YOLO系列算法全家桶 |
您所在的位置:网站首页 › ipad各个系列详解 › YOLO系列算法全家桶 |
YOLO系列算法全家桶
|
前言 本文详细介绍了从YOLOv1-YOLOv9的网络结构,以及各个版本之间的迭代。  YOLOv1-YOLOv8之间的对比如下表所示: Model Anchor Input Backbone Neck Predict/ Train YOLOv1 锚框(7*7grids,2 anchors) resize(448*448*3): 训练是224*224,测试是448*448; GoogLeNet(24*Conv+2*FC+reshape;Dropout防止过拟合;最后一层使用线性激活函数,其余层都使用ReLU激活函数); 无 IOU_Loss、nms;一个网格只预测了2个框,并且都属于同一类;全连接层直接预测bbox的坐标值; YOLOv2 锚框(13*13grids,5 anchors:通过k-means选择先验框) resize(416*416*3):416/32=13,最后得到的是奇数值有实际的中心点;在原训练的基础上又加上了(10个epoch)的448x448高分辨率样本进行微调; Darknet-19(19*Conv+5*MaxPool+AvgPool+Softmax;没有FC层,每一个卷积后都使用BN和ReLU防止过拟合(舍弃dropout);提出passthrough层:把高分辨率特征拆分叠加大到低分辨率特征中,进行特征融合,有利于小目标的检测); 无 IOU_Loss、nms;一个网络预测5个框,每个框都可以属于不同类;预测相对于anchor box的偏移量;多尺度训练(训练模型经过一定迭代后,输入图像尺寸变换)、联合训练机制; YOLOv3 锚框(13*13grids,9 anchors:三种尺度*三种宽高比) resize(608*608*3) Darknet-53(53*Conv,每一个卷积层后都使用BN和Leaky ReLU防止过拟合,残差连接); FPN(多尺度检测,特征融合) IOU_Loss、nms;多标签预测(softmax分类函数更改为logistic分类器); YOLOv4 锚框 resize(608*608*3)、Mosaic数据增强、SAT自对抗训练数据增强 CSPDarknet53(CSP模块:更丰富的梯度组合,同时减少计算量、跨小批量标准化(CmBN)和Mish激活、DropBlock正则化(随机删除一大块神经元)、采用改进SAM注意力机制:在空间位置上添加权重); SPP(通过最大池化将不同尺寸的输入图像变得尺寸一致)、PANnet(修改PAN,add替换成concat) CIOU_Loss、DIOU_nms;自对抗训练SAT:在原始图像的基础上,添加噪音并设置权重阈值让神经网络对自身进行对抗性攻击训练;类标签平滑:将绝对化标签进行平滑(如:[0,1]→[0.05,0.95]),即分类结果具有一定的模糊化,使得网络的抗过拟合能力增强; YOLOv5 锚框 resize(608*608*3)、Mosaic数据增强、自适应锚框计算、自适应图片缩放 CSPDarknet53(CSP模块,每一个卷积层后都使用BN和Leaky ReLU防止过拟合,Focus模块); SPP、PAN GIOU_Loss、DIOU_Nms;跨网格匹配(当前网格的上、下、左、右的四个网格中找到离目标中心点最近的两个网格,再加上当前网格共三个网格进行匹配); YOLOX 无锚框 resize(608*608*3) Darknet-53 SPP、FPN CIOU_Loss、DIOU_Nms、Decoupled Head、SimOTA标签分配策略; YOLOv6 无锚框 resize(640*640*3) EfficientRep Backbone(Rep算子) SPP、Rep-PAN Neck SIOU_Loss、DIOU_Nms、Efficient Decoupled Head、SimOTA标签分配策略; YOLOv7 锚框 resize(640*640*3) Darknet-53(CSP模块替换了ELAN模块;下采样变成MP2层;每一个卷积层后都使用BN和SiLU防止过拟合); SPP、PAN CIOU_Loss、DIOU_Nms、SimOTA标签分配策略、带辅助头的训练(通过增加训练成本,提升精度,同时不影响推理的时间); YOLOv8 无锚框 resize(640*640*3) Darknet-53(C3模块换成了C2F模块) SPP、PAN CIOU_Loss、DFL_Loss、DIOU_Nms、TAL标签分配策略、Decoupled Head; 一、YOLO算法的核心思想YOLO系列的核心思想就是把目标检测转变为一个回归问题,利用整张图片作为网络的输入,通过神经网络,得到边界框的位置及其所属的类别。 1. YOLO系列算法的步骤(1)划分图像:YOLO将输入图像划分为一个固定大小的网格。 (2)预测边界框和类别:对于每个网格,YOLO预测出固定数量(通常为5个或3个) 的边界框。每个边界框由5个主要属性描述:边界框的位置(中心坐标和宽高)和边界框包含的目标的置信度(confidence)。此外,每个边界框还预测目标的类别。 (3)单次前向传递:YOLO通过一个卷积神经网络(CNN)进行单次前向传递,同时预测所有边界框的位置和类别。相比于其他目标检测算法,如基于滑动窗口或区域提议的方法,YOLO具有更快的速度,因为它只需要一次前向传递即可完成预测。 (4)损失函数:YOLO使用多任务损失函数来训练网络。该损失函数包括位置损失、置信度损失和类别损失。位置损失衡量预测边界框和真实边界框之间的位置差异。置信度损失衡量边界框是否正确地预测了目标,并惩罚背景框的置信度。类别损失衡量目标类别的预测准确性。 (5)非最大抑制(Non-Maximum Suppression):在预测的边界框中,可能存在多个相互重叠的框,代表同一个目标。为了消除冗余的边界框,YOLO使用非最大抑制算法,根据置信度和重叠程度筛选出最佳的边界框。 2. Backbone、Neck和Head物体检测器的结构开始被描述为三个部分:Backbone, Neck和Head。下图显示了一个高层次的Backbone, Neck 和 Head图。 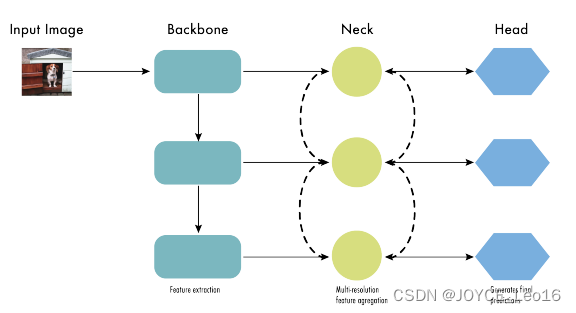 Backbone负责从输入图像中提取有用的特征。它通常是一个卷积神经网络(CNN),在大规模的图像分类任务中训练,如IamgeNet。骨干网络在不同尺度上捕捉层次化的特征,在较早的层中提取低层次的特征(如边缘和纹理),在较深的层中提取高层次的特征(如物体部分和语义信息)。 Neck是连接Backbone和Head的一个中间部件。它聚集并细化骨干网提取的特征,通常侧重于加强不同尺度的空间和语义信息。颈部可能包括额外的卷积层、特征金字塔(FPN)或其他机制,以提高特征的代表性。 Head是物体检测器的最后组成部分。它负责根据Backbone和Neck提供的特征进行预测。它通常由一个或多个特定任务的子网络组成,执行分类、定位,以及最近的实例分割和姿势估计。头部处理颈部提供的特征,为每个候选物产生预测。最后,一个后处理步骤,如非极大值抑制(NMS),过滤掉重叠的预测,只保留置信度最高的检测。 二、YOLO系列的算法1. YOLOv1(2016)(论文地址:https://arxiv.org/pdf/1506.02640.pdf) 1.1 模型介绍在YOLOv1提出之前,R-CNN系列算法在目标检测领域中独占鳌头。R-CNN系列检测精度高,但是由于其网络结构是双阶段(two-stage)的特点,使得它的检测速度不能满足实时性,饱受诟病。为了打破这一僵局,涉及一种速度更快的目标检测器是大势所趋。 2016年,Joseph Redmon、Santosh Divvala、Ross Girshick等人提出了一种单阶段(one-stage)的目标检测网络。它的检测速度非常快,每秒可以处理45帧图片,能够轻松地实时运行。由于其速度之快和其使用的特殊方法,作者将其取名为:You Only Look Once(也就是我们常说的YOLO的全称),并将该成果发表在了CVPR2016上,从而引起了广泛地关注。 YOLO的核心思想就是把目标检测转变成一个回归问题,利用整张图作为网络的输入,仅仅经过一个神经网络,得到bounding box(边界框)的位置及其所属的类别。 1.2 网络结构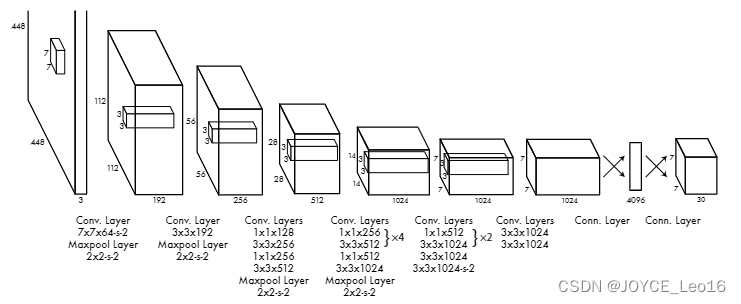 现在看来,YOLOv1的网络结构十分清晰,是一种传统的one-stage的卷积神经网络: 网络输入:448*448*3的彩色图片中间层:由若干卷积层和最大池化层组成,用于提取图片的抽象特征全连接层:由两个全连接层组成,用来预测目标的位置和类别的概率值网络输出:7*7*30的预测结果1.3 实现细节(1)检测策略 YOLOv1采用的是“分而治之”的策略,将一张图片平均分成7x7个网格,每个网格分别负责预测中心点落在该网格内的目标。在Faster R-CNN中,是通过一个RPN来获得目标的感兴趣区域,这种方法精度高,但是需要额外再训练一个RPN网络,这无疑增加了训练的负担。在YOLOv1中,通过划分得到了7x7个网格,这49个网格就相当于是目标的感兴趣区域。通过这种方式,我们就不需要再额外设计一个RPN网络,这正是YOLOv1作为单阶段网络的简单快捷之处。 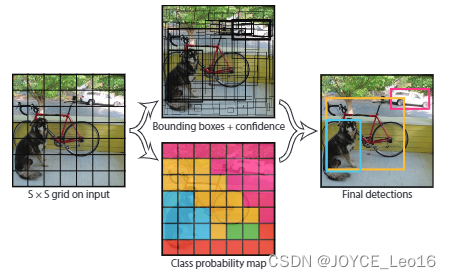 具体实现过程如下: ①. 将一副图像分成 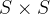 个网格(grid cell),如果某个object的中心落在这个网格中,则这个网络就负责预测这个object。 ②. 每个网格都要预测B个bounding box,每个bounding box要预测 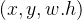 和confidence共5个值。 ③. 每个网格还要预测一个类别信息,记为C个类。 ④. 总的来说, 个网格,每个网格要预测B个bounding box,还要预测C个类。网络输出就是一个 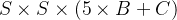 的张量。 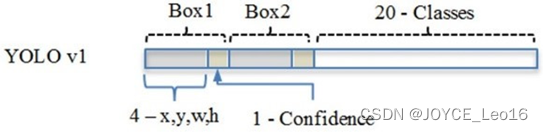 在实际过程中,YOLOv1把一张图片划分为了7x7个网格,并且每个网格预测2个Box(Box1和Box2),20个类别。所以实际上,S=7,B=2,C=20。那么网络输出的shape也就是: 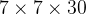 。 (2)目标损失函数 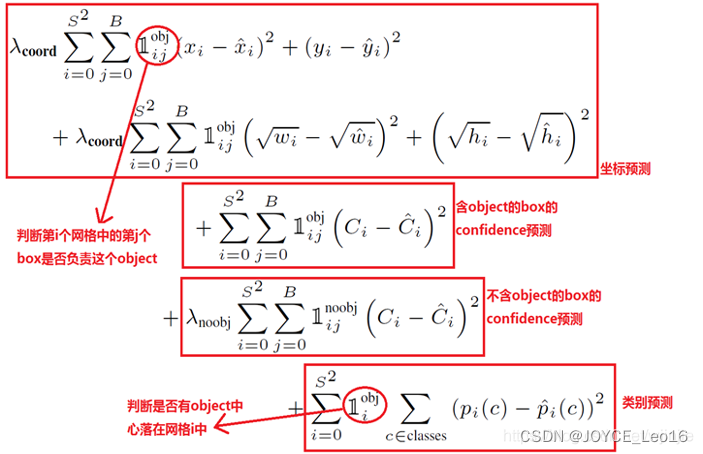 损失由三部分组成,分别是:坐标预测损失、置信度预测损失、类别预测损失。 使用的是差方和误差。需要注意的是,w和h在进行误差计算的时候取得是它们的平方根,原因是对不同大小的bounding box预测中,相比于大bounding box预测偏一点,小box预测偏一点更不能忍受。而差方和误差函数中对同样的偏移loss是一样。为了缓和这个问题,作者用了一个比较取巧的办法,就是将bounding box的w和h取平方根代替原本的w和h。定位误差比分类误差更大,所以增加对定位误差的惩罚,使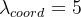 。 在每个图像中,许多网格单元不包含任何目标值。训练时就会把这些网格里的框的“置信度”分数推到零,这往往超过了包含目标的框的梯度。从而可能导致模型不稳定,训练早期发散。因此要减少了不包含目标的框的置信度预测的损失,使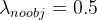 。 1.4 性能表现(1)优点 YOLO检测速度非常快。标准版本的YOLO可以每秒处理45张图像;YOLO的极速版本每秒可以处理150帧图像。这就意味着YOLO可以小于25毫秒延迟,实时地处理视频。对于欠实时系统,在准确率保证的情况下,YOLO速度快于其他方法。YOLO实时检测的平均精度是其他实时监测系统的两倍。迁移能力强,能运用到其他新的领域(比如艺术品目标检测)。(2)局限性 YOLO对相互靠近的物体,以及很小的群体检测效果不好,这是因为一个网格只预测了2个框,并且都只属于同一类。由于损失函数的问题,定位误差是影响检测效果的主要原因,尤其是大小物体的处理上,还有待加强。(因为对于小的bounding boxes,small error影响更大)。YOLO对不常见的角度的目标泛化性性能偏弱。2. YOLOv2(2016)(论文地址:https://arxiv.org/pdf/1612.08242.pdf#page=4.24) 2.1 改进部分YOLOv2Joseph Redmon和Ali Farhadi发表在CVPR 2017。它包括了对原始YOLO的一些改进,保持相同的速度,也更强大,能够检测9000个类别,这些改进有以下几点: (1)在所有卷积层上的批量归一化改善了收敛性,并作为一个正则器来减少过拟合; (2)高分辨率分类器,和YOLOv1一样,他们在ImageNet以224x224的分辨率对模型进行了预训练。然而,这一次,他们在分辨率为448x448的ImageNet上对模型进行了10次微调,提高了网络在高分辨率输入下的性能; (3)完全卷积。它们去掉了密集层,采用了全卷积架构。 (4)使用Anchor来预测边界盒。他们使用一组先验框Anchor,这些Anchor具有预定义的形状,用于匹配物体的原型形状,如图6所示,每个网格单元都定义了多个Anchor,系统预测每个Anchor的坐标和类别。网络输出的大小与每个网格单元的Anchor数量成正比。 (5)维度聚类。挑选好的Anchor有助于网络学习预测更准确的边界盒。作者对训练中的边界盒进行了k-means聚类,以找到更好的先验。他们选择了五个Anchor,在召回率和模型复杂性之间进行了良好的权衡。 (6)直接预测位置。与其他预测偏移量的方法不同,YOLOv2遵循同样的理念,预测了相对于网格单元的位置坐标,网络为每个单元预测了五个bounding box,每个bounding box有五个值 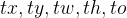 ,其中 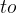 相当于YOLOv1的Pc,最终得到的bounding box坐标如图7所示。 (7)细粒度的特征。与YOLOv1相比,YOLOv2去掉了一个池化层,对于416x416的输入图像,得到13x13的特征图。 (8)多尺度训练。由于YOLOv2不使用全连接层,输入可以是不同的尺寸。为了使YOLOv2对不同的输入尺寸具有鲁棒性,作者随机训练模型,每10批改变尺寸(从320x320到608x608)。 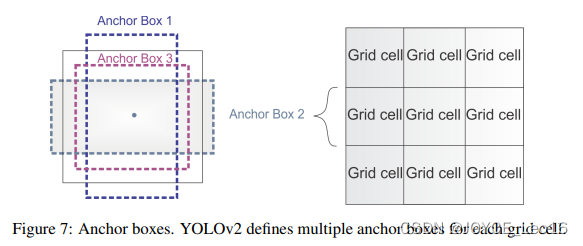 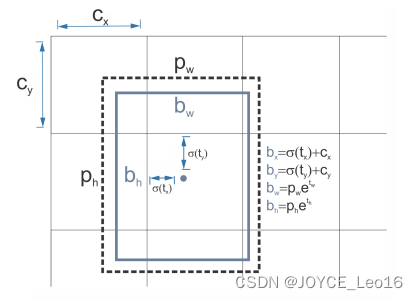 2.2 网络结构 2.2 网络结构YOLOv2 采用 Darknet-19 作为特征提取网络,其整体结构如下: 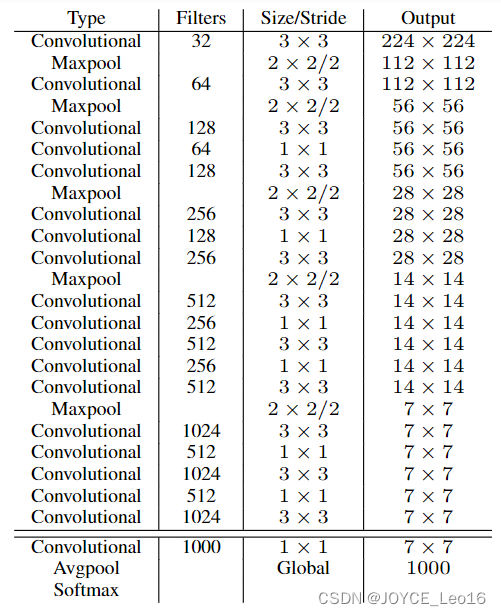 改进后的YOLOv2:Darknet-19,总结如下: ①. 与VGG相似,使用了很多3x3卷积核;并且每一次池化后,下一层的卷积核的通道数=池化输出的通道 x 2。 ②. 在每一层卷积后,都增加了BN层进行预处理。 ③. 采用了降维的思想,把1x1的卷积置于3x3之间,用来压缩特征。 ④. 在网络最后的输出上增加了一个global average pooling层。 ⑤. 整体上采用了19个卷积层,5个池化层。 为了更好的说明,将Darknet-19与YOLOv1、VGG16网络进行对比: VGG-16:大多数检测网络框架都是以VGG-16作为基础特征提取器,它功能强大,准确率高,但是计算复杂度较大,所以速度会相对较慢。因此YOLOv2的网络结构将从这方面改进。YOLOv1:基于GoogLeNet的自定义网络,比VGG-16的速度快,但是精度稍不如VGG-16。Darknet-19:速度方面,处理一张图片仅需要55.8亿次运算,相比于VGG306.9亿次,速度快了近6倍。精度方面,在ImageNet上的测试精度为:top1准确率为72.9%,top5的准确率为91.2%。2.3 性能表现在VOC2007数据集上进行测试,YOLOv2在速度为67fps时,精度可以达到76.8的mAP;在速度为40fps时,精度可以达到78.6的mAP 。可以很好的在速度和精度之间进行权衡。下图是YOLOv1在加入各种改进方法后,检测性能的改变。可见在经过多种改进方法后,YOLOv2在原基础上检测精度具有很大的提升。  相对于YOLOv1而言,不足之处在于,没有进行多尺度特征的结合预测,传递模块(Pass-Through Module)的使用在提升细粒度特征的同时也对特征的空间,分布产生了一定影响,以及对小目标的检测能力没有明显提升。 3. YOLOv3 (2018)(论文地址:https://arxiv.org/pdf/1804.02767.pdf) 3.1 模型介绍2018年,作者Redmon又在YOLOv2的基础上做了一些改进。特征提取部分采用Darknet-53网络结构代替原来的Darknet-19,利用特征金字塔网络结构实现了多尺度检测,分类方法使用逻辑回归代替了softmax,在兼顾实用性的同时保证了目标检测的准确性。 从YOLOv1到YOLOv3,每一代性能的提升都与backbone(骨干网络)的改进密切相关。在YOLOv3中,作者不仅提供了darknet-53,还提供了轻量级的tiny-darknet。如果你想检测精度与速度兼备,可以选择darknet-53作为backbone;如果你想达到更快的检测速度,精度方面可以妥协。那么tiny-darknet是你很好的选择。总之,YOLOv3的灵活性使得它在实际工程中得到很多人的青睐。 3.2 网络结构相比于 YOLOv2 的 骨干网络,YOLOv3 进行了较大的改进。借助残差网络的思想,YOLOv3 将原来的 darknet-19 改进为darknet-53。论文中给出的整体结构如下: 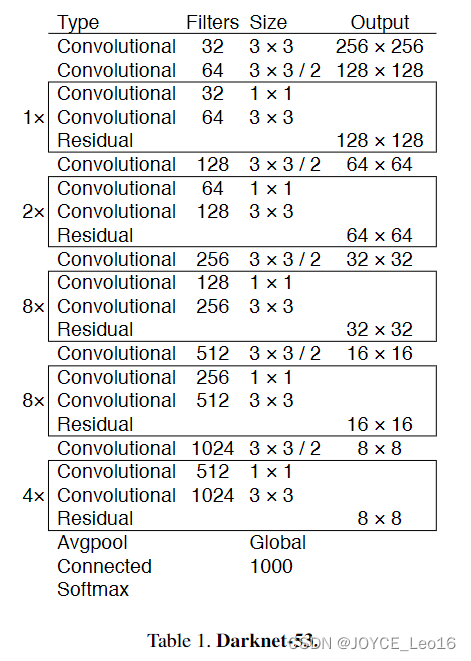 Darknet-53主要由1x1和3x3的卷积层组成,每个卷积层之后包含一个批量归一化层和一个Leaky ReLU,加入这两部分的目的是为了防止过拟合。卷积层、BN层以及LeakyReLU共同组成Darknet-53的基本CBL。因为在Darknet-53中共包含53个这样的CBL,所以称其为Darkent-53。 为了更加清晰地了解Darknet-53的网络结构,可以看下面这张图: 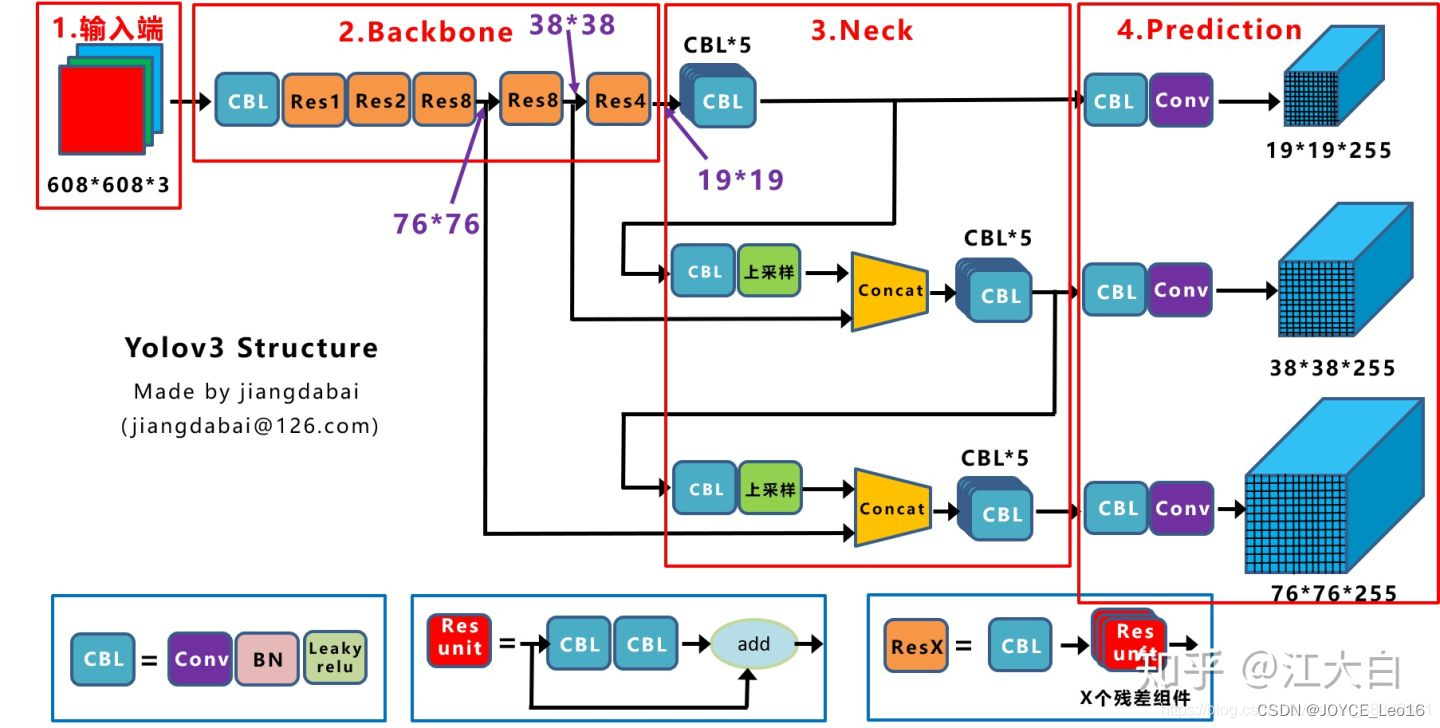 (图片来源:jiangdabai) 为了更好的理解此图,下面对主要单元进行说明: CBL:一个卷积层、一个BN层和一个Leaky ReLU组成的基本卷积单元。res unit:输入通过两个CBL后,再与原输入进行add;这是一种常规的残差单元。残差单元的目的是为了让网络可以提取到更深层的特征,同时避免出现梯度消失或爆炸。ResX:X个残差组件。concat:将Darknet-53的中间层和后面的某一层的上采样进行张量拼接,达到多尺度特征融合的目的。这与残差层的add操作是不一样的,拼接会扩充张量的维度,而add直接相加不会导致张量维度的改变。最后面的蓝色立方体表示三种尺度的输出。与Darknet-19相比,Darknet-53主要做了如下改进: 没有采用最大池化层,转而采用步长为2的卷积层进行下采样。为了防止过拟合,在每个卷积层之后加入了一个BN层和一个Leaky ReLU。引入了残差网络的思想,目的是为了让网络可以提取到更深层的特征,同时避免出现梯度消失或爆炸。将网络的中间层和后面某一层的上采样进行张量拼接,达到多尺度特征融合的目的。3.3 改进部分(1)输入端 Mosaic数据扩增:将四张不同的训练图像随机拼接在一起,形成一张马赛克图像。这种方式可以帮助模型学习并适应不同的场景、目标形状和尺度变化。自适应锚框计算:引入了自适应锚框计算的机制,旨在更好地适应各种目标的尺寸和长宽比例变化。初始锚框定义:首先,根据训练集的标注框,选择初始的锚框。可以使用一些聚类算法(如k-means)对标注框进行聚类,以确定一组代表性的锚框。锚框调整:对于每个训练样本,根据该样本中的目标框与初始框的匹配程度,调整初始框的大小和长宽比例。这可以通过计算目标框与锚框的IoU(交并比)来确定匹配程度,并根据匹配程度调整锚框的尺寸。锚框聚类:根据经过调整的锚框,再次进行聚类,得到一组更适应当前数据集的锚框。这些聚类过程通常是迭代进行的,直到达到一定的收敛条件。锚框选择:根据聚类得到的锚框集合,可以选择一定数量的锚框用于目标检测。通常,可以根据聚类结果中的锚框长宽比例的分布情况,选择一些具有代表性的锚框。自适应缩放:根据目标尺寸来自动调整输入图像的大小。这样可以更好地适应不同尺度的目标,提高目标检测的准确性。 (2)主干网络 YOLOv3的主干网络Darknet-53包含卷积层(Convolutional Layer)、残差层(Residual Layer)、特征融合层(Feature Fusion Layer),网络层数的加深提高了检测精度,大量残差网络模块的引入减少了由网络层数加深引起的梯度下降问题,金字塔池化模块的引入可以实现多尺寸的输入和统一尺寸的输出。 (3)颈部网络 YOLOv3的颈部网络是FPN(多尺度检测,特征融合),FPN(Feature Pyramid Network)是一种用于目标检测和语义分割任务的特征金字塔网络结构。它的设计目的是解决单尺度特征提取网络在处理不同尺度目标时的困难。 FPN的主要思想如下: 特征提取:首先,通过卷积神经网络(如ResNet)进行特征提取。这些特征具有不同的尺度和语义信息。顶层池化:为了获取更高分辨率的特征,FPN使用自顶向下的顶层池化操作,将较低分辨率的特征图上采样到较高分辨率。这可以通过上采样或插值等方法实现。横向连接:为了融合不同层次的特征信息,FPN引入横向连接,将上一层的特征与下一层的上采样特征进行逐元素相加(Element-wise Sum)。这样可以将低级别的细节信息与高级别的语义信息相结合,产生具有多尺度特征的金字塔结构。特征融合:为了进一步提升特征表达能力,FPN在每个金字塔层级上引入一个额外的卷积层,进行特征融合和调整。(4)输出端 YOLOv3在输出的改进是多标签预测(softmax函数变为logistics分类器)。在YOLOv1中,通常使用softmax函数作为分类器的激活函数,将每个类别的输出转化为概率分布。 然而,对于YOLOv3这样的多标签检测任务,一个目标可能属于多个类别,使用softmax函数会导致多个类别的概率之和超过1,不符合多标签问题的要求。因此,在YOLOv3中,采用了logistic分类器作为分类器的激活函数。 logistic分类器将每个类别的输出视为独立的二分类问题,对每个类别使用sigmoid函数进行激活。sigmoid函数将输出限制在0到1之间,表示每个类别的存在概率。 3.4 性能表现如下图所示,是各种先进的目标检测算法在COCO数据集上测试结果。很明显,在满足检测精度差不都的情况下,YOLOv3具有更快的推理速度。 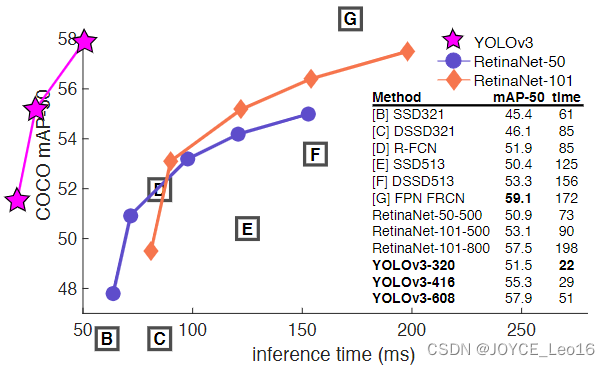 如下表所示,对不同的单阶段和两阶段网络进行了测试。通过对比发现,YOLOv3达到了与当前先进检测器的同样的水平。检测精度最高的是单阶段网络RetinaNet,但是YOLOv3的推理速度比RetinaNet快得多。 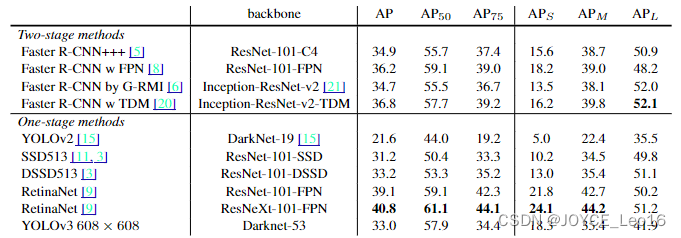 4. YOLOv4(2020) 4. YOLOv4(2020)(论文地址:https://arxiv.org/pdf/2004.10934.pdf) 4.1 模型介绍从YOLOv3后,YOLO没有新版本。直到2020年4月,Alexey Bochkovskiy、Chien-Yao Wang和Hong-Yuan Mark Liao在ArXiv发布了YOLOv4[50]的论文。起初,不同的作者提出一个新的YOLO "官方 "版本让人感觉很奇怪;然而,YOLOv4保持了相同的YOLO理念——实时、开源、端到端和DarkNet框架——而且改进非常令人满意,社区迅速接受了这个版本作为官方的YOLOv4。 YOLOv4的独特之处在于: 是一个高效而强大的目标检测网络。它使我们每个人都可以使用GTX 1080Ti 或2080Ti的GPU来训练一个超快速和精确的目标检测器。 在论文中,验证了大量先进的技巧对目标检测性能的影响。 对当前先进的目标检测方法进行了改进,使之更有效,并且更适合在单GPU上训练;这些改进包括CBN、PAN、SAM等。 4.2 网络结构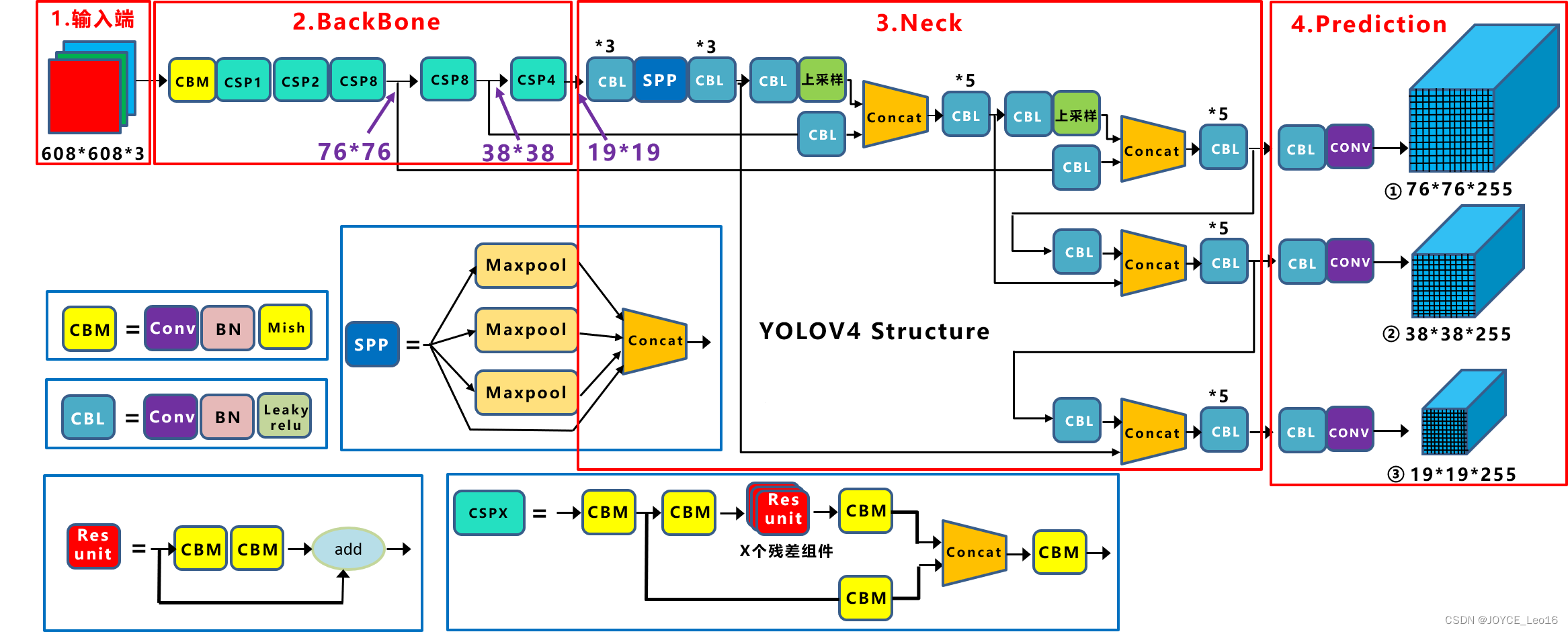 (图片来源:jiangdabai) 先详细介绍一下YOLOv4的基本组件: CBM:Yolov4网络结构中的最小组件,由Conv+Bn+Mish激活函数三者组成。CBL:由Conv+Bn+Leaky_relu激活函数三者组成。Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。CSPX:借鉴CSPNet网络结构,由卷积层和X个Res unint模块Concate组成。SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。YOLOv4 = CSPDarknet53(主干) + SPP附加模块(颈) + PANet路径聚合(颈) + YOLOv3(头部) 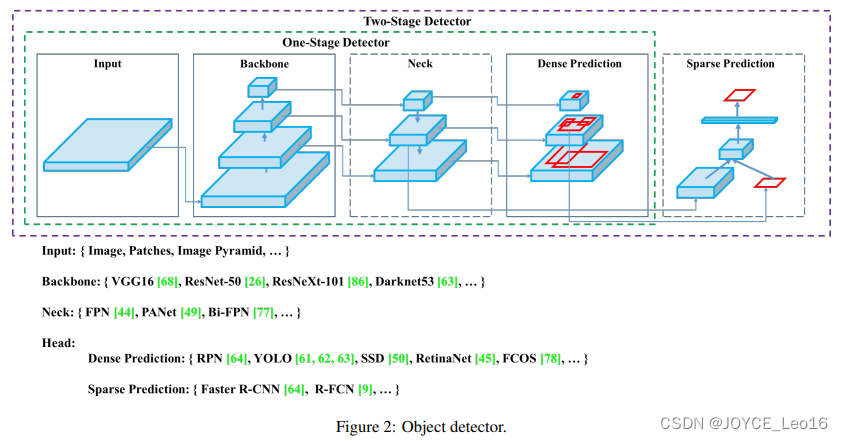 4.3 改进部分 4.3 改进部分(1)输入端 无明显变化。 (2)主干网络 CSPDarknet-53骨干网络:YOLOv4采用了称为CSPDarknet-53的新的骨干网络结构,它基于Darknet-53,并通过使用CSP(Cross Stage Partial)模块来提高特征表示的能力。SAM(Spatial Attention Module):通过引入SAM模块,YOLOv4能够自适应地调整特征图的通道注意力权重。以增强对目标的感知能力。Mish激活函数:YOLOv4采用了CSPDarknet-53作为其主干网络,该网络中的每个残差块(residual block)都应用了Mish激活函数。这使得网络能够从输入到输出的特征变换过程中引入非线性变换,并帮助网络更好地捕捉输入数据的复杂特性。(3)颈部网络 PANet特征融合:YOLOv4引入了PANet(Path Aggregation Network)模块,用于在不同尺度的特征图之间进行信息传递和融合,以获取更好的多尺度特征表示。SPP:具体是在CSPDarknet-53网络的后面,通过在不同大小的池化层上进行特征提取,从而捕捉到不同尺度上的上下文信息。(4)输出端 在YOLOv4中,确实引入了一种新的距离度量指标,称为CIOU。 CIOU是一种改进的目标检测损失函数,用于衡量预测框和真实框之间的距离。CIOU是DIoU的进一步扩展,除了考虑框的位置和形状之间的距离外,还引入了一个附加的参数用于衡量框的长宽比例的一致性。 CIOU的计算公式如下:  ,其中,IoU表示传统的交并比(Intersection over Union),d表示预测框和真实框中心点之间的欧氏距离,c表示预测框和真实框的对角线距离。在CIOU中,α是一个参数,用于平衡框长宽比例的一致性和框位置之间的距离。v是一个辅助项,用于惩罚预测框和真实框之间的长宽比例差异。 CIOU损失是通过最小化CIOU来优化目标检测模型。它可以作为定位损失函数的一部分,用于衡量预测框的定位准确性。通过CIOU损失的引入,YOLOv4可以更好地优化边界框的位置、形状和长宽比例,从而提高目标检测的准确性和鲁棒性。 4.4 性能表现如下图所示,在COCO目标检测数据集上,对当前各种先进的目标检测器进行了测试。可以发现,YOLOv4的检测速度比EfficientDet快两倍,性能相当。同时,将YOLOv3的AP和FPS分别提高10%和12%,吊打YOLOv3! 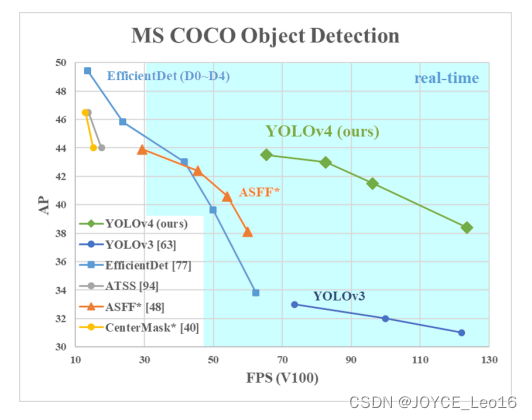 综合以上分析,总结出YOLOv4带给我们的优点有: 与其他先进的检测器相比,对于同样的精度,YOLOv4更快(FPS);对于同样的速度,YOLOv4更准(AP)。YOLOv4能在普通的GPU上训练和使用,比如GTX 1080Ti和GTX 2080Ti等。论文中总结了各种Tricks(包括各种BoF和BoS),给我们启示,选择合适的Tricks来提高自己的检测器性能。5. YOLOv5(2020)(代码地址:https://github.com/ultralytics/yolov5) 5.1 模型介绍YOLOv5有YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四个版本。文件中,这几个模型的结构基本一样,不同的是depth_multiple模型深度和width_multiple模型宽度这两个参数。就和我们买衣服的尺码大小排序一样,YOLOv5s网络是YOLOv5系列中深度最小、特征图的宽度最小的网络。其他三种都是在此基础上不断加深,不断加宽。  5.2 网络结构 5.2 网络结构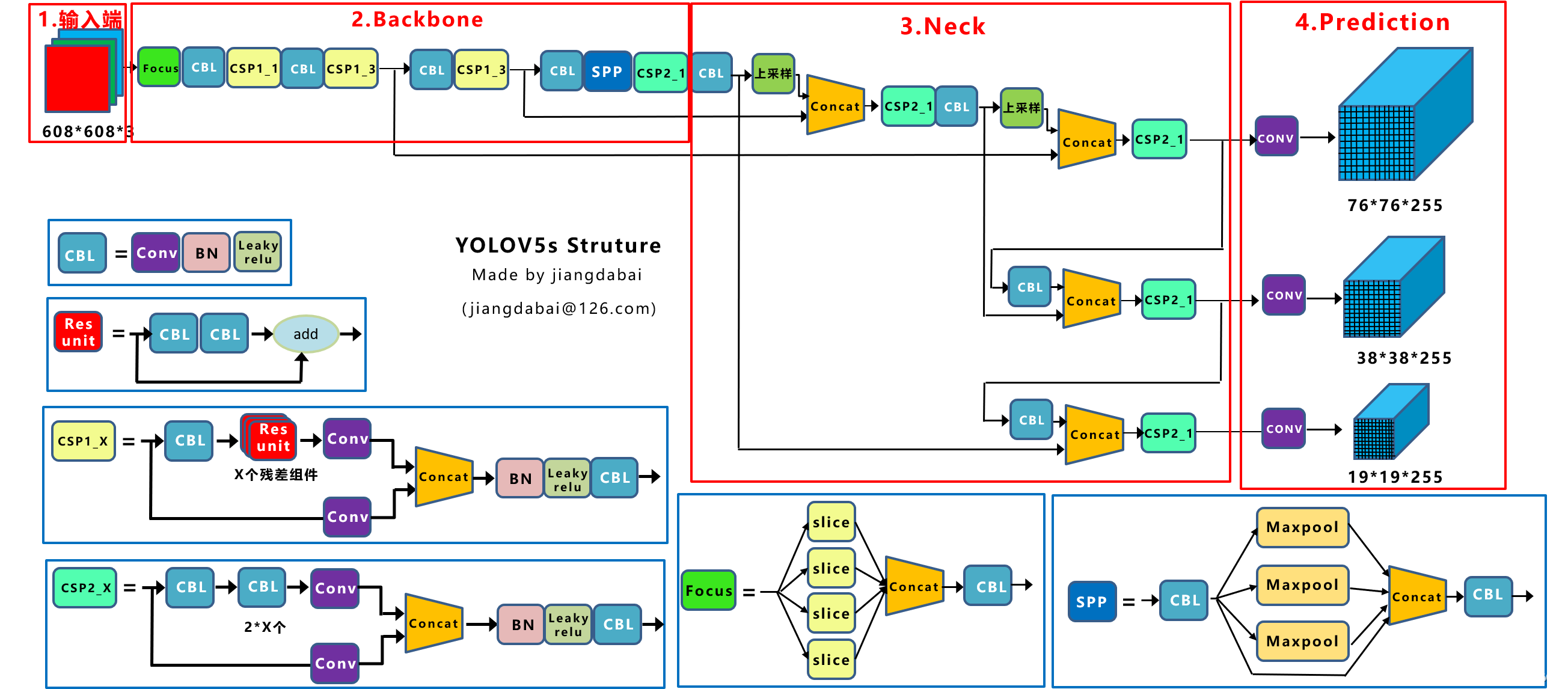 (图片来源:jiangdabai) 输入端:Mosaic数据增强、自适应锚框计算、自适应图片缩放Backbone:Focus结构,CSP结构Neck:FPN+PAN结构Head:CIOU_Loss基本组件: Focus:基本上就是YOLOv2的passthrough。CBL:由Conv+Bn+Leaky ReLU三者3组成。CSP1_X:借鉴CSPNet网络结构,由三个卷积层和X个Res unit模块Concat组成。CSP2_X:不再用Res unit模块,而是改为CBL。SPP:采用1x1,5x5,9x9,13x13的最大池化方式,进行多尺度融合。5.3 改进部分(1)输入端 无明显变化。 (2)主干网络 Focus结构:Focus结构是YOLOv5中的一个重要组件,用于提取高分辨率特征。它采用的是一种轻量级的卷积操作,帮助模型在保持较高感受野的同时减少计算负担。Focus结构通过将输入特征图进行通道划分和空间划分,将原始特征图转换为更小尺寸的特征图,并保留了原始特征图中的重要信息。这样做有助于提高模型的感知能力和对小尺寸目标的检测准确性。CSPDarknet-53结构:CSP(Cross Stage Partial)Darknet-53是YOLOv5中的主干网络结构。相对于YOLOv4中的Darknet-53,CSPDarknet-53引入了跨阶级部分连接的想法,通过将特征图在通道维度上分为两个部分,将其中一部分直接连入下一阶段,以增加信息流动的路径,提高特征的传递效率。CSPDarknet-53结构在减少参数和计算量的同时,保持了较高的特征表示能力,有助于提高目标检测的准确性和速度。(3)颈部网络 无明显变化。 (4)输出端 无明显变化。 5.4 性能表现在COCO数据集上,当输入原图的尺寸是:640x640时,YOLOv5的5个不同版本的模型的检测数据如下: 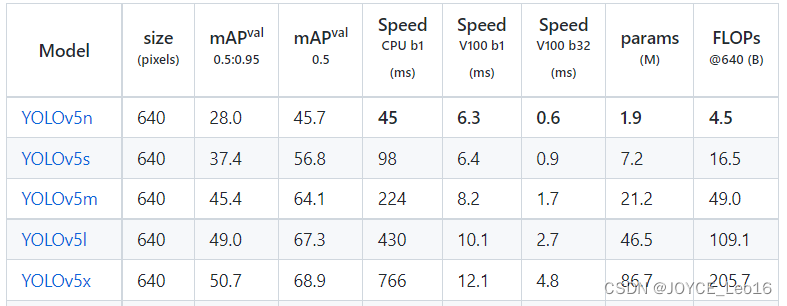 在COCO数据集上,当输入原图的尺寸是:1280x1280时,YOLOv5的5个不同版本的模型的检测数据如下: 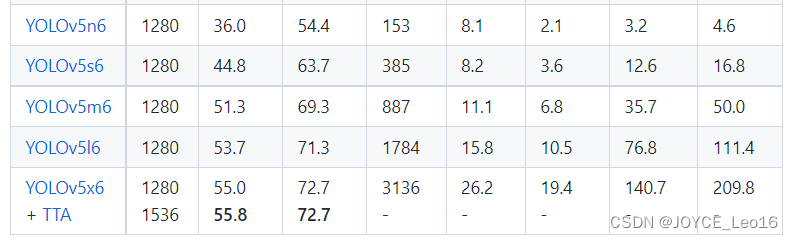 从上表可得知,从YOLOv5n到YOLOv5x,这五个YOLOv5模型的检测精度逐渐上升,检测速度逐渐下降。根据项目要求,用户可以选择合适的模型,来实现精度与速度的最佳权衡! 6. YOLOX(2021)(论文地址:https://arxiv.org/pdf/2107.08430.pdf) (代码地址:https://github.com/Megvii-BaseDetection/YOLOX?tab=readme-ov-file) 6.1 模型介绍YOLOX在YOLO系列的基础上做了一系列的工作,其主要贡献在于:在YOLOv3的基础上,引入了Decoupled Head,Data Aug,Anchor Free和SimOTA样本匹配的方法,构建了一种anchor-free的端到端目标检测框架,并且达到了一流的检测水平。 此外,本文提出的 YOLOX-L 模型在视频感知挑战赛(CVPR 2021年自动驾驶研讨会)上获得了第一名。作者还提供了支持ONNX、TensorRT、NCNN和Openvino的部署版本 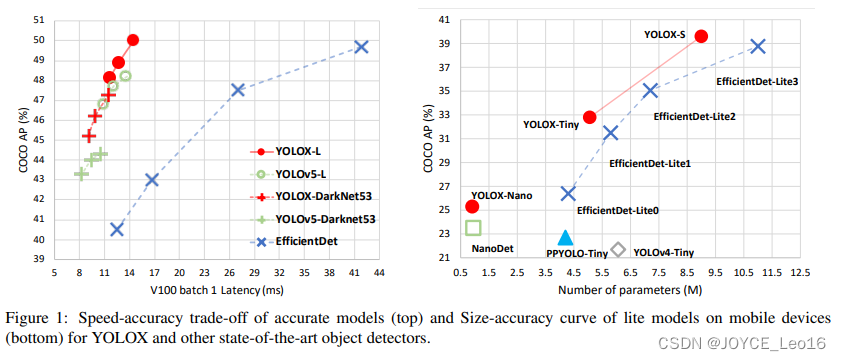 为什么提出YOLOX: 目标检测分为Anchor Based和Anchor Free两种方式。 在Yolov3、Yolov4、Yolov5中,通常都是采用 Anchor Based的方式,来提取目标框。 Yolox 将 Anchor free 的方式引入到Yolo系列中,使用anchor free方法有如下好处: 降低了计算量,不涉及IoU计算,另外产生的预测框数量较少。假设feature map的尺度为80x80,anchor based方法在Feature Map上,每个单元格一般设置三个不同尺寸大小的锚框,因此产生3x80x80=19200个预测框。而使用anchor free的方法,仅产生80x80=6400个预测框,降低了计算量。 缓解了正负样本不平衡问题anchor free方法的预测框只有anchor based方法的1/3,而预测框中大部分是负样本,因此anchor free方法可以减少负样本数,进一步缓解了正负样本不平衡问题。 避免了anchor的调参anchor based方法的anchor box的尺度是一个超参数,不同的超参数设置会影响模型性能。anchor free方法避免了这一点。 6.2 网络结构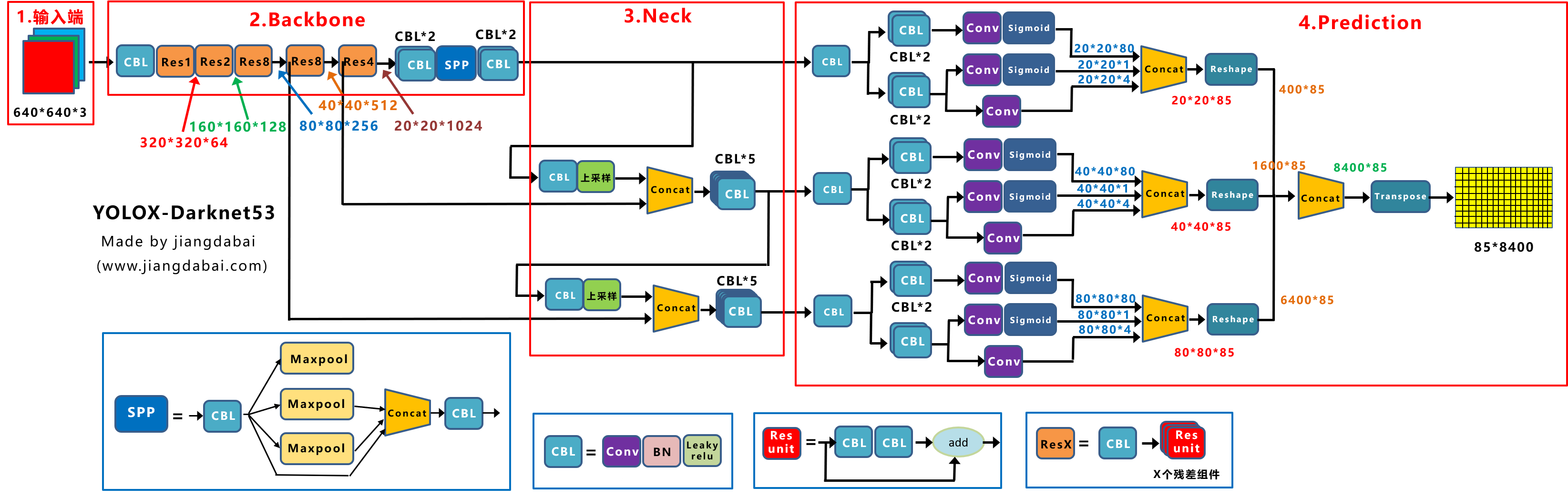 (图片来源:jiangdabai) 输入端:表示输入的图片,采用的数据增强方式:RandomHorizontalFlip、ColorJitter、多尺度增强。Backbone:用来提取图片特征,采用Darknet53。Neck:用于特征融合,采用PAFPN。Prediction:用来结果预测。Decoupled Head、End-to-End YOLO、Anchor-free、Multi positives。6.3 改进部分无锚(Anchor-free):自YOLOv2以来,所有后续的的YOLO版本都是基于锚点的检测器。YOLOX受到CornerNet、CenterNet和FCOS等最先进的无锚物体检测器的启发,回到了一个无锚结构,简化了训练进和解码过程。与YOLOv3基线相比,无锚的AP增加了0.9;多重正样本(Multi positives):为了弥补因缺乏锚点而产生的巨大不平衡,作者使用了中心采样。他们将中心3x3的区域作为正例区域。这种方法使得AP增加了2.1。解耦头(Decoupled head):分类置信度和定位精度之间可能存在错位。由于这个原因,YOLOX将这两者分离成两个头(如图2所示),一个用于分类任务,另一个用于回归任务,将AP提高了1.1分,并加快了模型收敛。高级标签分配:有研究表明,当多个对象的bounding box重叠时,ground truth标签分配可能存在模糊性,并将分配程序表述为最佳传输(OT)问题。YOLOX在这项工作的启发下,提出了一个简化的版本,称为simOTA。这一变化使AP增加了2.3分。强化增强:YOLOX使用MixUP和Mosaic增强。作者发现,在使用这些增强后,ImageNet预训练不再有好处。强势增强使AP增加了2.4分。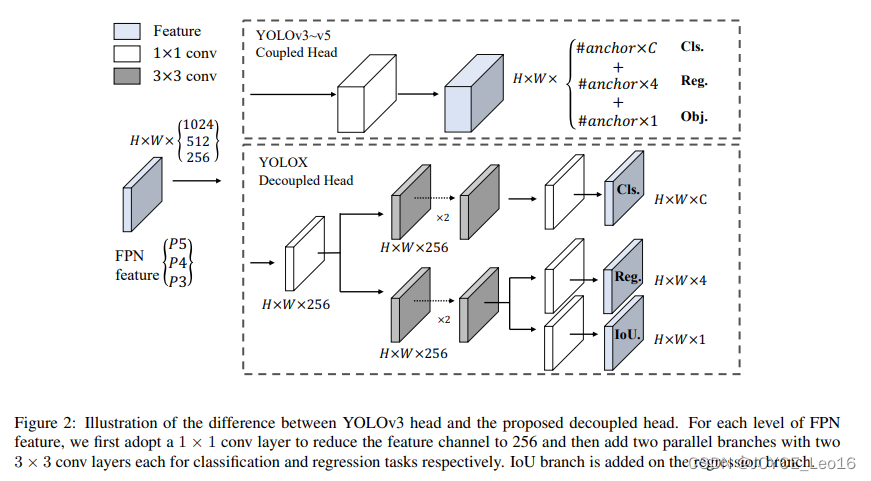 6.4 性能表现 6.4 性能表现YOLOX的性能超越了YOLOV5,YOLOX-X的AP值达到了51.2,超过YOLOV5-X 0.8个百分点,此外模型推理速度和参数量都具有比较大的优势。 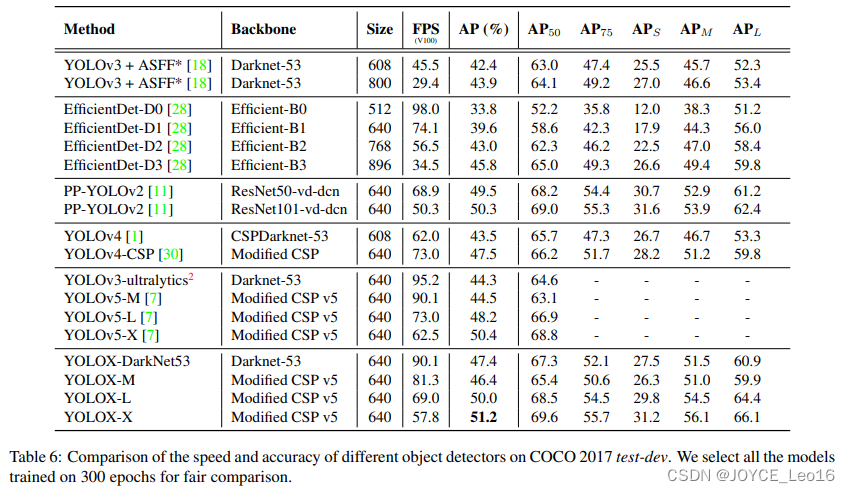 7. YOLOv6(2022) 7. YOLOv6(2022)(论文地址:https://arxiv.org/pdf/2209.02976.pdf) (代码地址:https://github.com/meituan/YOLOv6/) 7.1 模型介绍YOLOv6于2022年9月由美团视觉人工智能部发布在ArXiv。与YOLOv4和YOLOv5类似,它为工业应用提供了各种不同尺寸的模型。跟随基于锚点的方法的趋势,YOLOv6采用了无锚点的检测器。 YOLOv5/YOLOX 使用的 Backbone 和 Neck 都基于 CSPNet 搭建,采用了多分支的方式和残差结构。对于 GPU 等硬件来说,这种结构会一定程度上增加延时,同时减小内存带宽利用率。因此,YOLOv6对Backbone 和 Neck 都进行了重新设计,Head层沿用了YOLOX中的Decoupled Head并稍作修改。相当于YOLOv5而言,v6对网络模型结构进行了大量的更改。 7.2 网络结构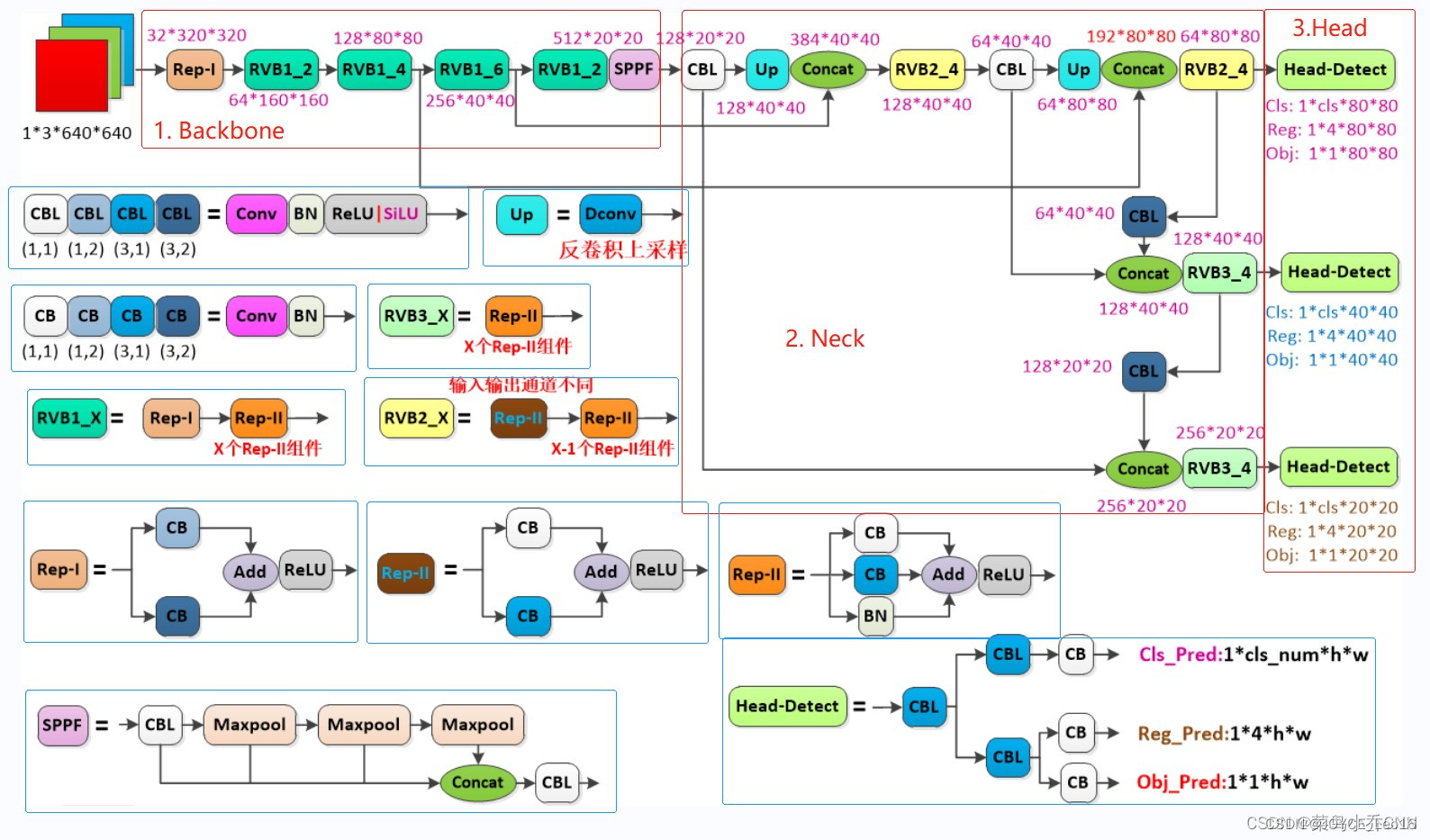 (图片来源:cainiaoxiaoqiao) 由上图所示,从整体上看,YOLOv6的网络结构与YOLOv4、YOLOv5是很相似的,尤其是backbone和neck部分,但是其中的实现模块是有变化的;但最大的不同在于Head部分,采用的是YOLOX的hHead方式,将分类和回归分为两个支路,进行了解耦操作。 7.3 改进部分(1)输入端 无锚框,取消了YOLOv1到YOLOv5一直沿用的锚框。 (2)主干网络 YOLOv6的Backbone的实现的基本模块为RVB1_X结构,其全程为RepVGGBlock_X,表示由多个RepVGGBlock组成。 RepVGGBlock是RepVGG网络的重复模块,由多个RepVGGConv模块组成。每个RepVGGBlock由两个RepVGGConv模块组成,第一个RepVGGConv是一个3x3卷积操作,而第二个RepVGGConv是一个1x1卷积操作。 这两个卷积模块之间使用了批归一BatchNorm)和ReLU激活函数。RepVGGConv模块是RepVGG网络中的基本卷积模块,由一个卷积层、批归一化和ReLU激活函数组成。这样的设计使得RepVGGBlock具有较强的表达能力,并且可以适应不同的特征提取需求。 RepVGGBlock在RepVGG网络中被重复堆叠多次,形成了深层的网络结构。通过堆叠多个RepVGGBlock,可以提高网络的表示能力和复杂度,从而实现更准确的特征提取和目标识别。 (3)颈部网络 PANet结构类似更换为RepVGGBlock结构。 (4)输出端 YOLOv6对检测头进行了解耦,分开了边框与类别的分类过程。 7.4 性能表现YOLOv6 的检测精度和速度均优于以前最先进的模型,同时设计了 8 种缩放模型为不同场景中的工业应用定制不同规模的网络模型,可以检测不同尺度的图像从而提高检测效果,其部署简单、计算量较低,适用于实时检测。并且支持在不同平台上面的部署,简化工程部署的适配工作。但检测准确率其同时期的其他先进算法相比较低。 下表为与 COCO 2017 val 上其他 YOLO 系列的比较。FPS 和延迟是在使用 TensorRT 的 Tesla T4 上以 FP16 精确度测量的。我们的所有模型都在没有预训练或任何外部数据的情况下训练了 300 个epoch。在输入分辨率为 640×640 的情况下,我们对模型的准确性和速度性能进行了评估。'‡'表示所提出的自蒸馏方法是倾斜化的。∗"表示通过官方代码发布的模型的重新评估结果。 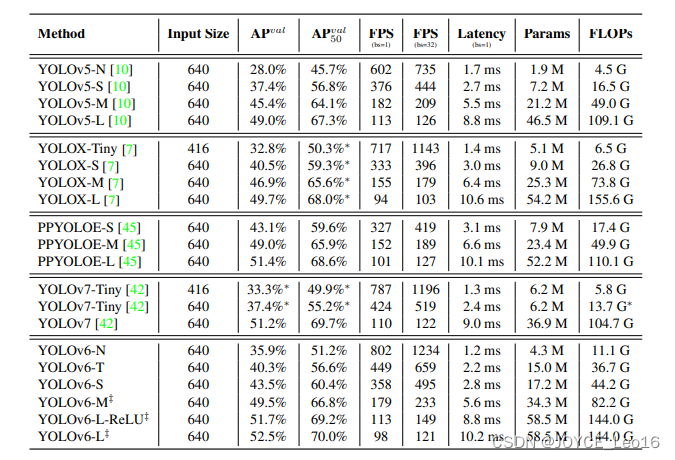 8. YOLOv7(2022) 8. YOLOv7(2022)(论文地址:https://arxiv.org/pdf/2207.02696.pdf) (代码地址:https://github.com/WongKinYiu/yolov7) 8.1 模型介绍YOLOv7由YOLOv4和YOLOR的同一作者于2022年7月发表在ArXiv。当时,在5 FPS到160 FPS的范围内,它的速度和准确度超过了所有已知的物体检测器。与YOLOv4一样,它只使用MS COCO数据集进行训练,没有预训练的骨干。YOLOv7提出了一些架构上的变化和一系列的免费包,在不影响推理速度的情况下提高了准确率,只影响了训练时间。 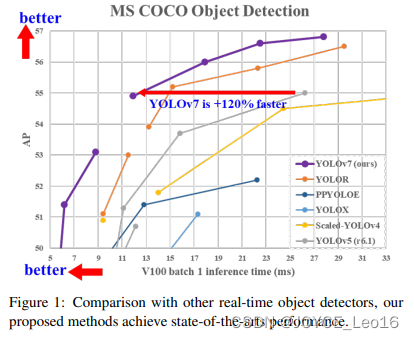 8.2 网络结构 8.2 网络结构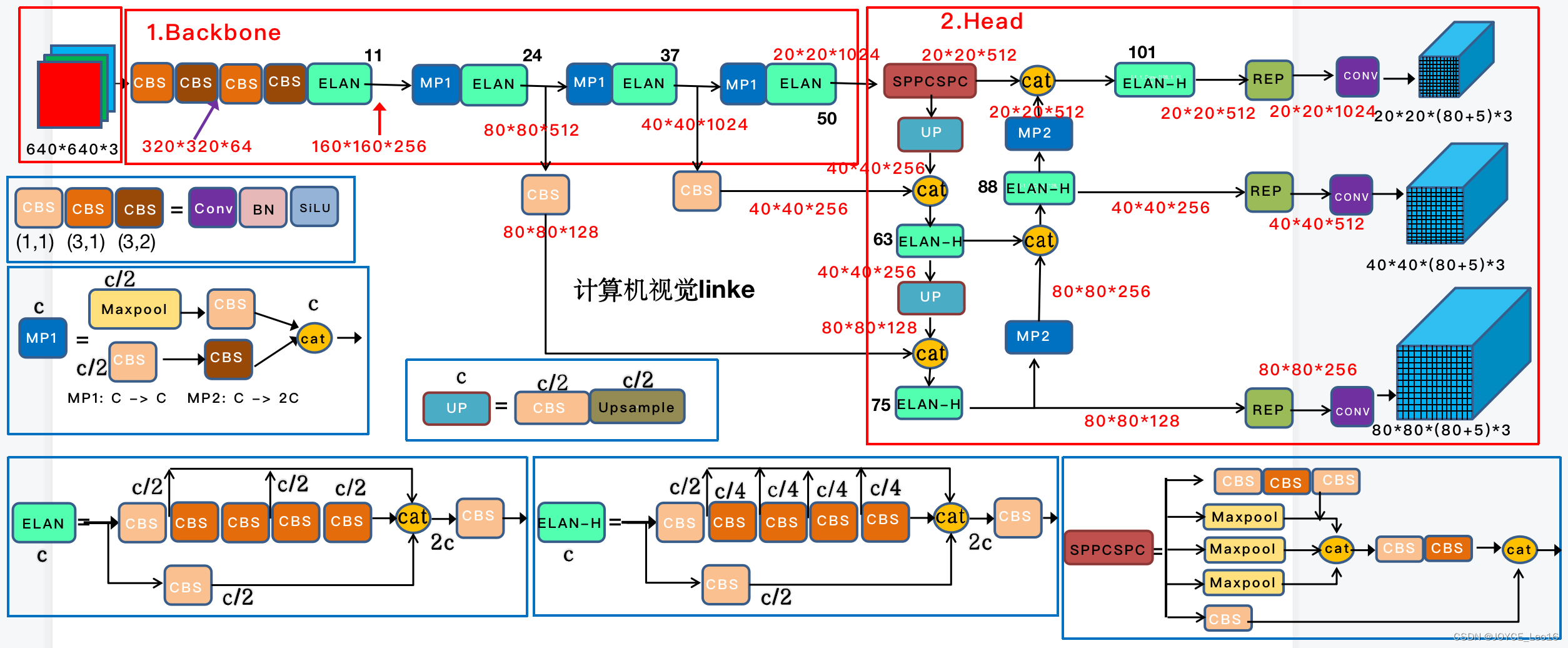 首先对输入的图片 resize 为 640x640 大小,输入到 backbone 网络中,然后经 head 层网络输出三层不同 size 大小的 **feature map**,经过 Rep 和 conv输出预测结果,这里以 coco 为例子,输出为 80 个类别,然后每个输出(x ,y, w, h, o) 即坐标位置和前后背景,3 是指的 anchor 数量,因此每一层的输出为 (80+5)x3 = 255再乘上 feature map 的大小就是最终的输出了。 8.3 改进部分(1)输入端 与YOLOv5类似。 (2)主干网络 Backbone为骨干网络由CBS、ELAN、MP-1组成。 CBS结构:特征提取和通道转换。ELAN:通过不同的分支将特征图拼接起来,进而促进更深层网络的有效学习和收敛。MP-1:将经过不同下采样方式所得到的特征图进行融合,在不增加计算量的同时保留更多的特征信息。(3)颈部网络 该网络主要包括SPPCSPC、ELANW、UPSample三个子模块和Cat结构,其中,SPPCSPC模块用于提高特征提取的效率和准确率;ELANW模块相比于ELAN模块增加了两个拼接操作;UPSample模块用于实现不同层次特征的高效融合;Cat结构旨在进一步优化卷积层的效果。 (4)输出端 与YOLOv6类似。检测头负责网络最终的预测输出,针对Neck处理后的特征信息进行解耦,采用重参数化模块对Neck输出的三种不同尺寸的特征进行通道数调整,再经过1x1的卷积操作,得出目标物体的位置、置信度和类别的预测。 8.4 性能表现YOLOv7 算法提出了基于级联的模型缩放策略从而生成不同尺寸的模型,减少参数量和计算量,可以进行实时目标检测,在大数据集进行训练检测有较高精度且整体检测性能有所提升。但是其网络架构也相对复杂进行训练测试需要大量计算资源,且对小目标和密集场景的检测效果较差。 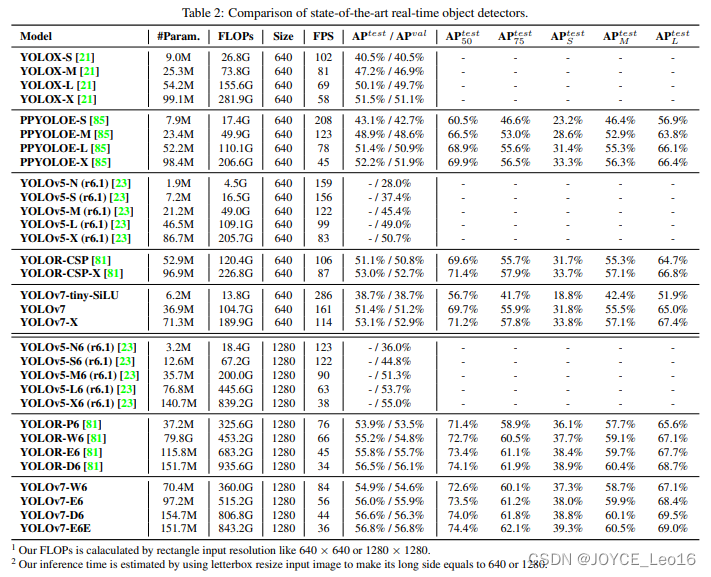 9. YOLOv8(2023) 9. YOLOv8(2023)(代码地址:https://github.com/ultralytics/ultralytics) 9.1 模型介绍YOLOv8 与YOLOv5出自同一个团队,是一款前沿、最先进(SOTA)的模型,基于先前 YOLOv5版本的成功,引入了新功能和改进,进一步提升性能和灵活性。 YOLOv8是一种尖端的、最先进的 (SOTA) 模型,它建立在以前成功的 YOLO 版本的基础上,并引入了新的功能和改进,以进一步提高性能和灵活性。YOLOv8 旨在快速、准确且易于使用,这也使其成为对象检测、图像分割和图像分类任务的绝佳选择。具体创新包括一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,还支持YOLO以往版本,方便不同版本切换和性能对比。 YOLOv8 有 5 个不同模型大小的预训练模型:n、s、m、l 和 x。关注下面的参数个数和COCO mAP(准确率),可以看到准确率比YOLOv5有了很大的提升。特别是 l 和 x,它们是大模型尺寸,在减少参数数量的同时提高了精度。 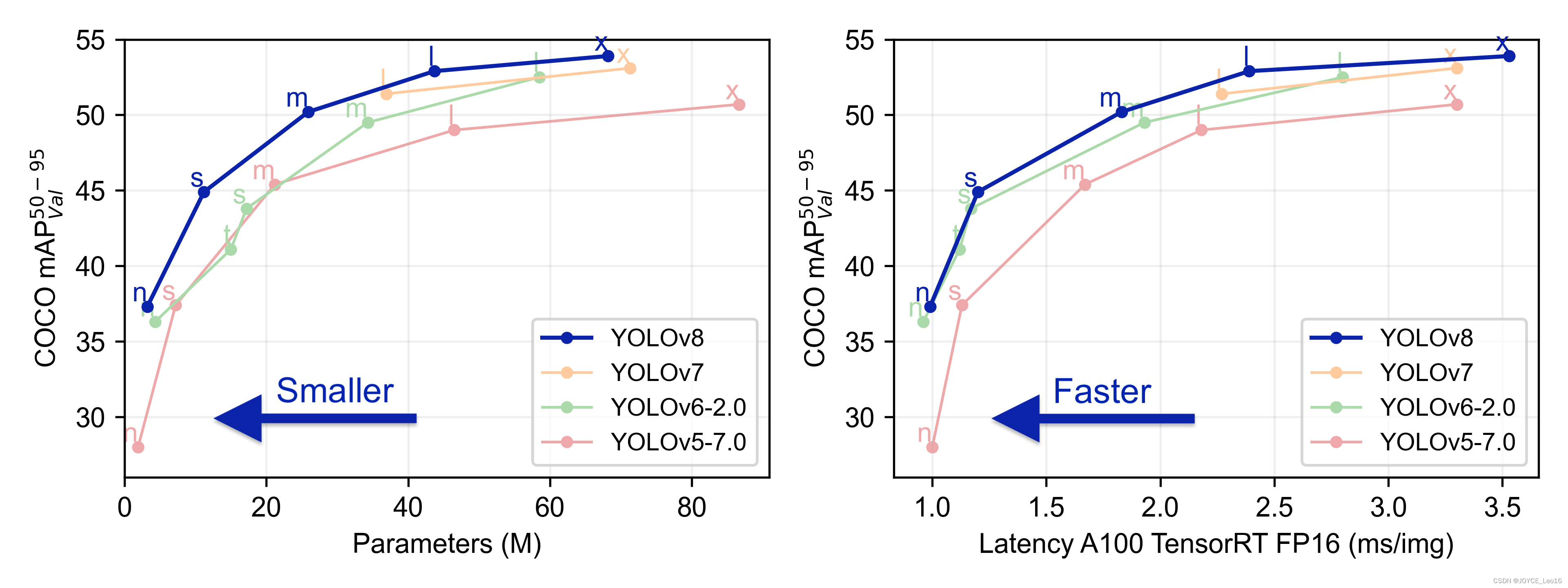 9.2 网络结构 9.2 网络结构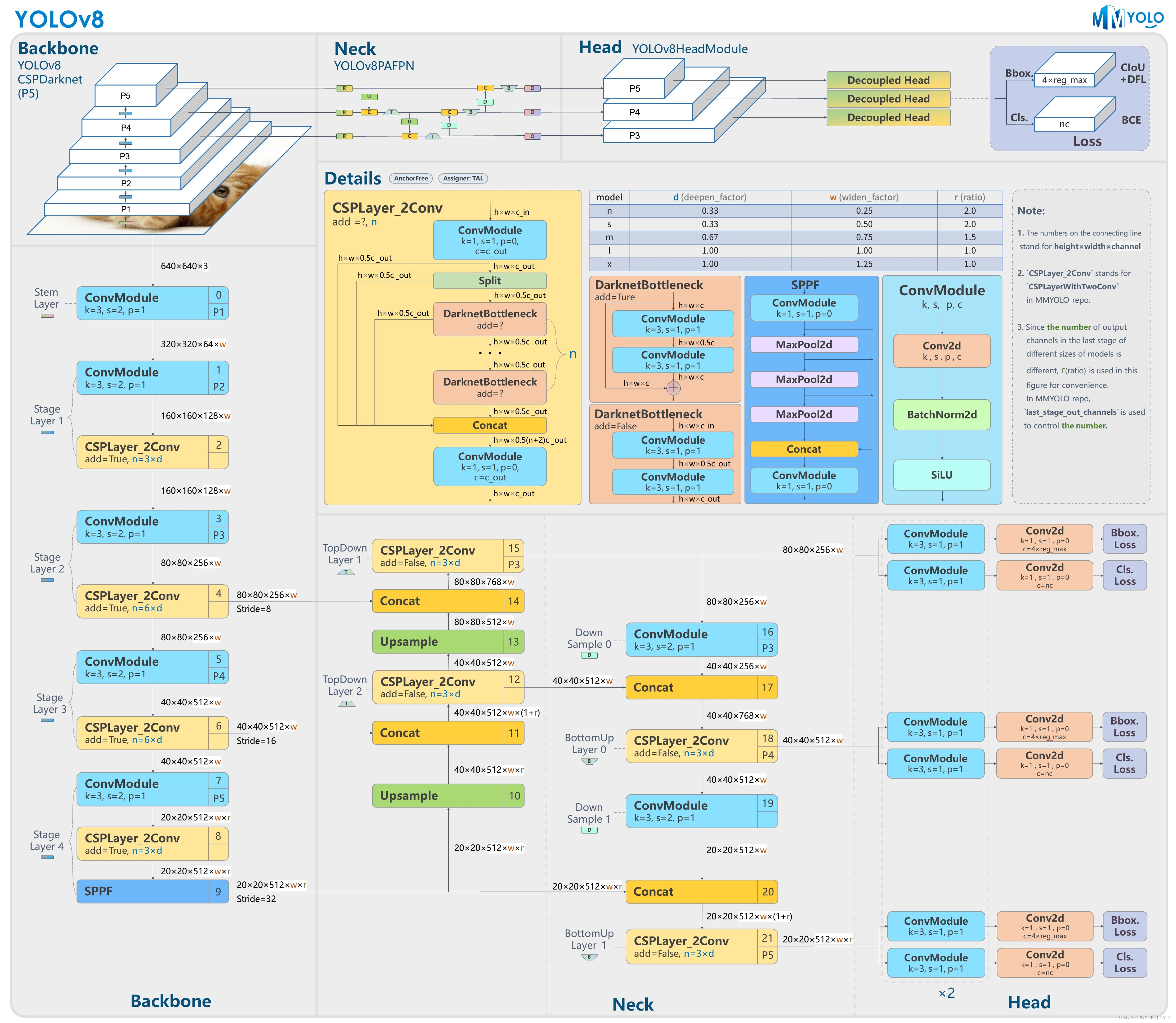 整体结构上与YOLOv5类似: CSPDarknet(主干) + PAN-FPN(颈) + Decoupled-Head(输出头部),但是在各模块的细节上有一些改进,并且整体上是基于anchor-free的思想,这与yolov5也有着本质上的不同。 9.3 改进部分(1)输入端 与YOLOv7类似。 (2)主干网络 Backbone部分采用的结构为Darknet53,其中包括基本卷积单元Conv、实现局部特征和全局特征的Feature Map级别的融合的空间金字塔池化模块SPPF、增加网络的深度和感受野,提高特征提取能力的C2F模块。 (3)颈部网络 与YOLOv5类似。 (4)输出端 在损失函数计算方面,采用了Task AlignedAssigner正样本分配策略。由分类损失VFL(Varifocal Loss)和回归损失CIOU(Complete-IOU)+DFL(Deep Feature Loss)两部分的三个损失函数加权组合而成。 9.4 性能表现YOLOv8 的检测、分割和姿态模型在 COCO 数据集上进行预训练,而分类模型在 ImageNet 数据集上进行预训练。在首次使用时,模型会自动从最新的 Ultralytics 发布版本中下载。 YOLOv8共提供了5中不同大小的模型选择,方便开发者在性能和精度之前进行平衡。以下以YOLOv8的目标检测模型为例: 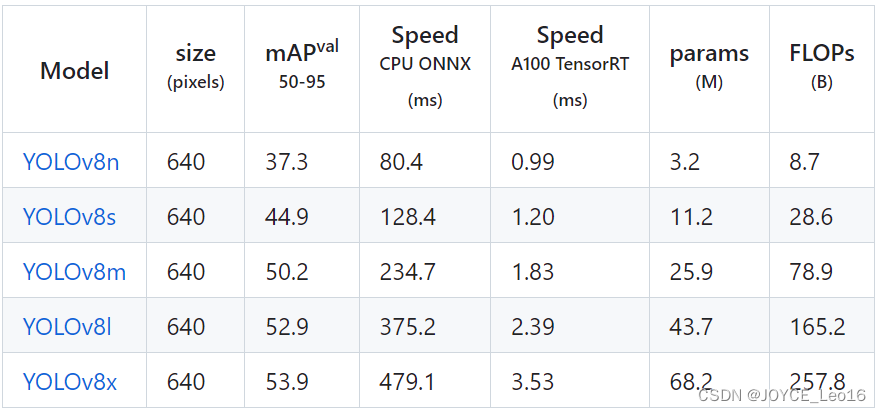 YOLOv8的分割模型也提供了5中不同大小的模型选择: 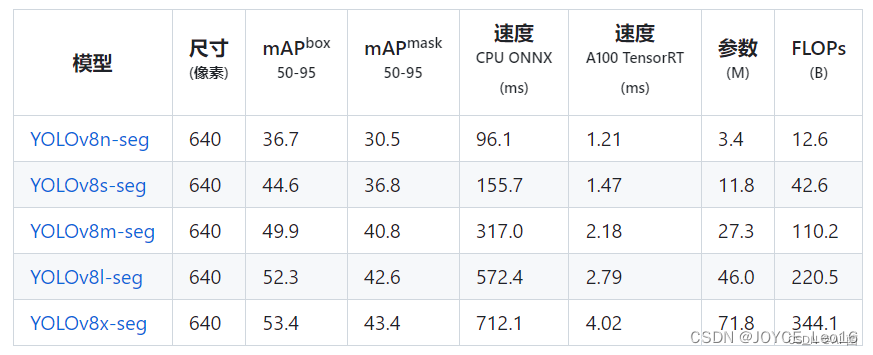 从下图我们可以看到,YOLOv8 在目标检测和实例分割任务上的性能都很好:  (图片来源:YOLOv8来了!) 10. YOLOv9(2024)(论文地址:https://arxiv.org/pdf/2402.13616.pdf) (代码地址:https://github.com/WongKinYiu/yolov9) 10.1 模型介绍YOLOv9是原YOLOv7团队打造,提出了可编程梯度信息(PGI)的概念来应对深度网络实现多个目标所需的各种变化。 PGI可以为目标任务计算目标函数提供完整的输入信息,从而获得可靠的梯度信息来更新网络权值。此外,还设计了一种新的轻量级网络架构——基于梯度路径规划的通用高效层聚合网络(GELAN)。 GELAN的架构证实了PGI在轻量级模型上取得了优异的结果。 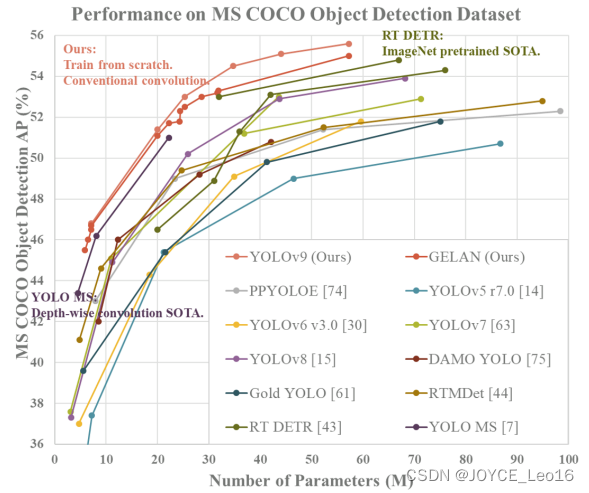 10.2 网络结构 10.2 网络结构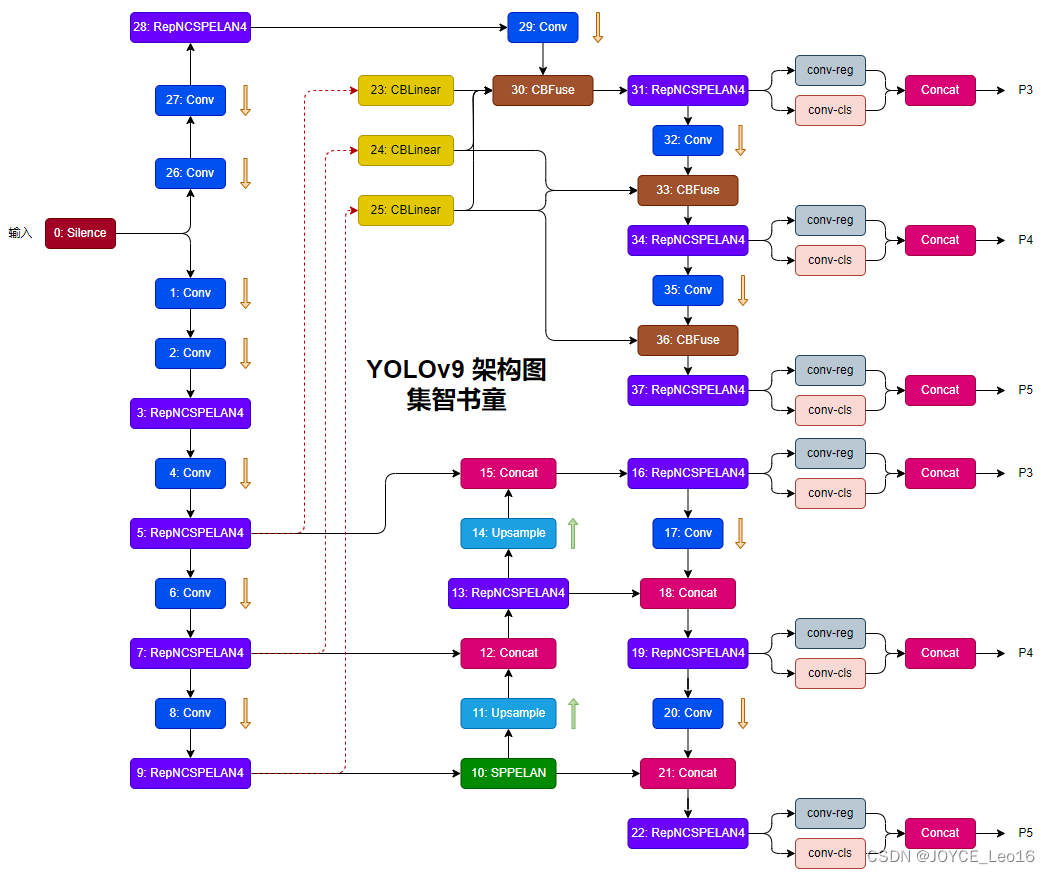 下图展示了不同网络架构的随机初始权重输出特征图的可视化结果:(a) 输入图像,(b) PlainNet,(c) ResNet,(d) CSPNet,和 (e) 提议的GELAN。从这些可视化结果中,我们可以看出在不同的架构中,提供给目标函数用以计算损失的信息在不同程度上有所丢失,而提议的GELAN架构能够保留最完整的信息,并为计算目标函数提供最可靠的梯度信息。 具体来说,输入图像(a)是原始未处理的图像。接下来的四个图像(b-e)分别展示了当这个输入图像通过不同的网络架构时,在网络的某一层上的特征图。这些特征图通过网络层的权重随机初始化得到,旨在展示网络在处理数据时的特征提取能力。图中的颜色变化代表特征的激活程度,激活程度越高,说明网络对于图像的某一部分特征越敏感。  PlainNet (b) 显示了一个基本网络结构的特征图,可以看到有大量的信息丢失,这意味着在实际应用中可能不会捕捉到所有有用的特征。ResNet (c) 作为一个经典的深度学习架构,展示了更好的信息保留能力,但仍有一些信息损失。CSPNet (d) 通过其特殊的结构设计,进一步减少了信息的丢失。GELAN (e) 展示了该研究提出的架构,从图中可以看出,与其他架构相比,它保留了最完整的信息,这表明GELAN架构能更好地保留输入数据的信息,为后续的目标函数计算提供更准确的梯度信息。10.3 主要贡献我们从可逆函数的角度理论分析了现有的深度神经网络架构,并通过这一过程成功解释了过去难以解释的许多现象。我们还基于这一分析设计了PGI和辅助可逆分支,并取得了优异的结果。我们设计的PGI解决了深度监督只能用于极深神经网络架构的问题,因此允许新的轻量级架构真正应用于日常生活中。我们设计的GELAN仅使用传统卷积就实现了比基于最先进技术的深度卷积设计更高的参数利用率,同时展现了轻巧、快速和准确的巨大优势。结合所提出的PGI和GELAN,YOLOv9在MS COCO数据集上的对象检测性能在所有方面都大大超过了现有的实时对象检测器。 PlainNet (b) 显示了一个基本网络结构的特征图,可以看到有大量的信息丢失,这意味着在实际应用中可能不会捕捉到所有有用的特征。ResNet (c) 作为一个经典的深度学习架构,展示了更好的信息保留能力,但仍有一些信息损失。CSPNet (d) 通过其特殊的结构设计,进一步减少了信息的丢失。GELAN (e) 展示了该研究提出的架构,从图中可以看出,与其他架构相比,它保留了最完整的信息,这表明GELAN架构能更好地保留输入数据的信息,为后续的目标函数计算提供更准确的梯度信息。10.3 主要贡献我们从可逆函数的角度理论分析了现有的深度神经网络架构,并通过这一过程成功解释了过去难以解释的许多现象。我们还基于这一分析设计了PGI和辅助可逆分支,并取得了优异的结果。我们设计的PGI解决了深度监督只能用于极深神经网络架构的问题,因此允许新的轻量级架构真正应用于日常生活中。我们设计的GELAN仅使用传统卷积就实现了比基于最先进技术的深度卷积设计更高的参数利用率,同时展现了轻巧、快速和准确的巨大优势。结合所提出的PGI和GELAN,YOLOv9在MS COCO数据集上的对象检测性能在所有方面都大大超过了现有的实时对象检测器。核心算法:(具体参考:http://t.csdnimg.cn/1LWuY) (1)可编程梯度信息(PGI) 为了解决上述问题,论文提出了一种新的辅助监督框架,称为可编程梯度信息(PGI),如图3(d)所示。 PGI主要包括三个组成部分:主分支、辅助可逆分支、多级辅助信息。 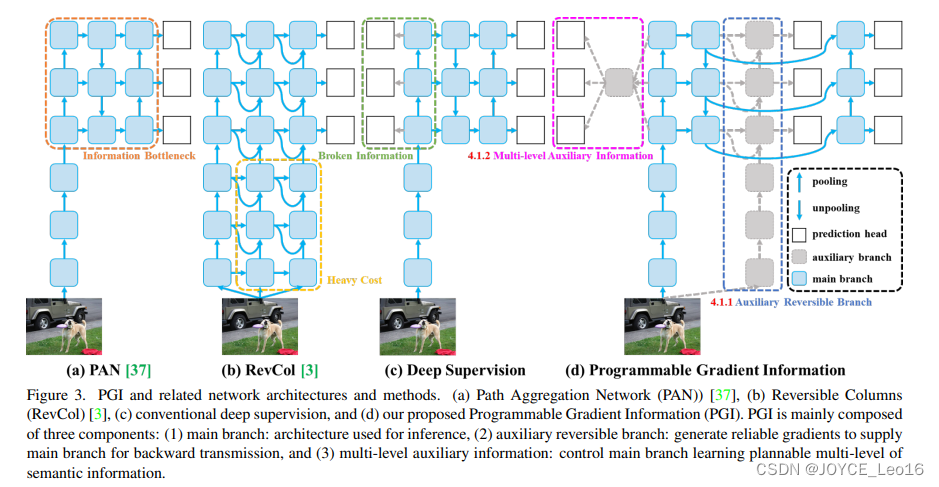 从图3(d)中我们可以看出,PGI的推理过程仅使用主分支,因此不需要任何额外的推理成本。至于其他两个组件,它们仅用于训练阶段而不在推理阶段,用于解决或减缓深度学习方法中的几个重要问题: 辅助可逆分支:是为了处理神经网络加深带来的问题而设计的。网络加深会造成信息瓶颈,导致损失函数无法生成可靠的梯度。对于多级辅助信息:旨在处理深度监督带来的误差累积问题,特别是针对多个预测分支的架构和轻量级模型。(2)GELAN 通过结合采用梯度路径规划设计的两种神经网络架构CSPNet 和ELAN ,论文设计了兼顾轻量级、推理速度和准确性的广义高效层聚合网络(GELAN)。其整体架构如图 4 所示。论文将最初仅使用卷积层堆叠的 ELAN 的功能推广到可以使用任何计算块的新架构。 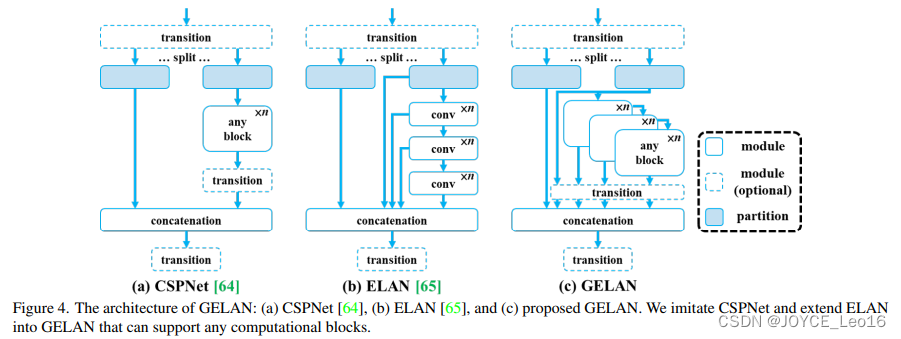 10.4 性能表现 10.4 性能表现我们基于YOLOv7和Dynamic YOLOv7分别构建了YOLOv9的通用和扩展版本。在网络架构设计中,我们用GELAN替换了ELAN,GELAN使用CSPNet块作为计算块,并计划采用RepConv。我们还简化了下采样模块,并优化了无锚点的预测头。至于PGI的辅助损失部分,我们完全遵循了YOLOv7的辅助头设置。 如表1所示,与轻量级和中型模型YOLO MS相比,YOLOv9的参数减少了约10%,计算量减少了5∼15%,但AP仍然有0.4∼0.6%的提升。与 YOLOv7 AF 相比,YOLOv9-C 的参数减少了 42%,计算量减少了 22%,但达到了相同的 AP(53%)。与YOLOv8-X相比,YOLOv9-E参数减少16%,计算量减少27%,AP显着提升1.7%。上述对比结果表明,论文提出的YOLOv9与现有方法相比在各方面都有显著改进。 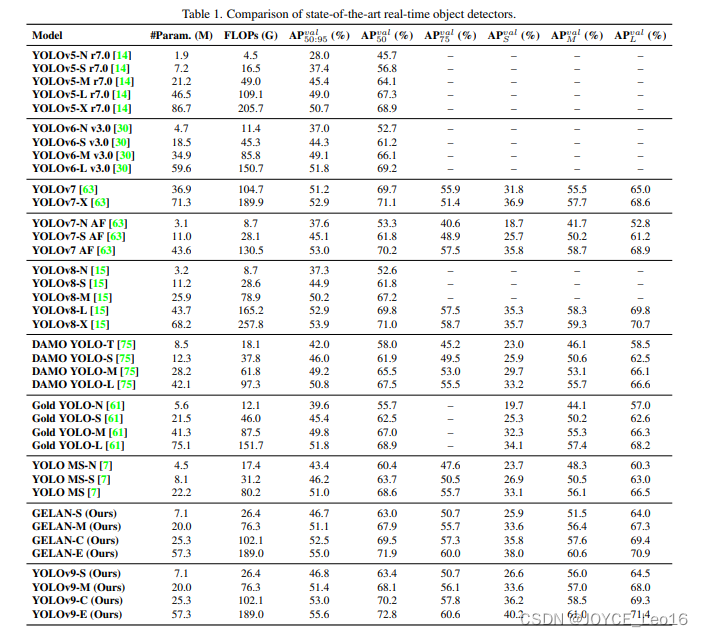 参考: https://arxiv.org/pdf/2304.00501.pdf http://t.csdnimg.cn/pQb6X http://t.csdnimg.cn/GfUXC http://t.csdnimg.cn/f9x3z http://t.csdnimg.cn/gSuBb http://t.csdnimg.cn/eIzHw http://t.csdnimg.cn/0e7zR https://www.cnblogs.com/cvlinke/p/16496988.html http://t.csdnimg.cn/CvyTo http://t.csdnimg.cn/aKEOi http://t.csdnimg.cn/1LWuY |
【本文地址】
今日新闻 |
推荐新闻 |