Python爬虫 |
您所在的位置:网站首页 › imovie怎么使用网易云的音乐 › Python爬虫 |
Python爬虫
|
文章目录
前言爬取分析完整代码爬取效果拓展代码
前言
上一篇简述了如何使用 Python 爬虫自动爬取CSDN博客排行榜数据并自动整理成Excel文件,这篇文章来看看如何自动化爬取网易云音乐的歌曲。 爬取分析来看看网易云音乐官网:
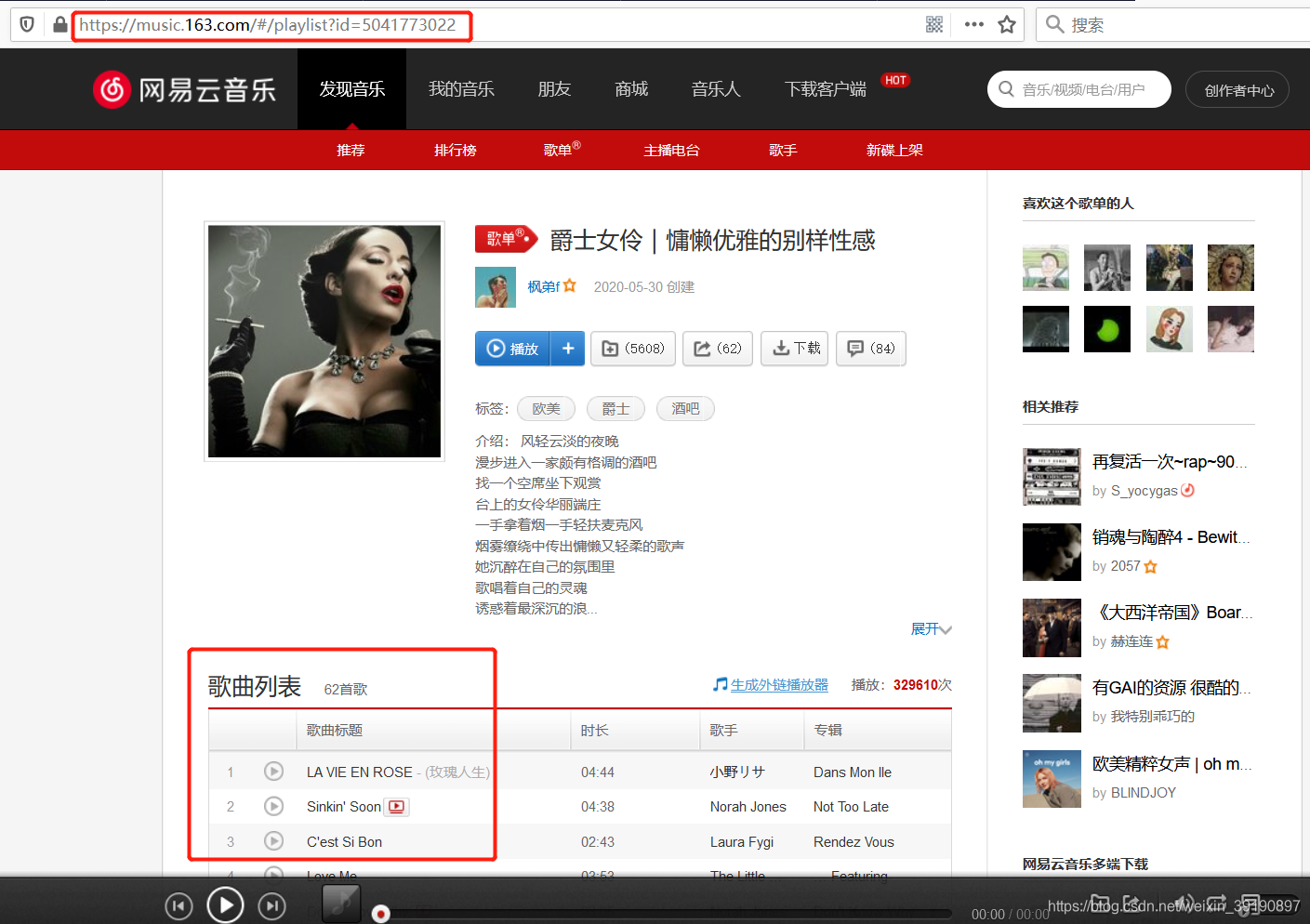
访问目标歌单的地址 https://music.163.com/#/playlist?id=5041773022 :
爬取后得到歌曲名称和歌曲href:
所以我们爬取的地址进行拼接后得到完整的mp3地址过程为: musicUrl='http://music.163.com/song/media/outer/url'+music['href'][5:]+'.mp3'得到完整的MP3地址后可以通过python中的 urlretrieve 方法下载歌曲。 完整代码 #encoding=utf8 import requests from bs4 import BeautifulSoup import urllib.request headers = { 'Referer':'http://music.163.com/', 'Host':'music.163.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.75 Safari/537.36', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8', } # 歌单的url地址 play_url = 'http://music.163.com/playlist?id=5041773022' # 获取页面内容 s = requests.session() response=s.get(play_url,headers = headers).content #使用bs4匹配出对应的歌曲名称和地址 s = BeautifulSoup(response,'lxml') main = s.find('ul',{'class':'f-hide'}) lists=[] for music in main.find_all('a'): list=[] # print('{} : {}'.format(music.text, music['href'])) musicUrl='http://music.163.com/song/media/outer/url'+music['href'][5:]+'.mp3' musicName=music.text # 单首歌曲的名字和地址放在list列表中 list.append(musicName) list.append(musicUrl) # 全部歌曲信息放在lists列表中 lists.append(list) print(lists) # 下载列表中的全部歌曲,并以歌曲名命名下载后的文件,文件位置为当前文件夹 for i in lists: url=i[1] name=i[0] try: print('正在下载',name) urllib.request.urlretrieve(url,'./music/%s.mp3'% name) print('下载成功') except: print('下载失败') 爬取效果在Pycharm执行以上脚本:
附上一位大佬另外的一种实现爬取网易云歌单音乐的代码: #导入库 import requests from fake_useragent import UserAgent from lxml import etree import re #网易云官网 搜索薛之谦跳转网页后 检查 network doc 找到该网页的 #Request URL: https://music.163.com/artist?id=5781 #1、确定url地址(薛之谦的歌单) url = 'https://music.163.com/artist?id=5781' #网易云音乐的外链地址 base_url = 'https://link.hhtjim.com/163/' #2、请求 headers= { "User-Agent": UserAgent().chrome } result = requests.get(url, headers=headers).text # print(result) #3、删选数据 拿到列表中的歌曲id 为一个字典 里面有每首个的id dom =etree.HTML(result) # 通过审查元素发现每首歌在 中通过xpath分析得获取所有歌曲id的xpath语句为'//a[contains(@href,"/song?")]/@href' ids = dom.xpath('//ul[@class="f-hide"]//li/a/@href') #将数据切片只需要id数值 #正则表达式 for i in range(len(ids)): ids[i] = re.sub('\D', '', ids[i]) #print(ids) for i in range(len(ids)): #每一首歌的地址 M_url = f'https://music.163.com/song?id={ids[i]}' response = requests.get(M_url, headers=headers) html = etree.HTML(response.text) music_info = html.xpath('//title/text()') #print(music_info) #['我好像在哪见过你(电影《精灵王座》主题曲) - 薛之谦 - 单曲 - 网易云音乐'] music_name = music_info[0].split('-')[0] singer = music_info[0].split('-')[1] #print(music_name, singer) #我好像在哪见过你(电影《精灵王座》主题曲) 薛之谦 #获取歌源 music_url = base_url + str(ids[i]) + '.mp3' #print(music_url) #打印出每首歌的外链网址 music = requests.get(music_url).content #4、保存 with open('./music/'+music_name+'.mp3', 'wb') as file: file.write(music) print("正在下载第"+str(i+1)+"首: "+music_name+singer)执行效果如下:
|

 使用以下脚本打印歌单信息:
使用以下脚本打印歌单信息: 获取的歌曲地址是不完整的,需要进行拼接。简单案例:例如:杨钰莹的心雨,网址是:http://music.163.com/#/song?id=317151,很明显,ID是317151,那么,这首歌的真实地址就是:
获取的歌曲地址是不完整的,需要进行拼接。简单案例:例如:杨钰莹的心雨,网址是:http://music.163.com/#/song?id=317151,很明显,ID是317151,那么,这首歌的真实地址就是: 查看项目工程文件夹music下已成功爬取下载的音乐文件:
查看项目工程文件夹music下已成功爬取下载的音乐文件: 双击可正常播放:
双击可正常播放:

【本文地址】
今日新闻 |
推荐新闻 |