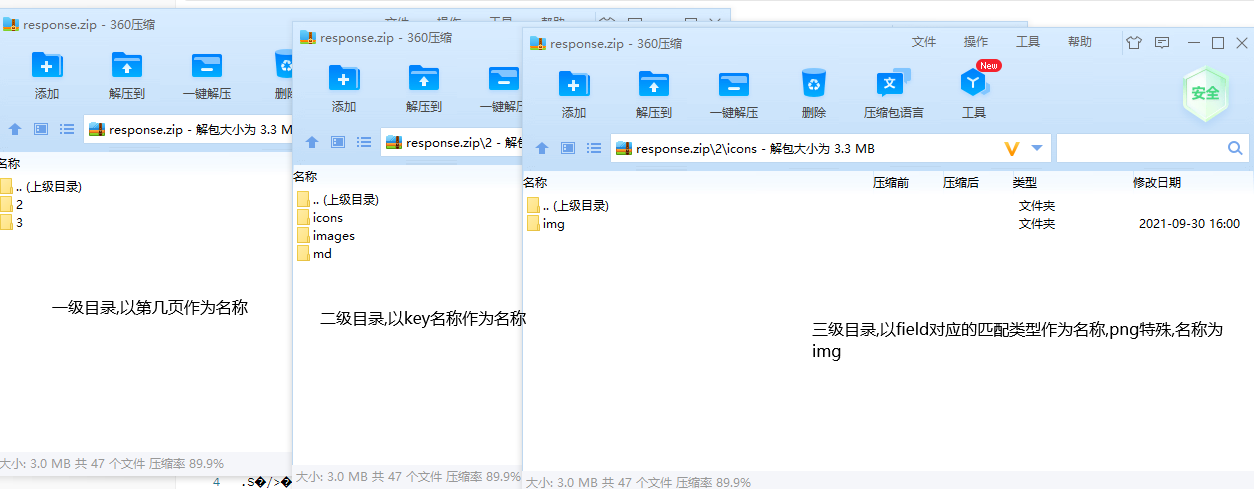
http://localhost:8000/pro/list/export/zip post,application/json 3.2 json CSDN示例: { "fileName":"xxx.zip", "helpUrl":"https://blog.csdn.net/weixin_43917143", "targetUrl":"(https://blog\\.csdn\\.net/weixin_43917143/article/details/\\w+)", "fields":[ {"key":"md","value":"//*[@id=\"article_content\"]/[@id=\"content_views\"]","type":"XPath","fileType":"MD"}, {"key":"images","value":"//*[@id=\"article_content\"]//*//img","type":"XPath","fileType":"PNG"}, {"key":"icons","value":"//div[@class=\"mouse-box\"]//img","type":"XPath","fileType":"PNG"} ] } 简书示例: { "fileName":"简书-xxx.zip", "helpUrl":"https://www.jianshu.com/u/7dcee71ee038", "targetUrl":"(https://www\\.jianshu\\.com/p/\\w+)", "fields":[ {"key":"md","value":"//div[@class=\"_gp-ck\"]/section[@class=\"ouvjEz\"][1]","type":"XPath","fileType":"MD"} ] } 3.3 效果CSDN效果:
|

【本文地址】
今日新闻 |
推荐新闻 |