双非本硕,成功上岸大数据开发 !!! |
您所在的位置:网站首页 › java开发转大数据开发值得吗 › 双非本硕,成功上岸大数据开发 !!! |
双非本硕,成功上岸大数据开发 !!!
|
校招生应届生写的大数据上岸过程比较少,很多应届毕业生想从事大数据开发,但是网上搜不到太多完整的上岸的过程,大部分都是面经之类的,所以想总结一下,不知道是否能帮助到有需要的人。 本文来自核心技术群优秀群友投稿: louwin 个人背景我觉得有必要写一下个人背景,没有个人背景的上岸过程就是耍流氓,有些人一开始说无竞赛,无论文,我一想那我来学习一下,最后知道是复旦本硕,这你不是搞我心态么。(狗头,如有冒犯,不要打我) 自己是双非本硕,大数据一年的练习生,喜欢rap篮球。 上岸过程靠自己的热爱学习,拿到大厂暑期实习,然后秋招上岸。贼简单的一句话需要细细展开来讲。 首先你需要热爱大数据,热爱是第一驱动力,我知道很多本硕选择大数据,是觉得后端或者别的太卷了,选择大数据是一种逃避手段,那我只能说对于大厂而言,大数据也很不容易,原因如下: 工作岗位比后端少得多很需要你实际的工作经验自己学习和工作脱轨的很严重很多大厂岗位分的极其细致,可能你看到的数据开发根本不适合你我个人觉得在大厂应届生及其卷的情况下,大数据逐渐神仙打架,如果是一线城市,那不好意思了,神仙下凡,那作为一个双非如何上岸呢? 第一,你是否真的喜欢大数据这一点很矛盾,虽然说越努力越热爱,但是一开始学习后是否很喜欢大数据对你的帮助真的很大,你能否接受从0开始接触一堆组件,而且可能是你本科完全没听过的东西,如果接触了以后很喜欢,那么恭喜你,你的起跑线和别人一样,但跑的速度可太快了,每天学自己热爱的东西,是多么幸福的事情,能让你最后坚持下来。如果不是真的喜欢,只是想找个工作,卷后端/前端/客户端靠谱多了,既然都卷,选岗位多,容易进的嘛。 第二,打扎实你的基础注意,我这里指的基础并不是大数据的基础,而是你计算机的基础,通俗的说就是科班素养,再具体点就是考研408科目(数据结构+操作系统+计算机网络+计算机组成原理),为啥喜欢科班的,就是因为再不怎么学,至少在脑子里留下一丢丢的印象,这些科目为我打下的基础让我受益匪浅,会对我的思考方式有帮助,甚至对解决问题的也有帮助,还有看计算机论文,看文档,画图的能力,都是平时锻炼出来的。 那如果非科班,或者平时真的学的不好怎么办呢,那当然是赶紧弥补,不过如果确定从事大数据的话,我觉得数据结构+操作系统足够了,可以稍微偷个懒,这两门课的重要性时时刻刻影响着我,他的思路在计算机很多领域都有影子。 其余的基础那就多了,编程语言,大数据思想,学了什么框架等等。校招生和社招生最大的区别就是,校招生最主要的是展示自己的潜力值得培养,你所学的一切东西在面试的时候都是为了展示这一点,我举一个面试遇到的问题:c在处理垃圾堆快和java自身靠jvm处理,你觉得有什么区别。这个问题是面试官结合人物背景和之前的聊天临时问的,如果你全靠背八股直接凉了,需要你当场思考给出回答,他不需要你回答标准答案,甚至这个问题就没有答案,但是面试官会通过你的当场思考来判断你的思维能力,如何思考并回答呢,答案就一个,基础是否扎实。 所以,如果还有几年才毕业的同学,好好打基础哟~ 想不到吧,秋招其实三月份就开始了 双非进大厂现在老难了,最好要找个暑期实习,不断是不是大公司,但需要找一个,基本上大厂的暑期实习3月份就开始了,而且有些其实就是秋招,默认你可以转正,我当时面试的有几个大厂直接就和我说,这个其实就是秋招直接转正的,所以会问的难一点,秋招不放hc了。 有实习经验对自己帮助很大,主要收获有以下几点: 1)工程能力,github/maven/shell/linux,这些常见的工程模块平时用的比较少,还以一些测试交接的流程熟悉以后,知道现实中工作是怎么样的。 2)结束实际中的海量数据,平时练习几十万条数据最多了,集群上的机器也很少,实习让你实际感受几十亿,几百亿的数据量,和庞大的集群,收获很多,会遇到很多想不到的问题,算是彻底入门了大数据。 3)对你的秋招帮助很大,尚且不说大厂实习如果转正,那你秋招有很大的底气,关键是如果没转正出去找工作,别人一看,实习过,那说明你具备一些实际的工作经验,同时有公司相信的潜力,这也让我有信心自己可以相信你的潜力。 所以,对于校招的大数据而言,不光是大数据,还有很多别的,但最终就是个展示自身潜力的过程。 学习的内容 编程语言类:java, scala(皮毛),python(皮毛),shell(皮毛)其实主要就是 java,面试的时候遇到的也是java,并发编程,jvm gc,基础的 collection 都问到了 数据结构!!!!:力扣不刷直接挂,除非学历很好 基础:要是非科班,有条件的话还是尽可能看一下数据结构和操作系统吧 hadoop组件:hadoop(会个基础的mr job,了解相关原理,看一下google的三驾马车),hbase(基础应用),hive(hql还是需要练习一下的) spark:sparkcore(可以看一下常用算子的源码),sparksql,主要就这两个,其余的有条件可以看一下spark streaming flink:时间足够的话可以看(推荐入门书籍flink基础教程,以及flink官方文档),之后自己做个简单的项目上手还是快的 消息队列:kafka,了解并使用一下,自己练项目也会用到 做项目带到的工具:flume,sqoop,datax,redis,说实话,项目做完我知道我用过,重新用的话还是对着文档写 项目:可视化小项目(java ssm框架基础实用),离线数仓(主要是hive),实时数仓(flink简单实用) 剩下的还是一些别的内容是实习过程中学到的,就暂时不写了。 面试遇到的内容 比较有意思的场景题或着开放题1)假如要一个没有存储上限的arraylist,怎么设计 2)c语言回收堆快时,和jvm相比你觉得有哪些不同 3)两个超级大表做关联,如果不用sql,让你直接设计计算过程怎么设计 4)常规的百万级别数据blablabla…… 5)你调研一个框架是如何调研的 6)java有单元测试,如果对sql做单元测试怎么设计 7)实际更新spark3之后,对比spark2在实际工作中全部是优点么 8)如何判断出现了shuffle,如何快速定位哪里出了问题 问题已经有写记不全了,选择了一些有意思的,我这里没有给出我当时的回答,每个人有每个人的思考方式,希望大家的思维可以发散。 结尾投稿本文的读者把春招实习/秋招遇到的问题放一起了,做一个简单概括,对于想转型大数据开发的小伙伴们具有一定的指导意义,大家也可以多去牛客上看看其他人写的面经。如果真的热爱大数据,请一起坚持下去,还是很有意思的。 对了,如果想跟投稿本文的优秀群友一样,加入我的核心技术交流群,与更多优秀的小伙伴学习,交流,欢迎大家扫码添加我的微信 zwj_bigdataer ,记得备注【昵称-城市-岗位】,我看到后会第一时间通过。 另外,我可以送上自己私藏的一份大数据礼包,对于99%的程序员学习大数据都是相当有帮助和指导意义的。 108套企业真题
|

 大数据面试宝典
大数据面试宝典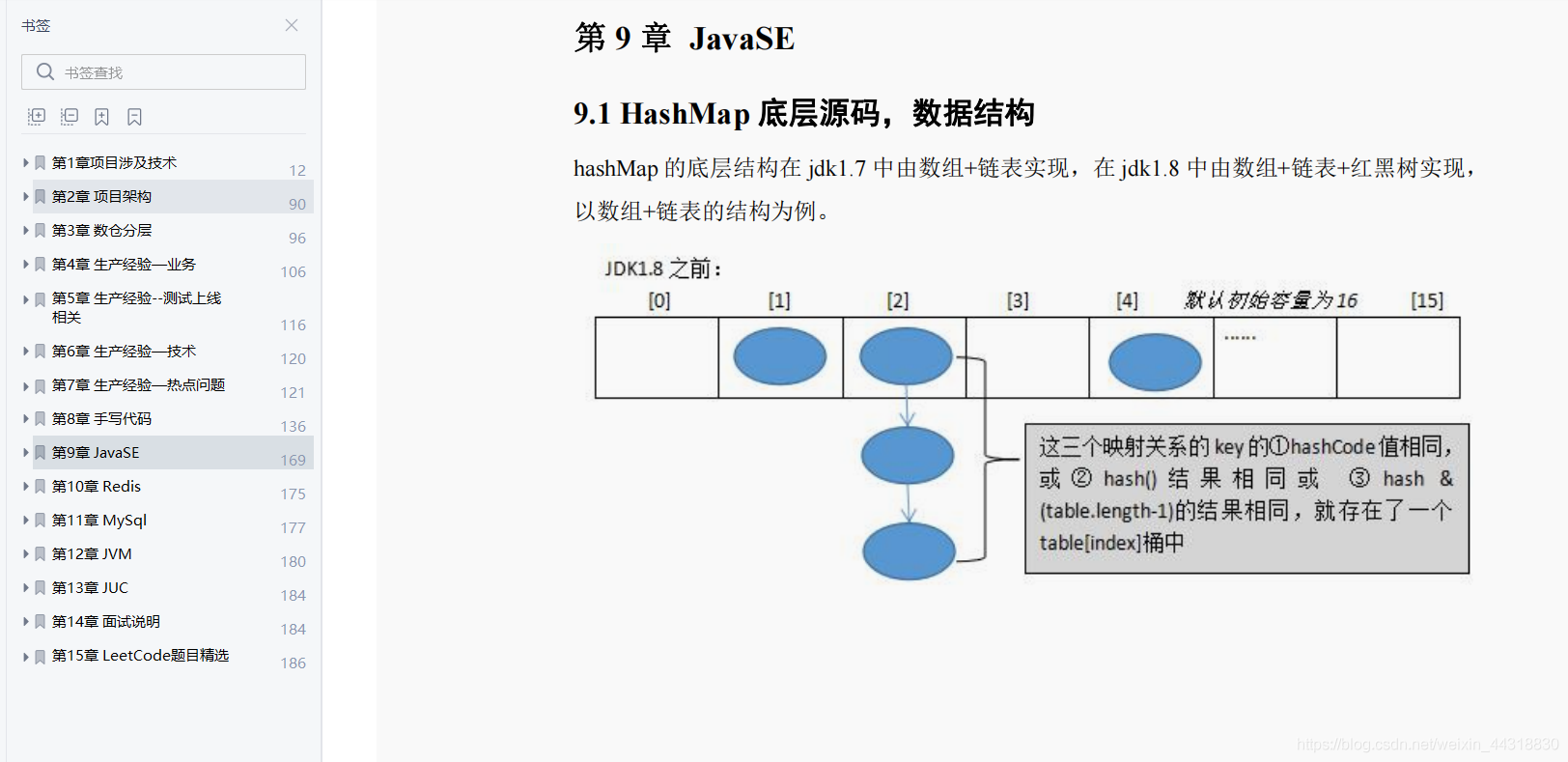
【本文地址】
今日新闻 |
推荐新闻 |