机器学习入门研究(十七) |
您所在的位置:网站首页 › instacart官网 › 机器学习入门研究(十七) |
机器学习入门研究(十七)
|
目录 1.获取数据 2.合并数据 3.数据降维 4.使用K-means进行分类 分类 KMeans预估器返回参数 5.总结 Instacart Market Basket Analysis是一个经典的顾客行为预测案例。通过分析开源大量的订单数据来预测将用户进行分类 1.获取数据我们从官网中下载到对应的数据,放到本地目录之后,读取到数据如下: (1)order_products__prior.csv:订单与商品信息。对应的字段有:order_id, product_id, add_to_cart_order, reordered,我们通过 order_products = pd.read_csv("order_products__prior.csv")获取到该表中的内容如下,只截取部分数据如图:
(2)products.csv:商品信息。对应的字段有:product_id, product_name, aisle_id, department_id,我们通过 products = pd.read_csv("products.csv")获取到该表中的内容如下:只截取部分数据如图:
(3)orders.csv:用户的订单信息。对应的字段有:order_id,user_id,eval_set,order_number,….,我们通过 orders = pd.read_csv("orders.csv")获取到该表中的内容如下:只截取部分数据如图:
(4)aisles.csv:商品所属具体物品类别。对应的字段有:aisle_id, aisle,我们通过 aisles = pd.read_csv("aisles.csv")获取到该表中的内容如下:只截取部分数据如图:
从上面的几个表中,我们并不能进行预测用户的购物行为,我们能用来预测用户的购买物品的类别,那么就需要将用户的user_id和用户物品类别aisle之间的建立关系,但是我们发现用户信息user_id在orders中 ,商品类别aisle在aisles中,那么需要将user_id和aisle建立关系才可以进行预测。 所以我们的目标就是将user_id和aisle,并将user_id作为表的行索引,aisle作为列索引,那么我们就可以采用聚类算法来进行预测了。 2.合并数据通过观察几个表发现,aisle和user_id可以通过aisle_id、product_id、order_id进行关联到一起。 (1)我们发现在aisles.csv中有aisle_id,在products.csv也有aisle_id,所以需要先把这两个表进行合并,采用pandas中的merge来进行合并,两个表无先后顺序,并且merge默认的为内联接,我们只需要按照aisle_id进行合并即可。 #的是让aisle_id和product_id 在同一张表中 tab1=pd.merge(aisles,products, on =["aisle_id","aisle_id"] )得到的表如下:
经过上述操作这样我们就拿到了第一张表,此时aisle_id和product_id 在同一张表中。 PS:pandas.merge作用:根据某个字段对表进行合并 pandas.merge(left, right, how="inner", on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=("_x", "_y"), copy=True, indicator=False, validate=None )其中几个主要参数介绍如下: 参数含义left左表right右表how合并表方式,默认为inner,还可以支持outer:全连接 /left:左连接 /right :右连接 on根据某个字段进行合并,必须两个都存在,当两个表格中没有同时存在的话,可以使用left_on/right_on来设置left_on左表需要连接字段right_on右表需要连接的字段left_index左表行索引作为连接间right_index右表行索引作为连接间 suffixes对两个数据集中出现的重复列,新数据集中加上后缀_x,_y进行区别indicator根据连接键对合并后的数据进行排列,默认为True(2)我们在看哪个表格中含有product_id,我们看到order_products中含有product_id,那么我们就需要将刚才获得的tab1和order_products进行合并 tab2=pd.merge(tab1,order_products,on=["product_id","product_id"])得到的tab2表结构如下:
这样我们获得的tab2就含有了aisle_id和order_id (3)我们在看哪个表中含有order_id,在orders中含有order_id,并且含有user_id,那么我们将orders和tab2合并后,生成的表中就即含有aisle_id,也含有 aisle_id和user_id了,这样就将aisle_id和user_id放到了同一张表中了,这个表格中就含有了user_id和aisle。
(4)上面提到的tab3,并不是我们想要的行索引为 user_id,类索引为商品类别aisle,那我们还需要用到到交叉表,来找到这两者之间的频次的关系。那就需要使用交叉表对tab3进行转化成行为user_id,列为商品类别个数的表结构。如下: table = pd.crosstab(tab3["user_id"],tab3["aisle"])转化后的表结构如图所示:
我们可以看到获取到的表结构一共有206209个样本,134个特征。 PS:pandas.crosstab作用:用于统计分组频率,是一种特殊的pivot_table() pandas.crosstab( index, columns, values=None, rownames=None, colnames=None, aggfunc=None, margins=False, margins_name="All", dropna=True, normalize=False, )其中参数介绍如下: 参数含义index行分组的键值。支持数组,若是数组,则说明为行为多级级联索引columns列分组的键值。支持数组,若是数组,则说明为列为多级级联索引values根据因子聚合的列表,需制定聚合函数rownames队列,如指定,必须与传递的队列列数匹配colnames队列,如指定,必须与传递的队列数匹配aggfunc配合values使用,该值传入的是计算函数例如aggfunc=np.average,那么就是对values标记的行或者列进行求平均值margins增加一行/列“总计”,默认为False。与normalize配合使用。 在设置为True的前提下: 如果normalize=‘index’,则margins作为新的一行出现在底部,即在底部多一行margins_name为索引值的总计数目; 如果normalize=‘columns’,则在最右侧增加一列,即在最右侧增加一行为margins_name为索引值的总计数目; 如果normalize=True,则在行和列都增加以margins_name为索引值的总计数目,即分别统计行和列的个数 margins_name增加的行/列的名字,默认值Alldropna默认为True,如果某列的数据全是Nan,则删除normalize是否被转化成浮点型都被转化成浮点型 默认为False。 normalize为'index'或1,则normalize每一行,转化值在单元格数据在该行的总数据中的占比 normalize为'columns'或0,则normalize每一列,转化值为单元格的数据在该列的总数据中的占比 normalize为'All'或True,则normalize全部,转化值为在单元格的数据在数据总和的占比 3.数据降维我们看到上面最后得到的数据集中一共有134个特征,但是特征里面有大量的0,说明有大量的特征冗余,所以要用PCA进行降维。其步骤如下:基本上就是实例化转换器,然后调用转换器的fit_transform进行转化。 #1)实例化一个转换器,一般采用百分比 #2)调用fit_transform transfer = PCA(n_components=0.95) data_new = transfer.fit_transform(table)转化后的data_new的数据如下:
现在经过PCA降维之后,就只剩下44个特征了。 4.使用K-means进行分类由于我们现在的数据集中无标签,所以需要通过无监督学习的方式来进行分类,我们使用K-means进行将用户分类。假设我们现在把用户分成3类,那么此时sklearn中的KMeans中的n_clusters为3。 分类我们看下步骤,和之前我们提到的监督学习的步骤一样: (1)实例化预估器 estimator = KMeans(n_clusters=3)(2)用预估器进行预测,由于这里没有标签,所以直接只传入特征值即可 estimator.fit(data_new) y_predict = estimator.predict(data_new)我们打印下该分类结果的前300条数据,发现每一个样本现在都被归为一类,用0,1,2来表示这三类人:
(3)评价预估器 这个后面会单独在去总结,这里先不去总结了。等总结好了,在更新。 KMeans预估器返回参数我们在看下这个KMeans预估器里面的一些返回参数: (1)返回该所有样本对应的分类标签 estimator.labels_可以看下输出的值为:可以看到就是一个一维数组,每个样本对应的分类的类别
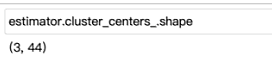
(2)返回分类簇的中心点坐标 estimator.cluster_centers_由于数据内容比较多,不再截图数组的内容,只展示数组的大小,是一个
关于聚类和降维里面的有些东西自己还是不太清楚,自己还需要在多去学习下。里面涉及到的代码已经上传。由于那个csv文件比较大,可以自行上官网进行下载。 |











【本文地址】
今日新闻 |
推荐新闻 |