h = key.hashCode()) ^ (h >>> 16) 详细解读以及为什么要将hashCode值右移16位并且与原来的hashCode值进行异或操作 |
您所在的位置:网站首页 › java中的hashcode是什么值 › h = key.hashCode()) ^ (h >>> 16) 详细解读以及为什么要将hashCode值右移16位并且与原来的hashCode值进行异或操作 |
h = key.hashCode()) ^ (h >>> 16) 详细解读以及为什么要将hashCode值右移16位并且与原来的hashCode值进行异或操作
|
h = key.hashCode()) ^ (h >>> 16) 详细解读
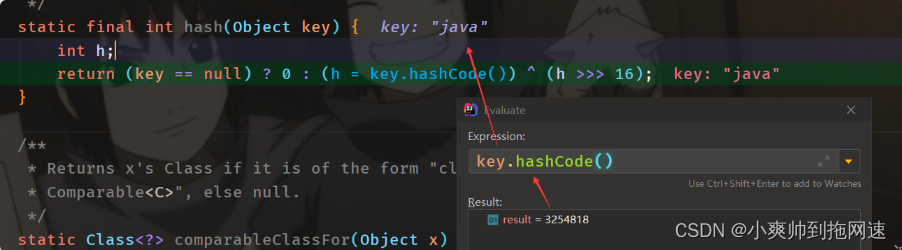
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
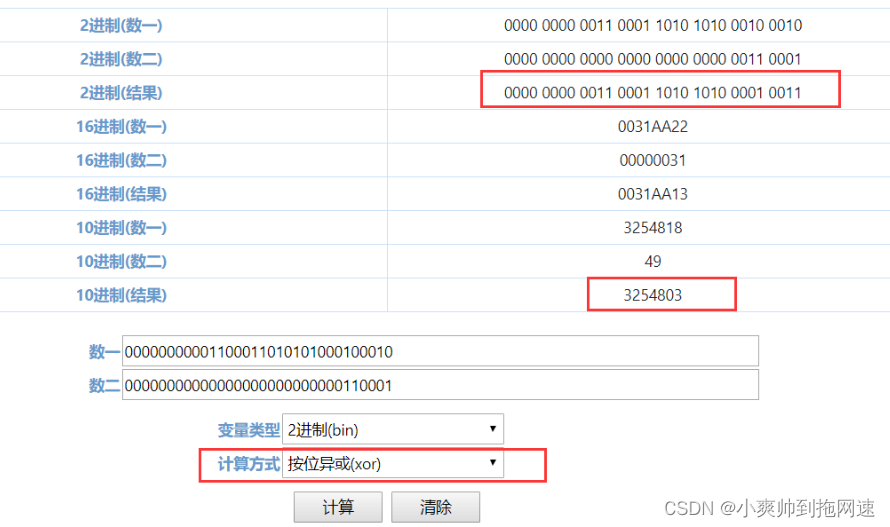
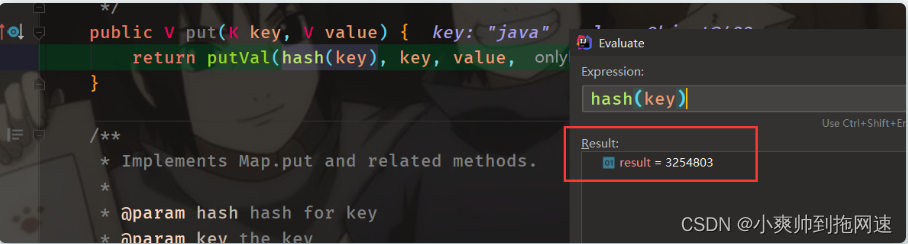
当前key = “java”的hashCode() = 3254818 是十进制的
十进制:3254818 注意:int类型 占4byte 32位 处理数据二进制:11 0001 1010 1010 0010 0010 (22位,不足32位,则补0到32位) 0000 0000 0011 0001 1010 1010 0010 0010 (32位) h>>>16 无符号右移16位 0000 0000 0000 0000 0000 0000 0011 0001 ^ 异或操作:相同为0,不相同为1,可以理解为不进位相加 数据处理完毕,开始进行异或操作h = key.hashCode() ^ (h >>> 16) 0000 0000 0011 0001 1010 1010 0010 0010 ( h = key.hashCode()) ^ (异或) 0000 0000 0000 0000 0000 0000 0011 0001 (h >>> 16) 结果为: 0000 0000 0011 0001 1010 1010 0001 0011 3245803 (十进制结果)
计算结果与程序反馈的结果一致
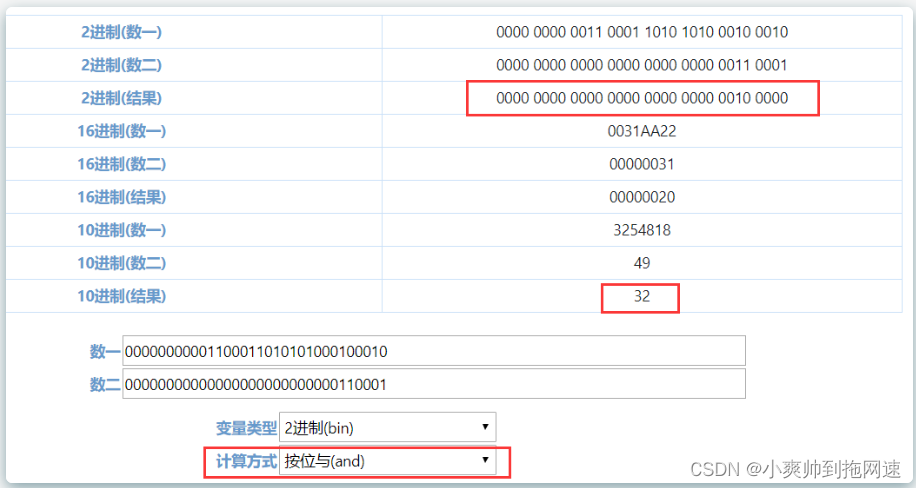
如果使用的是&(按位与)操作,那么结果会是这样的: 可以明显发现2进制结果向0靠拢,因为按位与的结果有4种,只有1&1才会出现结果为1,其余的情况都为0,这样不仅不能够保留原两组数据中各自的特征,还会明显抬高hash冲突的几率
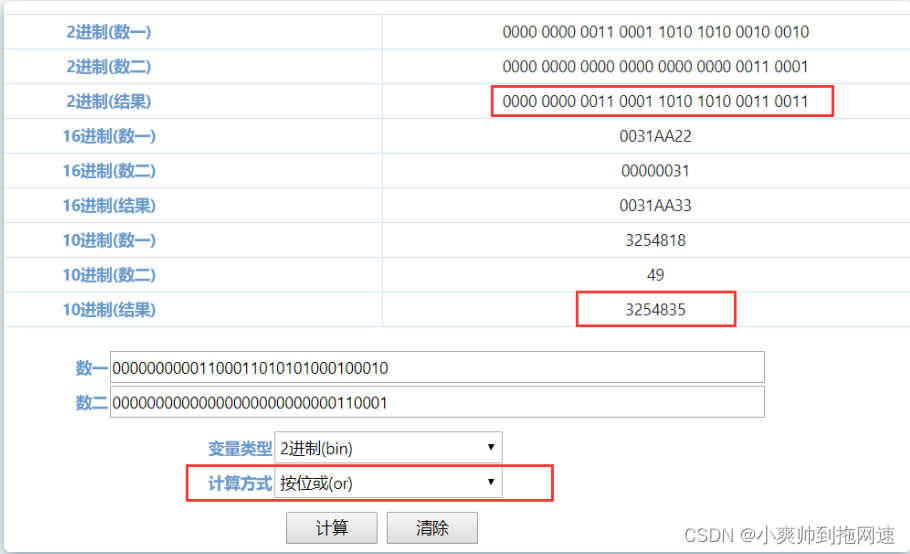
如果使用的是 |(按位或)操作,那么结果会是这样的: 可以发现虽然同异或的结果差别不是很大,但是也能发现结果向1靠拢,并且不能够很好的保留各自的特征 除此之外,异或与或的最大差别就是,异或只能满足一个条件,而或能够同时满足两个条件 异或:相同为0,不相同为1 ,如果结果为1,可能出现的情况是 00 11 此种情况可以很好的保留各自的特征,因为他们都是一样的0也好1也罢 或:有一个为1则为1,两个都为0则为0 ,如果为结果为1,可能出现的情况是10 11,这些情况我们很难去判断出参与运算的两组数据各自的特征 很明显按位或(|)操作不能够很好的保留两组数各自的特征
以上内容仅为个人解读,如有误解,欢迎评论指出,感谢各位 |
【本文地址】
今日新闻 |
推荐新闻 |