TiDB 高并发写入场景最佳实践 |
您所在的位置:网站首页 › influxdb批量写入并发 › TiDB 高并发写入场景最佳实践 |
TiDB 高并发写入场景最佳实践
|
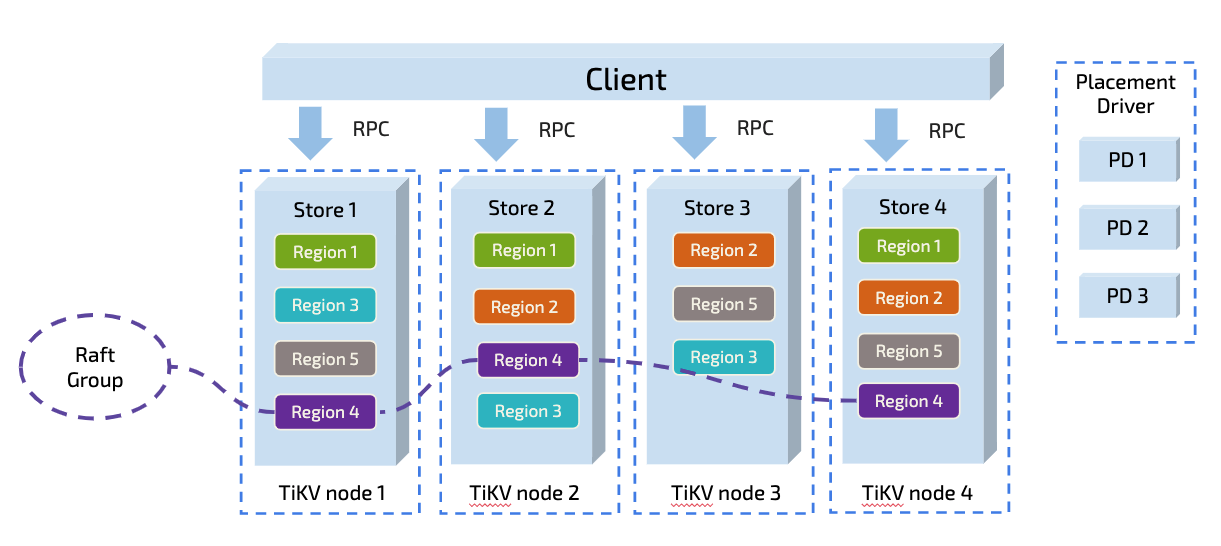
TiDB 高并发写入场景最佳实践 在 TiDB 的使用过程中,一个典型场景是高并发批量写入数据到 TiDB。本文阐述了该场景中的常见问题,旨在给出一个业务的最佳实践,帮助读者避免因使用 TiDB 不当而影响业务开发。 目标读者本文假设你已对 TiDB 有一定的了解,推荐先阅读 TiDB 原理相关的三篇文章(讲存储,说计算,谈调度),以及 TiDB Best Practice。 高并发批量插入场景高并发批量插入的场景通常出现在业务系统的批量任务中,例如清算以及结算等业务。此类场景存在以下特点: 数据量大需要短时间内将历史数据入库需要短时间内读取大量数据这就对 TiDB 提出了以下挑战: 写入/读取能力是否可以线性水平扩展随着数据持续大并发写入,数据库性能是否稳定不衰减对于分布式数据库来说,除了本身的基础性能外,最重要的就是充分利用所有节点能力,避免让单个节点成为瓶颈。 TiDB 数据分布原理如果要解决以上挑战,需要从 TiDB 数据切分以及调度的原理开始讲起。这里只作简单说明,详情可参阅谈调度。 TiDB 以 Region 为单位对数据进行切分,每个 Region 有大小限制(默认 96M)。Region 的切分方式是范围切分。每个 Region 会有多副本,每一组副本,称为一个 Raft Group。每个 Raft Group 中由 Leader 负责执行这块数据的读 & 写(TiDB 支持 Follower-Read)。Leader 会自动地被 PD 组件均匀调度在不同的物理节点上,用以均分读写压力。
从原理上来说,只要没有业务上的写入热点(即业务写入没有 AUTO_INCREMENT 的主键和单调递增的索引,更多细节可参阅 TiDB 正确使用方式),依靠这个架构,TiDB 不仅具备线性扩展的读写能力,也能够充分利用分布式资源。从这一点看,TiDB 尤其适合高并发批量写入场景的业务。 但理论场景和实际情况往往存在不同。以下实例说明了热点是如何产生的。 热点产生的实例以下为一张示例表: CREATE TABLE IF NOT EXISTS TEST_HOTSPOT( id BIGINT PRIMARY KEY, age INT, user_name VARCHAR(32), email VARCHAR(128) )这个表的结构非常简单,除了 id 为主键以外,没有额外的二级索引。将数据写入该表的语句如下,id 通过随机数离散生成: SET SESSION cte_max_recursion_depth = 1000000; INSERT INTO TEST_HOTSPOT SELECT n, -- ID RAND()*80, -- 0 到 80 之间的随机数 CONCAT('user-',n), CONCAT( CHAR(65 + (RAND() * 25) USING ascii), -- 65 到 65+25 之间的随机数,转换为一个 A-Z 字符 '-user-', n, '@example.com' ) FROM (WITH RECURSIVE nr(n) AS (SELECT 1 -- 从 1 开始 CTE UNION ALL SELECT n + 1 -- 每次循环 n 增加 1 FROM nr WHERE n |
【本文地址】
今日新闻 |
推荐新闻 |