时序数据库爆了!下一个独角兽是拿来的开源还是大投入的“自研”系统? |
您所在的位置:网站首页 › influxdb使用场景 › 时序数据库爆了!下一个独角兽是拿来的开源还是大投入的“自研”系统? |
时序数据库爆了!下一个独角兽是拿来的开源还是大投入的“自研”系统?
|
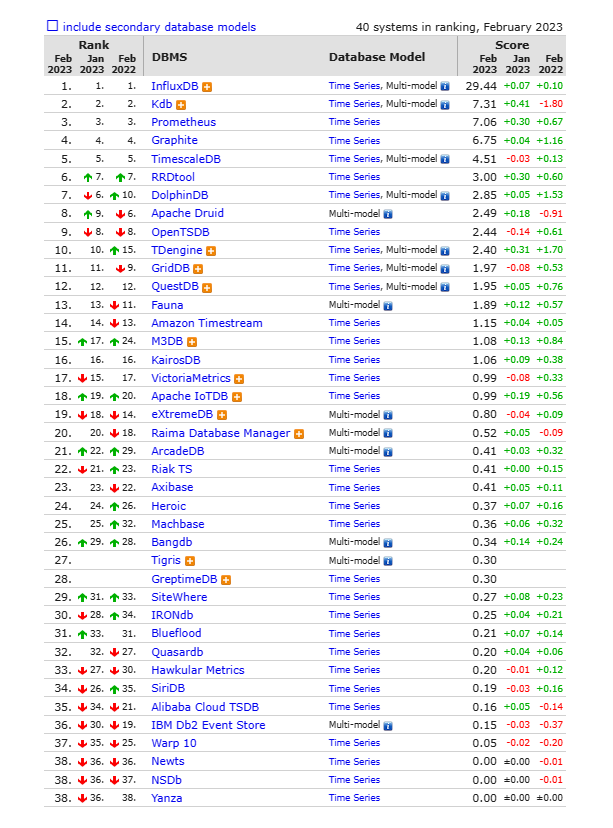
时间序列数据过去由通用数据库处理。例如,如果在20年前,有人可能会在Oracle的关系数据库中构建应用;如果在10年前,有人可能会使用通用SQL数据库。显然 随着时序数据量的增加,其性能、扩展性等都难以满足需求。 在 最近的5~7年里,出现了一个专门处理时间序列类别的数据库,也就是说,如果你知道数据的特征——也就是随时间推移的数据——那么你就可以采用时间序列数据库,一般简称为时序数据库。 专为时序数据优化而设计的时序数据库,在很多方面都与传统的关系型数据库不太一样,如它不关心范式和事务;写多于读,95%-99%的操作都是写操作;顺序读,基本上都是按照时间顺序读取一段时间内的数据等。 因此,时序数据库以写性能优先,不为读取做存储优化,但是通过分布式和并发读,来提高读取的速度。 在写入的时候就考虑到读的性能问题,将统一指标、时间段的数据写入到同一数据块中,为读取进行写入优化。 时序数据库应用场景大爆发。2020年出现的 新冠疫情,使全球数十亿人成为时间序列数据的消费者,以便准确及时地提供疫情相关各种统计数据。 现在比较流行的各种穿戴设备,都可以联网,穿戴设备上采集的心跳信息、血流信息、体感信息等也会实时传输给服务器进行实时分析、存储以及查询统计。 财务数据就是时间序列数据。时序数据库可以轻松跟踪时间序列资金、市场数据,并将其与其他数据相关联,快速做出决策。 面向客户和内部的SaaS应用和数据管道等产品数据也是时间序列数据。用户想快速了解产品随时间推移的使用方式、细分客户群,以便做出产品和业务决策。时序数据库可以存储所有应用程序指标,而成本只是分析服务的一小部分。 通过精确定位地理空间和时间精度跟踪设备性能是一个时间序列问题。时序数据库可帮助用户经济高效地大规模存储和分析源源不断的设备遥测和传感器数流,以便管理工业设备维护、车队管理、资产跟踪、路线规划、产量优化、石油和天然气生产等。 在可预知的未来3~5年,随着物联网以及工业4.0的到来,所有设备都会携带传感器并联网,传感器收集的时序数据将严重依赖时序数据库的实时分析能力、存储能力以及查询统计能力。 开源系统先行,背后商业公司伺机而动 每一个开源系统背后都有一家商业公司,就像开源搜索数据库Elasticsearch背后有一个市值50多亿美元的Elastic公司;开源MySQL背后有巨头甲骨文;开源数据库MariaDB背后有上市的商业数据库公司MariaDB plc··· 时序数据库也不例外,开源系统InfluxDB、Kdb+和Prometheus长时间霸占DB-Engine榜单前三 。
主流的时序数据库 数据来源:DB-Engines InfluxData是开源的InfluxDB的创建者和主要赞助商,专为处理物联网设备和传感器、应用程序、容器、虚拟机和网络生成的大量带时间戳的数据而构建InfluxDB。 InfluxData成立于2012年,总部位于美国旧金山。作为时间序列数据管理专家,InfluxData是在刚刚的E轮融资和其他企业融资中筹集了8100万美元,使其总融资额超过2亿美元。 InfluxData在时序数据库发展上,有两大突出表现: 一是InfluxData 专为时间序列数据构建新型的系统,因此在性能等方面表现突出。在时间序列数据库领域,有在关系数据库基础上进行改进的时序数据库,比如基于PostgreSQL开发的TimescaleDB,也有在KV数据库的基础之上进行改进的时序数据库,比如基于HBase开发的OpenTSDB。但是与专门的时序数据库相比,显然不在一个层次。 二是在提高时序数据库性能的同时, 针对新需求提出更多解决方案。InfluxData首席执行官Evan Kaplan说:“作为现代时间序列市场的先驱,我们在推动该领域最近的加速发展方面发挥了关键作用,将时间序列从边缘推向云,现在又进入分析领域。我们的投资者相信我们对时间序列的愿景,可以为客户和社区可以想象的最复杂和最大规模的分析用例提供支持。” InfluxData推出InfluxDB Cloud,让用户专注于构建应用,而不是管理集群,并可在AWS、Google和Azure上使用;在边缘运行的InfluxDB 是开源的、社区支持的时间序列数据库,很容易部署在边缘、本地笔记本电脑或服务器上;本地部署上,InfluxDB Enterprise 预配和控制的环境中利用高级安全性和合规性功能。 云服务商因为IoT需求而发展起来的时序数据库服务托管也快速发展,如边云一体化,方案集成方便简单的阿里云Lindorm TSDB时序数据库;对内支撑了华为云基础设施服务,对外以服务的形式开放,帮助上云企业解决相关业务问题华为GaussDB(for Influx)时序数据库;快速、可扩展的全托管、无服务器时间序列数据库服务的亚马逊云科技的Amazon Timestream等。 自主研发与开源系统谁能统领市场? 在时序数据库市场,相对于开源系统,自主研发的系统表现出更强的竞争力。国内自研的时序数据库正开始替代国外的开源系统,实现时序数据库库的国产化替代。 星环科技在其大数据基础平台TDH 9.0中,实现9种存储引擎支持10种数据模型。其中,时序数据库Timelyre已经升级到了2.2版本。 为了满足时间序列数据的处理需求,Timelyre改进压缩算法,进一步降低了20%~50%存储空间占用,提升2倍写入性能。 同时相比于开源时序产品,Timelyre基于TDH多模型架构下的分布式扩展能力,让Timelyre具备了更多设备标签存储能力,以及基于TDH统一SQL分析能力,让Timelyre具备复杂关联查询能力。 成立于2016年的智臾科技其拥有集高性能时序数据库与全面的分析功能为一体的新一代数据库DolphinDB。 由浪潮集团控股的KaiwuDB今年推出时序数据库KaiwuDB 1.0,拥有实时就地运算等核心专利技术。 北京东方国信科技股份有限公司 自主研发的产品CirroData-TimeS在时序空间大数据处理上有着独到的优势。 面对日益增加的应用场景以及市场空间, 国产自研的时序数据库将迎来巨大的发展机遇。 从产品技术发展上看,未来时序数据库首先要 支持海量的设备、大量的指标和标签,而不是现在开源系统的InfluxDB建议标签数不要超过3~5个,而其性能会随着指标数的增加而降低。 二是不但要很好地支持Metrics这种查询,而且还 要实现一流的分析能力。 三是 支持多态存储、多机存储、存算分离。 最后是可视化服务。随着万物互联的到来,用户对信息的全面掌握的需求增长,时序数据的可视化展示成为一大趋势,对时序数据库的查询能力提出更高的要求。 参考资料: ·https://analyticsindiamag.com/threes-a-crowd-chatgpt-vs-bard-vs-ernie-bot/ ·https://www.timescale.com/blog/what-is-a-time-series-database/ ·https://www.influxdata.com/blog/relational-databases-vs-time-series-databases/#:~:text=Relational%20Database%20Overview ·https://transwarp.cn/subproduct/timelyre 扫码关注 大数据应用,从现在开始 END返回搜狐,查看更多 |
【本文地址】
今日新闻 |
推荐新闻 |