如何比较Hive,Spark,Impala和Presto? |
您所在的位置:网站首页 › impala和mysql区别 › 如何比较Hive,Spark,Impala和Presto? |
如何比较Hive,Spark,Impala和Presto?
|
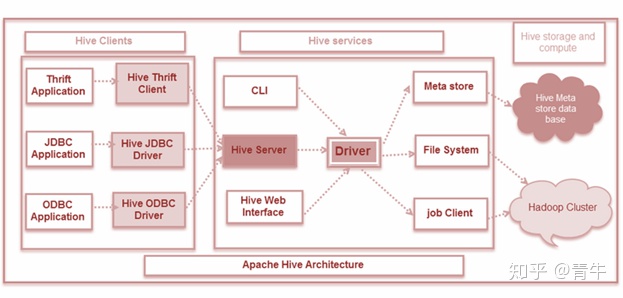
Spark,Hive,Impala和Presto是基于SQL的引擎,Impala由Cloudera开发和交付。在选择这些数据库来管理数据库时,许多Hadoop用户会感到困惑。Presto是一个开放源代码的分布式SQL查询引擎,旨在运行甚至PB级的SQL查询,它是由Facebook人设计的。 Spark SQL是一个分布式内存计算引擎,它的内存处理能力很高。Hive也由Apache作为查询引擎引入,这使数据库工程师的工作更加轻松,他们可以轻松地在结构化数据上编写ETL作业。在发布Spark之前,Hive被认为是最快速的数据库之一。 现在,Spark还支持Hive,也可以通过Spike对其进行访问。就Impala而言,它也是一个基于Hadoop设计的SQL查询引擎。Impala查询不会转换为mapreduce作业,而是本地执行。 这是对Hive,Spark,Impala和Presto的简要介绍。在本文中,我们会讲解这些SQL查询引擎的功能描述,并根据它们的属性介绍这些引擎之间的差异。 Hive,Spark,Impala和Presto之间的区别让我们看一下所有这些功能特性的描述: 什么是Hive?用于查询和管理大型数据集的Apache Hive数据仓库软件设施将分布式存储用作其后端存储系统。它建立在Apache之上。该工具是在Hadoop文件系统或HDFS的顶部开发的。Hadoop可简化以下任务: 临时查询数据封装庞大的数据集和分析 Hive特征 在Hive中,首先创建数据库表,然后将数据加载到这些表中Hive旨在管理和查询存储表中的结构化数据Map Reduce没有可用性和优化功能,但是Hive具有这些功能。查询优化可以高效地执行查询Hive的灵感语言降低了Map Reduce编程的复杂性,并重用了其他数据库概念,例如行、列、模式等。Hive使用目录结构进行数据分区并提高性能。Hive的大多数交互都是通过CLI或命令行界面进行的,并且HQL或Hive查询语言用于查询数据库Hive支持四种文件格式,即TEXTFILE,ORC,RCFILE和SEQUENCEFILE Hive的三个核心部分 Hive客户Hive服务Hive存储和计算
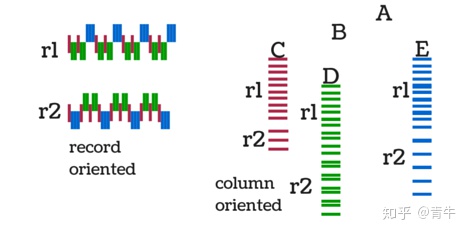
通过不同的驱动程序,Hive与各种应用程序进行通信。与基于Java的应用程序一样,它使用JDBC驱动程序,对于其他应用程序,它使用ODBC驱动程序。Hive客户端和驱动程序然后再次与Hive服务和Hive服务器通信。Hive客户端可以通过Hive服务解决其查询。 CLI或命令行界面在这里就像Hive服务一样,用于数据定义语言操作。来自不同应用程序的请求由驱动程序处理,并转发到不同的Meta商店和现场系统进行进一步处理。 Hive服务(如作业客户端,文件系统和元存储)与Hive存储进行通信,并用于执行以下操作: 在Hive中创建并存储了表的元数据信息,也称为“元存储数据库”数据和查询结果加载到表中,这些表以后存储在HDFS上的Hadoop集群中配置单元在本地模式或地图缩小模式下执行。如果数据大小较小或处于伪模式下,则使用Hive的本地模式可以提高处理速度。而对于大量数据或用于多节点处理,则使用Hive的Map Reduce模式,以提供更好的性能。 什么是Impala?Impala是一个大规模并行处理引擎,是一个开源引擎。它要求将数据库存储在运行Apache Hadoop的计算机群集中。这是一个SQL引擎,由Cloudera在2012年推出。 Hadoop程序员可以以出色的方式在Impala上运行其SQL查询,它被认为是一种高效的引擎,因为它在处理之前不会移动或转换数据,该引擎可以轻松实现。Impala的数据格式、元数据、文件安全性和资源管理与MapReduce相同。 它具有Hadoop的所有特质,还可以支持多用户环境。以下列出了使Impala非常有用的两个最有用的品质: 1)列存储
2)树结构
Impala在2年内崛起,已成为最重要的SQL引擎之一。现在,甚至Amazon Web Services和MapR都已列出了对Impala的支持。 什么是Spark?Apache Spark是最受欢迎的QL引擎之一,它是通用数据处理引擎,在核心火花数据处理的顶部还有很多其他库,例如图形计算、机器学习和流处理,这些库可以在应用程序中一起使用。Spark支持以下语言,例如Spark、Java和R应用程序开发。
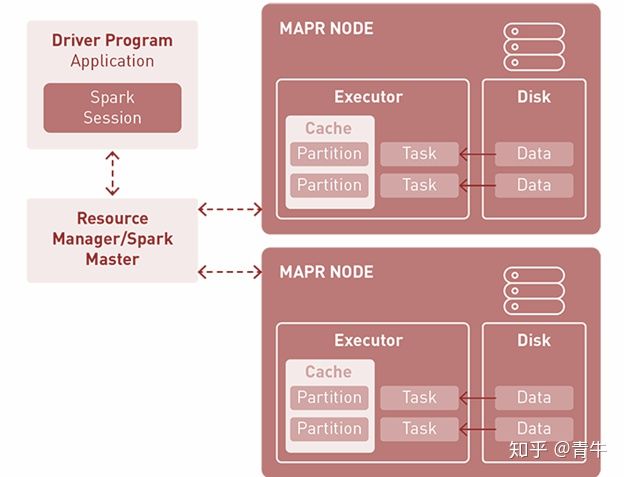
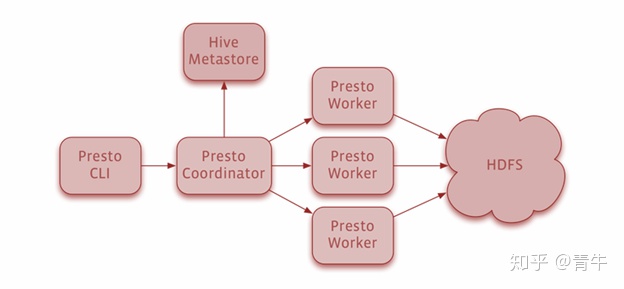
Spark应用程序运行几个独立的进程,这些进程由驱动程序中的SparkSession对象协调,簇或资源管理器也将该任务分配给工作人员。任务将其工作单位应用于数据集、结果,创建了一个新的数据集分区,最终结果可以存储并保存在磁盘上,也可以发送回驱动程序。 Spark可以处理PB级的数据,并以分布式方式在成千上万个群集中进行处理,这些群集分布在几个物理和虚拟群集之间。Spark被用于多种应用,例如: 流处理机器学习互动分析资料整合由于其有益的功能(例如速度,简单性和支持),Spark被许多用户选择。可以通过一组丰富的API来访问Spark的功能,这些API专门用于快速,轻松地与数据进行交互。Apache Spark社区庞大且支持您快速,快速地获得查询的答案。 什么是Presto?Presto是一个分布式的开源SQL查询引擎,用于运行交互式分析查询。它可以处理从GB到PB的任何大小的查询。Presto是由Facebook人设计的。它旨在加速商业数据仓库查询处理。它可以扩大与Facebook相匹配的组织规模。 Presto在一组机器上运行。Presto设置包括多个工作人员和协调员。Presto查询由其客户提交给协调器。然后,Presto协调器分析查询并创建其执行计划。稍后,处理过程将分配给工人。
在处理PB级或TB级数据时,用户将不得不使用大量工具与HDFS和Hadoop进行交互。Presto可以帮助用户通过Hive和Pig等MapReduce作业管道查询数据库。Presto可以帮助用户处理不同类型的数据源,例如Cassandra和许多其他传统数据源。 Presto的功能 可以帮助从其驻留位置查询数据,例如Hive,Cassandra,专有数据存储或关系数据库。可以合并来自多个数据源的单个查询的数据Presto的响应时间非常快,通过昂贵的商业解决方案,他们可以快速解决查询它使用矢量化的柱状处理Presto具有流水线执行其架构简单而广泛Facebook每天都使用Presto在一天中运行PB级数据。这可能包括几个内部数据存储。它还支持为查询提供数据的可插拔连接器。Presto支持以下连接器: TPC-HCassandraHadoop /Hive就Presto应用程序而言,它支持Facebook,Teradata和Airbnb等许多工业应用程序。Presto支持标准的ANSI SQL,这对于数据分析人员和开发人员而言非常容易。Presto是用Java开发和编写的,但没有与Java代码相关的问题,例如: 内存分配和垃圾回收。Presto具有Hadoop友好的连接器体系结构。 推荐用法 就这些查询引擎的用途而言,您可以考虑以下几点: 对于任何类似BI的交互式工作负载,Impala可能是您的最佳选择。由于Impala查询的延迟最低,如果是为了减少查询延迟,您可以果断选择Impala,尤其是对于并发执行。 但对于低延迟和多用户支持要求,Hive也是不错的选择。选择Hive,仅出于您的ETL或批处理要求。但Hive不会减少太多查询处理所需的时间,因此它可以成为BI的合适选择。 Spark SQL,用户可以有选择地使用SQL构造为Spark管道编写查询。Spark SQL重用Hive元存储和前端,与现有的Hive查询,数据和UDF完全兼容。通过基于成本的查询优化器,代码生成器和列式存储Spark查询的执行速度得以提高。 Presto在BI类型查询中处于领先地位,与主要用于性能丰富查询的Spark不同,Presto对并发查询工作负载的支持至关重要。因此从并发查询执行和增加的工作量的角度出发,您可以使用它。 选择合适的数据库或SQL引擎完全取决于您的要求。在这里,我们列出了所有SQL引擎的一些常用和有益的功能。您可以选择Presto或Spark或Hive或Impala。数据库的选择取决于技术规格和功能的可用性。 写在最后 如果你不确定数据库或SQL查询引擎的选择,那只需进行详细比较它们特定的属性和登记功能,你就能更轻松地选择合适的数据库或SQL引擎了。 |
【本文地址】
今日新闻 |
推荐新闻 |